![]()
RLCard是一款卡牌游戏强化学习 (Reinforcement Learning, RL) 的工具包。 它支持多种卡牌游戏环境,具有易于使用的接口,以用于实现各种强化学习和搜索算法。 RLCard的目标是架起强化学习和非完全信息游戏之间的桥梁。 RLCard由DATA Lab at Rice and Texas A&M University以及社区贡献者共同开发.
- 官方网站:https://www.rlcard.org
- Jupyter Notebook教程:https://github.com/datamllab/rlcard-tutorial
- 论文:https://arxiv.org/abs/1910.04376
- 视频:YouTube
- 图形化界面:RLCard-Showdown
- 斗地主演示:Demo
- 资源:Awesome-Game-AI
- 相关项目:DouZero项目
- 知乎:https://zhuanlan.zhihu.com/p/526723604
- 杂项资源:您听说过以数据为中心的人工智能吗?请查看我们的 data-centric AI survey 和 awesome data-centric AI resources!
社区:
- Slack: 在我们的#rlcard-project slack频道参与讨论.
- QQ群: 加入我们的QQ群讨论。密码:rlcardqqgroup
- 一群:665647450
- 二群:117349516
新闻:
- 我们更新Jupyter Notebook的教程帮助您快速了解RLCard!请看 RLCard 教程.
- 所有的算法都已支持PettingZoo接口. 请点击这里. 感谢Yifei Cheng的贡献。
- 请关注DouZero, 一个强大的斗地主AI,以及ICML 2021论文。点击此处进入在线演示。该算法同样集成到了RLCard中,详见在斗地主中训练DMC。
- 我们的项目被用在PettingZoo中,去看看吧!
- 我们发布了RLCard的可视化演示项目:RLCard-Showdown。请点击此处查看详情!
- Jupyter Notebook教程发布了!我们添加了一些R语言的例子,包括用reticulate调用RLCard的Python接口。点击查看详情。
- 感谢@Clarit7为支持不同人数的二十一点游戏(Blackjack)做出的贡献。我们欢迎更多的贡献,以使得RLCard中的游戏配置更加多样化。点击这里查看详情。
- 感谢@Clarit7为二十一点游戏(Blackjack)和限注德州扑克的人机界面做出的贡献。
- RLCard现支持本地随机环境种子和多进程。感谢@weepingwillowben提供的测试脚本。
- 无限注德州扑克人机界面现已可用。无限注德州扑克的动作空间已被抽象化。感谢@AdrianP-做出的贡献。
- 新游戏Gin Rummy以及其可视化人机界面现已可用,感谢@billh0420做出的贡献。
- PyTorch实现现已可用,感谢@mjudell做出的恭喜。
如果本项目对您有帮助,请添加引用:
Zha, Daochen, et al. "RLCard: A Platform for Reinforcement Learning in Card Games." IJCAI. 2020.
@inproceedings{zha2020rlcard,
title={RLCard: A Platform for Reinforcement Learning in Card Games},
author={Zha, Daochen and Lai, Kwei-Herng and Huang, Songyi and Cao, Yuanpu and Reddy, Keerthana and Vargas, Juan and Nguyen, Alex and Wei, Ruzhe and Guo, Junyu and Hu, Xia},
booktitle={IJCAI},
year={2020}
}确保您已安装Python 3.6+和pip。我们推荐您使用pip安装稳定版本rlcard:
pip3 install rlcard
默认安装方式只包括卡牌环境。如果想使用PyTorch实现的训练算法,运行
pip3 install rlcard[torch]
如果您访问较慢,国内用户可以通过清华镜像源安装:
pip3 install rlcard -i https://pypi.tuna.tsinghua.edu.cn/simple
或者,您可以克隆最新版本(如果您访问Github较慢,国内用户可以使用Gitee镜像):
git clone https://github.com/datamllab/rlcard.git
或使只克隆一个分支以使其更快
git clone -b master --single-branch --depth=1 https://github.com/datamllab/rlcard.git
然后运行以下命令进行安装
cd rlcard
pip3 install -e .
pip3 install -e .[torch]
我们也提供conda安装方法:
conda install -c toubun rlcard
Conda安装只包含卡牌环境,您需要按照您的需求手动安装PyTorch。
以下是一个小例子
import rlcard
from rlcard.agents import RandomAgent
env = rlcard.make('blackjack')
env.set_agents([RandomAgent(num_actions=env.num_actions)])
print(env.num_actions) # 2
print(env.num_players) # 1
print(env.state_shape) # [[2]]
print(env.action_shape) # [None]
trajectories, payoffs = env.run()RLCard可以灵活地连接各种算法,参考以下例子:
- 小试随机智能体
- Blackjack上的Deep-Q学习
- 在Leduc Hold'em上训练CFR(机会抽样)
- 与预训练Leduc模型游玩
- 在斗地主上训练DMC
- 评估智能体
- 在PettingZoo上训练
运行examples/human/leduc_holdem_human.py来游玩预训练的Leduc Hold'em模型。Leduc Hold'em是简化版的德州扑克,具体规则可以参考这里。
>> Leduc Hold'em pre-trained model
>> Start a new game!
>> Agent 1 chooses raise
=============== Community Card ===============
┌─────────┐
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
│░░░░░░░░░│
└─────────┘
=============== Your Hand ===============
┌─────────┐
│J │
│ │
│ │
│ ♥ │
│ │
│ │
│ J│
└─────────┘
=============== Chips ===============
Yours: +
Agent 1: +++
=========== Actions You Can Choose ===========
0: call, 1: raise, 2: fold
>> You choose action (integer):
我们也提供图形界面以实现更便捷的调试,详情请查看这里。以下是一些演示:
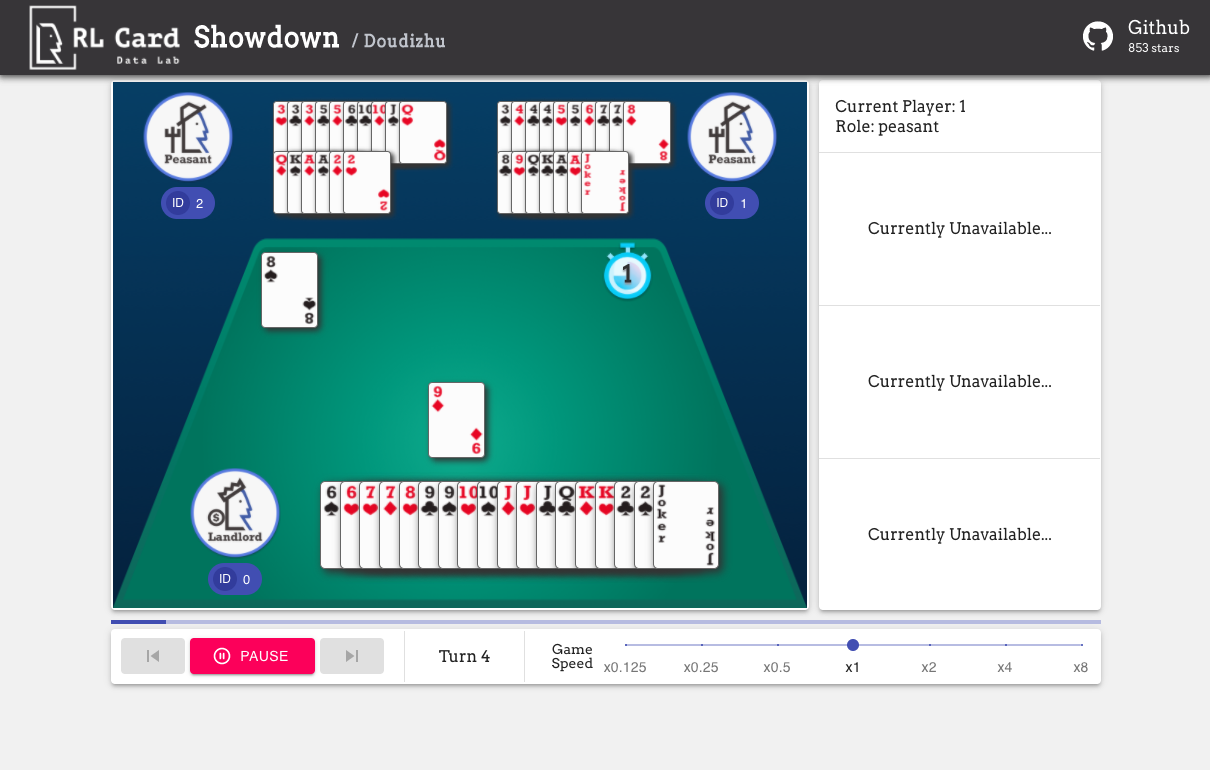
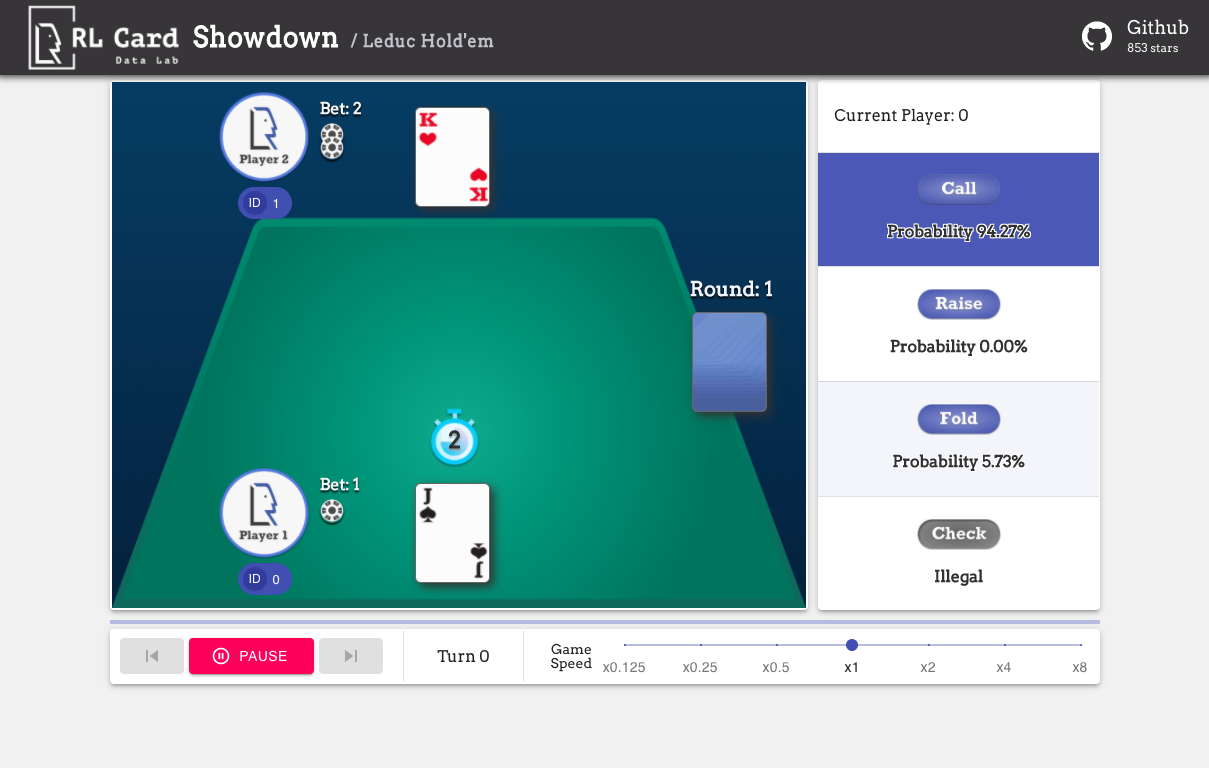
我们从不同角度提供每种游戏的估算复杂度。
InfoSet数量: 信息集数量;InfoSet尺寸: 单个信息集的平均状态数量;状态尺寸: 状态空间的尺寸;环境名: 应该传入rlcard.make以创建新游戏环境的名称。除此之外,我们也提供每种环境的文档链接和随机智能体释例。
| 游戏 | InfoSet数量 | InfoSet尺寸 | 状态尺寸 | 环境名 | 用法 |
|---|---|---|---|---|---|
| 二十一点 Blackjack (wiki, 百科) | 10^3 | 10^1 | 10^0 | blackjack | 文档, [释例]](examples/run_random.py) |
| Leduc Hold’em (论文) | 10^2 | 10^2 | 10^0 | leduc-holdem | 文档, 释例 |
| 限注德州扑克 Limit Texas Hold'em (wiki, 百科) | 10^14 | 10^3 | 10^0 | limit-holdem | 文档, 释例 |
| 斗地主 Dou Dizhu (wiki, 百科) | 10^53 ~ 10^83 | 10^23 | 10^4 | doudizhu | 文档, 释例 |
| 麻将 Mahjong (wiki, 百科) | 10^121 | 10^48 | 10^2 | mahjong | 文档, 释例 |
| 无限注德州扑克 No-limit Texas Hold'em (wiki, 百科) | 10^162 | 10^3 | 10^4 | no-limit-holdem | 文档, 释例 |
| UNO (wiki, 百科) | 10^163 | 10^10 | 10^1 | uno | 文档, 释例 |
| Gin Rummy (wiki, 百科) | 10^52 | - | - | gin-rummy | 文档, 释例 |
| 桥牌 (wiki, baike) | - | - | bridge | 文档, 释例 |
| 算法 | 释例 | 参考 |
|---|---|---|
| 深度蒙特卡洛(Deep Monte-Carlo,DMC) | examples/run_dmc.py | [论文] |
| 深度Q学习 (Deep Q Learning, DQN) | examples/run_rl.py | [论文] |
| 虚拟自我对局 (Neural Fictitious Self-Play,NFSP) | examples/run_rl.py | [论文] |
| 虚拟遗憾最小化算法(Counterfactual Regret Minimization,CFR) | examples/run_cfr.py | [论文] |
我们提供了一个模型集合作为基准线。
| 模型 | 解释 |
|---|---|
| leduc-holdem-cfr | Leduc Hold'em上的预训练CFR(机会抽样)模型 |
| leduc-holdem-rule-v1 | 基于规则的Leduc Hold'em模型,v1 |
| leduc-holdem-rule-v2 | 基于规则的Leduc Hold'em模型,v2 |
| uno-rule-v1 | 基于规则的UNO模型,v1 |
| limit-holdem-rule-v1 | 基于规则的限注德州扑克模型,v1 |
| doudizhu-rule-v1 | 基于规则的斗地主模型,v1 |
| gin-rummy-novice-rule | Gin Rummy新手规则模型 |
您可以使用以下的接口创建新环境,并且可以用字典传入一些可选配置项
- env = rlcard.make(env_id, config={}): 创建一个环境。
env_id是环境的字符串代号;config是一个包含一些环境配置的字典,具体包括:seed:默认值None。设置一个本地随机环境种子用以复现结果。allow_step_back: 默认值False.True将允许step_back函数用以回溯遍历游戏树。- 其他特定游戏配置:这些配置将以
game_开头。目前我们只支持配置Blackjack游戏中的玩家数量game_num_players。
环境创建完成后,我们就能访问一些游戏信息。
- env.num_actions: 状态数量。
- env.num_players: 玩家数量。
- env.state_shape: 观测到的状态空间的形状(shape)。
- env.action_shape: 状态特征的形状(shape),斗地主的状态可以被编码为特征。
状态(State)是一个Python字典。它包括观测值state['obs'],合规动作state['legal_actions'],原始观测值state['raw_obs']和原始合规动作state['raw_legal_actions']。
以下接口提供基础功能,虽然其简单易用,但会对智能体做出一些前提假设。智能体必须符合智能体模版。
- env.set_agents(agents):
agents是Agent对象的列表。列表长度必须等于游戏中的玩家数量。 - env.run(is_training=False): 运行一局完整游戏并返回轨迹(trajectories)和回报(payoffs)。该函数可以在
set_agents被调用之后调用。如果is_training设定为True,它将使用智能体中的step函数来进行游戏;如果is_training设定为False,则会调用eval_step。
对于更高级的方法,可以使用以下接口来对游戏树进行更灵活的操作。这些接口不会对智能体有前提假设。
- env.reset(): 初始化一个游戏,返回状态和第一个玩家的ID。
- env.step(action, raw_action=False): 推进环境到下一步骤。
action可以是一个原始动作或整型数值;当传入原始动作(字符串)时,raw_action应该被设置为True。 - env.step_back(): 只有当
allow_step_back设定为True时可用,向后回溯一步。 该函数可以被用在需要操作游戏树的算法中,例如CFR(机会抽样)。 - env.is_over(): 如果当前游戏结束,则返回
True,否则返回False。 - env.get_player_id(): 返回当前玩家的ID。
- env.get_state(player_id): 返回玩家ID
player_id对应的状态。 - env.get_payoffs(): 在游戏结束时,返回所有玩家的回报(payoffs)列表。
- env.get_perfect_information(): (目前仅支持部分游戏)获取当前状态的完全信息。
主要模块的功能如下:
- /examples: 使用RLCard的一些样例。
- /docs: RLCard的文档。
- /tests: RLCard的测试脚本。
- /rlcard/agents: 强化学习算法以及人类智能体。
- /rlcard/envs: 环境包装(状态表述,动作编码等)。
- /rlcard/games: 不同的游戏引擎。
- /rlcard/models: 包括预训练模型和规则模型在内的模型集合。
请参考这里查阅更多文档Documents。API文档在我们的网站中。
我们非常感谢对本项目的贡献!请为反馈或漏洞创建Issue。如果您想恭喜代码,请参考贡献指引。如果您有任何问题,请联系通过daochen.zha@rice.edu联系Daochen Zha
我们诚挚的感谢竞技世界网络技术有限公司(JJ World Network Technology Co.,LTD)为本项目提供的大力支持,以及所有来自社区成员的贡献。