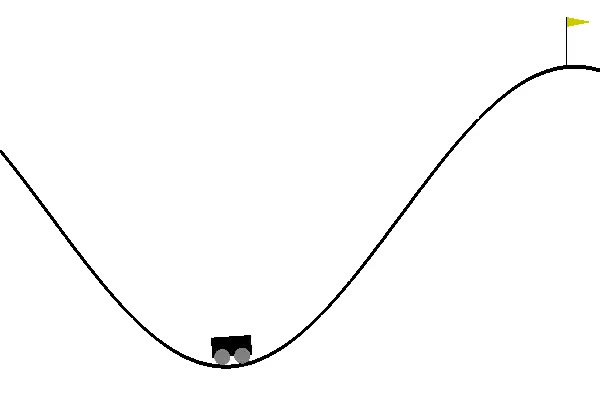
'Mountain car' environment from GYM library.
A car is on a one-dimensional track, positioned between two "mountains". The goal is to drive up the mountain on the right; however, the car’s engine is not strong enough to scale the mountain in a single pass. Therefore, the only way to succeed is to drive back and forth to build up momentum.
Q-table agent
To determine value of Q-function for every state-action pair agent use a table of a
finite size.
Since domain state observation consist of 2 continuous variables observation, received from domain, discretized into natural numeric
value in range [0, 40].
In such a way Q-values table has resulting size of 40x40x3 of floating point values.
Multi Layer Perceptron agent
DQN agent:
- Input layer - 2x6
- Output layer - 6x3
- Sigmoid activation function after final layer
- Argmax function over output vector to determine optimal policy.
-
Install dependencies
pip install -r requirements.txt -
Run training. Use
--r_train 0to run without renderingpython main.py --agent mlp
For a complete overview of the supported global flags, use main --help.