Machine learning models may perform differently on different data subgroups. We propose the notion of divergence over itemsets (i.e., conjunctions of simple predicates) as a measure of different classification behavior on data subgroups, and the use of frequent pattern mining techniques for their identification. We quantify the contribution of different attribute values to divergence with the notion of Shapley values to identify both critical and peculiar behaviors of attributes. See our paper for details and citations.
DivExplorer is available as a python package and as a interactive cloud-based web app.
DivExplorer is a web app for analyzing datasets and finding subgroups of data where a classifier behaves differently than on the overall data.
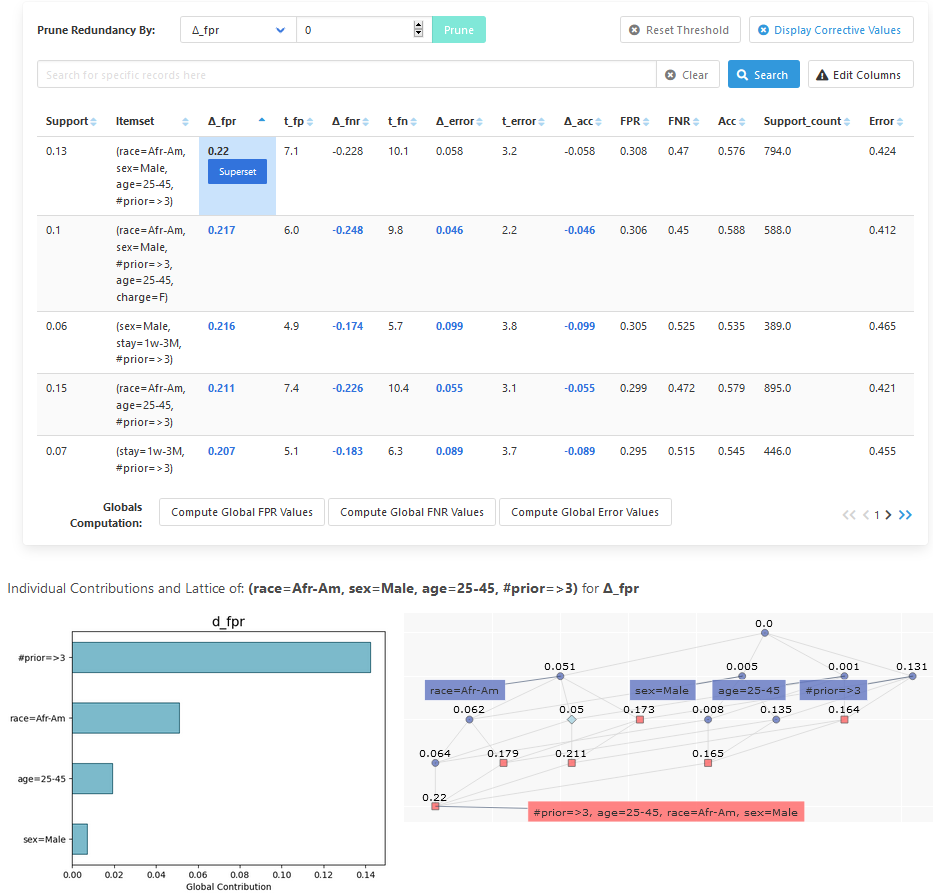
You can try DivExplorer here. You can use the preprocessed discretized COMPAS dataset as demo dataset.
Source code and documentation are available at the following link.
DivExplorer is designed by Eliana Pastor, Andrew Gavgavian, Elena Baralis, Luca de Alfaro
DivExplorer is available as a python package at the following link.
Looking for Trouble: Analyzing Classifier Behavior via Pattern Divergence. Eliana Pastor, Luca de Alfaro, Elena Baralis. Proceedings of the 2021 International Conference on Management of Data (SIGMOD '21). June 20--25, 2021, Virtual Event, China. (to appear)