This repository houses the official implementation of BABE-2, an advanced algorithm designed for the enhancement of historical music recordings.
E. Moliner, M. Turunen, F. Elvander and V. Välimäki,, "A Diffusion-Based Generative Equalizer for Music Restoration", submitted to DAFx24, Mar, 2022

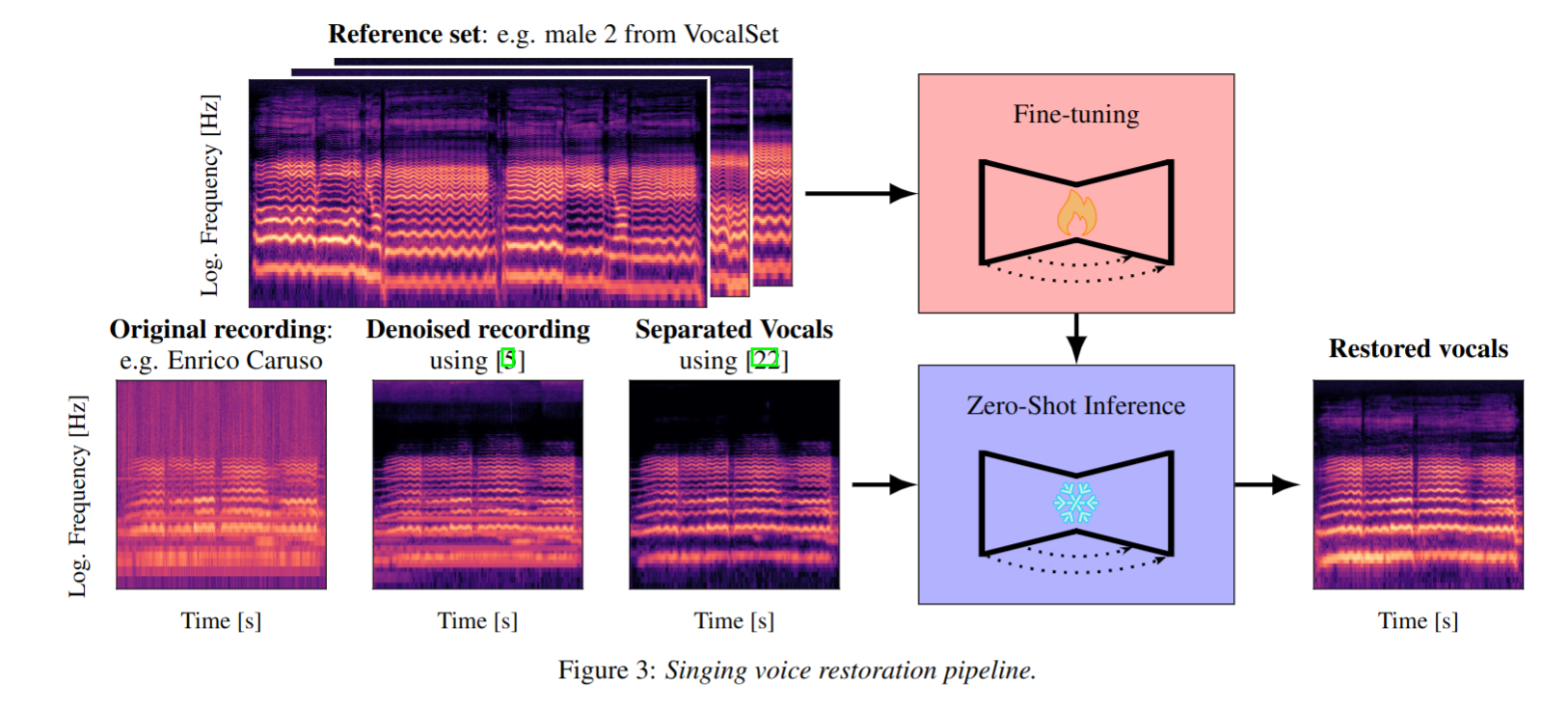
This paper presents a novel approach to audio restoration, focusing on the enhancement of low-quality music recordings, and in particular historical ones. Building upon a previous algorithm called BABE, or Blind Audio Bandwidth Extension, we introduce BABE-2, which presents a series of significant improvements. This research broadens the concept of bandwidth extension to \emph{generative equalization}, a novel task that, to the best of our knowledge, has not been explicitly addressed in previous studies. BABE-2 is built around an optimization algorithm utilizing priors from diffusion models, which are trained or fine-tuned using a curated set of high-quality music tracks. The algorithm simultaneously performs two critical tasks: estimation of the filter degradation magnitude response and hallucination of the restored audio. The proposed method is objectively evaluated on historical piano recordings, showing a marked enhancement over the prior version. The method yields similarly impressive results in rejuvenating the works of renowned vocalists Enrico Caruso and Nellie Melba. This research represents an advancement in the practical restoration of historical music.
Listen to our audio samples
Read the pre-print in arXiv
The pretrained checkpoints used in the paper experiments are available here
python test.py --config-name=conf_singing_voice.yaml tester=singer_evaluator_BABE2 tester.checkpoint="path/to/checkpoint.pt" id="BABE2_restored" tester.evaluation.single_recording="path/to/recording.wav"python test.py --config-name=conf_piano.yaml tester=only_uncond_maestro tester.checkpoint="path/to/checkpoint.pt" id="BABE2" tester.modes=["unconditional"]Train a model from scratch:
python train.py --config-name=conf_custom.yaml model_dir="experiments/model_dir" exp.batch=$batch_size dset.path="/path/to/dataset"Fine-tune from pre-trained model:
python train.py --config-name=conf_custom.yaml model_dir="experiments/finetuned_model_dir" exp.batch=$batch_size dset.path="/path/to/dataset" exp.finetuning=True exp.base_checkpoint="/link/to/pretrained/checkpoint.pt"