Дедлоки — одна из немногих проблем FBP, которая невозможна в рамках одного процесса, но возникает в результате взаимодействия между несколькими. Когда два или более процессов мешают друг другу таким образом, что сеть в целом в конечном итоге не может работать.
Я знаю, некоторые программисты чувствуют, что они променяли знакомые трудности традиционного программирования на новую и экзотическую проблему, которая кажется очень сложной, и задаются вопросом, а не переместили ли мы сложность из одного места в другое! Хотя, на первый взгляд, взаимоблокировки могут казаться пугающими, я уверяю вас, вы научитесь распозновать сети, склонные к взаимоблокировкам, и научитесь надежным способам предотвращения их возникновения. Я не знаю ни одного случая, когда правильно спроектированная сеть привела бы к дедлоку на проде.
Однако, сперва нам следует более глубоко взглянуть на вопрос, который я упомянул выше: если FBP так хорош, то почему он порождает новый и экзотический класс проблем, с которыми программист не столкнулся бы в обычных условиях?
Ну, вообще-то, это не ново — просто "обычная" программа имеет только один процесс, так что о взаимоблокировках можно не беспокоиться. В FBP же у нас есть несколько процессов, и несколько процессов всегда приводили к разного рода блокировкам. Если на предыдущих страницах я убедил вас в целесообразности подхода FBP, то вы с облегчением узнаете, что существует довольно много литературы по многопроцессным взаимоблокировкам. Любой, кто проектировал распределенные системы, сталкивался с этим.
Например, предположим, что два человека пытаются получить доступ к одному и тому же счету в банке через разные банкоматы. Само по себе это не вызывает проблем, нужно просто подождать, сперва один, потом второй.
Теперь предположим, что они оба решили перевести деньги между одними и теми же двумя счетами, но в разных направлениях. Обычно это программируется так, чтобы обе транзакции переводили обе учетные записи в режим обновления (Get Hold в терминах IMS DL/I). Теперь рассмотрим следующую последовательность событий (назовем учетные записи X и Y):
транзакция А — получить Х с удержанием
транзакция B — получить Y с удержанием
(1) транзакция B – попытайтесь получить X с удержанием
(2) транзакция А – попытайтесь получить Y, удерживая
В точке (1) транзакция B приостанавливается, потому что ей нужен X, который принадлежит A. В точке (2) транзакция A приостанавливается, потому что ей нужен Y, который принадлежит B. Теперь ни один из них не может освободить ресурс, который другой хочет. Если бы A не нуждался в Y, он бы в конце концов закончил то, что делал, и освободил бы X, чтобы B мог продолжить. Однако теперь, когда он попытался захватить Y, результатом стал непреодолимый тупик. Это часто называют «смертельными объятиями», и на самом деле это похоже на один из видов блокировки в FBP. Обычно онлайн-системы имеют какой-то тайм-аут, который отменяет одну или обе задействованные транзакции.
Обычно вероятность такого события бесконечно мала, поэтому многие системы просто не беспокоятся об этом. Этого можно полностью предотвратить, всегда получая учетные записи в фиксированной последовательности, но иногда это невозможно, поэтому, вероятно, верно будет сказать, что некоторая часть (даже если небольшая) транзакций зайдет в тупик в онлайн-системе. Поэтому вы должны быть в состоянии принять какие-то меры по исправлению положения.
В FBP мы также можем получить взаимоблокировки между процессами сети. Конечно, в онлайн-системе FBP каждая транзакция будет представлять собой сеть, поэтому вы можете получить "смертельные объятия" между отдельными сетями, запрашивающими одни и те же ресурсы, но мы предполагаем, что они обрабатываются обычным способом для базового программного обеспечения для управления ресурсами. Однако, поскольку в сети имеется несколько процессов, внутри сети могут возникать взаимоблокировки. Во всех этих внутрисетевых случаях мы обнаружили, что это всегда проблема проектирования.
Общий термин для таких тупиков, как «смертельные объятия», — "deaclock". В литературе есть классический пример этого, называемый «проблемой обедающих философов», к которой обращались многие авторы, писавшие о многопроцессности.
Представьте, что в комнате стоит стол, на котором лежат 5 палочек для еды, расположенных на равном расстоянии друг от друга, и миска с рисом в центре. Когда философ голоден, он входит в комнату, берет по две палочки с каждой стороны своего места, ест до тех пор, пока не насытится, а затем уходит, положив палочки на стол (надеюсь, после того, как их помоет). Если все философы войдут одновременно и каждый возьмет палочку справа (или слева), вы получите взаимную блокировку, поскольку никто не может есть, следовательно, никто не может высвободить палочку для еды, следовательно, никто не может есть! Обратите внимание, что обедающие философы демонстрируют ту же топологию цикла, о которой я предупреждал вас в предыдущих главах. Обедающие философы могут также страдать от обратного синдрома, "livelock", когда, хотя тупика и нет, парадоксальным образом один из философов находится под угрозой голодной смерти, поскольку нет никакой гарантии, что он когда-либо сможет воспользоваться двумя свободными палочками. Кузе и др. (1986) доказали, что хотя сеть с соединениями фиксированной пропускной способности (например, в FBP) может страдать от deaclock'а, она никогда не может страдать от livelock'а.
Мы будем использовать рисунок 14.2 из главы «Петлевые сети», чтобы представить версию взаимоблокировки ресурсов FBP. Я покажу это еще раз для удобства:
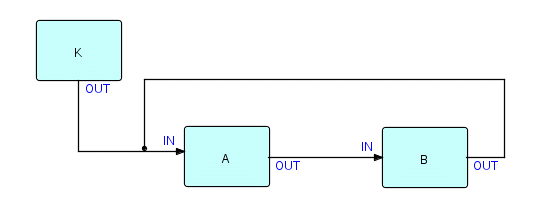
Предположим, что логика A и логика B одинаковы и выглядят следующим образом:
/* Copy IPs from IN to OUT */
receive from IN using a
do while receive has not reached end of data
send a to OUT
receive from IN using a
enddo
Фрагмент 16.2
Другими словами, они оба являются простыми фильтрами. Однако предположим, что при некоторых обстоятельствах B не может отправить только что полученный IP на свой порт OUT, поэтому его логика фактически следующая:
/* Copy c-type IPs from IN to OUT */
receive from IN using a
do while receive has not reached end of data
if condition c is true
send a to OUT
endif
receive from IN using a
enddo
Фрагмент 16.3
Начнем с запуска A. A отправляет IP через свой порт OUT. Затем он осуществляет прием на IN, но там ничего нет, поэтому он приостанавливается. В соединении между A и B теперь что-то есть, поэтому B запускается. Допустим, условие «c» неверно, поэтому B получает IP, но не может его отправить. Затем B продолжает прием и приостанавливается. Прием A также приостановлен, он будет ждать бесконечно, поскольку B не отправил IP, который ожидает A. B приостановлен на неопределенный срок, поскольку A не может отправить то, чего ожидает B.
Это очень похоже на смертельные объятия: два процесса, каждый из которых приостановлен, ожидая, пока другой что-нибудь сделает. Поскольку прием A и B приостановлен, в нашей сети нет ничего активного (K завершился). Поэтому ни один процесс не может продолжаться. Программа в целом определенно не завершилась нормально и ничего не происходит! Фактически именно так драйвер распознает возникновение взаимоблокировки.
AMPS и DFDM добавляют масла в огонь: можно приостановить один или несколько процессов в ожидании внешнего события (например, завершения ввода-вывода). В этом случае сеть в целом переходит в «системное ожидание», ожидая одного или нескольких внешних событий. Когда происходит одно из этих событий, драйвер восстанавливает контроль и передает контроль над рассматриваемым процессом. Если бы не тот факт, что кто-то ожидает внешнего события, это выглядело бы просто дедлоком. Вместо этого событие в конечном итоге произойдет, что позволит процессу продолжиться, что позволит всем другим взаимосвязанным процессам запускаться по мере необходимости. Эта функция является одним из важных преимуществ производительности FBP: в отличие от обычного программирования, если процессу необходимо дождаться возникновения события, при использовании FBP обычно нет необходимости переводить всю сеть в состояние ожидания (если позволяет базовое программное обеспечение).
Давайте перерисуем диаграмму, на которой состояния каждого процесса будут показаны в верхнем левом углу процесса. Такая модель состояний довольно распространена и вполне характерна для определенного вида тупика. Драйверы всех реализаций FBP всегда перечисляют состояния процесса как часть своих диагностических выходных данных в случае взаимоблокировки.
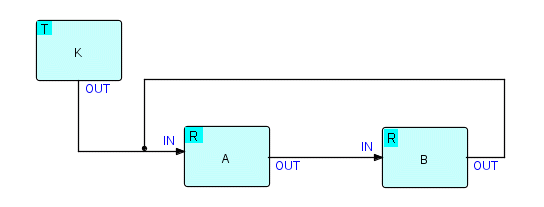
Где T означает Terminated,
а R означает приостановлен на получении (receive).
Фрагмент 16.4
Очевидно, что такого рода deadlock произойдет каждый раз, когда процесс выводит меньше IP-адресов, чем требуется нижестоящему процессу.
Поскольку единственным видом ресурса, «родным» для FBP, является IP, то единственной проблемой может быть непоступление IP. Поэтому тщательное тестирование выявит это. У нас также могут быть «инфраструктурные» или «гибридные» (FBP плюс инфраструктура) взаимоблокировки, когда, скажем, один процесс ожидает внешнего события, которое никогда не происходит, а другой — IP-адреса, который первый должен отправить.
Ничто не мешает процессу DFDM выдать MVS ENQ, что позволяет двум процессам блокировать друг друга, выдавая два ENQ для одного и того же ресурса, но в разных порядках. Здесь применимы старые соображения о взаимоблокировках, но, как я уже сказал, это хорошо изученная область вычислений.
Другой класс тупиков, знакомый системным программистам, — это «тупики хранилища». Взаимная блокировка такого типа возникает из-за того, что одному процессу не хватает памяти для хранения информации, которая понадобится позже. Этот тип взаимоблокировки, в отличие от взаимоблокировки ресурсов, обычно можно разрешить, предоставив больше места для хранения (не всегда, однако).
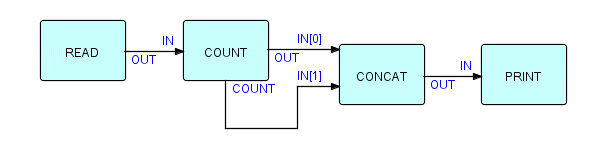
Вот пример тупика хранилища: предположим, вы подсчитываете поток IP и хотите распечатать все IP, а затем их количество. Компоненты для этого должны быть вам уже хорошо знакомы: подсчитываемые IP переходят в процесс COUNT на порте IN и выходят через порт OUT, в то время как IP счетчика создаются и отправляются через порт COUNT при закрытии. Итак, все, что нам нужно сделать, это объединить количество IP после тех, которые приходят из OUT. Это, конечно, очень просто — вот сеть: