"Вот что мне нравится в AMPS так это то, как много там, по сравнению с традиционным программированием, способов решить задачу (программист из большой Канадской компании).
Мы начнем эту главу с самой простой сети, которую только можно вообразить — ну, на самом деле, сеть только с одним процессом — самая простая, но это эквивалентно обычной программе! Простейшей сетью, по крайней мере, с одним соединением может быть Reader, питающий Writer, как показано ниже:
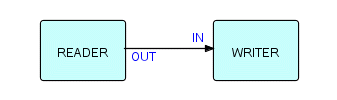
Фрагмент 6.1
Эта сеть просто копирует один файл в другой, поэтому она эквивалентна утилите "копирования", которая есть практически в каждой операционной системе. Разница в том, что FBP позволяет комбинировать эти утилиты во всё более сложные функции. Утилиты, по моему опыту, предоставляют ряд функций, но всегда хочется чего-то немного другого. Функции, которые в них зашиты, часто не те, которые нужны. Это вполне понятно, учитывая сложность прогнозирования того, что люди сочтут полезным. Одна из альтернатив — объединить несколько утилит, записав промежуточные файлы на диск. FBP эффективно позволяет вам комбинировать несколько служебных функций, не требуя места на диске или ввода-вывода для чтения и записи с диска и на диск (таким образом, вы также используете меньше процессорного времени и, что более важно, меньше реально затраченного времени).
Предположим, вы хотите объединить функцию "копирования" с селектором, а затем отсортировать результат перед записью на диск. Просто свяжите нужные функции вместе:

Фрагмент 6.2
На самом деле, сеть даже не обязательно должна быть полностью подключена. Например, следующее совершенно правильно и даже может быть полезно!
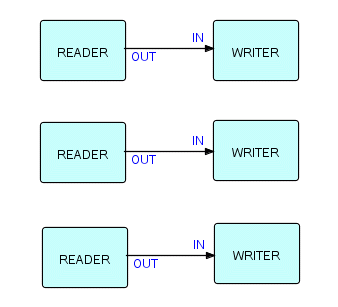
Фрагмент 6.3
Я помню время, когда возможность написать программу, которая одновременно считывала карты и записывала их на ленту, читала ленту и выбивала записи, а также выполняла некоторую печать, считалась вершиной изобретательности программиста! Я обнаружил, что с FBP все, что вам нужно сделать, это указать связи между шестью процессами, как показано на диаграмме!
Теперь, если вы думаете об этой диаграмме как о способе сделать что-то, а не контролировать, когда это происходит, вы поймете, что три пары процессов, показанные выше, не обязательно должны выполняться одновременно. Дело в том, что они могут, если есть соответствующие ресурсы, но они не обязаны - это не влияет на их правильное функционирование. Думайте об этой сети как о трех железнодорожных путях, по каждому из которых движется поезд. Вы просто заботитесь о том, чтобы каждый поезд прибыл в пункт назначения, а не когда именно и как быстро. В бизнес-приложениях нас интересует правильное функционирование, а не точное время событий. В реализации MVS FBP три "дорожки", вероятно, будут работать одновременно, поскольку ввод-вывод может перекрываться. В THREADS [реализация для ПК], в которых еще нет перекрытия ввода-вывода, они могут выполняться последовательно. Ни в одном из этих случаев порядок не определен. Я думаю, что нижний будет работать первым, но я не уверен! Естественно, это очень нервирует олдскульных программистов, привыкших контролировать каждую деталь, когда что должно произойти. Я буду постоянно возвращаться к этому моменту, поскольку он очень важен: **разработка приложений должна быть связана с функцией, а не с контролем времени, если время не является частью функции**, как в некоторых real-time приложениях. Нам предстоит решить, что стоит внимания программиста, а что можно смело оставить машине. **Незнание точного времени, когда что-то произойдет, освобождает**, а не дезориентирует. Но да, некоторым программистам переход покажется довольно трудным!
Кстати, при сравнении 4GL и FBP меня поразил тот факт, что в FBP действительно можно делать все что угодно! Сила FBP заключается не в ограничении того, что могут делать программисты, а в инкапсуляции общих задач в повторно используемые компоненты или конструкции. Поскольку в традиционном программировании программа фактически представляет собой FBP-сеть из одного процесса, программист может игнорировать все средства FBP, если хочет, и в результате получается обычная программа. Это может прозвучать дерзко, но для меня это говорит о том, что мы ничего не убираем — мы добавляем совершенно новое измерение в процесс программирования. В то время как некоторые программисты действительно чувствуют ограничения с FBP, это происходит из-за необходимости выражать все как "черные ящики" с четко определенными интерфейсами между ними, а не из-за какой-либо потери функционала.
В оставшейся части главы мы соберем несколько простых примеров с использованием повторно используемых компонентов, но сначала мы должны составить каталог. Компоненты, которые не были упомянуты выше, являются довольно очевидными расширениями того, что было раньше. Некоторые элементы в этом списке следует понимать как разновидность некоторого компонента, а заранее определенные фрагменты кода. Например, в FBP-магазине может быть два или три модуля Sort с разными характеристиками:
- sort
- collate
- split
- assign
- replicate
- count
- concatenate
- compare
- generate reports
- read
- write
- transform
- manipulate text (может быть большой группой)
- discard
Давайте также добавим некоторые компоненты, которые оказались полезными во время разработки и отладки: dumper (который отображает шестнадцатеричные и символьные форматы) и компонент построчного принтера.
Мы не упоминали assign раньше. Я собираюсь использовать это для некоторых примеров, поэтому мы подробнее рассмотрим этот тип компонента. Этот компонент (или вид компонентов) просто вставляет значение в указанную позицию в каждом входящем IP и выводит измененные IP. Он имеет ту же форму, что и "фильтр", и его можно нарисовать следующим образом:
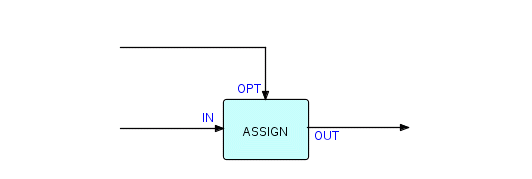
Фрагмент 6.4
Где OPT получает спецификацию того, где во входящих IP должна происходить модификация и какое значение должно быть помещено туда. Например, мы можем разработать компонент Assign, который принимает IP опций, выглядящие следующим образом:
3, 5, ABCDE
Это может означать, что "ABCDE" должен быть вставлен в 5 символов, начиная со смещения 3 от начала каждого IP. Это может показаться слишком простым, но можно комбинировать с другими функциями, чтобы обеспечить широкий спектр функций.
Кстати, этот компонент иллюстрирует полезность IIP: если в рисунке 6.4 подключить assign OPT порт к IIP, вы, по сути, определите постоянное присваивание со значением, определенным вне процесса Assign, но фиксированным для сети в целом. Теперь вместо этого подключите OPT-порт Assign к восходящему процессу, и теперь у вас есть динамическое присваивание, где значения могут быть любыми, и могут изменяться как угодно.
Теперь воспользуемся Assign, чтобы пометить IP, поступающие из разных источников. Предположим, вы хотите объединить три файла и выполнить одинаковую обработку для всех из них, но также хотите иметь возможность позже снова разделить их. Вы можете использовать Assign, чтобы установить "исходный код" в IP из каждого файла, а затем использовать Splitter, чтобы разделить их позже.
В предыдущей главе мы использовали идею двустороннего селектора, который выглядит следующим образом:
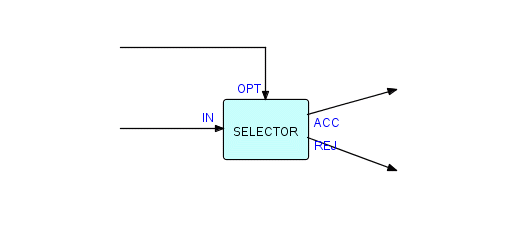
Фрагмент 6.5
Теперь мы можем обобщить это до "n-стороннего разделителя", где вместо двух портов с конкретными именами у нас есть массив портов, который по существу использует номер для обозначения фактического выходного соединения. Покажем это следующим образом (используя соглашение о нумерации THREADS):
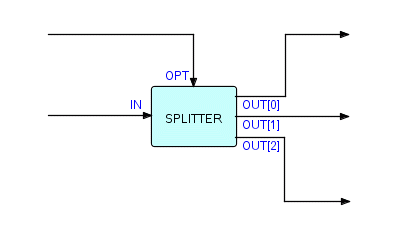
Фрагмент 6.6
Объединив компоненты Assign и разделитель, мы могли бы реализовать приведенный выше пример слияния трех файлов следующим образом:
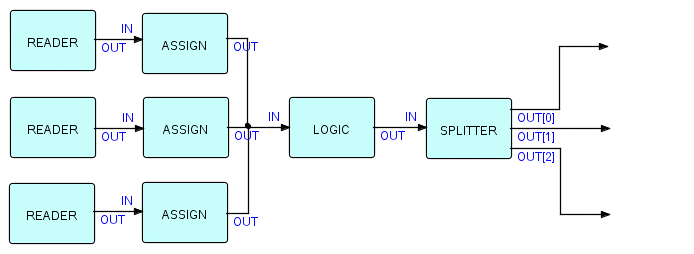
Фрагмент 6.7
Разделители необходимо параметризовать, указав длину и смещение поля, а также ряд возможных значений. Таким образом, приведенный выше сплиттер может быть параметризован следующим образом:
54,1,'A','B','C'
Предполагая, что коды A, B и C были вставлены в IP, поступающие от трех считывателей соответственно.
Построим более сложный пример на основе провинций Канады. Допустим, у нас есть файл записей с кодами провинций. Мы хотим упорядочить их по часовым поясам, чтобы мы могли распечатать их и попросить курьера доставить их к началу работы. Самая восточная точка Канады на 4,5 часа опережает самую западную, поэтому большинству крупных канадских компаний приходится бороться с проблемами часового пояса.
Здесь мы также будем использовать сплиттер для разделения потока IP по провинциям. Как только потоки "провинций" будут разделены, мы можем использовать Assign для вставки соответствующих кодов в разные IP. Этот сплиттер может иметь IP опции, выглядящий следующим образом:
6, 2, 'ON', 'QU', 'MA', 'AL', ...
Это будет читаться следующим образом: проверьте 2 символа, начиная со смещения 6 от входящего IP; если это ON, направьте IP на OUT[0]; если QU, на OUT[1]; если MA, на OUT[2]; и т.д. Конечно, в обоих вышеперечисленных случаях было бы гораздо удобнее использовать имена полей, а не смещения и длины. Мы поговорим об этой идее в главе о дескрипторах.
Еще один вопрос, на который мы должны ответить: что делает селектор, если входящий IP не соответствует ни одному из указанных шаблонов? В DFDM стандартный сплиттер просто отправлял "левые" IP в элемент массива 'n+1', где 'n' равно количеству возможных значений (в DFDM использовалось индексирование, основанное на 1). Другой возможностью может быть отправка несовпадающих IPов на отдельный именованный порт.
Таким образом, приложение может выглядеть так (я просто покажу два процесса Assign и предположу, что все IP совпадают):
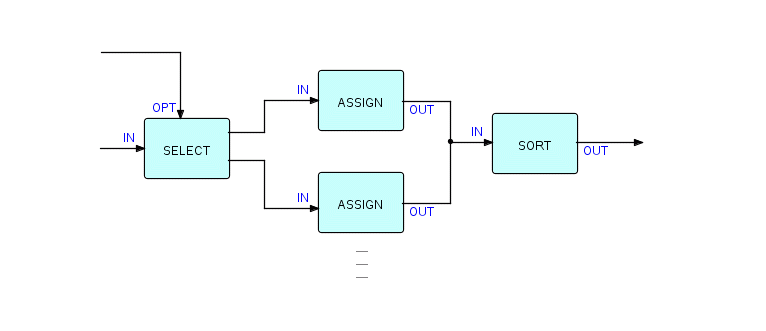
Фрагмент 6.8
Assign-процессы могут вставить код, который возрастает по мере продвижения с востока на запад. Поскольку сортировка переупорядочивает все данные, мы можем передать все измененные записи в один порт в процессе сортировки. Это также позволяет избежать взаимоблокировки (о том, почему это так, я расскажу подробнее в одной из последующих глав).
Я не показывал варианты портов в Assigns, но они будут необходимы, чтобы указать, какие коды нужно вставлять и куда.
Теперь давайте добавим логику для обработки несовпадающих IP. Поскольку о них, вероятно, следует сообщать человеку, мы добавим компонент принтера и воспользуемся техникой именованного порта следующим образом:
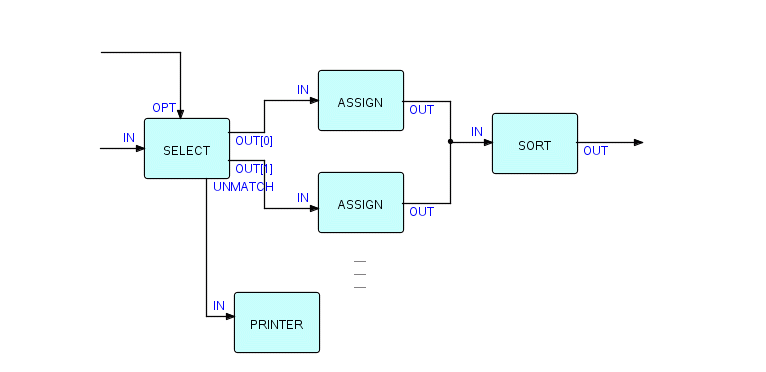
Фрагмент 6.9
На этом этапе у нас будет просто список несопоставленных IP, выводимых в файл для печати. Вы, вероятно, захотите добавить поясняющий заголовок и немного отформатировать их. Позже вы увидите, как это сделать. На данный момент давайте просто скажем, что вам, вероятно, потребуется изменить эту сеть, вставив один или несколько процессов, где я показал PRINTER выше, например:
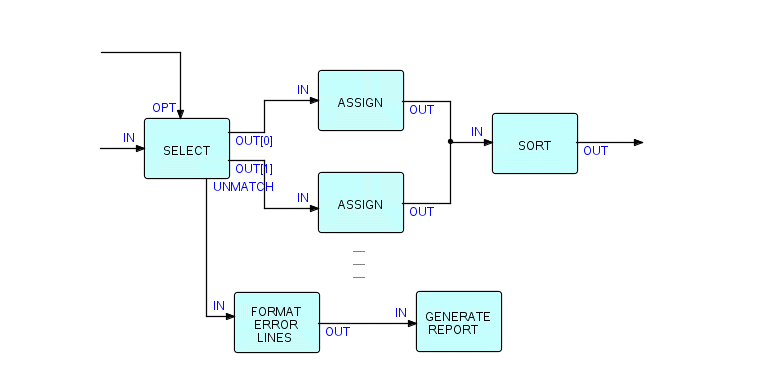
Фрагмент 6.10
Давайте предположим, что теперь у нас есть наша сеть, работающая и делающая то, что она должна делать — мы должны задать вопрос: является ли эта сеть "промышленно сильной"? Когда что-то работает, возникает определенное искушение почувствовать, что работа закончена. На самом деле, вполне допустимо использовать программу, подобную показанной выше, для одноразового приложения типа утилиты или для временного моста между двумя приложениями. Но есть фундаментальный вопрос, на который дизайнер должен ответить, а именно (в этом приложении), как долго в Канаде будет ровно 13 провинций и территорий? Не бойтесь, это не книга о канадской политике! Мы заставили нашу программную структуру отражать часть структуры внешнего мира, и мы должны решить, насколько комфортно мы чувствуем себя с этой зависимостью. Да, всегда найдутся программисты, и мы всегда сможем изменить эту программу... лишь бы ее найти! Никто не может принять решение за вас, но я бы посоветовал, если этой программе придется просуществовать более нескольких лет, вы, возможно, захотите рассмотреть возможность структурирования своего кода для использования с отдельно скомпилированной таблицей или базой данных, которая может собрать воедино все атрибуты провинций, представляющих интерес для вашего приложения. Тогда ваше приложение может выглядеть следующим образом (если вы абстрагируете в SELECT "определение провинции", а в ASSIGN как "вставку кода часового пояса для каждой провинции"):

Фрагмент 6.11
Обратите внимание, что эта диаграмма стала проще, а компоненты — сложнее. Она имеет ту же общую структуру, что и предыдущая диаграмма, но ее форма не отражает (возможно, изменчивую) политическую структуру. Другой подход может заключаться в объединении компонентов SELECT и ASSIGN, показанных выше, с использованием либо кода специального назначения, либо универсального преобразующего модуля.
Более тонкое обобщение может состоять в том, чтобы сохранить параллелизм, но не привязывать его к отдельным провинциям во время спецификации сети. Давайте решим, что никогда не будет больше, скажем, 24 провинций, поэтому мы расширим предыдущую диаграмму, чтобы иметь 24 процесса ASSIGN. SELECT будет иметь 24 порт-элемента на выходе, подключенном к ASSIGN. Теперь, поскольку и ASSIGN, и SELECT управляются параметрами, мы можем получить их параметры из файла (который читается модулем чтения) или таблицы (используя компонент Table Look-up) и отправить их на их порты OPT. Возможности безграничны! Важными решениями являются не "как мне заставить это работать?", а "какое решение даст мне лучший баланс между производительностью и удобством сопровождения?". Когда я преподавал концепции FBP, я обычно говорил своим студентам, что машина примет почти все, что вы ей бросите - настоящая проблема в программировании состоит в том, чтобы сделать вашу программу понятной для людей (будь то другие люди, смотрящие на ваш код годы спустя или вы сами через неделю)! Это гораздо более сложная задача, чем просто заставить код работать.
Есть еще один способ взглянуть на этот пример: что мы на самом деле делаем на этой диаграмме - так это преобразование одного кода в другой под управлением таблицы. Одним из обобщенных типов компонентов, который мы сочли наиболее полезным, был один (или несколько) компонентов поиска по таблице. Таблицу можно хранить как загрузочный модуль (в MVS), и в этом случае она должна будет поддерживаться отделом программирования, но лучшим методом является хранение ее в файле. Компонент поиска по таблице будет выглядеть следующим образом:
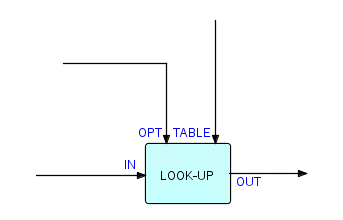
(Прим. Пер - OPT порт в этом и последующих примерах указывает только размер и сдвиг искомого поля, сами обрабатываемые значения теперь передаются через порт TABLE)
Фрагмент 6.12
Во время запуска компонент будет читать все IP из порта с именем TABLE и создаст таблицу в хранилище. Затем он начинает процесс получения IP от IN, ищет указанное поле в таблице, вставляет найденное значение в IP, а затем отправляет их на OUT. Конечно, это нужно параметризовать — вероятно, нам нужно будет указать смещение и длину поля поиска во входящих IP, а также смещение и длину поля, которое необходимо вставить. Нам понадобится Reader, чтобы ввести в таблицу IP из файла, поэтому результирующая сеть будет выглядеть так (частично):
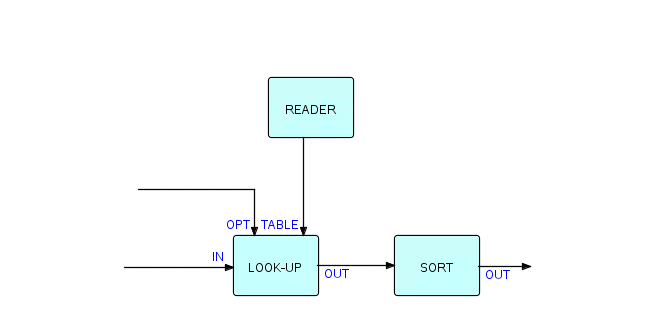
Фрагмент 6.13
Было обнаружено, что компоненты поиска по таблице очень полезны в различных диалектах FBP. В DFDM система распространялась с двумя готовыми компонентами поиска по таблицам. Один из них был очень похож на тот, который мы только что описали. Тем не менее, другой дает вам некоторое представление о том, что может быть предоставлено в виде повторно используемого кода, с немного большим воображением! Это довольно сложно, но это "черный ящик" многократно используемого кода, и я показываю его только для того, чтобы показать, что можно сделать с помощью одного компонента. Конечно, это нарушает некоторые из правил, которые мы дали выше, так что, возможно, это должно звучать предупреждающе! Однако, я думаю, вы согласитесь, что это по-прежнему "поточный" процесс, а не просто сложный алгоритм. По сути, он выполняет поиск в таблице, которая обновляется из какого-то резервного хранилища - неважно, какого типа, если другой процесс соответствует определенному протоколу. Таким образом, он действует как компонент поиска в таблице и как буферное устройство.
Вот картинка:
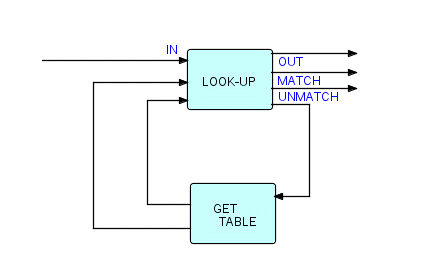
Фрагмент 6.14
Этот компонент поиска всегда работает с другим процессом (в данном случае называемым GET TABLE), который используется для доступа к файлу или базе данных прямого доступа. Эти два компонента работают вместе следующим образом:
- Верхний компонент строит таблицу, которая изначально пуста
- При поступлении каждого поискового запроса он сверяется с таблицей; если совпадение найдено, поисковый запрос выходит из состояния
OUT, а запись в таблице — из состоянияMATCH. - Если совпадение не найдено, запрос на поиск отправляется другому процессу, который либо найдет его, либо нет; если он находит его, поисковый запрос и найденная запись таблицы отправляются обратно в верхний компонент, чтобы соответственно быть отправлены на
OUTи добавлены в таблицу - Если не находит, то вместе с поисковым запросом на верхний компонент отправляется IP нулевой длины; IP нулевой длины говорит ему не добавлять запись в таблицу, и запрос на поиск отправляется в
UNMATCH
Это может показаться сложным, но после настройки этим очень легко пользоваться, и любой процесс может занимать "нижнее" положение при условии, что он ведет себя так, как описано. Этому компоненту DFDM ("верхнему" компоненту) требовалось всего 4 параметра, одним из которых было (необязательно) максимальное количество записей в таблице. Если бы этот предел был указан и был достигнут, записи начали бы удаляться из таблицы в последовательности FIFO. Другой возможностью могло быть использование последовательности LRU.
В этой главе мы попытались дать некоторое представление о том, что можно сделать, используя только повторно используемые компоненты. Конечно, их количество будет неуклонно расти, и, особенно если вы внесли некоторые организационные изменения, которые мы предложили в предыдущей главе, вы можете получить значительное количество полезных инструментов многократного использования. Мы не знаем, что это за число, но я предполагаю, что оно уменьшится до нескольких сотен. Их количество будет следовать кривой со следующей общей формой:
Фрагмент 6.15
Где менее часто используемые компоненты могут использоваться только в нескольких приложениях. При таком распределении вы можете задаться вопросом, стоит ли поддерживать редкоиспользуемые компоненты в отделе поддержки, или их следует сделать собственностью отделов, использующих их. Ответ будет зависеть от того, инкапсулированы ли в них специализированные знания, пытаетесь ли вы продать их вне компании и так далее.
Этот вид редко используемых компонентов имеет сходство с тем, что мы назвали "кастомными" компонентами. Пока весь код не будет готов (если это когда-нибудь случится), клиентам будет необходимо писать свои собственные компоненты. Это не так просто, как просто соединить повторно используемые компоненты, но это также довольно просто. В следующей главе я расскажу об идее составных компонентов, а затем в следующей главе начну обсуждение некоторых концепций построения систем путем объединения готовых и кастомных компонентов.