This project is a comparison of various activation functions on the MNIST dataset. We compared the performance of five different activation functions based on the accuracy, precision/recall, time, and number of epochs in their respective models.
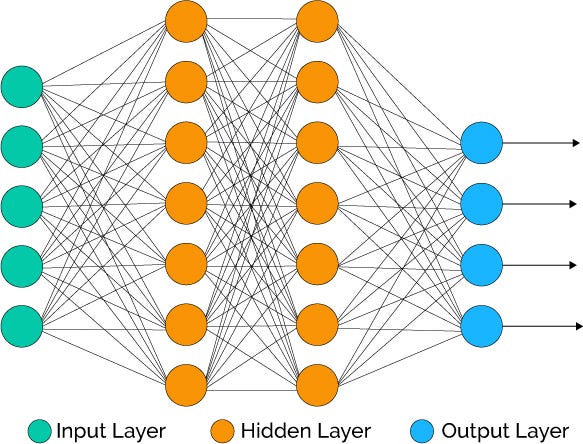
We utilized the same machine learning model for each experiment. We decided on a Feedforward Neural Network with 784 inputs (each pixel), 100 hidden units, and 10 outputs [0, 9].
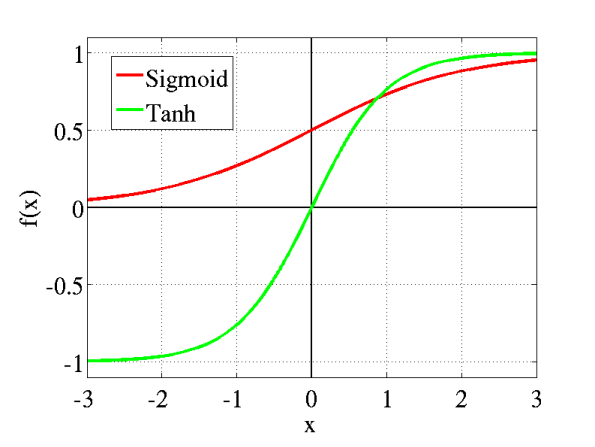
The downside to Signmoid/Tanh activation functions is that they are susceptible to the vanishing gradient problem which drastically slows down training, and is very sensitive to initial weights.
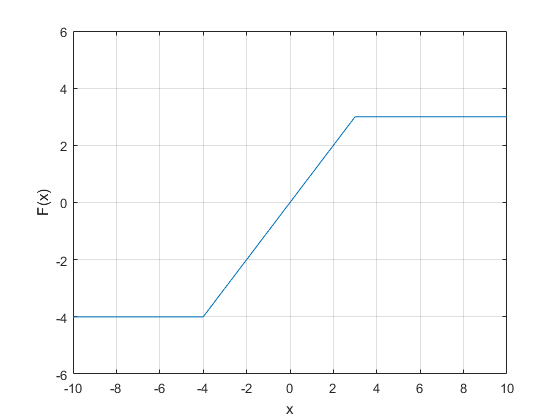
The ReLU activation function grows for positive values so for x >> 1 there's no vanishing gradient. This mean you can get faster training times. The downside is that you collect many dead neurons as the gradients go negative, additionally teh computation can explode as teh output is unbound.

This is essentially ReLU with an upper bound which stop the output explosion problem.
This function is ReLU with a small gradient below zero. This slope is controlled by a hyper parameter α. This fixes the dead neuron problem as there is now a gradient for outputs below zero.
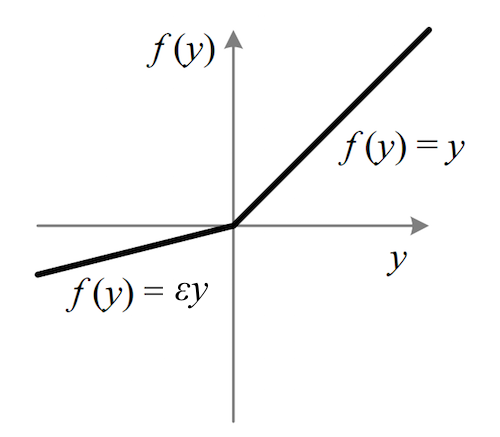
This is a control for our experiments, using a linear activation function is essentially the same as having no activation function.

| Model | Accuracy | Precision | Recall |
|---|---|---|---|
| (sigmoid) | 93.12% | 0.9786 | 0.9946 |
| (tanh) | 91.81% | 0.9776 | 0.9939 |
| (ReLU) | 93.80% | 0.9735 | 0.9953 |
| (satlin) | 92.86% | 0.9806 | 0.9945 |
| (Leaky ReLU, a=0.1) | 93.84% | 0.9786 | 0.9952 |
| (purelin/None) | 91.16% | 0.9684 | 0.9938 |


| Model | Accuracy | Precision | Recall |
|---|---|---|---|
| (sigmoid) | 93.12% | 0.9786 | 0.9946 |
| (tanh) | 91.81% | 0.9776 | 0.9939 |
| (ReLU) | 93.80% | 0.9735 | 0.9953 |
| (satlin) | 92.86% | 0.9806 | 0.9945 |
| (Leaky ReLU, a=0.1) | 93.84% | 0.9786 | 0.9952 |
| (purelin/None) | 91.16% | 0.9684 | 0.9938 |
