diff --git a/.github/PULL_REQUEST_TEMPLATE.md b/.github/PULL_REQUEST_TEMPLATE.md
index 183028b022..e8177cd9b7 100644
--- a/.github/PULL_REQUEST_TEMPLATE.md
+++ b/.github/PULL_REQUEST_TEMPLATE.md
@@ -10,6 +10,3 @@ Linked Issues:
Issues closed by this PR:
- Closes #
-**Before merging:**
-
-- [ ] Did you update the [flexflow-third-party](https://github.com/flexflow/flexflow-third-party) repo, if modifying any of the Cmake files, the build configs, or the submodules?
diff --git a/.github/README.md b/.github/README.md
new file mode 100644
index 0000000000..56434f6bf9
--- /dev/null
+++ b/.github/README.md
@@ -0,0 +1,230 @@
+# FlexFlow Serve: Low-Latency, High-Performance LLM Serving
+       [](https://flexflow.readthedocs.io/en/latest/?badge=latest)
+
+
+---
+
+## News🔥:
+
+* [08/16/2023] Adding Starcoder model support
+* [08/14/2023] Released Dockerfile for different CUDA versions
+
+## What is FlexFlow Serve
+
+The high computational and memory requirements of generative large language
+models (LLMs) make it challenging to serve them quickly and cheaply.
+FlexFlow Serve is an open-source compiler and distributed system for
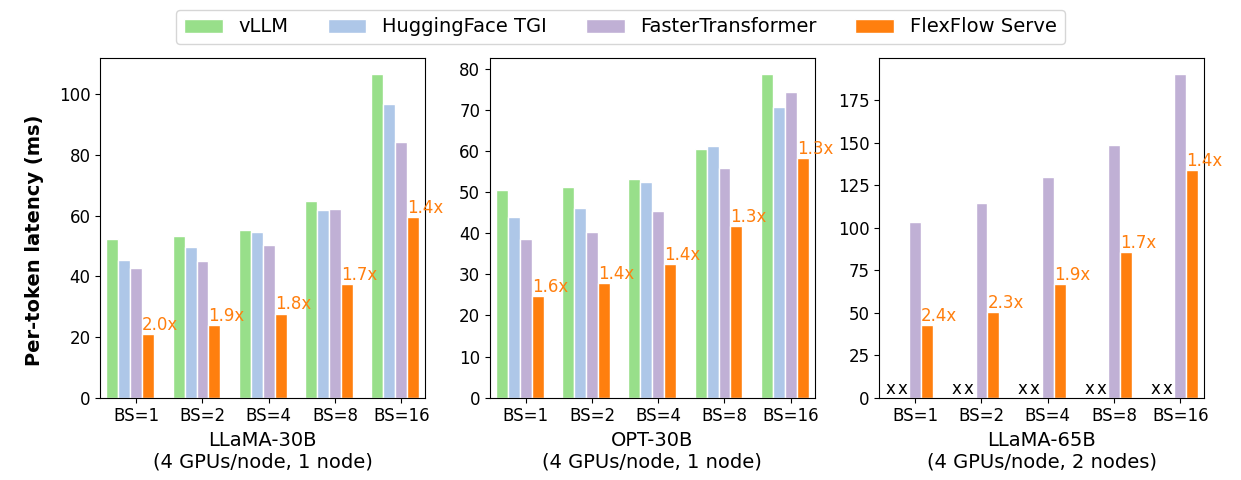
+__low latency__, __high performance__ LLM serving. FlexFlow Serve outperforms
+existing systems by 1.3-2.0x for single-node, multi-GPU inference and by
+1.4-2.4x for multi-node, multi-GPU inference.
+
+
+ +
+
+
+
+## Install FlexFlow Serve
+
+
+### Requirements
+* OS: Linux
+* GPU backend: Hip-ROCm or CUDA
+ * CUDA version: 10.2 – 12.0
+ * NVIDIA compute capability: 6.0 or higher
+* Python: 3.6 or higher
+* Package dependencies: [see here](https://github.com/flexflow/FlexFlow/blob/inference/requirements.txt)
+
+### Install with pip
+You can install FlexFlow Serve using pip:
+
+```bash
+pip install flexflow
+```
+
+### Try it in Docker
+If you run into any issue during the install, or if you would like to use the C++ API without needing to install from source, you can also use our pre-built Docker package for different CUDA versions and the `hip_rocm` backend. To download and run our pre-built Docker container:
+
+```bash
+docker run --gpus all -it --rm --shm-size=8g ghcr.io/flexflow/flexflow-cuda-11.8:latest
+```
+
+To download a Docker container for a backend other than CUDA v11.8, you can replace the `cuda-11.8` suffix with any of the following backends: `cuda-11.1`, `cuda-11.2`, `cuda-11.3`, `cuda-11.5`, `cuda-11.6`, `cuda-11.7`, `cuda-11.8`, and `hip_rocm`). More info on the Docker images, with instructions to build a new image from source, or run with additional configurations, can be found [here](../docker/README.md).
+
+### Build from source
+
+You can install FlexFlow Serve from source code by building the inference branch of FlexFlow. Please follow these [instructions](https://flexflow.readthedocs.io/en/latest/installation.html).
+
+## Quickstart
+The following example shows how to deploy an LLM using FlexFlow Serve and accelerate its serving using [speculative inference](#speculative-inference). First, we import `flexflow.serve` and initialize the FlexFlow Serve runtime. Note that `memory_per_gpu` and `zero_copy_memory_per_node` specify the size of device memory on each GPU (in MB) and zero-copy memory on each node (in MB), respectively.
+We need to make sure the aggregated GPU memory and zero-copy memory are **both** sufficient to store LLM parameters in non-offloading serving. FlexFlow Serve combines tensor and pipeline model parallelism for LLM serving.
+```python
+import flexflow.serve as ff
+
+ff.init(
+ num_gpus=4,
+ memory_per_gpu=14000,
+ zero_copy_memory_per_node=30000,
+ tensor_parallelism_degree=4,
+ pipeline_parallelism_degree=1
+ )
+```
+Second, we specify the LLM to serve and the SSM(s) used to accelerate LLM serving. The list of supported LLMs and SSMs is available at [supported models](#supported-llms-and-ssms).
+```python
+# Specify the LLM
+llm = ff.LLM("decapoda-research/llama-7b-hf")
+
+# Specify a list of SSMs (just one in this case)
+ssms=[]
+ssm = ff.SSM("JackFram/llama-68m")
+ssms.append(ssm)
+```
+Next, we declare the generation configuration and compile both the LLM and SSMs. Note that all SSMs should run in the **beam search** mode, and the LLM should run in the **tree verification** mode to verify the speculated tokens from SSMs.
+```python
+# Create the sampling configs
+generation_config = ff.GenerationConfig(
+ do_sample=False, temperature=0.9, topp=0.8, topk=1
+)
+
+# Compile the SSMs for inference and load the weights into memory
+for ssm in ssms:
+ ssm.compile(generation_config)
+
+# Compile the LLM for inference and load the weights into memory
+llm.compile(generation_config, ssms=ssms)
+```
+Finally, we call `llm.generate` to generate the output, which is organized as a list of `GenerationResult`, which include the output tokens and text.
+```python
+result = llm.generate("Here are some travel tips for Tokyo:\n")
+```
+
+### Incremental decoding
+
+Expand here
+
+
+```python
+import flexflow.serve as ff
+
+# Initialize the FlexFlow runtime. ff.init() takes a dictionary or the path to a JSON file with the configs
+ff.init(
+ num_gpus=4,
+ memory_per_gpu=14000,
+ zero_copy_memory_per_node=30000,
+ tensor_parallelism_degree=4,
+ pipeline_parallelism_degree=1
+ )
+
+# Create the FlexFlow LLM
+llm = ff.LLM("decapoda-research/llama-7b-hf")
+
+# Create the sampling configs
+generation_config = ff.GenerationConfig(
+ do_sample=True, temperature=0.9, topp=0.8, topk=1
+)
+
+# Compile the LLM for inference and load the weights into memory
+llm.compile(generation_config)
+
+# Generation begins!
+result = llm.generate("Here are some travel tips for Tokyo:\n")
+```
+
+
+
+### C++ interface
+If you'd like to use the C++ interface (mostly used for development and benchmarking purposes), you should install from source, and follow the instructions below.
+
+
+Expand here
+
+
+#### Downloading models
+Before running FlexFlow Serve, you should manually download the LLM and SSM(s) model of interest using the [inference/utils/download_hf_model.py](https://github.com/flexflow/FlexFlow/blob/inference/inference/utils/download_hf_model.py) script (see example below). By default, the script will download all of a model's assets (weights, configs, tokenizer files, etc...) into the cache folder `~/.cache/flexflow`. If you would like to use a different folder, you can request that via the parameter `--cache-folder`.
+
+```bash
+python3 ./inference/utils/download_hf_model.py ...
+```
+
+#### Running the C++ examples
+A C++ example is available at [this folder](../inference/spec_infer/). After building FlexFlow Serve, the executable will be available at `/build_dir/inference/spec_infer/spec_infer`. You can use the following command-line arguments to run FlexFlow Serve:
+
+* `-ll:gpu`: number of GPU processors to use on each node for serving an LLM (default: 0)
+* `-ll:fsize`: size of device memory on each GPU in MB
+* `-ll:zsize`: size of zero-copy memory (pinned DRAM with direct GPU access) in MB. FlexFlow Serve keeps a replica of the LLM parameters on zero-copy memory, and therefore requires that the zero-copy memory is sufficient for storing the LLM parameters.
+* `-llm-model`: the LLM model ID from HuggingFace (e.g. "decapoda-research/llama-7b-hf")
+* `-ssm-model`: the SSM model ID from HuggingFace (e.g. "JackFram/llama-160m"). You can use multiple `-ssm-model`s in the command line to launch multiple SSMs.
+* `-cache-folder`: the folder
+* `-data-parallelism-degree`, `-tensor-parallelism-degree` and `-pipeline-parallelism-degree`: parallelization degrees in the data, tensor, and pipeline dimensions. Their product must equal the number of GPUs available on the machine. When any of the three parallelism degree arguments is omitted, a default value of 1 will be used.
+* `-prompt`: (optional) path to the prompt file. FlexFlow Serve expects a json format file for prompts. In addition, users can also use the following API for registering requests:
+* `-output-file`: (optional) filepath to use to save the output of the model, together with the generation latency
+
+For example, you can use the following command line to serve a LLaMA-7B or LLaMA-13B model on 4 GPUs and use two collectively boost-tuned LLaMA-68M models for speculative inference.
+
+```bash
+./inference/spec_infer/spec_infer -ll:gpu 4 -ll:fsize 14000 -ll:zsize 30000 -llm-model decapoda-research/llama-7b-hf -ssm-model JackFram/llama-68m -prompt /path/to/prompt.json -tensor-parallelism-degree 4 --fusion
+```
+
+
+## Speculative Inference
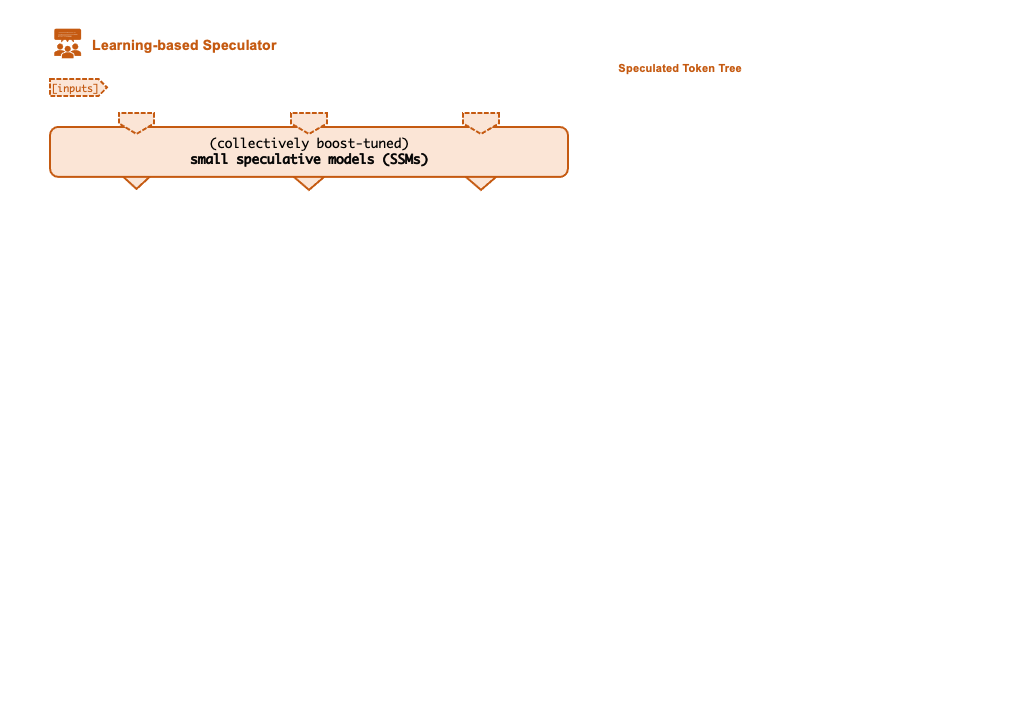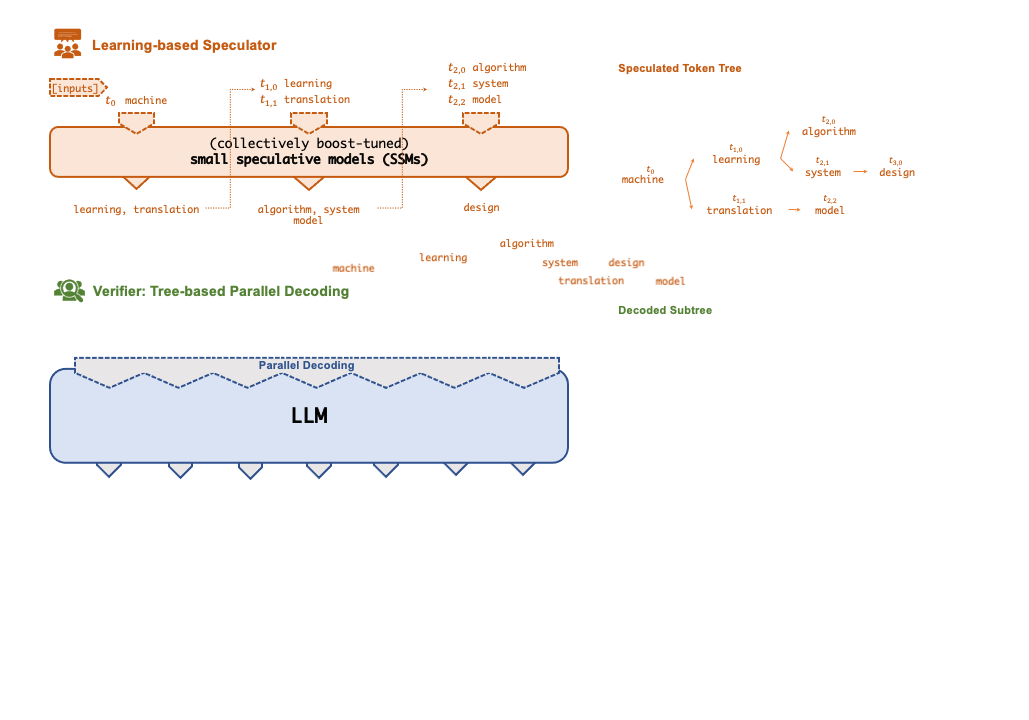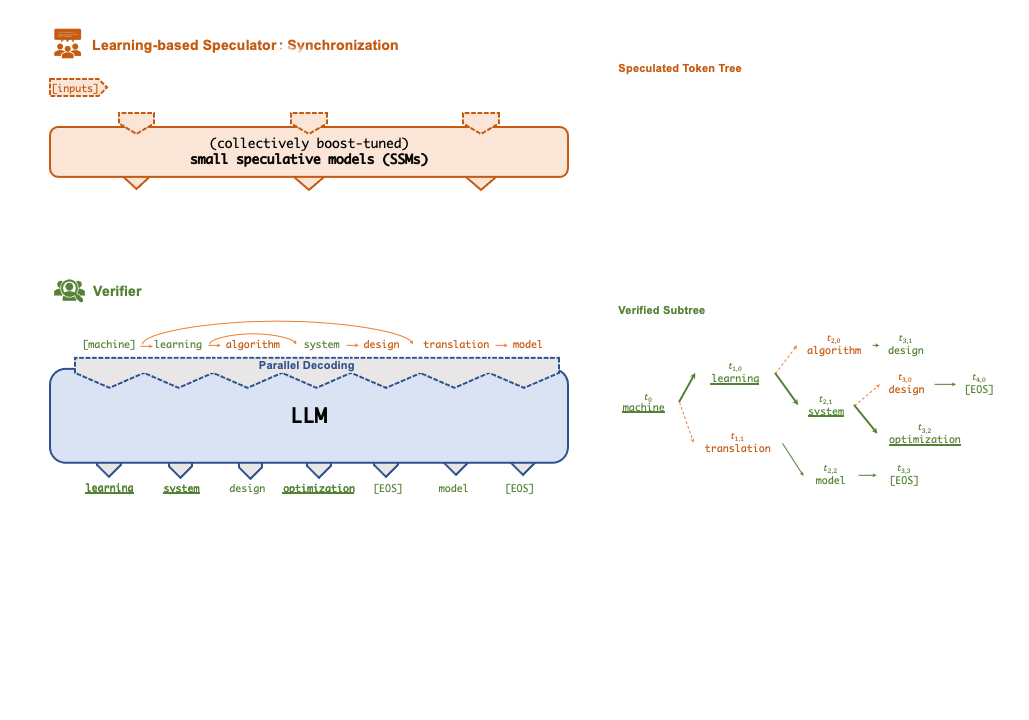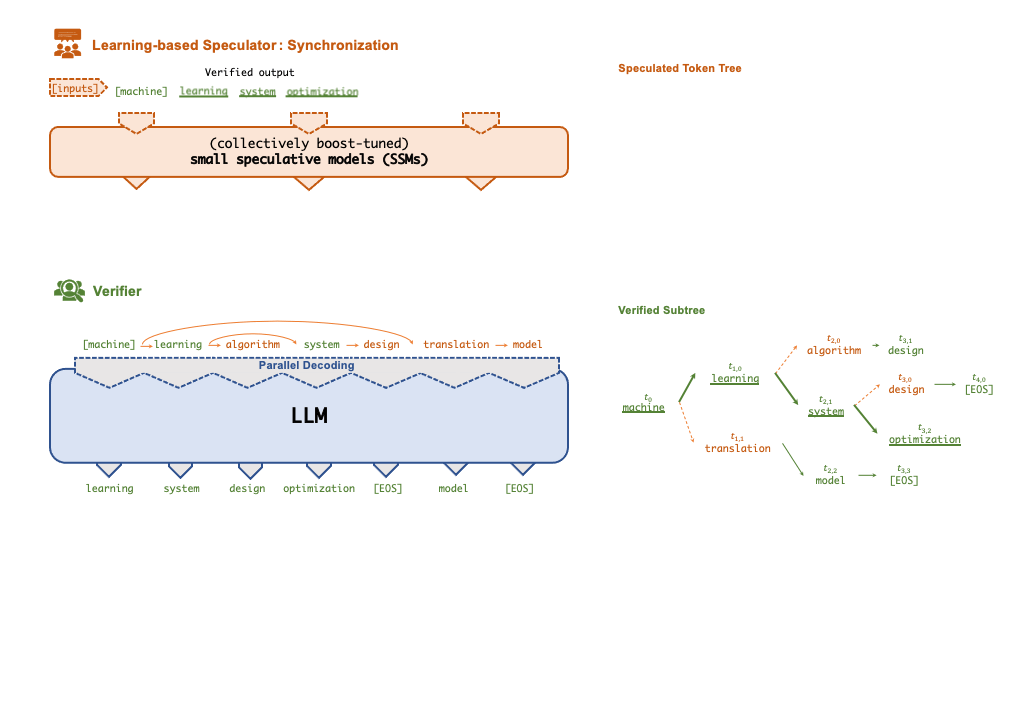
+A key technique that enables FlexFlow Serve to accelerate LLM serving is speculative
+inference, which combines various collectively boost-tuned small speculative
+models (SSMs) to jointly predict the LLM’s outputs; the predictions are organized as a
+token tree, whose nodes each represent a candidate token sequence. The correctness
+of all candidate token sequences represented by a token tree is verified against the
+LLM’s output in parallel using a novel tree-based parallel decoding mechanism.
+FlexFlow Serve uses an LLM as a token tree verifier instead of an incremental decoder,
+which largely reduces the end-to-end inference latency and computational requirement
+for serving generative LLMs while provably preserving model quality.
+
+
+ +
+
+
+### Supported LLMs and SSMs
+
+FlexFlow Serve currently supports all HuggingFace models with the following architectures:
+* `LlamaForCausalLM` / `LLaMAForCausalLM` (e.g. LLaMA/LLaMA-2, Guanaco, Vicuna, Alpaca, ...)
+* `OPTForCausalLM` (models from the OPT family)
+* `RWForCausalLM` (models from the Falcon family)
+* `GPTBigCodeForCausalLM` (models from the Starcoder family)
+
+Below is a list of models that we have explicitly tested and for which a SSM may be available:
+
+| Model | Model id on HuggingFace | Boost-tuned SSMs |
+| :---- | :---- | :---- |
+| LLaMA-7B | decapoda-research/llama-7b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-13B | decapoda-research/llama-13b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-30B | decapoda-research/llama-30b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-65B | decapoda-research/llama-65b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-2-7B | meta-llama/Llama-2-7b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-2-13B | meta-llama/Llama-2-13b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-2-70B | meta-llama/Llama-2-70b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| OPT-6.7B | facebook/opt-6.7b | [OPT-125M](https://huggingface.co/facebook/opt-125m) |
+| OPT-13B | facebook/opt-13b | [OPT-125M](https://huggingface.co/facebook/opt-125m) |
+| OPT-30B | facebook/opt-30b | [OPT-125M](https://huggingface.co/facebook/opt-125m) |
+| OPT-66B | facebook/opt-66b | [OPT-125M](https://huggingface.co/facebook/opt-125m) |
+| Falcon-7B | tiiuae/falcon-7b | |
+| Falcon-40B | tiiuae/falcon-40b | |
+| StarCoder-7B | bigcode/starcoderbase-7b | |
+| StarCoder-15.5B | bigcode/starcoder | |
+
+### CPU Offloading
+FlexFlow Serve also offers offloading-based inference for running large models (e.g., llama-7B) on a single GPU. CPU offloading is a choice to save tensors in CPU memory, and only copy the tensor to GPU when doing calculation. Notice that now we selectively offload the largest weight tensors (weights tensor in Linear, Attention). Besides, since the small model occupies considerably less space, it it does not pose a bottleneck for GPU memory, the offloading will bring more runtime space and computational cost, so we only do the offloading for the large model. You can run the offloading example by enabling the `-offload` and `-offload-reserve-space-size` flags.
+
+### Quantization
+FlexFlow Serve supports int4 and int8 quantization. The compressed tensors are stored on the CPU side. Once copied to the GPU, these tensors undergo decompression and conversion back to their original precision. Please find the compressed weight files in our s3 bucket, or use [this script](../inference/utils/compress_llama_weights.py) from [FlexGen](https://github.com/FMInference/FlexGen) project to do the compression manually.
+
+### Prompt Datasets
+We provide five prompt datasets for evaluating FlexFlow Serve: [Chatbot instruction prompts](https://specinfer.s3.us-east-2.amazonaws.com/prompts/chatbot.json), [ChatGPT Prompts](https://specinfer.s3.us-east-2.amazonaws.com/prompts/chatgpt.json), [WebQA](https://specinfer.s3.us-east-2.amazonaws.com/prompts/webqa.json), [Alpaca](https://specinfer.s3.us-east-2.amazonaws.com/prompts/alpaca.json), and [PIQA](https://specinfer.s3.us-east-2.amazonaws.com/prompts/piqa.json).
+
+## TODOs
+
+FlexFlow Serve is under active development. We currently focus on the following tasks and strongly welcome all contributions from bug fixes to new features and extensions.
+
+* AMD support. We are actively working on supporting FlexFlow Serve on AMD GPUs and welcome any contributions to this effort.
+
+## Acknowledgements
+This project is initiated by members from CMU, Stanford, and UCSD. We will be continuing developing and supporting FlexFlow Serve.
+
+## License
+FlexFlow uses Apache License 2.0.
diff --git a/.github/workflows/build-skip.yml b/.github/workflows/build-skip.yml
index b3ab69e9c1..8635c0d137 100644
--- a/.github/workflows/build-skip.yml
+++ b/.github/workflows/build-skip.yml
@@ -3,6 +3,7 @@ on:
pull_request:
paths-ignore:
- "include/**"
+ - "inference/**"
- "cmake/**"
- "config/**"
- "deps/**"
diff --git a/.github/workflows/build.yml b/.github/workflows/build.yml
index 1e7081a613..4e457ada1b 100644
--- a/.github/workflows/build.yml
+++ b/.github/workflows/build.yml
@@ -3,6 +3,7 @@ on:
pull_request:
paths:
- "include/**"
+ - "inference/**"
- "cmake/**"
- "config/**"
- "deps/**"
@@ -15,6 +16,7 @@ on:
- "master"
paths:
- "include/**"
+ - "inference/**"
- "cmake/**"
- "config/**"
- "deps/**"
@@ -146,6 +148,8 @@ jobs:
matrix:
gpu_backend: ["cuda", "hip_rocm"]
fail-fast: false
+ env:
+ FF_GPU_BACKEND: ${{ matrix.gpu_backend }}
steps:
- name: Checkout Git Repository
uses: actions/checkout@v3
@@ -157,6 +161,7 @@ jobs:
- name: Install CUDA
uses: Jimver/cuda-toolkit@v0.2.11
+ if: ${{ matrix.gpu_backend == 'cuda' }}
id: cuda-toolkit
with:
cuda: "11.8.0"
@@ -164,7 +169,7 @@ jobs:
use-github-cache: "false"
- name: Install system dependencies
- run: FF_GPU_BACKEND=${{ matrix.gpu_backend }} .github/workflows/helpers/install_dependencies.sh
+ run: .github/workflows/helpers/install_dependencies.sh
- name: Install conda and FlexFlow dependencies
uses: conda-incubator/setup-miniconda@v2
@@ -178,17 +183,25 @@ jobs:
export CUDNN_DIR="$CUDA_PATH"
export CUDA_DIR="$CUDA_PATH"
export FF_HOME=$(pwd)
- export FF_GPU_BACKEND=${{ matrix.gpu_backend }}
export FF_CUDA_ARCH=70
+ export FF_HIP_ARCH=gfx1100,gfx1036
+ export hip_version=5.6
+ export FF_BUILD_ALL_INFERENCE_EXAMPLES=ON
+
+ if [[ "${FF_GPU_BACKEND}" == "cuda" ]]; then
+ export FF_BUILD_ALL_EXAMPLES=ON
+ export FF_BUILD_UNIT_TESTS=ON
+ else
+ export FF_BUILD_ALL_EXAMPLES=OFF
+ export FF_BUILD_UNIT_TESTS=OFF
+ fi
+
cores_available=$(nproc --all)
n_build_cores=$(( cores_available -1 ))
if (( $n_build_cores < 1 )) ; then n_build_cores=1 ; fi
mkdir build
cd build
- if [[ "${FF_GPU_BACKEND}" == "cuda" ]]; then
- export FF_BUILD_ALL_EXAMPLES=ON
- export FF_BUILD_UNIT_TESTS=ON
- fi
+
../config/config.linux
make -j $n_build_cores
@@ -197,25 +210,24 @@ jobs:
export CUDNN_DIR="$CUDA_PATH"
export CUDA_DIR="$CUDA_PATH"
export FF_HOME=$(pwd)
- export FF_GPU_BACKEND=${{ matrix.gpu_backend }}
export FF_CUDA_ARCH=70
- cd build
+ export FF_HIP_ARCH=gfx1100,gfx1036
+ export hip_version=5.6
+ export FF_BUILD_ALL_INFERENCE_EXAMPLES=ON
+
if [[ "${FF_GPU_BACKEND}" == "cuda" ]]; then
- export FF_BUILD_ALL_EXAMPLES=ON
+ export FF_BUILD_ALL_EXAMPLES=ON
export FF_BUILD_UNIT_TESTS=ON
+ else
+ export FF_BUILD_ALL_EXAMPLES=OFF
+ export FF_BUILD_UNIT_TESTS=OFF
fi
+
+ cd build
../config/config.linux
sudo make install
sudo ldconfig
- - name: Check availability of Python flexflow.core module
- if: ${{ matrix.gpu_backend == 'cuda' }}
- run: |
- export LD_LIBRARY_PATH="$CUDA_PATH/lib64/stubs:$LD_LIBRARY_PATH"
- sudo ln -s "$CUDA_PATH/lib64/stubs/libcuda.so" "$CUDA_PATH/lib64/stubs/libcuda.so.1"
- export CPU_ONLY_TEST=1
- python -c "import flexflow.core; exit()"
-
- name: Run C++ unit tests
if: ${{ matrix.gpu_backend == 'cuda' }}
run: |
@@ -223,9 +235,20 @@ jobs:
export CUDA_DIR="$CUDA_PATH"
export LD_LIBRARY_PATH="$CUDA_PATH/lib64/stubs:$LD_LIBRARY_PATH"
export FF_HOME=$(pwd)
+ sudo ln -s "$CUDA_PATH/lib64/stubs/libcuda.so" "$CUDA_PATH/lib64/stubs/libcuda.so.1"
cd build
./tests/unit/unit-test
+ - name: Check availability of Python flexflow.core module
+ run: |
+ if [[ "${FF_GPU_BACKEND}" == "cuda" ]]; then
+ export LD_LIBRARY_PATH="$CUDA_PATH/lib64/stubs:$LD_LIBRARY_PATH"
+ fi
+ # Remove build folder to check that the installed version can run independently of the build files
+ rm -rf build
+ export CPU_ONLY_TEST=1
+ python -c "import flexflow.core; exit()"
+
makefile-build:
name: Build FlexFlow with the Makefile
runs-on: ubuntu-20.04
diff --git a/.github/workflows/clang-format-check.yml b/.github/workflows/clang-format-check.yml
index 46c9bf3be2..1601da86b3 100644
--- a/.github/workflows/clang-format-check.yml
+++ b/.github/workflows/clang-format-check.yml
@@ -10,6 +10,7 @@ jobs:
- check: "src"
exclude: '\.proto$'
- check: "include"
+ - check: "inference"
- check: "nmt"
- check: "python"
- check: "scripts"
diff --git a/.github/workflows/docker-build.yml b/.github/workflows/docker-build.yml
index d059a0605f..b0ca251510 100644
--- a/.github/workflows/docker-build.yml
+++ b/.github/workflows/docker-build.yml
@@ -7,6 +7,7 @@ on:
- ".github/workflows/docker-build.yml"
push:
branches:
+ - "inference"
- "master"
schedule:
# Run every week on Sunday at midnight PT (3am ET / 8am UTC) to keep the docker images updated
@@ -25,25 +26,42 @@ jobs:
strategy:
matrix:
gpu_backend: ["cuda", "hip_rocm"]
- cuda_version: ["11.1", "11.2", "11.3", "11.5", "11.6", "11.7", "11.8"]
+ gpu_backend_version: ["11.1", "11.2", "11.3", "11.4", "11.5", "11.6", "11.7", "11.8", "12.0", "5.3", "5.4", "5.5", "5.6"]
# The CUDA version doesn't matter when building for hip_rocm, so we just pick one arbitrarily (11.8) to avoid building for hip_rocm once per number of CUDA version supported
exclude:
+ - gpu_backend: "cuda"
+ gpu_backend_version: "5.3"
+ - gpu_backend: "cuda"
+ gpu_backend_version: "5.4"
+ - gpu_backend: "cuda"
+ gpu_backend_version: "5.5"
+ - gpu_backend: "cuda"
+ gpu_backend_version: "5.6"
- gpu_backend: "hip_rocm"
- cuda_version: "11.1"
+ gpu_backend_version: "11.1"
- gpu_backend: "hip_rocm"
- cuda_version: "11.2"
+ gpu_backend_version: "11.2"
- gpu_backend: "hip_rocm"
- cuda_version: "11.3"
+ gpu_backend_version: "11.3"
- gpu_backend: "hip_rocm"
- cuda_version: "11.5"
+ gpu_backend_version: "11.4"
- gpu_backend: "hip_rocm"
- cuda_version: "11.6"
+ gpu_backend_version: "11.5"
- gpu_backend: "hip_rocm"
- cuda_version: "11.7"
+ gpu_backend_version: "11.6"
+ - gpu_backend: "hip_rocm"
+ gpu_backend_version: "11.7"
+ - gpu_backend: "hip_rocm"
+ gpu_backend_version: "11.8"
+ - gpu_backend: "hip_rocm"
+ gpu_backend_version: "12.0"
fail-fast: false
env:
FF_GPU_BACKEND: ${{ matrix.gpu_backend }}
- cuda_version: ${{ matrix.cuda_version }}
+ gpu_backend_version: ${{ matrix.gpu_backend_version }}
+ # one of the two variables below will be unused
+ cuda_version: ${{ matrix.gpu_backend_version }}
+ hip_version: ${{ matrix.gpu_backend_version }}
branch_name: ${{ github.head_ref || github.ref_name }}
steps:
- name: Checkout Git Repository
@@ -53,8 +71,8 @@ jobs:
- name: Free additional space on runner
env:
- deploy_needed: ${{ ( github.event_name == 'push' || github.event_name == 'schedule' ) && env.branch_name == 'inference' }}
- build_needed: ${{ matrix.gpu_backend == 'hip_rocm' || ( matrix.gpu_backend == 'cuda' && matrix.cuda_version == '11.8' ) }}
+ deploy_needed: ${{ ( github.event_name == 'push' || github.event_name == 'schedule' || github.event_name == 'workflow_dispatch' ) && env.branch_name == 'inference' }}
+ build_needed: ${{ ( matrix.gpu_backend == 'hip_rocm' && matrix.gpu_backend_version == '5.6' ) || ( matrix.gpu_backend == 'cuda' && matrix.gpu_backend_version == '11.8' ) }}
run: |
if [[ $deploy_needed == "true" || $build_needed == "true" ]]; then
.github/workflows/helpers/free_space_on_runner.sh
@@ -64,17 +82,19 @@ jobs:
- name: Build Docker container
env:
- deploy_needed: ${{ ( github.event_name == 'push' || github.event_name == 'schedule' ) && env.branch_name == 'inference' }}
- build_needed: ${{ matrix.gpu_backend == 'hip_rocm' || ( matrix.gpu_backend == 'cuda' && matrix.cuda_version == '11.8' ) }}
+ deploy_needed: ${{ ( github.event_name == 'push' || github.event_name == 'schedule' || github.event_name == 'workflow_dispatch' ) && env.branch_name == 'inference' }}
+ build_needed: ${{ ( matrix.gpu_backend == 'hip_rocm' && matrix.gpu_backend_version == '5.6' ) || ( matrix.gpu_backend == 'cuda' && matrix.gpu_backend_version == '11.8' ) }}
run: |
# On push to inference, build for all compatible architectures, so that we can publish
# a pre-built general-purpose image. On all other cases, only build for one architecture
# to save time.
if [[ $deploy_needed == "true" ]] ; then
export FF_CUDA_ARCH=all
+ export FF_HIP_ARCH=all
./docker/build.sh flexflow
elif [[ $build_needed == "true" ]]; then
export FF_CUDA_ARCH=70
+ export FF_HIP_ARCH=gfx1100,gfx1036
./docker/build.sh flexflow
else
echo "Skipping build to save time"
@@ -83,11 +103,15 @@ jobs:
- name: Check availability of Python flexflow.core module
if: ${{ matrix.gpu_backend == 'cuda' }}
env:
- deploy_needed: ${{ ( github.event_name == 'push' || github.event_name == 'schedule' ) && env.branch_name == 'inference' }}
- build_needed: ${{ matrix.gpu_backend == 'hip_rocm' || ( matrix.gpu_backend == 'cuda' && matrix.cuda_version == '11.8' ) }}
+ deploy_needed: ${{ ( github.event_name == 'push' || github.event_name == 'schedule' || github.event_name == 'workflow_dispatch' ) && env.branch_name == 'inference' }}
+ build_needed: ${{ ( matrix.gpu_backend == 'hip_rocm' && matrix.gpu_backend_version == '5.6' ) || ( matrix.gpu_backend == 'cuda' && matrix.gpu_backend_version == '11.8' ) }}
run: |
if [[ $deploy_needed == "true" || $build_needed == "true" ]]; then
- docker run --env CPU_ONLY_TEST=1 --entrypoint /bin/bash flexflow-cuda-${cuda_version}:latest -c "export LD_LIBRARY_PATH=/usr/local/cuda/lib64/stubs:$LD_LIBRARY_PATH; sudo ln -s /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/stubs/libcuda.so.1; python -c 'import flexflow.core; exit()'"
+ if [[ $FF_GPU_BACKEND == "cuda" ]]; then
+ docker run --env CPU_ONLY_TEST=1 --entrypoint /bin/bash flexflow-${FF_GPU_BACKEND}-${gpu_backend_version}:latest -c "export LD_LIBRARY_PATH=/usr/local/cuda/lib64/stubs:$LD_LIBRARY_PATH; sudo ln -s /usr/local/cuda/lib64/stubs/libcuda.so /usr/local/cuda/lib64/stubs/libcuda.so.1; python -c 'import flexflow.core; exit()'"
+ else
+ docker run --env CPU_ONLY_TEST=1 --entrypoint /bin/bash flexflow-${FF_GPU_BACKEND}-${gpu_backend_version}:latest -c "python -c 'import flexflow.core; exit()'"
+ fi
else
echo "Skipping test to save time"
fi
@@ -96,7 +120,7 @@ jobs:
if: github.repository_owner == 'flexflow'
env:
FLEXFLOW_CONTAINER_TOKEN: ${{ secrets.FLEXFLOW_CONTAINER_TOKEN }}
- deploy_needed: ${{ ( github.event_name == 'push' || github.event_name == 'schedule' ) && env.branch_name == 'inference' }}
+ deploy_needed: ${{ ( github.event_name == 'push' || github.event_name == 'schedule' || github.event_name == 'workflow_dispatch' ) && env.branch_name == 'inference' }}
run: |
if [[ $deploy_needed == "true" ]]; then
./docker/publish.sh flexflow-environment
diff --git a/.github/workflows/gpu-ci-skip.yml b/.github/workflows/gpu-ci-skip.yml
index 157f3c271a..6a18e56bd1 100644
--- a/.github/workflows/gpu-ci-skip.yml
+++ b/.github/workflows/gpu-ci-skip.yml
@@ -8,9 +8,15 @@ on:
- "python/**"
- "setup.py"
- "include/**"
+ - "inference/**"
- "src/**"
+ - "tests/inference/**"
+ - "conda/flexflow.yml"
- ".github/workflows/gpu-ci.yml"
+ - "tests/cpp_gpu_tests.sh"
+ - "tests/inference_tests.sh"
- "tests/multi_gpu_tests.sh"
+ - "tests/python_interface_test.sh"
workflow_dispatch:
concurrency:
@@ -30,10 +36,18 @@ jobs:
needs: gpu-ci-concierge
steps:
- run: 'echo "No gpu-ci required"'
+
+ inference-tests:
+ name: Inference Tests
+ runs-on: ubuntu-20.04
+ needs: gpu-ci-concierge
+ steps:
+ - run: 'echo "No gpu-ci required"'
gpu-ci-flexflow:
name: Single Machine, Multiple GPUs Tests
runs-on: ubuntu-20.04
- needs: gpu-ci-concierge
+ # if: ${{ github.event_name != 'pull_request' || github.base_ref != 'inference' }}
+ needs: inference-tests
steps:
- run: 'echo "No gpu-ci required"'
diff --git a/.github/workflows/gpu-ci.yml b/.github/workflows/gpu-ci.yml
index 3b679e9f20..d604a7cea9 100644
--- a/.github/workflows/gpu-ci.yml
+++ b/.github/workflows/gpu-ci.yml
@@ -8,9 +8,13 @@ on:
- "python/**"
- "setup.py"
- "include/**"
+ - "inference/**"
- "src/**"
+ - "tests/inference/**"
+ - "conda/flexflow.yml"
- ".github/workflows/gpu-ci.yml"
- "tests/cpp_gpu_tests.sh"
+ - "tests/inference_tests.sh"
- "tests/multi_gpu_tests.sh"
- "tests/python_interface_test.sh"
push:
@@ -23,9 +27,13 @@ on:
- "python/**"
- "setup.py"
- "include/**"
+ - "inference/**"
- "src/**"
+ - "tests/inference/**"
+ - "conda/flexflow.yml"
- ".github/workflows/gpu-ci.yml"
- "tests/cpp_gpu_tests.sh"
+ - "tests/inference_tests.sh"
- "tests/multi_gpu_tests.sh"
- "tests/python_interface_test.sh"
workflow_dispatch:
@@ -77,7 +85,7 @@ jobs:
with:
miniconda-version: "latest"
activate-environment: flexflow
- environment-file: conda/flexflow-cpu.yml
+ environment-file: conda/flexflow.yml
auto-activate-base: false
auto-update-conda: false
@@ -89,7 +97,7 @@ jobs:
run: |
export PATH=$CONDA_PREFIX/bin:$PATH
export FF_HOME=$(pwd)
- export FF_USE_PREBUILT_LEGION=OFF
+ export FF_USE_PREBUILT_LEGION=OFF #remove this after fixing python path issue in Legion
mkdir build
cd build
../config/config.linux
@@ -106,6 +114,7 @@ jobs:
run: |
export PATH=$CONDA_PREFIX/bin:$PATH
export FF_HOME=$(pwd)
+ export FF_USE_PREBUILT_LEGION=OFF #remove this after fixing python path issue in Legion
cd build
../config/config.linux
make install
@@ -124,27 +133,119 @@ jobs:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CONDA_PREFIX/lib
./tests/align/test_all_operators.sh
+ inference-tests:
+ name: Inference Tests
+ runs-on: self-hosted
+ defaults:
+ run:
+ shell: bash -l {0} # required to use an activated conda environment
+ env:
+ CONDA: "3"
+ needs: gpu-ci-concierge
+ container:
+ image: ghcr.io/flexflow/flexflow-environment-cuda-11.8:latest
+ options: --gpus all --shm-size=8192m
+ steps:
+ - name: Install updated git version
+ run: sudo add-apt-repository ppa:git-core/ppa -y && sudo apt update -y && sudo apt install -y --no-install-recommends git
+
+ - name: Checkout Git Repository
+ uses: actions/checkout@v3
+ with:
+ submodules: recursive
+
+ - name: Install conda and FlexFlow dependencies
+ uses: conda-incubator/setup-miniconda@v2
+ with:
+ miniconda-version: "latest"
+ activate-environment: flexflow
+ environment-file: conda/flexflow.yml
+ auto-activate-base: false
+
+ - name: Build FlexFlow
+ run: |
+ export PATH=$CONDA_PREFIX/bin:$PATH
+ export FF_HOME=$(pwd)
+ export FF_USE_PREBUILT_LEGION=OFF #remove this after fixing python path issue in Legion
+ export FF_BUILD_ALL_INFERENCE_EXAMPLES=ON
+ mkdir build
+ cd build
+ ../config/config.linux
+ make -j
+
+ - name: Run inference tests
+ env:
+ CPP_INFERENCE_TESTS: ${{ vars.CPP_INFERENCE_TESTS }}
+ run: |
+ export PATH=$CONDA_PREFIX/bin:$PATH
+ export FF_HOME=$(pwd)
+ export CUDNN_DIR=/usr/local/cuda
+ export CUDA_DIR=/usr/local/cuda
+ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$CONDA_PREFIX/lib
+
+ # GPT tokenizer test
+ ./tests/gpt_tokenizer_test.sh
+
+ # Inference tests
+ source ./build/set_python_envs.sh
+ ./tests/inference_tests.sh
+
+ - name: Save inference output as an artifact
+ if: always()
+ run: |
+ cd inference
+ tar -zcvf output.tar.gz ./output
+
+ - name: Upload artifact
+ uses: actions/upload-artifact@v3
+ if: always()
+ with:
+ name: output
+ path: inference/output.tar.gz
+
+ # Github persists the .cache folder across different runs/containers
+ - name: Clear cache
+ if: always()
+ run: sudo rm -rf ~/.cache
+
gpu-ci-flexflow:
name: Single Machine, Multiple GPUs Tests
runs-on: self-hosted
- needs: python-interface-check
+ # skip this time-consuming test for PRs to the inference branch
+ # if: ${{ github.event_name != 'pull_request' || github.base_ref != 'inference' }}
+ defaults:
+ run:
+ shell: bash -l {0} # required to use an activated conda environment
+ env:
+ CONDA: "3"
+ needs: inference-tests
container:
- image: ghcr.io/flexflow/flexflow-environment-cuda-11.8:latest
+ image: ghcr.io/flexflow/flexflow-environment-cuda:latest
options: --gpus all --shm-size=8192m
steps:
- name: Install updated git version
run: sudo add-apt-repository ppa:git-core/ppa -y && sudo apt update -y && sudo apt install -y --no-install-recommends git
+
- name: Checkout Git Repository
uses: actions/checkout@v3
with:
submodules: recursive
+
+ - name: Install conda and FlexFlow dependencies
+ uses: conda-incubator/setup-miniconda@v2
+ with:
+ miniconda-version: "latest"
+ activate-environment: flexflow
+ environment-file: conda/flexflow.yml
+ auto-activate-base: false
- name: Build and Install FlexFlow
run: |
export PATH=/opt/conda/bin:$PATH
export FF_HOME=$(pwd)
export FF_BUILD_ALL_EXAMPLES=ON
- export FF_USE_PREBUILT_LEGION=OFF
+ export FF_BUILD_ALL_INFERENCE_EXAMPLES=ON
+ export FF_USE_PREBUILT_LEGION=OFF #remove this after fixing python path issue in Legion
pip install . --verbose
- name: Check FlexFlow Python interface (pip)
diff --git a/.github/workflows/helpers/install_cudnn.sh b/.github/workflows/helpers/install_cudnn.sh
index 318134e331..75e59109eb 100755
--- a/.github/workflows/helpers/install_cudnn.sh
+++ b/.github/workflows/helpers/install_cudnn.sh
@@ -44,6 +44,9 @@ elif [[ "$cuda_version" == "11.7" ]]; then
elif [[ "$cuda_version" == "11.8" ]]; then
CUDNN_LINK=https://developer.download.nvidia.com/compute/redist/cudnn/v8.7.0/local_installers/11.8/cudnn-linux-x86_64-8.7.0.84_cuda11-archive.tar.xz
CUDNN_TARBALL_NAME=cudnn-linux-x86_64-8.7.0.84_cuda11-archive.tar.xz
+elif [[ "$cuda_version" == "11.8" ]]; then
+ echo "CUDNN support for CUDA version 12.0 not yet added"
+ exit 1
fi
wget -c -q $CUDNN_LINK
if [[ "$cuda_version" == "11.6" || "$cuda_version" == "11.7" || "$cuda_version" == "11.8" ]]; then
diff --git a/.github/workflows/helpers/install_dependencies.sh b/.github/workflows/helpers/install_dependencies.sh
index 5ab211c962..1357882b5d 100755
--- a/.github/workflows/helpers/install_dependencies.sh
+++ b/.github/workflows/helpers/install_dependencies.sh
@@ -10,21 +10,56 @@ echo "Installing apt dependencies..."
sudo apt-get update && sudo apt-get install -y --no-install-recommends wget binutils git zlib1g-dev libhdf5-dev && \
sudo rm -rf /var/lib/apt/lists/*
-# Install CUDNN
-./install_cudnn.sh
-
-# Install HIP dependencies if needed
FF_GPU_BACKEND=${FF_GPU_BACKEND:-"cuda"}
+hip_version=${hip_version:-"5.6"}
if [[ "${FF_GPU_BACKEND}" != @(cuda|hip_cuda|hip_rocm|intel) ]]; then
echo "Error, value of FF_GPU_BACKEND (${FF_GPU_BACKEND}) is invalid."
exit 1
-elif [[ "$FF_GPU_BACKEND" == "hip_cuda" || "$FF_GPU_BACKEND" = "hip_rocm" ]]; then
+fi
+# Install CUDNN if needed
+if [[ "$FF_GPU_BACKEND" == "cuda" || "$FF_GPU_BACKEND" = "hip_cuda" ]]; then
+ # Install CUDNN
+ ./install_cudnn.sh
+fi
+# Install HIP dependencies if needed
+if [[ "$FF_GPU_BACKEND" == "hip_cuda" || "$FF_GPU_BACKEND" = "hip_rocm" ]]; then
echo "FF_GPU_BACKEND: ${FF_GPU_BACKEND}. Installing HIP dependencies"
- wget https://repo.radeon.com/amdgpu-install/22.20.5/ubuntu/focal/amdgpu-install_22.20.50205-1_all.deb
- sudo apt-get install -y ./amdgpu-install_22.20.50205-1_all.deb
- rm ./amdgpu-install_22.20.50205-1_all.deb
+ # Check that hip_version is one of 5.3,5.4,5.5,5.6
+ if [[ "$hip_version" != "5.3" && "$hip_version" != "5.4" && "$hip_version" != "5.5" && "$hip_version" != "5.6" ]]; then
+ echo "hip_version '${hip_version}' is not supported, please choose among {5.3, 5.4, 5.5, 5.6}"
+ exit 1
+ fi
+ # Compute script name and url given the version
+ AMD_GPU_SCRIPT_NAME=amdgpu-install_5.6.50600-1_all.deb
+ if [ "$hip_version" = "5.3" ]; then
+ AMD_GPU_SCRIPT_NAME=amdgpu-install_5.3.50300-1_all.deb
+ elif [ "$hip_version" = "5.4" ]; then
+ AMD_GPU_SCRIPT_NAME=amdgpu-install_5.4.50400-1_all.deb
+ elif [ "$hip_version" = "5.5" ]; then
+ AMD_GPU_SCRIPT_NAME=amdgpu-install_5.5.50500-1_all.deb
+ fi
+ AMD_GPU_SCRIPT_URL="https://repo.radeon.com/amdgpu-install/${hip_version}/ubuntu/focal/${AMD_GPU_SCRIPT_NAME}"
+ # Download and install AMD GPU software with ROCM and HIP support
+ wget "$AMD_GPU_SCRIPT_URL"
+ sudo apt-get install -y ./${AMD_GPU_SCRIPT_NAME}
+ sudo rm ./${AMD_GPU_SCRIPT_NAME}
sudo amdgpu-install -y --usecase=hip,rocm --no-dkms
- sudo apt-get install -y hip-dev hipblas miopen-hip rocm-hip-sdk
+ sudo apt-get install -y hip-dev hipblas miopen-hip rocm-hip-sdk rocm-device-libs
+
+ # Install protobuf v3.20.x manually
+ sudo apt-get update -y && sudo apt-get install -y pkg-config zip g++ zlib1g-dev unzip python autoconf automake libtool curl make
+ git clone -b 3.20.x https://github.com/protocolbuffers/protobuf.git
+ cd protobuf/
+ git submodule update --init --recursive
+ ./autogen.sh
+ ./configure
+ cores_available=$(nproc --all)
+ n_build_cores=$(( cores_available -1 ))
+ if (( n_build_cores < 1 )) ; then n_build_cores=1 ; fi
+ make -j $n_build_cores
+ sudo make install
+ sudo ldconfig
+ cd ..
else
echo "FF_GPU_BACKEND: ${FF_GPU_BACKEND}. Skipping installing HIP dependencies"
fi
diff --git a/.github/workflows/pip-install-skip.yml b/.github/workflows/pip-install-skip.yml
index f2606b94d8..92c3223e32 100644
--- a/.github/workflows/pip-install-skip.yml
+++ b/.github/workflows/pip-install-skip.yml
@@ -7,6 +7,7 @@ on:
- "deps/**"
- "python/**"
- "setup.py"
+ - "requirements.txt"
- ".github/workflows/helpers/install_dependencies.sh"
- ".github/workflows/pip-install.yml"
workflow_dispatch:
diff --git a/.github/workflows/pip-install.yml b/.github/workflows/pip-install.yml
index 7d60d3bf52..695ed9857b 100644
--- a/.github/workflows/pip-install.yml
+++ b/.github/workflows/pip-install.yml
@@ -7,6 +7,7 @@ on:
- "deps/**"
- "python/**"
- "setup.py"
+ - "requirements.txt"
- ".github/workflows/helpers/install_dependencies.sh"
- ".github/workflows/pip-install.yml"
push:
@@ -18,6 +19,7 @@ on:
- "deps/**"
- "python/**"
- "setup.py"
+ - "requirements.txt"
- ".github/workflows/helpers/install_dependencies.sh"
- ".github/workflows/pip-install.yml"
workflow_dispatch:
@@ -64,6 +66,8 @@ jobs:
export FF_HOME=$(pwd)
export FF_CUDA_ARCH=70
pip install . --verbose
+ # Remove build folder to check that the installed version can run independently of the build files
+ rm -rf build
- name: Check availability of Python flexflow.core module
run: |
diff --git a/.gitignore b/.gitignore
index 20d3979b08..be0266c9b5 100644
--- a/.gitignore
+++ b/.gitignore
@@ -15,6 +15,11 @@ __pycache__/
# C extensions
*.so
+/inference/weights/*
+/inference/tokenizer/*
+/inference/prompt/*
+/inference/output/*
+
# Distribution / packaging
.Python
build/
@@ -83,10 +88,7 @@ docs/build/
# Doxygen documentation
docs/doxygen/output/
-
-# Exhale documentation
-docs/source/_doxygen/
-docs/source/c++_api/
+docs/doxygen/cpp_api/
# PyBuilder
.pybuilder/
@@ -179,6 +181,7 @@ train-labels-idx1-ubyte
# Logs
logs/
+gpt_tokenizer
# pip version
python/flexflow/version.txt
diff --git a/.gitmodules b/.gitmodules
index b8419fda94..c68582d4ac 100644
--- a/.gitmodules
+++ b/.gitmodules
@@ -19,3 +19,7 @@
[submodule "deps/json"]
path = deps/json
url = https://github.com/nlohmann/json.git
+[submodule "deps/tokenizers-cpp"]
+ path = deps/tokenizers-cpp
+ url = https://github.com/mlc-ai/tokenizers-cpp.git
+ fetchRecurseSubmodules = true
\ No newline at end of file
diff --git a/CMakeLists.txt b/CMakeLists.txt
index 894be712e4..90df628a79 100644
--- a/CMakeLists.txt
+++ b/CMakeLists.txt
@@ -12,7 +12,16 @@ if (CMAKE_VERSION VERSION_GREATER_EQUAL "3.24.0")
endif()
set(CMAKE_MODULE_PATH ${CMAKE_MODULE_PATH} ${CMAKE_CURRENT_LIST_DIR}/cmake)
set(FLEXFLOW_ROOT ${CMAKE_CURRENT_LIST_DIR})
-set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -UNDEBUG")
+set(CMAKE_CXX_FLAGS "-std=c++17 ${CMAKE_CXX_FLAGS} -fPIC -UNDEBUG")
+
+option(INFERENCE_TESTS "Run inference tests" OFF)
+set(LIBTORCH_PATH "${CMAKE_CURRENT_SOURCE_DIR}/../libtorch" CACHE STRING "LibTorch Path")
+if (INFERENCE_TESTS)
+ find_package(Torch REQUIRED PATHS ${LIBTORCH_PATH} NO_DEFAULT_PATH)
+ set(CMAKE_CXX_FLAGS "-std=c++17 ${CMAKE_CXX_FLAGS} -fPIC ${TORCH_CXX_FLAGS}")
+ message(STATUS "LIBTORCH_PATH: ${LIBTORCH_PATH}")
+ message(STATUS "TORCH_LIBRARIES: ${TORCH_LIBRARIES}")
+endif()
# Set a default build type if none was specified
set(default_build_type "Debug")
@@ -154,9 +163,14 @@ set_property(CACHE FF_GPU_BACKEND PROPERTY STRINGS ${FF_GPU_BACKENDS})
# option for cuda arch
set(FF_CUDA_ARCH "autodetect" CACHE STRING "Target CUDA Arch")
-if (FF_CUDA_ARCH STREQUAL "")
+if ((FF_GPU_BACKEND STREQUAL "cuda" OR FF_GPU_BACKEND STREQUAL "hip_cuda") AND FF_CUDA_ARCH STREQUAL "")
message(FATAL_ERROR "FF_CUDA_ARCH cannot be an empty string. Set it to `autodetect`, `all`, or pass one or multiple valid CUDA archs.")
endif()
+# option for hip arch
+set(FF_HIP_ARCH "all" CACHE STRING "Target HIP Arch")
+if (FF_GPU_BACKEND STREQUAL "hip_rocm" AND FF_CUDA_ARCH STREQUAL "")
+ message(FATAL_ERROR "FF_HIP_ARCH cannot be an empty string. Set it to `all`, or pass one or multiple valid HIP archs.")
+endif()
# option for nccl
option(FF_USE_NCCL "Run FlexFlow with NCCL" OFF)
@@ -173,6 +187,7 @@ set(FF_MAX_DIM "4" CACHE STRING "Maximum dimention of tensors")
# option for legion
option(FF_USE_EXTERNAL_LEGION "Use pre-installed Legion" OFF)
+set(LEGION_MAX_RETURN_SIZE "32768" CACHE STRING "Maximum Legion return size")
set(FLEXFLOW_EXT_LIBRARIES "")
set(FLEXFLOW_INCLUDE_DIRS "")
@@ -184,10 +199,9 @@ set(LD_FLAGS $ENV{LD_FLAGS})
# Set global FLAGS
list(APPEND CC_FLAGS
- -std=c++11)
-
+ -std=c++17)
list(APPEND NVCC_FLAGS
- -std=c++11)
+ -std=c++17)
add_compile_options(${CC_FLAGS})
set(CUDA_NVCC_FLAGS ${CUDA_NVCC_FLAGS} ${NVCC_FLAGS})
@@ -220,12 +234,25 @@ if (FF_GPU_BACKEND STREQUAL "cuda" OR FF_GPU_BACKEND STREQUAL "hip_cuda")
include(cuda)
endif()
+# HIP
+if (FF_GPU_BACKEND STREQUAL "hip_rocm" OR FF_GPU_BACKEND STREQUAL "hip_cuda")
+ include(hip)
+endif()
+
# CUDNN
if (FF_GPU_BACKEND STREQUAL "cuda" OR FF_GPU_BACKEND STREQUAL "hip_cuda")
include(cudnn)
endif()
-# legion
+# Inference tests
+if(INFERENCE_TESTS)
+ list(APPEND FF_CC_FLAGS
+ -DINFERENCE_TESTS)
+ list(APPEND FF_NVCC_FLAGS
+ -DINFERENCE_TESTS)
+endif()
+
+# Legion
include(legion)
# Not build FlexFlow if BUILD_LEGION_ONLY is ON
@@ -275,9 +302,11 @@ if(NOT BUILD_LEGION_ONLY)
endif()
message(STATUS "FlexFlow MAX_DIM: ${FF_MAX_DIM}")
+ message(STATUS "LEGION_MAX_RETURN_SIZE: ${LEGION_MAX_RETURN_SIZE}")
list(APPEND FF_CC_FLAGS
- -DMAX_TENSOR_DIM=${FF_MAX_DIM})
+ -DMAX_TENSOR_DIM=${FF_MAX_DIM}
+ -DLEGION_MAX_RETURN_SIZE=${LEGION_MAX_RETURN_SIZE})
if(FF_USE_AVX2)
list(APPEND FF_CC_FLAGS
@@ -287,12 +316,14 @@ if(NOT BUILD_LEGION_ONLY)
list(APPEND FF_NVCC_FLAGS
-Wno-deprecated-gpu-targets
- -DMAX_TENSOR_DIM=${FF_MAX_DIM})
+ -DMAX_TENSOR_DIM=${FF_MAX_DIM}
+ -DLEGION_MAX_RETURN_SIZE=${LEGION_MAX_RETURN_SIZE})
list(APPEND FF_LD_FLAGS
-lrt
-ldl
- -rdynamic)
+ -rdynamic
+ -lstdc++fs)
# Set FF FLAGS
add_compile_options(${FF_CC_FLAGS})
@@ -306,11 +337,15 @@ if(NOT BUILD_LEGION_ONLY)
file(GLOB_RECURSE FLEXFLOW_HDR
LIST_DIRECTORIES False
${FLEXFLOW_ROOT}/include/*.h)
+
+ list(APPEND FLEXFLOW_HDR ${FLEXFLOW_ROOT}/inference/file_loader.h)
file(GLOB_RECURSE FLEXFLOW_SRC
LIST_DIRECTORIES False
${FLEXFLOW_ROOT}/src/*.cc)
+
list(REMOVE_ITEM FLEXFLOW_SRC "${FLEXFLOW_ROOT}/src/runtime/cpp_driver.cc")
+ list(APPEND FLEXFLOW_SRC ${FLEXFLOW_ROOT}/inference/file_loader.cc)
set(FLEXFLOW_CPP_DRV_SRC
${FLEXFLOW_ROOT}/src/runtime/cpp_driver.cc)
@@ -379,6 +414,18 @@ if(NOT BUILD_LEGION_ONLY)
add_compile_definitions(FF_USE_HIP_ROCM)
+ if (FF_HIP_ARCH STREQUAL "")
+ message(FATAL_ERROR "FF_HIP_ARCH is undefined")
+ endif()
+ set_property(TARGET flexflow PROPERTY HIP_ARCHITECTURES "${HIP_ARCH_LIST}")
+
+ message(STATUS "FF_GPU_BACKEND: ${FF_GPU_BACKEND}")
+ message(STATUS "FF_HIP_ARCH: ${FF_HIP_ARCH}")
+ message(STATUS "HIP_ARCH_LIST: ${HIP_ARCH_LIST}")
+ get_property(CHECK_HIP_ARCHS TARGET flexflow PROPERTY HIP_ARCHITECTURES)
+ message(STATUS "CHECK_HIP_ARCHS: ${CHECK_HIP_ARCHS}")
+ message(STATUS "HIP_CLANG_PATH: ${HIP_CLANG_PATH}")
+
# The hip cmake config module defines three targets,
# hip::amdhip64, hip::host, and hip::device.
#
@@ -456,30 +503,38 @@ if(NOT BUILD_LEGION_ONLY)
endif()
endif()
- # build binary
- option(FF_BUILD_RESNET "build resnet example" OFF)
- option(FF_BUILD_RESNEXT "build resnext example" OFF)
- option(FF_BUILD_ALEXNET "build alexnet example" OFF)
- option(FF_BUILD_DLRM "build DLRM example" OFF)
- option(FF_BUILD_XDL "build XDL example" OFF)
- option(FF_BUILD_INCEPTION "build inception example" OFF)
- option(FF_BUILD_CANDLE_UNO "build candle uno example" OFF)
- option(FF_BUILD_TRANSFORMER "build transformer example" OFF)
- option(FF_BUILD_MOE "build mixture of experts example" OFF)
- option(FF_BUILD_MLP_UNIFY "build mlp unify example" OFF)
- option(FF_BUILD_SPLIT_TEST "build split test example" OFF)
- option(FF_BUILD_SPLIT_TEST_2 "build split test 2 example" OFF)
- option(FF_BUILD_ALL_EXAMPLES "build all examples. Overrides others" OFF)
- option(FF_BUILD_UNIT_TESTS "build non-operator unit tests" OFF)
- option(FF_BUILD_SUBSTITUTION_TOOL "build substitution conversion tool" OFF)
- option(FF_BUILD_VISUALIZATION_TOOL "build substitution visualization tool" OFF)
-
- if(FF_BUILD_UNIT_TESTS)
- set(BUILD_GMOCK OFF)
- add_subdirectory(deps/googletest)
- enable_testing()
- add_subdirectory(tests/unit)
- endif()
+if (INFERENCE_TESTS)
+ target_link_libraries(flexflow "${TORCH_LIBRARIES}")
+ set_property(TARGET flexflow PROPERTY CXX_STANDARD 14)
+endif()
+
+# build binary
+option(FF_BUILD_TOKENIZER "build tokenizer=cpp for LLM serving" ON)
+option(FF_BUILD_RESNET "build resnet example" OFF)
+option(FF_BUILD_RESNEXT "build resnext example" OFF)
+option(FF_BUILD_ALEXNET "build alexnet example" OFF)
+option(FF_BUILD_DLRM "build DLRM example" OFF)
+option(FF_BUILD_XDL "build XDL example" OFF)
+option(FF_BUILD_INCEPTION "build inception example" OFF)
+option(FF_BUILD_CANDLE_UNO "build candle uno example" OFF)
+option(FF_BUILD_TRANSFORMER "build transformer example" OFF)
+option(FF_BUILD_MOE "build mixture of experts example" OFF)
+option(FF_BUILD_MLP_UNIFY "build mlp unify example" OFF)
+option(FF_BUILD_SPLIT_TEST "build split test example" OFF)
+option(FF_BUILD_SPLIT_TEST_2 "build split test 2 example" OFF)
+option(FF_BUILD_MLP_UNIFY_INFERENCE "build mlp unify inference example" OFF)
+option(FF_BUILD_ALL_INFERENCE_EXAMPLES "build all inference examples. Overrides others" OFF)
+option(FF_BUILD_ALL_EXAMPLES "build all examples. Overrides others" OFF)
+option(FF_BUILD_UNIT_TESTS "build non-operator unit tests" OFF)
+option(FF_BUILD_SUBSTITUTION_TOOL "build substitution conversion tool" OFF)
+option(FF_BUILD_VISUALIZATION_TOOL "build substitution visualization tool" OFF)
+
+if(FF_BUILD_UNIT_TESTS)
+ set(BUILD_GMOCK OFF)
+ add_subdirectory(deps/googletest)
+ enable_testing()
+ add_subdirectory(tests/unit)
+endif()
if(FF_BUILD_SUBSTITUTION_TOOL)
add_subdirectory(tools/protobuf_to_json)
@@ -489,86 +544,113 @@ if(NOT BUILD_LEGION_ONLY)
add_subdirectory(tools/substitutions_to_dot)
endif()
- if(FF_BUILD_RESNET OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/ResNet)
+if(FF_BUILD_ALL_INFERENCE_EXAMPLES OR FF_BUILD_TOKENIZER)
+ if (FF_GPU_BACKEND STREQUAL "hip_rocm")
+ SET(SPM_USE_BUILTIN_PROTOBUF OFF CACHE BOOL "Use builtin version of protobuf to compile SentencePiece")
endif()
-
- if(FF_BUILD_RESNEXT OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/resnext50)
+ # Ensure Rust is installed
+ execute_process(COMMAND rustc --version
+ RESULT_VARIABLE RUST_COMMAND_RESULT
+ OUTPUT_VARIABLE RUSTC_OUTPUT
+ ERROR_QUIET)
+ if(NOT RUST_COMMAND_RESULT EQUAL 0)
+ message(FATAL_ERROR "Rust is not installed on the system. Please install it by running: 'curl https://sh.rustup.rs -sSf | sh -s -- -y' and following the instructions on the screen.")
endif()
-
- if(FF_BUILD_ALEXNET OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/AlexNet)
+ # Ensure Cargo is installed
+ execute_process(COMMAND cargo --version
+ RESULT_VARIABLE CARGO_RESULT
+ OUTPUT_QUIET ERROR_QUIET)
+ if(NOT CARGO_RESULT EQUAL 0)
+ message(FATAL_ERROR "Rust is installed, but cargo is not. Please install it by running: 'curl https://sh.rustup.rs -sSf | sh -s -- -y' and following the instructions on the screen.")
endif()
+ add_subdirectory(deps/tokenizers-cpp tokenizers EXCLUDE_FROM_ALL)
+ target_include_directories(flexflow PUBLIC deps/tokenizers-cpp/include)
+ target_link_libraries(flexflow tokenizers_cpp)
+endif()
+if(FF_BUILD_RESNET OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/ResNet)
+endif()
- if(FF_BUILD_MLP_UNIFY OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/MLP_Unify)
- endif()
+if(FF_BUILD_RESNEXT OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/resnext50)
+endif()
- if(FF_BUILD_SPLIT_TEST OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/split_test)
- endif()
+if(FF_BUILD_ALEXNET OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/AlexNet)
+endif()
- if(FF_BUILD_SPLIT_TEST_2 OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/split_test_2)
- endif()
+if(FF_BUILD_MLP_UNIFY OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/MLP_Unify)
+endif()
- if(FF_BUILD_INCEPTION OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/InceptionV3)
- endif()
+if(FF_BUILD_SPLIT_TEST OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/split_test)
+endif()
- #TODO: Once functional add to BUILD_ALL_EXAMPLES
- if(FF_BUILD_CANDLE_UNO OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/candle_uno)
- endif()
+if(FF_BUILD_SPLIT_TEST_2 OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/split_test_2)
+endif()
- if(FF_BUILD_DLRM OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/DLRM)
+if(FF_BUILD_INCEPTION OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/InceptionV3)
+endif()
- #add_executable(generate_dlrm_hetero_strategy src/runtime/dlrm_strategy_hetero.cc)
- #target_include_directories(generate_dlrm_hetero_strategy PUBLIC ${FLEXFLOW_INCLUDE_DIRS})
+#TODO: Once functional add to BUILD_ALL_EXAMPLES
+if(FF_BUILD_CANDLE_UNO OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/candle_uno)
+endif()
- #add_executable(generate_dlrm_strategy src/runtime/dlrm_strategy.cc)
- #target_include_directories(generate_dlrm_strategy PUBLIC ${FLEXFLOW_INCLUDE_DIRS})
- endif()
+if(FF_BUILD_DLRM OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/DLRM)
- if(FF_BUILD_XDL OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/XDL)
- endif()
+ #add_executable(generate_dlrm_hetero_strategy src/runtime/dlrm_strategy_hetero.cc)
+ #target_include_directories(generate_dlrm_hetero_strategy PUBLIC ${FLEXFLOW_INCLUDE_DIRS})
- if(FF_BUILD_TRANSFORMER OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/Transformer)
- endif()
+ #add_executable(generate_dlrm_strategy src/runtime/dlrm_strategy.cc)
+ #target_include_directories(generate_dlrm_strategy PUBLIC ${FLEXFLOW_INCLUDE_DIRS})
+endif()
- if(FF_BUILD_MOE OR FF_BUILD_ALL_EXAMPLES)
- add_subdirectory(examples/cpp/mixture_of_experts)
- endif()
+if(FF_BUILD_XDL OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/XDL)
+endif()
- # installation
- set(INCLUDE_DEST "include")
- set(LIB_DEST "lib")
- install(FILES ${FLEXFLOW_HDR} DESTINATION ${INCLUDE_DEST})
- install(TARGETS flexflow DESTINATION ${LIB_DEST})
- # install python
- if (FF_USE_PYTHON)
- execute_process(COMMAND ${PYTHON_EXECUTABLE} -c "from distutils import sysconfig; print(sysconfig.get_python_lib(plat_specific=False,standard_lib=False))" OUTPUT_VARIABLE PY_DEST OUTPUT_STRIP_TRAILING_WHITESPACE)
- if (NOT FF_BUILD_FROM_PYPI)
- install(
- DIRECTORY ${FLEXFLOW_ROOT}/python/flexflow/
- DESTINATION ${PY_DEST}/flexflow
- FILES_MATCHING
- PATTERN "*.py")
- else()
- # pip automatically installs all *.py files in the python/flexflow folder, but because flexflow_cffi_header.py is generated at build time, we have to install it manually.
- install(
- PROGRAMS ${FLEXFLOW_ROOT}/python/flexflow/core/flexflow_cffi_header.py
- DESTINATION ${PY_DEST}/flexflow/core
- )
- # Use setup.py script to re-install the Python bindings library with the right library paths.
- # Need to put the instructions in a subfolder because of issue below:
- # https://stackoverflow.com/questions/43875499/do-post-processing-after-make-install-in-cmake
- add_subdirectory(cmake/pip_install)
- endif()
- endif()
+if(FF_BUILD_TRANSFORMER OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/Transformer)
+endif()
+
+if(FF_BUILD_MOE OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(examples/cpp/mixture_of_experts)
+endif()
+if(FF_BUILD_ALL_INFERENCE_EXAMPLES OR FF_BUILD_ALL_EXAMPLES)
+ add_subdirectory(inference/spec_infer)
+ add_subdirectory(inference/incr_decoding)
+endif()
+
+
+# installation
+set(INCLUDE_DEST "include")
+set(LIB_DEST "lib")
+install(FILES ${FLEXFLOW_HDR} DESTINATION ${INCLUDE_DEST})
+install(TARGETS flexflow DESTINATION ${LIB_DEST})
+# install python
+if (FF_USE_PYTHON)
+ execute_process(COMMAND ${PYTHON_EXECUTABLE} -c "from distutils import sysconfig; print(sysconfig.get_python_lib(plat_specific=False,standard_lib=False))" OUTPUT_VARIABLE PY_DEST OUTPUT_STRIP_TRAILING_WHITESPACE)
+ if (NOT FF_BUILD_FROM_PYPI)
+ install(
+ DIRECTORY ${FLEXFLOW_ROOT}/python/flexflow/
+ DESTINATION ${PY_DEST}/flexflow
+ FILES_MATCHING
+ PATTERN "*.py")
+ else()
+ # pip automatically installs all *.py files in the python/flexflow folder, but because flexflow_cffi_header.py is generated at build time, we have to install it manually.
+ install(
+ PROGRAMS ${FLEXFLOW_ROOT}/python/flexflow/core/flexflow_cffi_header.py
+ DESTINATION ${PY_DEST}/flexflow/core
+ )
+ # Use setup.py script to re-install the Python bindings library with the right library paths.
+ # Need to put the instructions in a subfolder because of issue below:
+ # https://stackoverflow.com/questions/43875499/do-post-processing-after-make-install-in-cmake
+ add_subdirectory(cmake/pip_install)
+ endif()
endif()
\ No newline at end of file
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index e607fddb1a..c3c0b5173f 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -119,7 +119,26 @@ After adding the DNN layers, the next step before compiling the model for traini
#### Model compilation
-TODO
+Model compilation consists of the following steps:
+
+1. We initialize an operator for each layer in the model, via the function `create_operators_from_layers()`. Layers work with `Tensor` input/weights/outputs, and are created directly by the user when writing a FlexFlow program. Operators work with `ParallelTensor` objects and they are responsible for running computations by launching kernels on GPUs.
+2. Launch the graph optimize task (`GRAPH_OPTIMIZE_TASK_ID`), implemented by`PCG::Graph::graph_optimize_task`, which returns `PCG::GraphOptimalViewSerialized`
+ 1. call `deserialize_graph_optimal_view(...)` to get `PCG::Graph *best_graph` and `std::unordered_map optimal_views` from deserialized `PCG::GraphOptimalViewSerialized`
+ 2. `convert_graph_to_operators()`
+ 3. print the dot of the best graph obtained
+ 4. map inputs to parallel tensor and weights to parallel tensor? -> strange for loop to understand better
+3. Init performance metrics via the `FFModel::update_metrics_task`
+4. Perform inplace optimizations (if enabled)
+5. Loop through the operators to do the following (to be understood better):
+ 1. `parameters.push_back(op->weights[i]);` for each weight in each operator
+ 2. `op->map_output_tensors(*this);`
+ 3. `((ParallelOp *)op)->create_input_partition(*this);` if the operator is a parallel operator
+6. Check correctness of the operator's input and output tensors' settings
+7. Perform fusion optimizations, if enabled
+8. Print all operators and their input and output regions
+9. Create the tensor for the label
+10. Initialize the optimizer
+11. In training mode, if NCCL is enabled, initialize all the communicators and other objects
## Continuous Integration
@@ -281,6 +300,10 @@ We want to make contributing to this project as easy and transparent as possible
### Formatting
We use `clang-format` to format our C++ code. If you make changes to the code and the Clang format CI test is failing, you can lint your code by running: `./scripts/format.sh` from the main folder of this repo.
+### Documenting the code
+We follow the Python Docstring conventions for documenting the Python code. We document the C++ code using comments in any of the conventioned supported by Doxygen [see here](https://doxygen.nl/manual/docblocks.html).
+
+
### Pull Requests
We actively welcome your pull requests.
diff --git a/FlexFlow.mk b/FlexFlow.mk
index b434045893..14f32a7639 100644
--- a/FlexFlow.mk
+++ b/FlexFlow.mk
@@ -59,7 +59,8 @@ GEN_SRC += $(shell find $(FF_HOME)/src/loss_functions/ -name '*.cc')\
$(shell find $(FF_HOME)/src/runtime/ -name '*.cc')\
$(shell find $(FF_HOME)/src/utils/dot/ -name '*.cc')\
$(shell find $(FF_HOME)/src/dataloader/ -name '*.cc')\
- $(shell find $(FF_HOME)/src/c/ -name '*.cc')
+ $(shell find $(FF_HOME)/src/c/ -name '*.cc')\
+ $(shell find $(FF_HOME)/inference/ -name 'file_loader.cc')
GEN_SRC := $(filter-out $(FF_HOME)/src/runtime/cpp_driver.cc, $(GEN_SRC))
FF_CUDA_SRC += $(shell find $(FF_HOME)/src/loss_functions/ -name '*.cu')\
@@ -94,15 +95,17 @@ ifneq ($(strip $(FF_USE_PYTHON)), 1)
endif
-INC_FLAGS += -I${FF_HOME}/include -I${FF_HOME}/deps/optional/include -I${FF_HOME}/deps/variant/include -I${FF_HOME}/deps/json/include
+INC_FLAGS += -I${FF_HOME}/include -I${FF_HOME}/inference -I${FF_HOME}/deps/optional/include -I${FF_HOME}/deps/variant/include -I${FF_HOME}/deps/json/include -I${FF_HOME}/deps/tokenizers-cpp/include -I${FF_HOME}/deps/tokenizers-cpp/sentencepiece/src
CC_FLAGS += -DMAX_TENSOR_DIM=$(MAX_DIM) -DLEGION_MAX_RETURN_SIZE=32768
NVCC_FLAGS += -DMAX_TENSOR_DIM=$(MAX_DIM) -DLEGION_MAX_RETURN_SIZE=32768
HIPCC_FLAGS += -DMAX_TENSOR_DIM=$(MAX_DIM) -DLEGION_MAX_RETURN_SIZE=32768
GASNET_FLAGS +=
# For Point and Rect typedefs
-CC_FLAGS += -std=c++11
-NVCC_FLAGS += -std=c++11
-HIPCC_FLAGS += -std=c++11
+CC_FLAGS += -std=c++17
+NVCC_FLAGS += -std=c++17
+HIPCC_FLAGS += -std=c++17
+
+LD_FLAGS += -L$(FF_HOME)/deps/tokenizers-cpp/example/tokenizers -ltokenizers_cpp -ltokenizers_c -L$(FF_HOME)/deps/tokenizers-cpp/example/tokenizers/sentencepiece/src -lsentencepiece
ifeq ($(strip $(FF_USE_NCCL)), 1)
INC_FLAGS += -I$(MPI_HOME)/include -I$(NCCL_HOME)/include
diff --git a/INSTALL.md b/INSTALL.md
index d2e3c1d2f6..8d33770c92 100644
--- a/INSTALL.md
+++ b/INSTALL.md
@@ -1,4 +1,4 @@
-# Installing FlexFlow
+# Building from source
To build and install FlexFlow, follow the instructions below.
## 1. Download the source code
@@ -85,10 +85,11 @@ export FF_HOME=/path/to/FlexFlow
### Run FlexFlow Python examples
The Python examples are in the [examples/python](https://github.com/flexflow/FlexFlow/tree/master/examples/python). The native, Keras integration and PyTorch integration examples are listed in `native`, `keras` and `pytorch` respectively.
-To run the Python examples, you have two options: you can use the `flexflow_python` interpreter, available in the `build` folder, or you can use the native Python interpreter. If you choose to use the native Python interpreter, you should either install FlexFlow, or, if you prefer to build without installing, export the following flags:
+To run the Python examples, you have two options: you can use the `flexflow_python` interpreter, available in the `build` folder, or you can use the native Python interpreter. If you choose to use the native Python interpreter, you should either install FlexFlow, or, if you prefer to build without installing, export the required environment flags by running the following command (edit the path if your build folder is not named `build`):
-* `export PYTHONPATH="${FF_HOME}/python:${FF_HOME}/build/deps/legion/bindings/python:${PYTHONPATH}"`
-* `export LD_LIBRARY_PATH="${FF_HOME}/build:${FF_HOME}/build/deps/legion/lib:${LD_LIBRARY_PATH}"`
+```
+source ./build/set_python_envs.sh
+```
**We recommend that you run the** `mnist_mlp` **test under** `native` **using the following cmd to check if FlexFlow has been installed correctly:**
diff --git a/MULTI-NODE.md b/MULTI-NODE.md
index a8fd2fb705..4bae47cfa6 100644
--- a/MULTI-NODE.md
+++ b/MULTI-NODE.md
@@ -68,4 +68,4 @@ ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIOy5NKYdE8Cwgid59rx6xMqyj9vLaWuXIwy/BSRiK4su
Follow step 6 in [INSTALL.md](INSTALL.md) to set environment variables.
-A script to run a Python example on multiple nodes is available at `scripts/mnist_mlp_run.sh`. You can run the script using [`mpirun`](https://www.open-mpi.org/doc/current/man1/mpirun.1.php) (if you configured it in step 3) or [`srun`](https://slurm.schedmd.com/srun.html).
\ No newline at end of file
+A script to run a Python example on multiple nodes is available at `scripts/mnist_mlp_run.sh`. You can run the script using [`mpirun`](https://www.open-mpi.org/doc/current/man1/mpirun.1.php) (if you configured it in step 3) or [`srun`](https://slurm.schedmd.com/srun.html).
diff --git a/README.md b/README.md
index 9ad900fb3c..e84bf20605 100644
--- a/README.md
+++ b/README.md
@@ -1,72 +1,53 @@
-# FlexFlow
-       [](https://flexflow.readthedocs.io/en/latest/?badge=latest)
+# FlexFlow: Low-Latency, High-Performance Training and Serving
+       [](https://flexflow.readthedocs.io/en/latest/?badge=latest)
-FlexFlow is a deep learning framework that accelerates distributed DNN training by automatically searching for efficient parallelization strategies. FlexFlow provides a drop-in replacement for PyTorch and TensorFlow Keras. Running existing PyTorch and Keras programs in FlexFlow only requires [a few lines of changes to the program](https://flexflow.ai/keras).
-## Install FlexFlow
-To install FlexFlow from source code, please read the [instructions](https://flexflow.readthedocs.io/en/latest/installation.html). If you would like to quickly try FlexFlow, we also provide pre-built Docker packages for several versions of CUDA and for the `hip_rocm` backend, together with [Dockerfiles](./docker) if you wish to build the containers manually. More info on the Docker images can be found [here](./docker/README.md). You can also use `conda` to install the FlexFlow Python package (coming soon).
+---
-## PyTorch Support
-Users can also use FlexFlow to optimize the parallelization performance of existing PyTorch models in two steps. First, a PyTorch model can be exported to the FlexFlow model format using `flexflow.torch.fx.torch_to_flexflow`.
-```python
-import torch
-import flexflow.torch.fx as fx
+## News 🔥:
-model = MyPyTorchModule()
-fx.torch_to_flexflow(model, "mymodel.ff")
-```
+* [08/16/2023] Adding Starcoder model support
+* [08/14/2023] Released Dockerfile for different CUDA versions
+
+## Install FlexFlow
-Second, a FlexFlow program can directly import a previously saved PyTorch model and [autotune](https://www.usenix.org/conference/osdi22/presentation/unger) the parallelization performance for a given parallel machine.
-```python
-from flexflow.pytorch.model import PyTorchModel
+### Requirements
+* OS: Linux
+* GPU backend: Hip-ROCm or CUDA
+ * CUDA version: 10.2 – 12.0
+ * NVIDIA compute capability: 6.0 or higher
+* Python: 3.6 or higher
+* Package dependencies: [see here](https://github.com/flexflow/FlexFlow/blob/inference/requirements.txt)
-def top_level_task():
- torch_model = PyTorchModel("mymodel.ff")
- output_tensor = torch_model.apply(ffmodel, input_tensor)
- ## Model compilation
- ffmodel.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
- ## Model training
- (x_train, y_train) = cifar10.load_data()
- ffmodel.fit(x_train, y_train, epochs=30)
+### Install with pip
+You can install FlexFlow using pip:
+
+```bash
+pip install flexflow
```
-**More FlexFlow PyTorch examples**: see the [pytorch examples folder](https://github.com/flexflow/FlexFlow/tree/master/examples/python/pytorch).
+### Try it in Docker
+If you run into any issue during the install, or if you would like to use the C++ API without needing to install from source, you can also use our pre-built Docker package for different CUDA versions and the `hip_rocm` backend. To download and run our pre-built Docker container:
+
+```bash
+docker run --gpus all -it --rm --shm-size=8g ghcr.io/flexflow/flexflow-cuda-11.8:latest
+```
-## TensorFlow Keras and ONNX Support
-FlexFlow prioritizes PyTorch compatibility, but also includes frontends for [Tensorflow Keras](./docs/source/keras.rst) and [ONNX](./docs/source/onnx.rst) models.
+To download a Docker container for a backend other than CUDA v11.8, you can replace the `cuda-11.8` suffix with any of the following backends: `cuda-11.1`, `cuda-11.2`, `cuda-11.3`, `cuda-11.5`, `cuda-11.6`, `cuda-11.7`, `cuda-11.8`, and `hip_rocm`). More info on the Docker images, with instructions to build a new image from source, or run with additional configurations, can be found [here](../docker/README.md).
-## C++ Interface
-For users that prefer to program in C/C++. FlexFlow supports a C++ program inference that is equivalent to its Python APIs.
+### Build from source
-**More FlexFlow C++ examples**: see the [C++ examples folder](https://github.com/flexflow/FlexFlow/tree/master/examples/cpp).
+You can install FlexFlow Serve from source code by building the inference branch of FlexFlow. Please follow these [instructions](https://flexflow.readthedocs.io/en/latest/installation.html).
-## Command-Line Flags
-In addition to setting runtime configurations in a FlexFlow Python/C++ program, the FlexFlow runtime also accepts command-line arguments for various runtime parameters:
+## Get Started!
-FlexFlow training flags:
-* `-e` or `--epochs`: number of total epochs to run (default: 1)
-* `-b` or `--batch-size`: global batch size in each iteration (default: 64)
-* `-p` or `--print-freq`: print frequency (default: 10)
-* `-d` or `--dataset`: path to the training dataset. If not set, synthetic data is used to conduct training.
+To get started, check out the quickstart guides below for the FlexFlow training and serving libraries.
-Legion runtime flags:
-* `-ll:gpu`: number of GPU processors to use on each node (default: 0)
-* `-ll:fsize`: size of device memory on each GPU (in MB)
-* `-ll:zsize`: size of zero-copy memory (pinned DRAM with direct GPU access) on each node (in MB). This is used for prefecthing training images from disk.
-* `-ll:cpu`: number of data loading workers (default: 4)
-* `-ll:util`: number of utility threads to create per process (default: 1)
-* `-ll:bgwork`: number of background worker threads to create per process (default: 1)
+* [FlexFlow Train](./TRAIN.md)
+* [FlexFlow Serve](./SERVE.md)
-Performance auto-tuning flags:
-* `--search-budget` or `--budget`: the number of iterations for the MCMC search (default: 0)
-* `--search-alpha` or `--alpha`: a hyper-parameter for the search procedure (default: 0.05)
-* `--export-strategy` or `--export`: path to export the best discovered strategy (default: None)
-* `--import-strategy` or `--import`: path to import a previous saved strategy (default: None)
-* `--enable-parameter-parallel`: allow FlexFlow to explore parameter parallelism for performance auto-tuning. (By default FlexFlow only considers data and model parallelism.)
-* `--enable-attribute-parallel`: allow FlexFlow to explore attribute parallelism for performance auto-tuning. (By default FlexFlow only considers data and model parallelism.)
-For performance tuning related flags: see [performance autotuning](https://flexflow.ai/search).
## Contributing
@@ -75,6 +56,14 @@ Please let us know if you encounter any bugs or have any suggestions by [submitt
We welcome all contributions to FlexFlow from bug fixes to new features and extensions.
## Citations
+
+**FlexFlow Serve:**
+
+* Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, Zhihao Jia. [SpecInfer: Accelerating Generative Large Language Model Serving with Speculative Inference and Token Tree Verification](https://arxiv.org/abs/2305.09781). In ArXiV, May 2023.
+
+
+**FlexFlow Train:**
+
* Colin Unger, Zhihao Jia, Wei Wu, Sina Lin, Mandeep Baines, Carlos Efrain Quintero Narvaez, Vinay Ramakrishnaiah, Nirmal Prajapati, Pat McCormick, Jamaludin Mohd-Yusof, Xi Luo, Dheevatsa Mudigere, Jongsoo Park, Misha Smelyanskiy, and Alex Aiken. [Unity: Accelerating DNN Training Through Joint Optimization of Algebraic Transformations and Parallelization](https://www.usenix.org/conference/osdi22/presentation/unger). In Proceedings of the Symposium on Operating Systems Design and Implementation (OSDI), July 2022.
* Zhihao Jia, Matei Zaharia, and Alex Aiken. [Beyond Data and Model Parallelism for Deep Neural Networks](https://cs.stanford.edu/~zhihao/papers/sysml19a.pdf). In Proceedings of the 2nd Conference on Machine Learning and Systems (MLSys), April 2019.
@@ -86,3 +75,4 @@ FlexFlow is developed and maintained by teams at CMU, Facebook, Los Alamos Natio
## License
FlexFlow uses Apache License 2.0.
+
diff --git a/SERVE.md b/SERVE.md
new file mode 100644
index 0000000000..e716392b32
--- /dev/null
+++ b/SERVE.md
@@ -0,0 +1,209 @@
+# FlexFlow Serve: Low-Latency, High-Performance LLM Serving
+
+
+## What is FlexFlow Serve
+
+The high computational and memory requirements of generative large language
+models (LLMs) make it challenging to serve them quickly and cheaply.
+FlexFlow Serve is an open-source compiler and distributed system for
+__low latency__, __high performance__ LLM serving. FlexFlow Serve outperforms
+existing systems by 1.3-2.0x for single-node, multi-GPU inference and by
+1.4-2.4x for multi-node, multi-GPU inference.
+
+
+
+
+
+
+## Quickstart
+The following example shows how to deploy an LLM using FlexFlow Serve and accelerate its serving using [speculative inference](#speculative-inference). First, we import `flexflow.serve` and initialize the FlexFlow Serve runtime. Note that `memory_per_gpu` and `zero_copy_memory_per_node` specify the size of device memory on each GPU (in MB) and zero-copy memory on each node (in MB), respectively. FlexFlow Serve combines tensor and pipeline model parallelism for LLM serving.
+```python
+import flexflow.serve as ff
+
+ff.init(
+ {
+ "num_gpus": 4,
+ "memory_per_gpu": 14000,
+ "zero_copy_memory_per_node": 30000,
+ "tensor_parallelism_degree": 4,
+ "pipeline_parallelism_degree": 1,
+ }
+)
+```
+Second, we specify the LLM to serve and the SSM(s) used to accelerate LLM serving. The list of supported LLMs and SSMs is available at [supported models](#supported-llms-and-ssms).
+```python
+# Specify the LLM
+llm = ff.LLM("decapoda-research/llama-7b-hf")
+
+# Specify a list of SSMs (just one in this case)
+ssms=[]
+ssm = ff.SSM("JackFram/llama-68m")
+ssms.append(ssm)
+```
+Next, we declare the generation configuration and compile both the LLM and SSMs. Note that all SSMs should run in the **beam search** mode, and the LLM should run in the **tree verification** mode to verify the speculated tokens from SSMs.
+```python
+# Create the sampling configs
+generation_config = ff.GenerationConfig(
+ do_sample=False, temperature=0.9, topp=0.8, topk=1
+)
+
+# Compile the SSMs for inference and load the weights into memory
+for ssm in ssms:
+ ssm.compile(generation_config)
+
+# Compile the LLM for inference and load the weights into memory
+llm.compile(generation_config, ssms=ssms)
+```
+Finally, we call `llm.generate` to generate the output, which is organized as a list of `GenerationResult`, which include the output tokens and text.
+```python
+result = llm.generate("Here are some travel tips for Tokyo:\n")
+```
+
+### Incremental decoding
+
+
+Expand here
+
+
+```python
+
+import flexflow.serve as ff
+
+# Initialize the FlexFlow runtime. ff.init() takes a dictionary or the path to a JSON file with the configs
+ff.init(
+ {
+ "num_gpus": 4,
+ "memory_per_gpu": 14000,
+ "zero_copy_memory_per_gpu": 30000,
+ "tensor_parallelism_degree": 4,
+ "pipeline_parallelism_degree": 1,
+ }
+)
+
+# Create the FlexFlow LLM
+llm = ff.LLM("decapoda-research/llama-7b-hf")
+
+# Create the sampling configs
+generation_config = ff.GenerationConfig(
+ do_sample=True, temperature=0.9, topp=0.8, topk=1
+)
+
+# Compile the LLM for inference and load the weights into memory
+llm.compile(generation_config)
+
+# Generation begins!
+result = llm.generate("Here are some travel tips for Tokyo:\n")
+
+```
+
+
+
+### C++ interface
+If you'd like to use the C++ interface (mostly used for development and benchmarking purposes), you should install from source, and follow the instructions below.
+
+
+Expand here
+
+
+#### Downloading models
+
+Before running FlexFlow Serve, you should manually download the LLM and SSM(s) model of interest using the [inference/utils/download_hf_model.py](https://github.com/flexflow/FlexFlow/blob/inference/inference/utils/download_hf_model.py) script (see example below). By default, the script will download all of a model's assets (weights, configs, tokenizer files, etc...) into the cache folder `~/.cache/flexflow`. If you would like to use a different folder, you can request that via the parameter `--cache-folder`.
+
+```bash
+python3 ./inference/utils/download_hf_model.py ...
+```
+
+#### Running the C++ examples
+A C++ example is available at [this folder](../inference/spec_infer/). After building FlexFlow Serve, the executable will be available at `/build_dir/inference/spec_infer/spec_infer`. You can use the following command-line arguments to run FlexFlow Serve:
+
+* `-ll:gpu`: number of GPU processors to use on each node for serving an LLM (default: 0)
+* `-ll:fsize`: size of device memory on each GPU in MB
+* `-ll:zsize`: size of zero-copy memory (pinned DRAM with direct GPU access) in MB. FlexFlow Serve keeps a replica of the LLM parameters on zero-copy memory, and therefore requires that the zero-copy memory is sufficient for storing the LLM parameters.
+* `-llm-model`: the LLM model ID from HuggingFace (e.g. "decapoda-research/llama-7b-hf")
+* `-ssm-model`: the SSM model ID from HuggingFace (e.g. "JackFram/llama-160m"). You can use multiple `-ssm-model`s in the command line to launch multiple SSMs.
+* `-cache-folder`: the folder
+* `-data-parallelism-degree`, `-tensor-parallelism-degree` and `-pipeline-parallelism-degree`: parallelization degrees in the data, tensor, and pipeline dimensions. Their product must equal the number of GPUs available on the machine. When any of the three parallelism degree arguments is omitted, a default value of 1 will be used.
+* `-prompt`: (optional) path to the prompt file. FlexFlow Serve expects a json format file for prompts. In addition, users can also use the following API for registering requests:
+* `-output-file`: (optional) filepath to use to save the output of the model, together with the generation latency
+
+For example, you can use the following command line to serve a LLaMA-7B or LLaMA-13B model on 4 GPUs and use two collectively boost-tuned LLaMA-68M models for speculative inference.
+
+```bash
+./inference/spec_infer/spec_infer -ll:gpu 4 -ll:fsize 14000 -ll:zsize 30000 -llm-model decapoda-research/llama-7b-hf -ssm-model JackFram/llama-68m -prompt /path/to/prompt.json -tensor-parallelism-degree 4 --fusion
+```
+
+
+## Speculative Inference
+A key technique that enables FlexFlow Serve to accelerate LLM serving is speculative
+inference, which combines various collectively boost-tuned small speculative
+models (SSMs) to jointly predict the LLM’s outputs; the predictions are organized as a
+token tree, whose nodes each represent a candidate token sequence. The correctness
+of all candidate token sequences represented by a token tree is verified against the
+LLM’s output in parallel using a novel tree-based parallel decoding mechanism.
+FlexFlow Serve uses an LLM as a token tree verifier instead of an incremental decoder,
+which largely reduces the end-to-end inference latency and computational requirement
+for serving generative LLMs while provably preserving model quality.
+
+
+
+
+
+### Supported LLMs and SSMs
+
+FlexFlow Serve currently supports all HuggingFace models with the following architectures:
+* `LlamaForCausalLM` / `LLaMAForCausalLM` (e.g. LLaMA/LLaMA-2, Guanaco, Vicuna, Alpaca, ...)
+* `OPTForCausalLM` (models from the OPT family)
+* `RWForCausalLM` (models from the Falcon family)
+* `GPTBigCodeForCausalLM` (models from the Starcoder family)
+
+Below is a list of models that we have explicitly tested and for which a SSM may be available:
+
+| Model | Model id on HuggingFace | Boost-tuned SSMs |
+| :---- | :---- | :---- |
+| LLaMA-7B | decapoda-research/llama-7b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-13B | decapoda-research/llama-13b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-30B | decapoda-research/llama-30b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-65B | decapoda-research/llama-65b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-2-7B | meta-llama/Llama-2-7b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-2-13B | meta-llama/Llama-2-13b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| LLaMA-2-70B | meta-llama/Llama-2-70b-hf | [LLaMA-68M](https://huggingface.co/JackFram/llama-68m) , [LLaMA-160M](https://huggingface.co/JackFram/llama-160m) |
+| OPT-6.7B | facebook/opt-6.7b | [OPT-125M](https://huggingface.co/facebook/opt-125m) |
+| OPT-13B | facebook/opt-13b | [OPT-125M](https://huggingface.co/facebook/opt-125m) |
+| OPT-30B | facebook/opt-30b | [OPT-125M](https://huggingface.co/facebook/opt-125m) |
+| OPT-66B | facebook/opt-66b | [OPT-125M](https://huggingface.co/facebook/opt-125m) |
+| Falcon-7B | tiiuae/falcon-7b | |
+| Falcon-40B | tiiuae/falcon-40b | |
+| StarCoder-15.5B | bigcode/starcoder | |
+
+
+### CPU Offloading
+FlexFlow Serve also offers offloading-based inference for running large models (e.g., llama-7B) on a single GPU. CPU offloading is a choice to save tensors in CPU memory, and only copy the tensor to GPU when doing calculation. Notice that now we selectively offload the largest weight tensors (weights tensor in Linear, Attention). Besides, since the small model occupies considerably less space, it it does not pose a bottleneck for GPU memory, the offloading will bring more runtime space and computational cost, so we only do the offloading for the large model. [TODO: update instructions] You can run the offloading example by enabling the `-offload` and `-offload-reserve-space-size` flags.
+
+### Quantization
+FlexFlow Serve supports int4 and int8 quantization. The compressed tensors are stored on the CPU side. Once copied to the GPU, these tensors undergo decompression and conversion back to their original precision. Please find the compressed weight files in our s3 bucket, or use [this script](../inference/utils/compress_llama_weights.py) from [FlexGen](https://github.com/FMInference/FlexGen) project to do the compression manually. [TODO: update instructions for quantization].
+
+### Prompt Datasets
+We provide five prompt datasets for evaluating FlexFlow Serve: [Chatbot instruction prompts](https://specinfer.s3.us-east-2.amazonaws.com/prompts/chatbot.json), [ChatGPT Prompts](https://specinfer.s3.us-east-2.amazonaws.com/prompts/chatgpt.json), [WebQA](https://specinfer.s3.us-east-2.amazonaws.com/prompts/webqa.json), [Alpaca](https://specinfer.s3.us-east-2.amazonaws.com/prompts/alpaca.json), and [PIQA](https://specinfer.s3.us-east-2.amazonaws.com/prompts/piqa.json).
+
+## TODOs
+
+FlexFlow Serve is still under active development. We currently focus on the following tasks and strongly welcome all contributions from bug fixes to new features and extensions.
+
+* AMD support. We are actively working on supporting FlexFlow Serve on AMD GPUs and welcome any contributions to this effort.
+
+## Acknowledgements
+This project is initiated by members from CMU, Stanford, and UCSD. We will be continuing developing and supporting FlexFlow Serve. Please cite FlexFlow Serve as:
+
+``` bibtex
+@misc{miao2023specinfer,
+ title={SpecInfer: Accelerating Generative Large Language Model Serving with Speculative Inference and Token Tree Verification},
+ author={Xupeng Miao and Gabriele Oliaro and Zhihao Zhang and Xinhao Cheng and Zeyu Wang and Rae Ying Yee Wong and Alan Zhu and Lijie Yang and Xiaoxiang Shi and Chunan Shi and Zhuoming Chen and Daiyaan Arfeen and Reyna Abhyankar and Zhihao Jia},
+ year={2023},
+ eprint={2305.09781},
+ archivePrefix={arXiv},
+ primaryClass={cs.CL}
+}
+```
+
+## License
+FlexFlow uses Apache License 2.0.
diff --git a/TRAIN.md b/TRAIN.md
new file mode 100644
index 0000000000..1595274a4c
--- /dev/null
+++ b/TRAIN.md
@@ -0,0 +1,65 @@
+# FlexFlow Train: Distributed DNN Training with Flexible Parallelization Strategies.
+FlexFlow Train is a deep learning framework that accelerates distributed DNN training by automatically searching for efficient parallelization strategies. FlexFlow Train provides a drop-in replacement for PyTorch and TensorFlow Keras. Running existing PyTorch and Keras programs in FlexFlow oTrain nly requires [a few lines of changes to the program](https://flexflow.ai/keras).
+
+
+## PyTorch Support
+Users can also use FlexFlow Train to optimize the parallelization performance of existing PyTorch models in two steps. First, a PyTorch model can be exported to the FlexFlow model format using `flexflow.torch.fx.torch_to_flexflow`.
+```python
+import torch
+import flexflow.torch.fx as fx
+
+model = MyPyTorchModule()
+fx.torch_to_flexflow(model, "mymodel.ff")
+```
+
+Second, a FlexFlow Train program can directly import a previously saved PyTorch model and [autotune](https://www.usenix.org/conference/osdi22/presentation/unger) the parallelization performance for a given parallel machine.
+
+```python
+from flexflow.pytorch.model import PyTorchModel
+
+def top_level_task():
+ torch_model = PyTorchModel("mymodel.ff")
+ output_tensor = torch_model.apply(ffmodel, input_tensor)
+ ## Model compilation
+ ffmodel.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
+ ## Model training
+ (x_train, y_train) = cifar10.load_data()
+ ffmodel.fit(x_train, y_train, epochs=30)
+```
+
+**More FlexFlow PyTorch examples**: see the [pytorch examples folder](https://github.com/flexflow/FlexFlow/tree/master/examples/python/pytorch).
+
+## TensorFlow Keras and ONNX Support
+FlexFlow Train prioritizes PyTorch compatibility, but also includes frontends for [Tensorflow Keras](./docs/source/keras.rst) and [ONNX](./docs/source/onnx.rst) models.
+
+## C++ Interface
+For users that prefer to program in C/C++. FlexFlow Train supports a C++ program inference that is equivalent to its Python APIs.
+
+**More FlexFlow C++ examples**: see the [C++ examples folder](https://github.com/flexflow/FlexFlow/tree/master/examples/cpp).
+
+
+## Command-Line Flags
+In addition to setting runtime configurations in a FlexFlow Train Python/C++ program, the FlexFlow Train runtime also accepts command-line arguments for various runtime parameters:
+
+FlexFlow training flags:
+* `-e` or `--epochs`: number of total epochs to run (default: 1)
+* `-b` or `--batch-size`: global batch size in each iteration (default: 64)
+* `-p` or `--print-freq`: print frequency (default: 10)
+* `-d` or `--dataset`: path to the training dataset. If not set, synthetic data is used to conduct training.
+
+Legion runtime flags:
+* `-ll:gpu`: number of GPU processors to use on each node (default: 0)
+* `-ll:fsize`: size of device memory on each GPU (in MB)
+* `-ll:zsize`: size of zero-copy memory (pinned DRAM with direct GPU access) on each node (in MB). This is used for prefecthing training images from disk.
+* `-ll:cpu`: number of data loading workers (default: 4)
+* `-ll:util`: number of utility threads to create per process (default: 1)
+* `-ll:bgwork`: number of background worker threads to create per process (default: 1)
+
+Performance auto-tuning flags:
+* `--search-budget` or `--budget`: the number of iterations for the MCMC search (default: 0)
+* `--search-alpha` or `--alpha`: a hyper-parameter for the search procedure (default: 0.05)
+* `--export-strategy` or `--export`: path to export the best discovered strategy (default: None)
+* `--import-strategy` or `--import`: path to import a previous saved strategy (default: None)
+* `--enable-parameter-parallel`: allow FlexFlow Train to explore parameter parallelism for performance auto-tuning. (By default FlexFlow Train only considers data and model parallelism.)
+* `--enable-attribute-parallel`: allow FlexFlow Train to explore attribute parallelism for performance auto-tuning. (By default FlexFlow Train only considers data and model parallelism.)
+For performance tuning related flags: see [performance autotuning](https://flexflow.ai/search).
diff --git a/cmake/hip.cmake b/cmake/hip.cmake
new file mode 100644
index 0000000000..b32d68d608
--- /dev/null
+++ b/cmake/hip.cmake
@@ -0,0 +1,11 @@
+if (NOT FF_HIP_ARCH STREQUAL "")
+ if (FF_HIP_ARCH STREQUAL "all")
+ set(FF_HIP_ARCH "gfx900,gfx902,gfx904,gfx906,gfx908,gfx909,gfx90a,gfx90c,gfx940,gfx1010,gfx1011,gfx1012,gfx1013,gfx1030,gfx1031,gfx1032,gfx1033,gfx1034,gfx1035,gfx1036,gfx1100,gfx1101,gfx1102,gfx1103")
+ endif()
+ string(REPLACE "," " " HIP_ARCH_LIST "${FF_HIP_ARCH}")
+endif()
+
+message(STATUS "FF_HIP_ARCH: ${FF_HIP_ARCH}")
+if(FF_GPU_BACKEND STREQUAL "hip_rocm")
+ set(HIP_CLANG_PATH ${ROCM_PATH}/llvm/bin CACHE STRING "Path to the clang compiler by ROCM" FORCE)
+endif()
diff --git a/cmake/legion.cmake b/cmake/legion.cmake
index b4cfad20e2..b83cbc52f2 100644
--- a/cmake/legion.cmake
+++ b/cmake/legion.cmake
@@ -142,8 +142,11 @@ else()
set(Legion_USE_HIP ON CACHE BOOL "enable Legion_USE_HIP" FORCE)
if (FF_GPU_BACKEND STREQUAL "hip_cuda")
set(Legion_HIP_TARGET "CUDA" CACHE STRING "Legion_HIP_TARGET CUDA" FORCE)
+ set(Legion_CUDA_ARCH ${FF_CUDA_ARCH} CACHE STRING "Legion CUDA ARCH" FORCE)
elseif(FF_GPU_BACKEND STREQUAL "hip_rocm")
set(Legion_HIP_TARGET "ROCM" CACHE STRING "Legion HIP_TARGET ROCM" FORCE)
+ set(Legion_HIP_ARCH ${FF_HIP_ARCH} CACHE STRING "Legion HIP ARCH" FORCE)
+ message(STATUS "Legion_HIP_ARCH: ${Legion_HIP_ARCH}")
endif()
endif()
set(Legion_REDOP_COMPLEX OFF CACHE BOOL "disable complex")
diff --git a/conda/environment.yml b/conda/environment.yml
index 2069acccdf..c1acd7b3da 100644
--- a/conda/environment.yml
+++ b/conda/environment.yml
@@ -7,6 +7,7 @@ dependencies:
- cffi>=1.11.0
- Pillow
- pybind11
+ - rust
- cmake-build-extension
- pip
- pip:
diff --git a/conda/flexflow-cpu.yml b/conda/flexflow-cpu.yml
deleted file mode 100644
index cc6fcf4667..0000000000
--- a/conda/flexflow-cpu.yml
+++ /dev/null
@@ -1,20 +0,0 @@
-name: flexflow
-channels:
- - defaults
- - conda-forge
-dependencies:
- - python>=3.6
- - cffi>=1.11.0
- - Pillow
- - pybind11
- - cmake-build-extension
- - pytest
- - pip
- - pip:
- - qualname>=0.1.0
- - keras_preprocessing>=1.1.2
- - numpy>=1.16.0
- - torch --index-url https://download.pytorch.org/whl/cpu
- - torchaudio --index-url https://download.pytorch.org/whl/cpu
- - torchvision --index-url https://download.pytorch.org/whl/cpu
- - requests
diff --git a/conda/flexflow.yml b/conda/flexflow.yml
new file mode 100644
index 0000000000..9ff7f3957a
--- /dev/null
+++ b/conda/flexflow.yml
@@ -0,0 +1,26 @@
+name: flexflow
+channels:
+ - defaults
+ - conda-forge
+dependencies:
+ - python>=3.6
+ - cffi>=1.11.0
+ - Pillow
+ - pybind11
+ - rust
+ - cmake-build-extension
+ - pytest
+ - pip
+ - pip:
+ - qualname>=0.1.0
+ - keras_preprocessing>=1.1.2
+ - numpy>=1.16.0
+ - torch>=1.13.1 --index-url https://download.pytorch.org/whl/cpu
+ - torchaudio>=0.13.1 --index-url https://download.pytorch.org/whl/cpu
+ - torchvision>=0.14.1 --index-url https://download.pytorch.org/whl/cpu
+ - regex
+ - onnx
+ - transformers>=4.31.0
+ - sentencepiece
+ - einops
+ - requests
diff --git a/config/config.inc b/config/config.inc
index b146d228d5..7f1f0ffcf4 100644
--- a/config/config.inc
+++ b/config/config.inc
@@ -27,6 +27,19 @@ if [ -n "$INSTALL_DIR" ]; then
SET_INSTALL_DIR="-DCMAKE_INSTALL_PREFIX=${INSTALL_DIR}"
fi
+if [ "$INFERENCE_TESTS" = "ON" ]; then
+ SET_INFERENCE_TESTS="-DINFERENCE_TESTS=ON"
+else
+ SET_INFERENCE_TESTS="-DINFERENCE_TESTS=OFF"
+fi
+
+#set cmake prefix path dir
+if [ -n "$LIBTORCH_PATH" ]; then
+ SET_LIBTORCH_PATH="-DLIBTORCH_PATH=${LIBTORCH_PATH}"
+else
+ SET_LIBTORCH_PATH=""
+fi
+
# set build type
if [ -n "$BUILD_TYPE" ]; then
SET_BUILD="-DCMAKE_BUILD_TYPE=${BUILD_TYPE}"
@@ -37,6 +50,11 @@ if [ -n "$FF_CUDA_ARCH" ]; then
SET_CUDA_ARCH="-DFF_CUDA_ARCH=${FF_CUDA_ARCH}"
fi
+# set HIP Arch
+if [ -n "$FF_HIP_ARCH" ]; then
+ SET_HIP_ARCH="-DFF_HIP_ARCH=${FF_HIP_ARCH}"
+fi
+
# set CUDA dir
if [ -n "$CUDA_DIR" ]; then
SET_CUDA="-DCUDA_PATH=${CUDA_DIR}"
@@ -106,6 +124,13 @@ elif [ "$FF_BUILD_ALL_EXAMPLES" = "OFF" ]; then
else
SET_EXAMPLES="-DFF_BUILD_ALL_EXAMPLES=ON"
fi
+if [ "$FF_BUILD_ALL_INFERENCE_EXAMPLES" = "ON" ]; then
+ SET_INFERENCE_EXAMPLES="-DFF_BUILD_ALL_INFERENCE_EXAMPLES=ON"
+elif [ "$FF_BUILD_ALL_INFERENCE_EXAMPLES" = "OFF" ]; then
+ SET_INFERENCE_EXAMPLES="-DFF_BUILD_ALL_INFERENCE_EXAMPLES=OFF"
+else
+ SET_INFERENCE_EXAMPLES="-DFF_BUILD_ALL_INFERENCE_EXAMPLES=ON"
+fi
# enable C++ unit tests
if [ "$FF_BUILD_UNIT_TESTS" = "ON" ]; then
@@ -154,6 +179,11 @@ if [ -n "$FF_MAX_DIM" ]; then
SET_MAX_DIM="-DFF_MAX_DIM=${FF_MAX_DIM}"
fi
+#set LEGION_MAX_RETURN_SIZE
+if [ -n "$LEGION_MAX_RETURN_SIZE" ]; then
+ SET_LEGION_MAX_RETURN_SIZE="-DLEGION_MAX_RETURN_SIZE=${LEGION_MAX_RETURN_SIZE}"
+fi
+
# set ROCM path
if [ -n "$ROCM_PATH" ]; then
SET_ROCM_PATH="-DROCM_PATH=${ROCM_PATH}"
@@ -197,7 +227,7 @@ if [ -n "$FF_GPU_BACKEND" ]; then
fi
fi
-CMAKE_FLAGS="-DCUDA_USE_STATIC_CUDA_RUNTIME=OFF -DLegion_HIJACK_CUDART=OFF ${SET_CC} ${SET_CXX} ${SET_INSTALL_DIR} ${SET_BUILD} ${SET_CUDA_ARCH} ${SET_CUDA} ${SET_CUDNN} ${SET_PYTHON} ${SET_BUILD_LEGION_ONLY} ${SET_NCCL} ${SET_NCCL_DIR} ${SET_LEGION_NETWORKS} ${SET_EXAMPLES} ${SET_USE_PREBUILT_LEGION} ${SET_USE_PREBUILT_NCCL} ${SET_USE_ALL_PREBUILT_LIBRARIES} ${SET_BUILD_UNIT_TESTS} ${SET_AVX2} ${SET_MAX_DIM} ${SET_ROCM_PATH} ${SET_FF_GPU_BACKEND}"
+CMAKE_FLAGS="-DCUDA_USE_STATIC_CUDA_RUNTIME=OFF -DLegion_HIJACK_CUDART=OFF ${SET_CC} ${SET_CXX} ${SET_INSTALL_DIR} ${SET_INFERENCE_TESTS} ${SET_LIBTORCH_PATH} ${SET_BUILD} ${SET_CUDA_ARCH} ${SET_CUDA} ${SET_CUDNN} ${SET_HIP_ARCH} ${SET_PYTHON} ${SET_BUILD_LEGION_ONLY} ${SET_NCCL} ${SET_NCCL_DIR} ${SET_LEGION_NETWORKS} ${SET_EXAMPLES} ${SET_INFERENCE_EXAMPLES} ${SET_USE_PREBUILT_LEGION} ${SET_USE_PREBUILT_NCCL} ${SET_USE_ALL_PREBUILT_LIBRARIES} ${SET_BUILD_UNIT_TESTS} ${SET_AVX2} ${SET_MAX_DIM} ${SET_LEGION_MAX_RETURN_SIZE} ${SET_ROCM_PATH} ${SET_FF_GPU_BACKEND}"
function run_cmake() {
SRC_LOCATION=${SRC_LOCATION:=`dirname $0`/../}
diff --git a/config/config.linux b/config/config.linux
index 509a713e66..056ebe0fed 100755
--- a/config/config.linux
+++ b/config/config.linux
@@ -1,5 +1,4 @@
#!/bin/bash
-
# set the CC and CXX, usually it is not needed as cmake can detect it
# set CC and CXX to mpicc and mpic++ when enable gasnet
# CC=mpicc
@@ -16,11 +15,26 @@
# set build type
BUILD_TYPE=${BUILD_TYPE:-Release}
+INFERENCE_TESTS=${INFERENCE_TESTS:-OFF}
+LIBTORCH_PATH=${LIBTORCH_PATH:-"$(realpath ../..)/libtorch"}
+if [[ "$INFERENCE_TESTS" == "ON" && ! -d "$LIBTORCH_PATH" ]]; then
+ cwd="$(pwd)"
+ cd ../..
+ wget https://download.pytorch.org/libtorch/nightly/cpu/libtorch-shared-with-deps-latest.zip
+ unzip libtorch-shared-with-deps-latest.zip
+ rm libtorch-shared-with-deps-latest.zip
+ LIBTORCH_PATH="$(pwd)/libtorch"
+ cd "$cwd"
+fi
+
# set CUDA Arch to the desired GPU architecture(s) to target (e.g. pass "FF_CUDA_ARCH=60" for Pascal).
# To pass more than one value, separate architecture numbers with a comma (e.g. FF_CUDA_ARCH=70,75).
# Alternatively, set "FF_CUDA_ARCH=autodetect" to build FlexFlow for all architectures detected on the machine,
# or set "FF_CUDA_ARCH=all" to build FlexFlow for all supported GPU architectures
FF_CUDA_ARCH=${FF_CUDA_ARCH:-"autodetect"}
+# FF_HIP_ARCH only supports building for a specific AMD architecture, a list of architectures separated by a comma
+# or all available architectures. TODO: support autodetect
+FF_HIP_ARCH=${FF_HIP_ARCH:-"all"}
# set CUDNN dir in case cmake cannot autodetect a path
CUDNN_DIR=${CUDNN_DIR:-"/usr/local/cuda"}
@@ -45,6 +59,7 @@ FF_UCX_URL=${FF_UCX_URL:-""}
# build C++ examples
FF_BUILD_ALL_EXAMPLES=${FF_BUILD_ALL_EXAMPLES:-OFF}
+FF_BUILD_ALL_INFERENCE_EXAMPLES=${FF_BUILD_ALL_INFERENCE_EXAMPLES:-ON}
# build C++ unit tests
FF_BUILD_UNIT_TESTS=${FF_BUILD_UNIT_TESTS:-OFF}
@@ -65,6 +80,9 @@ FF_MAX_DIM=${FF_MAX_DIM:-5}
# set BUILD_LEGION_ONLY
BUILD_LEGION_ONLY=${BUILD_LEGION_ONLY:-OFF}
+# set LEGION_MAX_RETURN_SIZE
+LEGION_MAX_RETURN_SIZE=${LEGION_MAX_RETURN_SIZE:-262144}
+
# set ROCM path
ROCM_PATH=${ROCM_PATH:-"/opt/rocm"}
@@ -82,7 +100,7 @@ fi
function get_build_configs() {
# Create a string with the values of the variables set in this script
- BUILD_CONFIGS="FF_CUDA_ARCH=${FF_CUDA_ARCH} CUDNN_DIR=${CUDNN_DIR} CUDA_DIR=${CUDA_DIR} NCCL_DIR=${NCCL_DIR} FF_USE_PYTHON=${FF_USE_PYTHON} BUILD_LEGION_ONLY=${BUILD_LEGION_ONLY} FF_GASNET_CONDUIT=${FF_GASNET_CONDUIT} FF_UCX_URL=${FF_UCX_URL} FF_LEGION_NETWORKS=${FF_LEGION_NETWORKS} FF_BUILD_ALL_EXAMPLES=${FF_BUILD_ALL_EXAMPLES} FF_BUILD_UNIT_TESTS=${FF_BUILD_UNIT_TESTS} FF_USE_PREBUILT_NCCL=${FF_USE_PREBUILT_NCCL} FF_USE_PREBUILT_LEGION=${FF_USE_PREBUILT_LEGION} FF_USE_ALL_PREBUILT_LIBRARIES=${FF_USE_ALL_PREBUILT_LIBRARIES} FF_USE_AVX2=${FF_USE_AVX2} FF_MAX_DIM=${FF_MAX_DIM} ROCM_PATH=${ROCM_PATH} FF_GPU_BACKEND=${FF_GPU_BACKEND} INSTALL_DIR=${INSTALL_DIR}"
+ BUILD_CONFIGS="FF_CUDA_ARCH=${FF_CUDA_ARCH} FF_HIP_ARCH=${FF_HIP_ARCH} CUDNN_DIR=${CUDNN_DIR} CUDA_DIR=${CUDA_DIR} NCCL_DIR=${NCCL_DIR} FF_USE_PYTHON=${FF_USE_PYTHON} BUILD_LEGION_ONLY=${BUILD_LEGION_ONLY} FF_GASNET_CONDUIT=${FF_GASNET_CONDUIT} FF_UCX_URL=${FF_UCX_URL} FF_LEGION_NETWORKS=${FF_LEGION_NETWORKS} FF_BUILD_ALL_EXAMPLES=${FF_BUILD_ALL_EXAMPLES} FF_BUILD_ALL_INFERENCE_EXAMPLES=${FF_BUILD_ALL_INFERENCE_EXAMPLES} FF_BUILD_UNIT_TESTS=${FF_BUILD_UNIT_TESTS} FF_USE_PREBUILT_NCCL=${FF_USE_PREBUILT_NCCL} FF_USE_PREBUILT_LEGION=${FF_USE_PREBUILT_LEGION} FF_USE_ALL_PREBUILT_LIBRARIES=${FF_USE_ALL_PREBUILT_LIBRARIES} FF_USE_AVX2=${FF_USE_AVX2} FF_MAX_DIM=${FF_MAX_DIM} ROCM_PATH=${ROCM_PATH} FF_GPU_BACKEND=${FF_GPU_BACKEND}"
}
if [[ -n "$1" && ( "$1" == "CMAKE_FLAGS" || "$1" == "CUDA_PATH" ) ]]; then
diff --git a/deps/tokenizers-cpp b/deps/tokenizers-cpp
new file mode 160000
index 0000000000..4f42c9fa74
--- /dev/null
+++ b/deps/tokenizers-cpp
@@ -0,0 +1 @@
+Subproject commit 4f42c9fa74946d70af86671a3804b6f2433e5dac
diff --git a/docker/build.sh b/docker/build.sh
index a254fb3116..6603d919f5 100755
--- a/docker/build.sh
+++ b/docker/build.sh
@@ -2,7 +2,7 @@
set -euo pipefail
# Usage: ./build.sh
-# Optional environment variables: FF_GPU_BACKEND, cuda_version
+# Optional environment variables: FF_GPU_BACKEND, cuda_version, hip_version
# Cd into $FF_HOME. Assumes this script is in $FF_HOME/docker
cd "${BASH_SOURCE[0]%/*}/.."
@@ -11,6 +11,7 @@ cd "${BASH_SOURCE[0]%/*}/.."
image=${1:-flexflow}
FF_GPU_BACKEND=${FF_GPU_BACKEND:-cuda}
cuda_version=${cuda_version:-"empty"}
+hip_version=${hip_version:-"empty"}
python_version=${python_version:-latest}
# Check docker image name
@@ -29,58 +30,98 @@ else
echo "Building $image docker image with default GPU backend: cuda"
fi
+# base image to use when building the flexflow environment docker image.
+ff_environment_base_image="ubuntu:20.04"
+# gpu backend version suffix for the docker image.
+gpu_backend_version=""
+
if [[ "${FF_GPU_BACKEND}" == "cuda" || "${FF_GPU_BACKEND}" == "hip_cuda" ]]; then
# Autodetect cuda version if not specified
if [[ $cuda_version == "empty" ]]; then
- cuda_version=$(command -v nvcc >/dev/null 2>&1 && nvcc --version | grep "release" | awk '{print $NF}')
+ # shellcheck disable=SC2015
+ cuda_version=$(command -v nvcc >/dev/null 2>&1 && nvcc --version | grep "release" | awk '{print $NF}' || true)
# Change cuda_version eg. V11.7.99 to 11.7
cuda_version=${cuda_version:1:4}
+ if [[ -z "$cuda_version" ]]; then
+ echo "Could not detect CUDA version. Please specify one manually by setting the 'cuda_version' env."
+ exit 1
+ fi
fi
# Check that CUDA version is supported, and modify cuda version to include default subsubversion
- if [[ "$cuda_version" == @(11.1|11.3|11.7) ]]; then
+ if [[ "$cuda_version" == @(11.1|11.3|11.7|12.0|12.1) ]]; then
cuda_version_input=${cuda_version}.1
elif [[ "$cuda_version" == @(11.2|11.5|11.6) ]]; then
cuda_version_input=${cuda_version}.2
- elif [[ "$cuda_version" == @(11.8) ]]; then
+ elif [[ "$cuda_version" == @(11.4) ]]; then
+ cuda_version_input=${cuda_version}.3
+ elif [[ "$cuda_version" == @(11.8|12.2) ]]; then
cuda_version_input=${cuda_version}.0
else
- echo "cuda_version is not supported, please choose among {11.1|11.2|11.3|11.5|11.6|11.7|11.8}"
+ echo "cuda_version is not supported, please choose among {11.1|11.2|11.3|11.4|11.5|11.6|11.7|11.8|12.0|12.1|12.2}"
exit 1
fi
- # Set cuda version suffix to docker image name
+ # Use CUDA 12.0 for all versions greater or equal to 12.0 for now
+ if [[ "$cuda_version" == @(12.1|12.2|12.3|12.4|12.5|12.6|12.7|12.8|12.9) ]]; then
+ cuda_version=12.0
+ cuda_version_input=${cuda_version}.1
+ fi
echo "Building $image docker image with CUDA $cuda_version"
- cuda_version="-${cuda_version}"
-else
- # Empty cuda version suffix for non-CUDA images
- cuda_version=""
- # Pick a default CUDA version for the base docker image from NVIDIA
- cuda_version_input="11.8.0"
+ ff_environment_base_image="nvidia/cuda:${cuda_version_input}-cudnn8-devel-ubuntu20.04"
+ gpu_backend_version="-${cuda_version}"
+fi
+
+if [[ "${FF_GPU_BACKEND}" == "hip_rocm" || "${FF_GPU_BACKEND}" == "hip_cuda" ]]; then
+ # Autodetect HIP version if not specified
+ if [[ $hip_version == "empty" ]]; then
+ # shellcheck disable=SC2015
+ hip_version=$(command -v hipcc >/dev/null 2>&1 && hipcc --version | grep "HIP version:" | awk '{print $NF}' || true)
+ # Change hip_version eg. 5.6.31061-8c743ae5d to 5.6
+ hip_version=${hip_version:0:3}
+ if [[ -z "$hip_version" ]]; then
+ echo "Could not detect HIP version. Please specify one manually by setting the 'hip_version' env."
+ exit 1
+ fi
+ fi
+ # Check that HIP version is supported
+ if [[ "$hip_version" != @(5.3|5.4|5.5|5.6) ]]; then
+ echo "hip_version is not supported, please choose among {5.3, 5.4, 5.5, 5.6}"
+ exit 1
+ fi
+ echo "Building $image docker image with HIP $hip_version"
+ if [[ "${FF_GPU_BACKEND}" == "hip_rocm" ]]; then
+ gpu_backend_version="-${hip_version}"
+ fi
fi
+# Get number of cores available on the machine. Build with all cores but one, to prevent RAM choking
+cores_available=$(nproc --all)
+n_build_cores=$(( cores_available -1 ))
+
# check python_version
if [[ "$python_version" != @(3.8|3.9|3.10|3.11|latest) ]]; then
echo "python_version not supported!"
exit 0
fi
-docker build --build-arg "FF_GPU_BACKEND=${FF_GPU_BACKEND}" --build-arg "cuda_version=${cuda_version_input}" --build-arg "python_version=${python_version}" -t "flexflow-environment-${FF_GPU_BACKEND}${cuda_version}" -f docker/flexflow-environment/Dockerfile .
+docker build --build-arg "ff_environment_base_image=${ff_environment_base_image}" --build-arg "N_BUILD_CORES=${n_build_cores}" --build-arg "FF_GPU_BACKEND=${FF_GPU_BACKEND}" --build-arg "hip_version=${hip_version}" --build-arg "python_version=${python_version}" -t "flexflow-environment-${FF_GPU_BACKEND}${gpu_backend_version}" -f docker/flexflow-environment/Dockerfile .
# If the user only wants to build the environment image, we are done
if [[ "$image" == "flexflow-environment" ]]; then
exit 0
fi
-# Gather arguments needed to build the FlexFlow image
-# Get number of cores available on the machine. Build with all cores but one, to prevent RAM choking
-cores_available=$(nproc --all)
-n_build_cores=$(( cores_available -1 ))
+# Done with flexflow-environment image
+
+###########################################################################################
-# If FF_CUDA_ARCH is set to autodetect, we need to perform the autodetection here because the Docker
-# image will not have access to GPUs during the build phase (due to a Docker restriction). In all other
-# cases, we pass the value of FF_CUDA_ARCH directly to Cmake.
-if [[ "${FF_CUDA_ARCH:-autodetect}" == "autodetect" ]]; then
- # Get CUDA architecture(s), if GPUs are available
- cat << EOF > ./get_gpu_arch.cu
+# Build flexflow image if requested
+if [[ "${FF_GPU_BACKEND}" == "cuda" || "${FF_GPU_BACKEND}" == "hip_cuda" ]]; then
+ # If FF_CUDA_ARCH is set to autodetect, we need to perform the autodetection here because the Docker
+ # image will not have access to GPUs during the build phase (due to a Docker restriction). In all other
+ # cases, we pass the value of FF_CUDA_ARCH directly to Cmake.
+ if [[ "${FF_CUDA_ARCH:-autodetect}" == "autodetect" ]]; then
+ # Get CUDA architecture(s), if GPUs are available
+ cat << EOF > ./get_gpu_arch.cu
#include
int main() {
int count = 0;
@@ -94,24 +135,25 @@ int main() {
return 0;
}
EOF
- gpu_arch_codes=""
- if command -v nvcc &> /dev/null
- then
- nvcc ./get_gpu_arch.cu -o ./get_gpu_arch
- gpu_arch_codes="$(./get_gpu_arch)"
- fi
- gpu_arch_codes="$(echo "$gpu_arch_codes" | xargs -n1 | sort -u | xargs)"
- gpu_arch_codes="${gpu_arch_codes// /,}"
- rm -f ./get_gpu_arch.cu ./get_gpu_arch
-
- if [[ -n "$gpu_arch_codes" ]]; then
- echo "Host machine has GPUs with architecture codes: $gpu_arch_codes"
- echo "Configuring FlexFlow to build for the $gpu_arch_codes code(s)."
- FF_CUDA_ARCH="${gpu_arch_codes}"
- export FF_CUDA_ARCH
- else
- echo "FF_CUDA_ARCH is set to 'autodetect', but the host machine does not have any compatible GPUs."
- exit 1
+ gpu_arch_codes=""
+ if command -v nvcc &> /dev/null
+ then
+ nvcc ./get_gpu_arch.cu -o ./get_gpu_arch
+ gpu_arch_codes="$(./get_gpu_arch)"
+ fi
+ gpu_arch_codes="$(echo "$gpu_arch_codes" | xargs -n1 | sort -u | xargs)"
+ gpu_arch_codes="${gpu_arch_codes// /,}"
+ rm -f ./get_gpu_arch.cu ./get_gpu_arch
+
+ if [[ -n "$gpu_arch_codes" ]]; then
+ echo "Host machine has GPUs with architecture codes: $gpu_arch_codes"
+ echo "Configuring FlexFlow to build for the $gpu_arch_codes code(s)."
+ FF_CUDA_ARCH="${gpu_arch_codes}"
+ export FF_CUDA_ARCH
+ else
+ echo "FF_CUDA_ARCH is set to 'autodetect', but the host machine does not have any compatible GPUs."
+ exit 1
+ fi
fi
fi
@@ -121,4 +163,4 @@ fi
# Set value of BUILD_CONFIGS
get_build_configs
-docker build --build-arg "N_BUILD_CORES=${n_build_cores}" --build-arg "FF_GPU_BACKEND=${FF_GPU_BACKEND}" --build-arg "BUILD_CONFIGS=${BUILD_CONFIGS}" --build-arg "cuda_version=${cuda_version}" -t "flexflow-${FF_GPU_BACKEND}${cuda_version}" -f docker/flexflow/Dockerfile .
+docker build --build-arg "N_BUILD_CORES=${n_build_cores}" --build-arg "FF_GPU_BACKEND=${FF_GPU_BACKEND}" --build-arg "BUILD_CONFIGS=${BUILD_CONFIGS}" --build-arg "gpu_backend_version=${gpu_backend_version}" -t "flexflow-${FF_GPU_BACKEND}${gpu_backend_version}" -f docker/flexflow/Dockerfile .
diff --git a/docker/flexflow-environment/Dockerfile b/docker/flexflow-environment/Dockerfile
index 7132276afe..524f179e7a 100644
--- a/docker/flexflow-environment/Dockerfile
+++ b/docker/flexflow-environment/Dockerfile
@@ -1,12 +1,11 @@
-ARG cuda_version
-FROM nvidia/cuda:${cuda_version}-cudnn8-devel-ubuntu20.04
-ARG python_version
+ARG ff_environment_base_image
+FROM ${ff_environment_base_image}
LABEL org.opencontainers.image.source=https://github.com/flexflow/FlexFlow
LABEL org.opencontainers.image.description="FlexFlow environment container"
# Install basic dependencies
-RUN apt-get update && apt-get install -y --no-install-recommends wget sudo binutils git zlib1g-dev lsb-release nano libhdf5-dev && \
+RUN apt-get update && apt-get install -y --no-install-recommends wget sudo binutils git zlib1g-dev lsb-release nano gdb libhdf5-dev && \
rm -rf /var/lib/apt/lists/* /etc/apt/sources.list.d/cuda.list /etc/apt/sources.list.d/nvidia-ml.list && \
apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends software-properties-common && \
apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y --no-install-recommends build-essential apt-utils \
@@ -17,6 +16,7 @@ RUN apt-get update && apt-get install -y --no-install-recommends wget sudo binut
apt-get upgrade -y libstdc++6
# Install Python3 with Miniconda
+ARG python_version
RUN echo "current python version is ${python_version}"
RUN echo "downloading python from miniconda"
RUN if [ "${python_version}" = "3.8" ]; then \
@@ -81,13 +81,39 @@ RUN if [ "${python_version}" = "3.8" ]; then \
# in the container. It also attempts to install packages for a graphical install.
# For our container, we don't need `hip-runtime-nvidia`
ARG FF_GPU_BACKEND "cuda"
+ARG hip_version "5.6"
+ARG N_BUILD_CORES
+# set MAKEFLAGS to speedup any dependency that uses make
+ENV MAKEFLAGS "${MAKEFLAGS} -j${N_BUILD_CORES}"
+
RUN if [ "$FF_GPU_BACKEND" = "hip_cuda" ] || [ "$FF_GPU_BACKEND" = "hip_rocm" ]; then \
echo "FF_GPU_BACKEND: ${FF_GPU_BACKEND}. Installing HIP dependencies"; \
- wget https://repo.radeon.com/amdgpu-install/22.20.5/ubuntu/bionic/amdgpu-install_22.20.50205-1_all.deb; \
- apt-get install -y ./amdgpu-install_22.20.50205-1_all.deb; \
- rm ./amdgpu-install_22.20.50205-1_all.deb; \
+ # Check that hip_version is one of 5.3,5.4,5.5,5.6
+ if [ "$hip_version" != "5.3" ] && [ "$hip_version" != "5.4" ] && [ "$hip_version" != "5.5" ] && [ "$hip_version" != "5.6" ]; then \
+ echo "hip_version '${hip_version}' is not supported, please choose among {5.3, 5.4, 5.5, 5.6}"; \
+ exit 1; \
+ fi; \
+ # Compute script name and url given the version
+ AMD_GPU_SCRIPT_NAME=amdgpu-install_5.6.50600-1_all.deb; \
+ if [ "$hip_version" = "5.3" ]; then \
+ AMD_GPU_SCRIPT_NAME=amdgpu-install_5.3.50300-1_all.deb; \
+ elif [ "$hip_version" = "5.4" ]; then \
+ AMD_GPU_SCRIPT_NAME=amdgpu-install_5.4.50400-1_all.deb; \
+ elif [ "$hip_version" = "5.5" ]; then \
+ AMD_GPU_SCRIPT_NAME=amdgpu-install_5.5.50500-1_all.deb; \
+ fi; \
+ AMD_GPU_SCRIPT_URL="https://repo.radeon.com/amdgpu-install/${hip_version}/ubuntu/focal/${AMD_GPU_SCRIPT_NAME}"; \
+ # Download and install AMD GPU software with ROCM and HIP support
+ wget $AMD_GPU_SCRIPT_URL; \
+ apt-get install -y ./${AMD_GPU_SCRIPT_NAME}; \
+ rm ./${AMD_GPU_SCRIPT_NAME}; \
amdgpu-install -y --usecase=hip,rocm --no-dkms; \
- apt-get install -y hip-dev hipblas miopen-hip rocm-hip-sdk; \
+ apt-get install -y hip-dev hipblas miopen-hip rocm-hip-sdk rocm-device-libs; \
+ # Install protobuf v3.20.x manually
+ apt-get update -y && sudo apt-get install -y pkg-config zip g++ zlib1g-dev autoconf automake libtool make; \
+ git clone -b 3.20.x https://github.com/protocolbuffers/protobuf.git; cd protobuf/ ; git submodule update --init --recursive; \
+ ./autogen.sh; ./configure; cores_available=$(nproc --all); n_build_cores=$(( cores_available -1 )); \
+ if (( n_build_cores < 1 )) ; then n_build_cores=1 ; fi; make -j $n_build_cores; make install; ldconfig; cd .. ; \
else \
echo "FF_GPU_BACKEND: ${FF_GPU_BACKEND}. Skipping installing HIP dependencies"; \
fi
@@ -102,7 +128,11 @@ ENV CUDA_DIR /usr/local/cuda
RUN conda install -c conda-forge cmake make pillow cmake-build-extension pybind11 numpy pandas keras-preprocessing
# Install CPU-only Pytorch and related dependencies
RUN conda install pytorch torchvision torchaudio cpuonly -c pytorch
-RUN conda install -c conda-forge onnx transformers sentencepiece
+RUN conda install -c conda-forge onnx transformers>=4.31.0 sentencepiece einops
RUN pip3 install tensorflow
-ENTRYPOINT ["/bin/bash"]
\ No newline at end of file
+# Install Rust
+RUN curl https://sh.rustup.rs -sSf | sh -s -- -y
+ENV PATH /root/.cargo/bin:$PATH
+
+ENTRYPOINT ["/bin/bash"]
diff --git a/docker/flexflow/Dockerfile b/docker/flexflow/Dockerfile
index d25ede4b3b..ba592e2626 100644
--- a/docker/flexflow/Dockerfile
+++ b/docker/flexflow/Dockerfile
@@ -1,6 +1,6 @@
ARG FF_GPU_BACKEND "cuda"
-ARG cuda_version ""
-FROM flexflow-environment-$FF_GPU_BACKEND$cuda_version:latest
+ARG gpu_backend_version ""
+FROM flexflow-environment-$FF_GPU_BACKEND$gpu_backend_version:latest
LABEL org.opencontainers.image.source=https://github.com/flexflow/FlexFlow
LABEL org.opencontainers.image.description="FlexFlow container"
diff --git a/docker/publish.sh b/docker/publish.sh
index b8668d3c0e..c70419a9cc 100755
--- a/docker/publish.sh
+++ b/docker/publish.sh
@@ -2,7 +2,7 @@
set -euo pipefail
# Usage: ./publish.sh
-# Optional environment variables: FF_GPU_BACKEND, cuda_version
+# Optional environment variables: FF_GPU_BACKEND, cuda_version, hip_version
# Cd into directory holding this script
cd "${BASH_SOURCE[0]%/*}"
@@ -11,6 +11,7 @@ cd "${BASH_SOURCE[0]%/*}"
image=${1:-flexflow}
FF_GPU_BACKEND=${FF_GPU_BACKEND:-cuda}
cuda_version=${cuda_version:-"empty"}
+hip_version=${hip_version:-"empty"}
# Check docker image name
if [[ "${image}" != @(flexflow-environment|flexflow) ]]; then
@@ -18,6 +19,9 @@ if [[ "${image}" != @(flexflow-environment|flexflow) ]]; then
exit 1
fi
+# gpu backend version suffix for the docker image.
+gpu_backend_version=""
+
# Check GPU backend
if [[ "${FF_GPU_BACKEND}" != @(cuda|hip_cuda|hip_rocm|intel) ]]; then
echo "Error, value of FF_GPU_BACKEND (${FF_GPU_BACKEND}) is invalid. Pick between 'cuda', 'hip_cuda', 'hip_rocm' or 'intel'."
@@ -31,25 +35,50 @@ fi
if [[ "${FF_GPU_BACKEND}" == "cuda" || "${FF_GPU_BACKEND}" == "hip_cuda" ]]; then
# Autodetect cuda version if not specified
if [[ $cuda_version == "empty" ]]; then
- cuda_version=$(command -v nvcc >/dev/null 2>&1 && nvcc --version | grep "release" | awk '{print $NF}')
+ # shellcheck disable=SC2015
+ cuda_version=$(command -v nvcc >/dev/null 2>&1 && nvcc --version | grep "release" | awk '{print $NF}' || true)
# Change cuda_version eg. V11.7.99 to 11.7
cuda_version=${cuda_version:1:4}
+ if [[ -z "$cuda_version" ]]; then
+ echo "Could not detect CUDA version. Please specify one manually by setting the 'cuda_version' env."
+ exit 1
+ fi
fi
# Check that CUDA version is supported
- if [[ "$cuda_version" != @(11.1|11.3|11.7|11.2|11.5|11.6|11.8) ]]; then
- echo "cuda_version is not supported, please choose among {11.1|11.2|11.3|11.5|11.6|11.7|11.8}"
+ if [[ "$cuda_version" != @(11.1|11.2|11.3|11.4|11.5|11.6|11.7|11.8|12.0|12.1|12.2) ]]; then
+ echo "cuda_version is not supported, please choose among {11.1|11.2|11.3|11.4|11.5|11.6|11.7|11.8|12.0|12.1|12.2}"
exit 1
fi
# Set cuda version suffix to docker image name
echo "Publishing $image docker image with CUDA $cuda_version"
- cuda_version="-${cuda_version}"
-else
- # Empty cuda version suffix for non-CUDA images
- cuda_version=""
+ gpu_backend_version="-${cuda_version}"
+fi
+
+if [[ "${FF_GPU_BACKEND}" == "hip_rocm" || "${FF_GPU_BACKEND}" == "hip_cuda" ]]; then
+ # Autodetect HIP version if not specified
+ if [[ $hip_version == "empty" ]]; then
+ # shellcheck disable=SC2015
+ hip_version=$(command -v hipcc >/dev/null 2>&1 && hipcc --version | grep "HIP version:" | awk '{print $NF}' || true)
+ # Change hip_version eg. 5.6.31061-8c743ae5d to 5.6
+ hip_version=${hip_version:0:3}
+ if [[ -z "$hip_version" ]]; then
+ echo "Could not detect HIP version. Please specify one manually by setting the 'hip_version' env."
+ exit 1
+ fi
+ fi
+ # Check that HIP version is supported
+ if [[ "$hip_version" != @(5.3|5.4|5.5|5.6) ]]; then
+ echo "hip_version is not supported, please choose among {5.3, 5.4, 5.5, 5.6}"
+ exit 1
+ fi
+ echo "Pubilishing $image docker image with HIP $hip_version"
+ if [[ "${FF_GPU_BACKEND}" == "hip_rocm" ]]; then
+ gpu_backend_version="-${hip_version}"
+ fi
fi
# Check that image exists
-docker image inspect "${image}-${FF_GPU_BACKEND}${cuda_version}":latest > /dev/null
+docker image inspect "${image}-${FF_GPU_BACKEND}${gpu_backend_version}":latest > /dev/null
# Log into container registry
FLEXFLOW_CONTAINER_TOKEN=${FLEXFLOW_CONTAINER_TOKEN:-}
@@ -59,8 +88,8 @@ echo "$FLEXFLOW_CONTAINER_TOKEN" | docker login ghcr.io -u flexflow --password-s
# Tag image to be uploaded
git_sha=${GITHUB_SHA:-$(git rev-parse HEAD)}
if [ -z "$git_sha" ]; then echo "Commit hash cannot be detected, cannot publish the docker image to ghrc.io"; exit; fi
-docker tag "${image}-${FF_GPU_BACKEND}${cuda_version}":latest ghcr.io/flexflow/"${image}-${FF_GPU_BACKEND}${cuda_version}":latest
+docker tag "${image}-${FF_GPU_BACKEND}${gpu_backend_version}":latest ghcr.io/flexflow/"${image}-${FF_GPU_BACKEND}${gpu_backend_version}":latest
# Upload image
-docker push ghcr.io/flexflow/"${image}-${FF_GPU_BACKEND}${cuda_version}":latest
+docker push ghcr.io/flexflow/"${image}-${FF_GPU_BACKEND}${gpu_backend_version}":latest
diff --git a/docker/pull.sh b/docker/pull.sh
index f8624a1072..e5b6f26f3c 100755
--- a/docker/pull.sh
+++ b/docker/pull.sh
@@ -2,7 +2,7 @@
set -euo pipefail
# Usage: ./pull.sh
-# Optional environment variables: FF_GPU_BACKEND, cuda_version
+# Optional environment variables: FF_GPU_BACKEND, cuda_version, hip_version
# Cd into directory holding this script
cd "${BASH_SOURCE[0]%/*}"
@@ -11,6 +11,7 @@ cd "${BASH_SOURCE[0]%/*}"
image=${1:-flexflow}
FF_GPU_BACKEND=${FF_GPU_BACKEND:-cuda}
cuda_version=${cuda_version:-"empty"}
+hip_version=${hip_version:-"empty"}
# Check docker image name
if [[ "${image}" != @(flexflow-environment|flexflow) ]]; then
@@ -28,31 +29,63 @@ else
echo "Downloading $image docker image with default GPU backend: cuda"
fi
+# gpu backend version suffix for the docker image.
+gpu_backend_version=""
+
if [[ "${FF_GPU_BACKEND}" == "cuda" || "${FF_GPU_BACKEND}" == "hip_cuda" ]]; then
# Autodetect cuda version if not specified
if [[ $cuda_version == "empty" ]]; then
- cuda_version=$(command -v nvcc >/dev/null 2>&1 && nvcc --version | grep "release" | awk '{print $NF}')
+ # shellcheck disable=SC2015
+ cuda_version=$(command -v nvcc >/dev/null 2>&1 && nvcc --version | grep "release" | awk '{print $NF}' || true)
# Change cuda_version eg. V11.7.99 to 11.7
cuda_version=${cuda_version:1:4}
+ if [[ -z "$cuda_version" ]]; then
+ echo "Could not detect CUDA version. Please specify one manually by setting the 'cuda_version' env."
+ exit 1
+ fi
fi
# Check that CUDA version is supported
- if [[ "$cuda_version" != @(11.1|11.3|11.7|11.2|11.5|11.6|11.8) ]]; then
- echo "cuda_version is not supported, please choose among {11.1|11.2|11.3|11.5|11.6|11.7|11.8}"
+ if [[ "$cuda_version" != @(11.1|11.2|11.3|11.4|11.5|11.6|11.7|11.8|12.0|12.1|12.2) ]]; then
+ echo "cuda_version is not supported, please choose among {11.1|11.2|11.3|11.4|11.5|11.6|11.7|11.8|12.0|12.1|12.2}"
exit 1
fi
+ # Use CUDA 12.0 for all versions greater or equal to 12.0 for now
+ if [[ "$cuda_version" == @(12.1|12.2|12.3|12.4|12.5|12.6|12.7|12.8|12.9) ]]; then
+ cuda_version=12.0
+ fi
# Set cuda version suffix to docker image name
echo "Downloading $image docker image with CUDA $cuda_version"
- cuda_version="-${cuda_version}"
-else
- # Empty cuda version suffix for non-CUDA images
- cuda_version=""
+ gpu_backend_version="-${cuda_version}"
+fi
+
+if [[ "${FF_GPU_BACKEND}" == "hip_rocm" || "${FF_GPU_BACKEND}" == "hip_cuda" ]]; then
+ # Autodetect HIP version if not specified
+ if [[ $hip_version == "empty" ]]; then
+ # shellcheck disable=SC2015
+ hip_version=$(command -v hipcc >/dev/null 2>&1 && hipcc --version | grep "HIP version:" | awk '{print $NF}' || true)
+ # Change hip_version eg. 5.6.31061-8c743ae5d to 5.6
+ hip_version=${hip_version:0:3}
+ if [[ -z "$hip_version" ]]; then
+ echo "Could not detect HIP version. Please specify one manually by setting the 'hip_version' env."
+ exit 1
+ fi
+ fi
+ # Check that HIP version is supported
+ if [[ "$hip_version" != @(5.3|5.4|5.5|5.6) ]]; then
+ echo "hip_version is not supported, please choose among {5.3, 5.4, 5.5, 5.6}"
+ exit 1
+ fi
+ echo "Downloading $image docker image with HIP $hip_version"
+ if [[ "${FF_GPU_BACKEND}" == "hip_rocm" ]]; then
+ gpu_backend_version="-${hip_version}"
+ fi
fi
# Download image
-docker pull ghcr.io/flexflow/"$image-${FF_GPU_BACKEND}${cuda_version}"
+docker pull ghcr.io/flexflow/"$image-${FF_GPU_BACKEND}${gpu_backend_version}"
# Tag downloaded image
-docker tag ghcr.io/flexflow/"$image-${FF_GPU_BACKEND}${cuda_version}":latest "$image-${FF_GPU_BACKEND}${cuda_version}":latest
+docker tag ghcr.io/flexflow/"$image-${FF_GPU_BACKEND}${gpu_backend_version}":latest "$image-${FF_GPU_BACKEND}${gpu_backend_version}":latest
# Check that image exists
-docker image inspect "${image}-${FF_GPU_BACKEND}${cuda_version}":latest > /dev/null
+docker image inspect "${image}-${FF_GPU_BACKEND}${gpu_backend_version}":latest > /dev/null
diff --git a/docker/run.sh b/docker/run.sh
index 43571a252b..76ec1e1ceb 100755
--- a/docker/run.sh
+++ b/docker/run.sh
@@ -2,7 +2,7 @@
set -euo pipefail
# Usage: ./run.sh
-# Optional environment variables: FF_GPU_BACKEND, cuda_version, ATTACH_GPUS, SHM_SIZE
+# Optional environment variables: FF_GPU_BACKEND, cuda_version, hip_version, ATTACH_GPUS, SHM_SIZE
# Cd into directory holding this script
cd "${BASH_SOURCE[0]%/*}"
@@ -11,13 +11,16 @@ cd "${BASH_SOURCE[0]%/*}"
image=${1:-flexflow}
FF_GPU_BACKEND=${FF_GPU_BACKEND:-cuda}
cuda_version=${cuda_version:-"empty"}
-detached=${detached:-"OFF"}
+hip_version=${hip_version:-"empty"}
# Parameter controlling whether to attach GPUs to the Docker container
ATTACH_GPUS=${ATTACH_GPUS:-true}
gpu_arg=""
if $ATTACH_GPUS ; then gpu_arg="--gpus all" ; fi
+# Whether to attach inference weights / files (make sure to download the weights first)
+ATTACH_INFERENCE_FILES=${ATTACH_INFERENCE_FILES:-false}
+
# Amount of shared memory to give the Docker container access to
# If you get a Bus Error, increase this value. If you don't have enough memory
# on your machine, decrease this value.
@@ -39,36 +42,82 @@ else
echo "Running $image docker image with default GPU backend: cuda"
fi
+# gpu backend version suffix for the docker image.
+gpu_backend_version=""
+
if [[ "${FF_GPU_BACKEND}" == "cuda" || "${FF_GPU_BACKEND}" == "hip_cuda" ]]; then
# Autodetect cuda version if not specified
if [[ $cuda_version == "empty" ]]; then
- cuda_version=$(command -v nvcc >/dev/null 2>&1 && nvcc --version | grep "release" | awk '{print $NF}')
+ # shellcheck disable=SC2015
+ cuda_version=$(command -v nvcc >/dev/null 2>&1 && nvcc --version | grep "release" | awk '{print $NF}' || true)
# Change cuda_version eg. V11.7.99 to 11.7
cuda_version=${cuda_version:1:4}
+ if [[ -z "$cuda_version" ]]; then
+ echo "Could not detect CUDA version. Please specify one manually by setting the 'cuda_version' env."
+ exit 1
+ fi
fi
# Check that CUDA version is supported
- if [[ "$cuda_version" != @(11.1|11.3|11.7|11.2|11.5|11.6|11.8) ]]; then
- echo "cuda_version is not supported, please choose among {11.1|11.2|11.3|11.5|11.6|11.7|11.8}"
+ if [[ "$cuda_version" != @(11.1|11.2|11.3|11.4|11.5|11.6|11.7|11.8|12.0|12.1|12.2) ]]; then
+ echo "cuda_version is not supported, please choose among {11.1|11.2|11.3|11.4|11.5|11.6|11.7|11.8|12.0|12.1|12.2}"
exit 1
fi
+ # Use CUDA 12.0 for all versions greater or equal to 12.0 for now
+ if [[ "$cuda_version" == @(12.1|12.2|12.3|12.4|12.5|12.6|12.7|12.8|12.9) ]]; then
+ cuda_version=12.0
+ fi
# Set cuda version suffix to docker image name
echo "Running $image docker image with CUDA $cuda_version"
- cuda_version_hyphen="-${cuda_version}"
-else
- # Empty cuda version suffix for non-CUDA images
- cuda_version_hyphen=""
+ gpu_backend_version="-${cuda_version}"
+fi
+
+if [[ "${FF_GPU_BACKEND}" == "hip_rocm" || "${FF_GPU_BACKEND}" == "hip_cuda" ]]; then
+ # Autodetect HIP version if not specified
+ if [[ $hip_version == "empty" ]]; then
+ # shellcheck disable=SC2015
+ hip_version=$(command -v hipcc >/dev/null 2>&1 && hipcc --version | grep "HIP version:" | awk '{print $NF}' || true)
+ # Change hip_version eg. 5.6.31061-8c743ae5d to 5.6
+ hip_version=${hip_version:0:3}
+ if [[ -z "$hip_version" ]]; then
+ echo "Could not detect HIP version. Please specify one manually by setting the 'hip_version' env."
+ exit 1
+ fi
+ fi
+ # Check that HIP version is supported
+ if [[ "$hip_version" != @(5.3|5.4|5.5|5.6) ]]; then
+ echo "hip_version is not supported, please choose among {5.3, 5.4, 5.5, 5.6}"
+ exit 1
+ fi
+ echo "Running $image docker image with HIP $hip_version"
+ if [[ "${FF_GPU_BACKEND}" == "hip_rocm" ]]; then
+ gpu_backend_version="-${hip_version}"
+ fi
fi
# Check that image exists, if fails, print the default error message.
-if [[ "$(docker images -q "$image"-"$FF_GPU_BACKEND""$cuda_version_hyphen":latest 2> /dev/null)" == "" ]]; then
- echo ""
- echo "To download the docker image, run:"
- echo " FF_GPU_BACKEND=${FF_GPU_BACKEND} cuda_version=${cuda_version} $(pwd)/pull.sh $image"
- echo "To build the docker image from source, run:"
- echo " FF_GPU_BACKEND=${FF_GPU_BACKEND} cuda_version=${cuda_version} $(pwd)/build.sh $image"
- echo ""
+if [[ "$(docker images -q "${image}-${FF_GPU_BACKEND}${gpu_backend_version}":latest 2> /dev/null)" == "" ]]; then
+ echo "Error, ${image}-${FF_GPU_BACKEND}${gpu_backend_version}:latest does not exist!"
+ if [[ "${FF_GPU_BACKEND}" == "cuda" ]]; then
+ echo ""
+ echo "To download the docker image, run:"
+ echo " FF_GPU_BACKEND=${FF_GPU_BACKEND} cuda_version=${cuda_version} $(pwd)/pull.sh $image"
+ echo "To build the docker image from source, run:"
+ echo " FF_GPU_BACKEND=${FF_GPU_BACKEND} cuda_version=${cuda_version} $(pwd)/build.sh $image"
+ echo ""
+ elif [[ "${FF_GPU_BACKEND}" == "hip_rocm" ]]; then
+ echo ""
+ echo "To download the docker image, run:"
+ echo " FF_GPU_BACKEND=${FF_GPU_BACKEND} hip_version=${hip_version} $(pwd)/pull.sh $image"
+ echo "To build the docker image from source, run:"
+ echo " FF_GPU_BACKEND=${FF_GPU_BACKEND} hip_version=${hip_version} $(pwd)/build.sh $image"
+ echo ""
+ fi
exit 1
fi
+inference_volumes=""
+if $ATTACH_INFERENCE_FILES ; then
+ inference_volumes="-v ~/.cache/flexflow:/usr/FlexFlow/inference";
+fi
-eval docker run -it "$gpu_arg" "--shm-size=${SHM_SIZE}" "${image}-${FF_GPU_BACKEND}${cuda_version_hyphen}:latest"
+eval docker run -it "$gpu_arg" "--shm-size=${SHM_SIZE}" "${inference_volumes}" "${image}-${FF_GPU_BACKEND}${gpu_backend_version}:latest"
diff --git a/docs/Makefile b/docs/Makefile
index 5424c5bc9f..d14c2ef91f 100644
--- a/docs/Makefile
+++ b/docs/Makefile
@@ -15,7 +15,7 @@ help:
.PHONY: help Makefile clean
clean:
- rm -rf build source/_doxygen/ source/c++_api/ doxygen/output
+ rm -rf build doxygen/output doxygen/cpp_api
@$(SPHINXBUILD) -M clean "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
# Catch-all target: route all unknown targets to Sphinx using the new
diff --git a/docs/doxygen/Doxyfile b/docs/doxygen/Doxyfile
index b38bfc12b5..aafa65d79b 100644
--- a/docs/doxygen/Doxyfile
+++ b/docs/doxygen/Doxyfile
@@ -44,7 +44,7 @@ PROJECT_NUMBER =
# for a project that appears at the top of each page and should give viewer a
# quick idea about the purpose of the project. Keep the description short.
-PROJECT_BRIEF = A distributed deep learning framework that supports flexible parallelization strategies.
+PROJECT_BRIEF = "A distributed deep learning framework that supports flexible parallelization strategies."
# With the PROJECT_LOGO tag one can specify a logo or an icon that is included
# in the documentation. The maximum height of the logo should not exceed 55
@@ -150,7 +150,7 @@ INLINE_INHERITED_MEMB = NO
# shortest path that makes the file name unique will be used
# The default value is: YES.
-FULL_PATH_NAMES = YES
+FULL_PATH_NAMES = NO
# The STRIP_FROM_PATH tag can be used to strip a user-defined part of the path.
# Stripping is only done if one of the specified strings matches the left-hand
@@ -874,12 +874,7 @@ WARN_LOGFILE =
# spaces. See also FILE_PATTERNS and EXTENSION_MAPPING
# Note: If this tag is empty the current directory is searched.
-INPUT = $(FF_HOME)/align
-INPUT += $(FF_HOME)/bootcamp_demo
-INPUT += $(FF_HOME)/examples
INPUT += $(FF_HOME)/include
-INPUT += $(FF_HOME)/nmt
-INPUT += $(FF_HOME)/python
INPUT += $(FF_HOME)/src
# This tag can be used to specify the character encoding of the source files
@@ -911,12 +906,10 @@ INPUT_ENCODING = UTF-8
FILE_PATTERNS = *.c \
*.cc \
- *.cpp \
*.cu \
+ *.cpp \
*.h \
- *.hpp \
- *.md \
- *.py
+ *.hpp
# The RECURSIVE tag can be used to specify whether or not subdirectories should
# be searched for input files as well.
@@ -2110,7 +2103,7 @@ MAN_LINKS = NO
# captures the structure of the code including all documentation.
# The default value is: NO.
-GENERATE_XML = YES
+GENERATE_XML = NO
# The XML_OUTPUT tag is used to specify where the XML pages will be put. If a
# relative path is entered the value of OUTPUT_DIRECTORY will be put in front of
diff --git a/docs/source/conf.py b/docs/source/conf.py
index 0e614f37c2..f67c0dae01 100644
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -13,28 +13,42 @@
import os
import sys
import subprocess
+import shutil
+import sphinx # only needed for the manual post processing
+from pathlib import Path
+from m2r2 import convert
+from docutils.core import publish_string
+import re
def get_parent_dir_path(path):
return os.path.abspath(os.path.join(path, ".."))
docs_path = get_parent_dir_path(os.path.dirname(os.path.abspath(__file__)))
doxygen_path = os.path.join(docs_path, "doxygen")
+doxygen_output = os.path.join(doxygen_path, "output")
+doxygen_cpp_api_out = os.path.join(doxygen_path, "cpp_api")
FF_HOME = get_parent_dir_path(docs_path)
python_package_path = os.path.join(FF_HOME, "python")
sys.path.insert(0, os.path.abspath(python_package_path))
# Build the Doxygen docs
-#subprocess.call(f'cd {doxygen_path}; FF_HOME={FF_HOME} doxygen', shell=True)
+shutil.rmtree(doxygen_cpp_api_out, ignore_errors=True)
+for gpu_backend in ("cuda", "hip"):
+ doxygen_dest = os.path.join(doxygen_cpp_api_out, f"{gpu_backend}_api")
+ os.makedirs(doxygen_dest, exist_ok=True)
+ exclude_extension = ".cu" if gpu_backend == "hip" else ".cpp"
+ doxygen_cmd = f'export FF_HOME={FF_HOME}; ( cat Doxyfile ; echo "EXCLUDE_PATTERNS+=*{exclude_extension}" ) | doxygen -'
+ subprocess.check_call(doxygen_cmd, cwd=doxygen_path, shell=True)
+ subprocess.check_call(f'mv {os.path.join(doxygen_output, "html")}/* {doxygen_dest}/', shell=True)
import sphinx_rtd_theme
# -- Project information -----------------------------------------------------
project = 'FlexFlow'
-copyright = '2020, Stanford, LANL, CMU, Facebook'
-author = 'Stanford, LANL, CMU, Facebook'
-
+copyright = '2023 CMU, Facebook, LANL, MIT, NVIDIA, and Stanford (alphabetical)'
+author = 'CMU, Facebook, LANL, MIT, NVIDIA, and Stanford (alphabetical)'
# -- General configuration ---------------------------------------------------
@@ -45,8 +59,6 @@ def get_parent_dir_path(path):
'sphinx_rtd_theme',
'sphinx.ext.autodoc',
'm2r2',
- 'breathe',
- 'exhale',
]
# Theme options are theme-specific and customize the look and feel of a theme
@@ -55,6 +67,7 @@ def get_parent_dir_path(path):
html_theme_options = {
"collapse_navigation" : False
}
+html_extra_path = [doxygen_cpp_api_out]
# Add any paths that contain templates here, relative to this directory.
# templates_path = ['_templates']
@@ -86,27 +99,50 @@ def get_parent_dir_path(path):
# so a file named "default.css" will overwrite the builtin "default.css".
# html_static_path = ['_static']
-# Breathe + Exhale configuration
-# Setup the breathe extension
-breathe_projects = {
- "FlexFlow": "./_doxygen/xml"
-}
-breathe_default_project = "FlexFlow"
-
-c_plus_plus_src_dirs = " ".join([f"\"{os.path.join(FF_HOME, 'src', dirname)}\"" for dirname in ("loss_functions", "mapper", "metrics_functions", "ops", "parallel_ops", "recompile", "runtime", "utils")])
-# Setup the exhale extension
-exhale_args = {
- # These arguments are required
- "containmentFolder": "./c++_api",
- "rootFileName": "c++_api_root.rst",
- "doxygenStripFromPath": "..",
- # Heavily encouraged optional argument (see docs)
- #"rootFileTitle": "Library API",
- # Suggested optional arguments
- "createTreeView": True,
- # TIP: if using the sphinx-bootstrap-theme, you need
- # "treeViewIsBootstrap": True,
- "exhaleExecutesDoxygen": True,
- "exhaleDoxygenStdin": f'INPUT = {c_plus_plus_src_dirs}'
-}
+def manual_post_processing(app, exception):
+ if exception is None and app.builder.name == 'html': # build succeeded
+ print(f'Post-processing HTML docs at path {app.outdir}')
+ build_dir = Path(app.outdir)
+
+ # List of subfolders to search
+ folder_paths = [build_dir, build_dir / 'developers_guide']
+
+ for folder_path in folder_paths:
+
+ # Only get HTML files in build dir, not subfolders
+ html_files = folder_path.glob('*.html')
+
+ for html_file in html_files:
+ content = html_file.read_text()
+
+ # Find dropdown menus, and manually convert their contents
+ pattern = r'\nExpand here
\n
(.*?) '
+ blocks = re.findall(pattern, content, re.DOTALL)
+
+ for block in blocks:
+ # Convert Markdown to HTML
+ rst = convert(block, github_markdown=True)
+ html = publish_string(rst, writer_name='html')
+ html_str = html.decode('utf-8')
+
+ # Replace block with converted HTML
+ content = content.replace(block, html_str)
+
+ # Add space after dropdown menu block
+ content = content.replace('',
+ '\n')
+
+ # Replace incorrect links
+ content = content.replace('href="../docker/README.md"', 'href="docker.html"')
+ content = content.replace('href="./TRAIN.md"', 'href="train_overview.html"')
+ content = content.replace('href="./SERVE.md"', 'href="serve_overview.html"')
+ content = content.replace('href="./docs/source/keras.rst"', 'href="keras.html"')
+ content = content.replace('href="./docs/source/onnx.rst"', 'href="onnx.html"')
+
+
+ html_file.write_text(content)
+
+
+def setup(app):
+ app.connect('build-finished', manual_post_processing)
diff --git a/docs/source/cpp_api.rst b/docs/source/cpp_api.rst
new file mode 100644
index 0000000000..b5d39be62e
--- /dev/null
+++ b/docs/source/cpp_api.rst
@@ -0,0 +1,10 @@
+*************
+C++ API
+*************
+
+The FlexFlow backend is at the core of FlexFlow Train and FlexFlow Serve. It is written entirely in C/C++ and CUDA/HIP. This section documents the API, which is generated by Doxygen and it is available at the following links:
+
+* `CUDA version <./cuda_api/index.html>`_ (default version)
+* `HIP version <./hip_api/index.html>`_
+
+The two versions only differ when it comes to the GPU kernels, so the great majority of the entries are identical. If you are unsure which version to use, take a look at the CUDA version.
diff --git a/docs/source/developers_guide.rst b/docs/source/developers_guide/developers_guide.rst
similarity index 64%
rename from docs/source/developers_guide.rst
rename to docs/source/developers_guide/developers_guide.rst
index 107135fae4..a125e60460 100644
--- a/docs/source/developers_guide.rst
+++ b/docs/source/developers_guide/developers_guide.rst
@@ -2,5 +2,5 @@
Developers Guide
******************
-.. mdinclude:: ../../CONTRIBUTING.md
+.. mdinclude:: ../../../CONTRIBUTING.md
:start-line: 2
diff --git a/docs/source/developers_guide/ff_internals.rst b/docs/source/developers_guide/ff_internals.rst
new file mode 100644
index 0000000000..15c0804255
--- /dev/null
+++ b/docs/source/developers_guide/ff_internals.rst
@@ -0,0 +1,6 @@
+*******************
+FlexFlow Internals
+*******************
+
+.. mdinclude:: internals.md
+ :start-line: 2
diff --git a/docs/source/developers_guide/internals.md b/docs/source/developers_guide/internals.md
new file mode 100644
index 0000000000..243b14a174
--- /dev/null
+++ b/docs/source/developers_guide/internals.md
@@ -0,0 +1,15 @@
+# FlexFlow Internals
+
+## The Parallel Computation Graph (PCG)
+
+FlexFlow uses a _Parallel Computation Graph (PCG)_ to simultaneously represent tensor operations, as well as parallelism choices and data movement across nodes.
+
+### Tensor representations
+
+There are two types of tensor representations in FlexFlow: a [Tensor](./cuda_api/de/da9/structFlexFlow_1_1TensorBase.html) and a [ParallelTensor](./cuda_api/d3/dfc/structFlexFlow_1_1ParallelTensorBase.html). The first variant is used when writing a FlexFlow DNN program, whereas the second is used by the runtime to run all the computations in a distributed fashion. `Tensor` and `ParallelTensor` are implemented as typedef-ed pointers to, respectively, the `TensorBase` (defined in `include/flexflow/tensor.h`) and `ParallelTensorBase` (defined in `include/flexflow/parallel_tensor.h`) structs.
+
+The `ParallelTensor` struct contains all the information that a `Tensor` also stores, but in addition, it also codifies how the tensor should be parallelized. For instance, a ParallelTensor records how each dimension is *partitioned*, how many *replicas* of the tensors have been created, and the *mapping* between the partitions of the tensors and the physical machines that will store them.
+
+## Transformation generation
+
+## Joint optimization
diff --git a/docs/source/docker.rst b/docs/source/docker.rst
index 4a457a8dcc..63f84e460c 100644
--- a/docs/source/docker.rst
+++ b/docs/source/docker.rst
@@ -1,3 +1,4 @@
+:tocdepth: 1
*************
Docker
*************
diff --git a/docs/source/index.rst b/docs/source/index.rst
index 7af62e417e..a7ea2ff3ac 100644
--- a/docs/source/index.rst
+++ b/docs/source/index.rst
@@ -7,47 +7,38 @@ Welcome to FlexFlow's documentation!
====================================
.. toctree::
- :maxdepth: 2
:caption: Getting Started
welcome
installation
docker
- jupyter
+ multinode
.. toctree::
- :maxdepth: 2
- :caption: Interoperability
+ :caption: FlexFlow Serve
- keras
- pytorch
- onnx
+ serve_overview
.. toctree::
- :maxdepth: 2
- :caption: Examples
-
- mt5
+ :caption: FlexFlow Train
-.. toctree::
- :maxdepth: 3
- :caption: Python API
+ train_overview
+ train_interface
+ train_examples
- python/models
- python/layers
- python/dataloader
+ train_python_api
.. toctree::
- :maxdepth: 2
- :caption: C++ API
+ :caption: FlexFlow Backend
- c++_api/c++_api_root
+ cpp_api
.. toctree::
- :maxdepth: 2
+ :maxdepth: 3
:caption: Developers Guide
- developers_guide
+ developers_guide/developers_guide.rst
+.. developers_guide/ff_internals.rst
.. Indices and tables
diff --git a/docs/source/installation.rst b/docs/source/installation.rst
index 109b546834..95ec8596e6 100644
--- a/docs/source/installation.rst
+++ b/docs/source/installation.rst
@@ -1,5 +1,6 @@
+:tocdepth: 1
*************
-Installing FlexFlow
+Building from source
*************
.. mdinclude:: ../../INSTALL.md
diff --git a/docs/source/keras.rst b/docs/source/keras.rst
index eb4f2d7fa7..f1c0743c70 100644
--- a/docs/source/keras.rst
+++ b/docs/source/keras.rst
@@ -1,6 +1,7 @@
-*************
-Keras Support
-*************
+:tocdepth: 1
+****************
+Keras Interface
+****************
FlexFlow provides a drop-in replacement for TensorFlow Keras. Running an existing Keras program on the FlexFlow backend only requires a few lines of changes to the program. The detailed instructions are as follows:
diff --git a/docs/source/mt5.rst b/docs/source/mt5.rst
index c9c3af080a..8a632b90d6 100644
--- a/docs/source/mt5.rst
+++ b/docs/source/mt5.rst
@@ -1,6 +1,6 @@
-****************
-HuggingFace mT5
-****************
+************************
+mT5 Model
+************************
.. mdinclude:: ../../examples/python/pytorch/mt5/README.md
:start-line: 2
diff --git a/docs/source/multinode.rst b/docs/source/multinode.rst
new file mode 100644
index 0000000000..8827200582
--- /dev/null
+++ b/docs/source/multinode.rst
@@ -0,0 +1,8 @@
+:tocdepth: 1
+******************
+Multinode tutorial
+******************
+
+
+.. mdinclude:: ../../MULTI-NODE.md
+ :start-line: 3
diff --git a/docs/source/onnx.rst b/docs/source/onnx.rst
index 91b314ac96..b6bc49b146 100644
--- a/docs/source/onnx.rst
+++ b/docs/source/onnx.rst
@@ -1,3 +1,4 @@
+:tocdepth: 1
*************
ONNX Support
*************
diff --git a/docs/source/pytorch.rst b/docs/source/pytorch.rst
index a6d4e23311..3dbe337d55 100644
--- a/docs/source/pytorch.rst
+++ b/docs/source/pytorch.rst
@@ -1,6 +1,7 @@
-***************
-PyTorch Support
-***************
+:tocdepth: 1
+******************
+PyTorch Interface
+******************
Users can use FlexFlow to optimize the parallelization performance of existing PyTorch models in two steps.
The PyTorch support requires the `PyTorch FX module `_, so make sure your PyTorch is up to date.
diff --git a/docs/source/serve_overview.rst b/docs/source/serve_overview.rst
new file mode 100644
index 0000000000..35c992a853
--- /dev/null
+++ b/docs/source/serve_overview.rst
@@ -0,0 +1,7 @@
+:tocdepth: 1
+*************
+Serving Overview
+*************
+
+.. mdinclude:: ../../SERVE.md
+ :start-line: 3
diff --git a/docs/source/train_examples.rst b/docs/source/train_examples.rst
new file mode 100644
index 0000000000..84d58c3465
--- /dev/null
+++ b/docs/source/train_examples.rst
@@ -0,0 +1,6 @@
+*************
+Training Examples
+*************
+
+.. toctree::
+ mt5
\ No newline at end of file
diff --git a/docs/source/train_interface.rst b/docs/source/train_interface.rst
new file mode 100644
index 0000000000..ce81fc1f3c
--- /dev/null
+++ b/docs/source/train_interface.rst
@@ -0,0 +1,8 @@
+*******************
+Training Interface
+*******************
+
+.. toctree::
+ keras
+ pytorch
+ onnx
\ No newline at end of file
diff --git a/docs/source/train_overview.rst b/docs/source/train_overview.rst
new file mode 100644
index 0000000000..58898ad35c
--- /dev/null
+++ b/docs/source/train_overview.rst
@@ -0,0 +1,7 @@
+:tocdepth: 1
+*************
+Training Overview
+*************
+
+.. mdinclude:: ../../TRAIN.md
+ :start-line: 3
diff --git a/docs/source/train_python_api.rst b/docs/source/train_python_api.rst
new file mode 100644
index 0000000000..40451dedf9
--- /dev/null
+++ b/docs/source/train_python_api.rst
@@ -0,0 +1,11 @@
+*******************
+Python API
+*******************
+This section documents the Python API for FlexFlow Train.
+
+.. toctree::
+ :maxdepth: 3
+
+ python/models
+ python/layers
+ python/dataloader
\ No newline at end of file
diff --git a/docs/source/welcome.rst b/docs/source/welcome.rst
index 8108b1dd67..7f73f15563 100644
--- a/docs/source/welcome.rst
+++ b/docs/source/welcome.rst
@@ -1,3 +1,4 @@
+:tocdepth: 1
*************
Overview
*************
diff --git a/img/overview.png b/img/overview.png
new file mode 100644
index 0000000000..5264e2d41a
Binary files /dev/null and b/img/overview.png differ
diff --git a/img/performance.png b/img/performance.png
new file mode 100644
index 0000000000..668e579197
Binary files /dev/null and b/img/performance.png differ
diff --git a/img/spec_infer_demo.gif b/img/spec_infer_demo.gif
new file mode 100644
index 0000000000..c0fda87b71
Binary files /dev/null and b/img/spec_infer_demo.gif differ
diff --git a/include/flexflow/accessor.h b/include/flexflow/accessor.h
index 6f95354823..65ab33b513 100644
--- a/include/flexflow/accessor.h
+++ b/include/flexflow/accessor.h
@@ -61,6 +61,7 @@ class GenericTensorAccessorW {
float *get_float_ptr() const;
double *get_double_ptr() const;
half *get_half_ptr() const;
+ char *get_byte_ptr() const;
DataType data_type;
Legion::Domain domain;
void *ptr;
@@ -79,6 +80,7 @@ class GenericTensorAccessorR {
float const *get_float_ptr() const;
double const *get_double_ptr() const;
half const *get_half_ptr() const;
+ char const *get_byte_ptr() const;
DataType data_type;
Legion::Domain domain;
void const *ptr;
diff --git a/include/flexflow/batch_config.h b/include/flexflow/batch_config.h
new file mode 100644
index 0000000000..ce331d3e41
--- /dev/null
+++ b/include/flexflow/batch_config.h
@@ -0,0 +1,149 @@
+/* Copyright 2023 CMU, Stanford, Facebook, LANL
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License");
+ * you may not use this file except in compliance with the License.
+ * You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+#pragma once
+
+#include "flexflow/ffconst.h"
+#include "legion.h"
+#include
+#include
+
+// #define MAX_SEQ_LEN 1024
+// #define BATCH_SIZE 2
+// #define BATCH_SIZE 16
+// #define MAX_REQUESTS 256
+
+namespace FlexFlow {
+
+class InferenceResult;
+class BeamInferenceResult;
+
+using BatchConfigFuture = Legion::Future;
+using InferenceResultFuture = Legion::Future;
+using BeamSearchBatchConfigFuture = Legion::Future;
+using TreeVerifyBatchConfigFuture = Legion::Future;
+using BeamInferenceResultFuture = Legion::Future;
+
+class BatchConfig {
+public:
+ using RequestGuid = size_t;
+ using TokenId = int;
+ BatchConfig();
+ int num_active_requests() const;
+ int num_active_tokens() const;
+ void print() const;
+ virtual InferenceMode get_mode() const;
+ static BatchConfig const *from_future(BatchConfigFuture const &future);
+ static int const MAX_NUM_REQUESTS = 1;
+ static int const MAX_NUM_TOKENS = 64;
+ static int const MAX_PROMPT_LENGTH = 62;
+ static int const MAX_SEQ_LENGTH = 256;
+
+ // These are set by update
+ int num_tokens;
+
+ struct PerRequestInfo {
+ int token_start_offset;
+ int num_tokens_in_batch;
+ int max_sequence_length;
+ RequestGuid request_guid;
+ };
+ struct PerTokenInfo {
+ int abs_depth_in_request;
+ int request_index;
+ TokenId token_id;
+ };
+ PerRequestInfo requestsInfo[MAX_NUM_REQUESTS];
+ PerTokenInfo tokensInfo[MAX_NUM_TOKENS];
+
+ bool request_completed[MAX_NUM_REQUESTS];
+};
+
+class TreeVerifyBatchConfig : public BatchConfig {
+public:
+ TreeVerifyBatchConfig();
+ ~TreeVerifyBatchConfig();
+ InferenceMode get_mode() const;
+ void print() const;
+ struct CommittedTokensInfo {
+ int token_index; // the index of the token in the previous batch
+ int request_index; // request index in the batch
+ int token_depth; // position of the token in the request's sequence
+ };
+
+ int num_tokens_to_commit;
+ CommittedTokensInfo committed_tokens[MAX_NUM_TOKENS];
+};
+
+struct InferenceResult {
+ static int const MAX_NUM_TOKENS = BatchConfig::MAX_NUM_TOKENS;
+ BatchConfig::TokenId token_ids[MAX_NUM_TOKENS];
+};
+
+class BeamSearchBatchConfig : public BatchConfig {
+public:
+ BeamSearchBatchConfig();
+ BeamSearchBatchConfig(int model_id);
+ BeamSearchBatchConfig(size_t beam_width, size_t target_iterations);
+ BeamSearchBatchConfig(BeamSearchBatchConfig const &other, int model_id);
+ InferenceMode get_mode() const;
+
+ ~BeamSearchBatchConfig();
+
+ void print() const;
+ bool done() const;
+ int max_beam_depth_all_requests() const;
+ int current_depth_all_requests() const;
+
+ size_t beam_width;
+ size_t target_iterations;
+ inline static int const MAX_BEAM_WIDTH = 1;
+ inline static int const MAX_BEAM_DEPTH = 8;
+
+ int model_id;
+ int max_init_length = 0;
+
+ struct BeamSearchPerRequestInfo {
+ int beam_size;
+ int current_depth = -1;
+ int max_depth = MAX_BEAM_DEPTH;
+
+ BatchConfig::TokenId tokens[BeamSearchBatchConfig::MAX_BEAM_WIDTH];
+ float probs[BeamSearchBatchConfig::MAX_BEAM_WIDTH];
+ int parent_id[BeamSearchBatchConfig::MAX_BEAM_WIDTH];
+ };
+
+ struct BeamSearchPerTokenInfo {
+ int sub_request_index;
+ };
+
+ BeamSearchPerRequestInfo beamRequestsInfo[MAX_NUM_REQUESTS];
+ BeamSearchPerTokenInfo beamTokenInfo[MAX_NUM_TOKENS * MAX_BEAM_WIDTH];
+ // why is this == MAX_NUM_REQUESTS * MAX_BEAM_WIDTH?
+ int sub_requests[MAX_NUM_REQUESTS * MAX_BEAM_WIDTH];
+
+private:
+ size_t current_iteration;
+};
+
+struct BeamInferenceResult {
+ static int const MAX_NUM_TOKENS = BatchConfig::MAX_NUM_TOKENS;
+ BatchConfig::TokenId
+ token_ids[MAX_NUM_TOKENS * BeamSearchBatchConfig::MAX_BEAM_WIDTH];
+ float probs[MAX_NUM_TOKENS * BeamSearchBatchConfig::MAX_BEAM_WIDTH];
+ int parent_id[MAX_NUM_TOKENS * BeamSearchBatchConfig::MAX_BEAM_WIDTH];
+};
+
+}; // namespace FlexFlow
diff --git a/include/flexflow/config.h b/include/flexflow/config.h
index d82b1377c7..be6c0d21da 100644
--- a/include/flexflow/config.h
+++ b/include/flexflow/config.h
@@ -37,14 +37,15 @@ namespace FlexFlow {
// ========================================================
// Define Runtime Constants
// ========================================================
-#define MAX_NUM_INPUTS 256
-#define MAX_NUM_WEIGHTS 64
-#define MAX_NUM_OUTPUTS 256
-#define MAX_NUM_FUSED_OPERATORS 64
-#define MAX_NUM_FUSED_TENSORS 64
+#define MAX_NUM_INPUTS 2048
+#define MAX_NUM_WEIGHTS 2048
+#define MAX_NUM_OUTPUTS 2048
+#define MAX_NUM_FUSED_OPERATORS 2048
+#define MAX_NUM_FUSED_TENSORS 2048
#define MAX_NUM_WORKERS 1024
#define MAX_FILENAME 200
#define MAX_OPNAME 128
+#define MAX_NUM_TRANSFORMER_LAYERS 100
// DataLoader
#define MAX_SAMPLES_PER_LOAD 64
#define MAX_FILE_LENGTH 128
@@ -70,6 +71,9 @@ struct FFHandler {
#endif
void *workSpace;
size_t workSpaceSize;
+ void *offload_reserve_space;
+ size_t offload_reserve_space_size;
+ DataType quantization_type;
bool allowTensorOpMathConversion;
#ifdef FF_USE_NCCL
ncclComm_t ncclComm;
@@ -78,6 +82,8 @@ struct FFHandler {
struct FFInitInfo {
size_t workSpaceSize;
+ size_t offload_reserve_space_size;
+ DataType quantization_type;
bool allowTensorOpMathConversion;
// int myRank, allRanks;
};
@@ -122,19 +128,26 @@ class FFConfig {
size_t workSpaceSize;
Legion::Context lg_ctx;
Legion::Runtime *lg_hlr;
- Legion::FieldSpace field_space;
+ // Legion::FieldSpace field_space;
bool syntheticInput, profiling, perform_fusion;
size_t simulator_work_space_size;
size_t search_budget;
float search_alpha;
bool search_overlap_backward_update;
CompMode computationMode;
+ bool cpu_offload;
+ size_t offload_reserve_space_size;
+ DataType quantization_type;
// Control parallelizable dimensions
bool only_data_parallel;
bool enable_sample_parallel;
bool enable_parameter_parallel;
bool enable_attribute_parallel;
bool enable_inplace_optimizations;
+ // Control parallelism degrees in inference
+ int data_parallelism_degree;
+ int tensor_parallelism_degree;
+ int pipeline_parallelism_degree;
// Control Tensor Op Math Conversion
bool allow_tensor_op_math_conversion;
std::string dataset_path;
diff --git a/include/flexflow/ffconst.h b/include/flexflow/ffconst.h
index 5658e2923d..2f97d48997 100644
--- a/include/flexflow/ffconst.h
+++ b/include/flexflow/ffconst.h
@@ -33,6 +33,8 @@ enum DataType {
DT_HALF = 43,
DT_FLOAT = 44,
DT_DOUBLE = 45,
+ DT_INT4 = 46,
+ DT_INT8 = 47,
DT_NONE = 49,
};
@@ -64,6 +66,12 @@ enum MetricsType {
METRICS_MEAN_ABSOLUTE_ERROR = 1032,
};
+enum InferenceMode {
+ INC_DECODING_MODE = 2001,
+ BEAM_SEARCH_MODE = 2002,
+ TREE_VERIFY_MODE = 2003,
+};
+
// This is consistent with TASO's OpType
// https://github.com/jiazhihao/TASO/blob/master/include/taso/ops.h#L75-L138
enum OperatorType {
@@ -129,6 +137,7 @@ enum OperatorType {
OP_SHAPE, // https://github.com/onnx/onnx/blob/master/docs/Operators.md#Shape
OP_SIZE, // https://github.com/onnx/onnx/blob/master/docs/Operators.md#Size
OP_TOPK, // https://github.com/onnx/onnx/blob/master/docs/Operators.md#TopK
+ OP_ARG_TOPK,
OP_WHERE, // https://github.com/onnx/onnx/blob/master/docs/Operators.md#Where
OP_CEIL, // https://github.com/onnx/onnx/blob/master/docs/Operators.md#Ceil
OP_CAST, // https://github.com/onnx/onnx/blob/master/docs/Operators.md#Cast
@@ -150,17 +159,35 @@ enum OperatorType {
OP_POW, // https://pytorch.org/docs/stable/generated/torch.pow.html
OP_MEAN, // https://pytorch.org/docs/stable/generated/torch.mean.html
OP_LAYERNORM,
+ OP_EXPERTS,
OP_GATHER, // https://pytorch.org/docs/stable/generated/torch.gather.html
+ OP_RMS_NORM,
+ OP_BEAM_TOPK,
+ OP_ARGMAX,
+ OP_INC_MULTIHEAD_SELF_ATTENTION,
+ OP_SPEC_INC_MULTIHEAD_SELF_ATTENTION,
+ OP_TREE_INC_MULTIHEAD_SELF_ATTENTION,
+ OP_SAMPLING,
// Parallel Ops
OP_REPARTITION,
OP_COMBINE,
OP_REPLICATE,
OP_REDUCTION,
OP_PIPELINE,
+ OP_ALLREDUCE,
OP_FUSED_PARALLEL,
OP_INVALID,
};
+enum ModelType {
+ UNKNOWN = 3001,
+ LLAMA = 3002,
+ LLAMA2 = 3003,
+ OPT = 3004,
+ FALCON = 3005,
+ STARCODER = 3006
+};
+
enum PMParameter {
PM_OP_TYPE, // AnyOp
PM_NUM_INPUTS, // AnyOp
@@ -189,6 +216,7 @@ enum PMParameter {
PM_COMBINE_DEGREE, // Combine
PM_REDUCTION_DIM, // Reduction
PM_REDUCTION_DEGREE, // Reduction
+ PM_ALLREDUCE_DIM, // AllReduce
PM_SOFTMAX_DIM, // Softmax
PM_NUM_HEADS, // MultiHeadAttention
PM_INVALID,
diff --git a/include/flexflow/ffconst_utils.h b/include/flexflow/ffconst_utils.h
index fcd881e57e..421a139d57 100644
--- a/include/flexflow/ffconst_utils.h
+++ b/include/flexflow/ffconst_utils.h
@@ -8,8 +8,16 @@ namespace FlexFlow {
std::string get_operator_type_name(OperatorType type);
+size_t data_type_size(DataType type);
+
+#define INT4_NUM_OF_ELEMENTS_PER_GROUP 32
+
+size_t get_quantization_to_byte_size(DataType type,
+ DataType quantization_type,
+ size_t num_elements);
+
std::ostream &operator<<(std::ostream &, OperatorType);
}; // namespace FlexFlow
-#endif // _FLEXFLOW_FFCONST_UTILS_H
\ No newline at end of file
+#endif // _FLEXFLOW_FFCONST_UTILS_H
diff --git a/include/flexflow/fftype.h b/include/flexflow/fftype.h
index a71c85dbc8..18ed6b8100 100644
--- a/include/flexflow/fftype.h
+++ b/include/flexflow/fftype.h
@@ -8,15 +8,16 @@ namespace FlexFlow {
class LayerID {
public:
+ static const LayerID NO_ID;
LayerID();
- LayerID(size_t id);
+ LayerID(size_t id, size_t transformer_layer_id);
bool is_valid_id() const;
friend bool operator==(LayerID const &lhs, LayerID const &rhs);
public:
- size_t id;
+ size_t id, transformer_layer_id;
};
}; // namespace FlexFlow
-#endif // _FF_TYPE_H
\ No newline at end of file
+#endif // _FF_TYPE_H
diff --git a/include/flexflow/flexflow_c.h b/include/flexflow/flexflow_c.h
index 16ce3ac205..003533bb80 100644
--- a/include/flexflow/flexflow_c.h
+++ b/include/flexflow/flexflow_c.h
@@ -47,6 +47,14 @@ FF_NEW_OPAQUE_TYPE(flexflow_dlrm_config_t);
FF_NEW_OPAQUE_TYPE(flexflow_dataloader_4d_t);
FF_NEW_OPAQUE_TYPE(flexflow_dataloader_2d_t);
FF_NEW_OPAQUE_TYPE(flexflow_single_dataloader_t);
+// Inference
+FF_NEW_OPAQUE_TYPE(flexflow_batch_config_t);
+FF_NEW_OPAQUE_TYPE(flexflow_tree_verify_batch_config_t);
+FF_NEW_OPAQUE_TYPE(flexflow_beam_search_batch_config_t);
+FF_NEW_OPAQUE_TYPE(flexflow_inference_manager_t);
+FF_NEW_OPAQUE_TYPE(flexflow_request_manager_t);
+FF_NEW_OPAQUE_TYPE(flexflow_file_data_loader_t);
+FF_NEW_OPAQUE_TYPE(flexflow_generation_result_t);
// -----------------------------------------------------------------------
// FFConfig
@@ -72,12 +80,31 @@ int flexflow_config_get_epochs(flexflow_config_t handle);
bool flexflow_config_get_enable_control_replication(flexflow_config_t handle);
+int flexflow_config_get_data_parallelism_degree(flexflow_config_t handle_);
+
+int flexflow_config_get_tensor_parallelism_degree(flexflow_config_t handle_);
+
+int flexflow_config_get_pipeline_parallelism_degree(flexflow_config_t handle_);
+
+void flexflow_config_set_data_parallelism_degree(flexflow_config_t handle_,
+ int value);
+
+void flexflow_config_set_tensor_parallelism_degree(flexflow_config_t handle_,
+ int value);
+
+void flexflow_config_set_pipeline_parallelism_degree(flexflow_config_t handle_,
+ int value);
+
int flexflow_config_get_python_data_loader_type(flexflow_config_t handle);
+
+bool flexflow_config_get_offload(flexflow_config_t handle);
+
// -----------------------------------------------------------------------
// FFModel
// -----------------------------------------------------------------------
-flexflow_model_t flexflow_model_create(flexflow_config_t config);
+flexflow_model_t flexflow_model_create(flexflow_config_t config,
+ bool cpu_offload);
void flexflow_model_destroy(flexflow_model_t handle);
@@ -197,9 +224,10 @@ flexflow_tensor_t
flexflow_tensor_t
flexflow_model_add_embedding(flexflow_model_t handle,
const flexflow_tensor_t input,
- int num_entires,
+ int num_entries,
int out_dim,
enum AggrMode aggr,
+ enum DataType dtype,
flexflow_op_t shared_op,
flexflow_initializer_t kernel_initializer,
char const *name);
@@ -371,6 +399,151 @@ flexflow_tensor_t flexflow_model_add_multihead_attention(
flexflow_initializer_t kernel_initializer,
char const *name);
+flexflow_tensor_t flexflow_model_add_inc_multihead_self_attention(
+ flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ int embed_dim,
+ int num_heads,
+ int kdim,
+ int vdim,
+ float dropout,
+ bool bias,
+ bool add_bias_kv,
+ bool add_zero_attn,
+ enum DataType data_type,
+ flexflow_initializer_t kernel_initializer_,
+ bool apply_rotary_embedding,
+ bool scaling_query,
+ float scaling_factor,
+ bool qk_prod_scaling,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_spec_inc_multihead_self_attention(
+ flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ int embed_dim,
+ int num_heads,
+ int kdim,
+ int vdim,
+ float dropout,
+ bool bias,
+ bool add_bias_kv,
+ bool add_zero_attn,
+ enum DataType data_type,
+ flexflow_initializer_t kernel_initializer_,
+ bool apply_rotary_embedding,
+ bool scaling_query,
+ float scaling_factor,
+ bool qk_prod_scaling,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_inc_multihead_self_attention_verify(
+ flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ int embed_dim,
+ int num_heads,
+ int kdim,
+ int vdim,
+ float dropout,
+ bool bias,
+ bool add_bias_kv,
+ bool add_zero_attn,
+ enum DataType data_type,
+ flexflow_initializer_t kernel_initializer_,
+ bool apply_rotary_embedding,
+ bool scaling_query,
+ float scaling_factor,
+ bool qk_prod_scaling,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_inc_multiquery_self_attention(
+ flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ int embed_dim,
+ int num_q_heads,
+ int num_kv_heads,
+ int kdim,
+ int vdim,
+ float dropout,
+ bool bias,
+ bool add_bias_kv,
+ bool add_zero_attn,
+ enum DataType data_type,
+ flexflow_initializer_t kernel_initializer_,
+ bool apply_rotary_embedding,
+ bool scaling_query,
+ float scaling_factor,
+ bool qk_prod_scaling,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_spec_inc_multiquery_self_attention(
+ flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ int embed_dim,
+ int num_q_heads,
+ int num_kv_heads,
+ int kdim,
+ int vdim,
+ float dropout,
+ bool bias,
+ bool add_bias_kv,
+ bool add_zero_attn,
+ enum DataType data_type,
+ flexflow_initializer_t kernel_initializer_,
+ bool apply_rotary_embedding,
+ bool scaling_query,
+ float scaling_factor,
+ bool qk_prod_scaling,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_inc_multiquery_self_attention_verify(
+ flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ int embed_dim,
+ int num_q_heads,
+ int num_kv_heads,
+ int kdim,
+ int vdim,
+ float dropout,
+ bool bias,
+ bool add_bias_kv,
+ bool add_zero_attn,
+ enum DataType data_type,
+ flexflow_initializer_t kernel_initializer_,
+ bool apply_rotary_embedding,
+ bool scaling_query,
+ float scaling_factor,
+ bool qk_prod_scaling,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_rms_norm(flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ float eps,
+ int dim,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_arg_top_k(flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ int k,
+ bool sorted,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_beam_top_k(flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ int max_beam_size,
+ bool sorted,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_sampling(flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ float top_p,
+ char const *name);
+
+flexflow_tensor_t flexflow_model_add_argmax(flexflow_model_t handle_,
+ const flexflow_tensor_t input_,
+ bool beam_search,
+ char const *name);
+
void flexflow_model_set_sgd_optimizer(flexflow_model_t handle,
flexflow_sgd_optimizer_t optimizer);
@@ -390,6 +563,18 @@ flexflow_tensor_t flexflow_model_get_parameter_by_id(flexflow_model_t handle,
flexflow_perf_metrics_t
flexflow_model_get_perf_metrics(flexflow_model_t handle);
+void flexflow_model_set_transformer_layer_id(flexflow_model_t handle, int id);
+
+flexflow_generation_result_t
+ flexflow_model_generate(flexflow_model_t handle_,
+ char const *input_text,
+ int max_num_chars,
+ char *output_text,
+ int max_seq_length,
+ int *output_length_and_tokens);
+
+void flexflow_model_set_position_offset(flexflow_model_t handle, int offset);
+
// -----------------------------------------------------------------------
// Tensor
// -----------------------------------------------------------------------
@@ -699,6 +884,92 @@ void flexflow_op_forward(flexflow_op_t handle, flexflow_model_t model);
void flexflow_perform_registration(void);
+// -----------------------------------------------------------------------
+// BatchConfig
+// -----------------------------------------------------------------------
+
+flexflow_batch_config_t flexflow_batch_config_create(void);
+
+void flexflow_batch_config_destroy(flexflow_batch_config_t handle);
+
+// -----------------------------------------------------------------------
+// TreeVerifyBatchConfig
+// -----------------------------------------------------------------------
+
+flexflow_tree_verify_batch_config_t
+ flexflow_tree_verify_batch_config_create(void);
+
+void flexflow_tree_verify_batch_config_destroy(
+ flexflow_tree_verify_batch_config_t handle);
+
+// -----------------------------------------------------------------------
+// BeamSearchBatchConfig
+// -----------------------------------------------------------------------
+
+flexflow_beam_search_batch_config_t
+ flexflow_beam_search_batch_config_create(void);
+
+void flexflow_beam_search_batch_config_destroy(
+ flexflow_beam_search_batch_config_t handle);
+
+// -----------------------------------------------------------------------
+// RequestManager
+// -----------------------------------------------------------------------
+
+flexflow_request_manager_t flexflow_request_manager_get_request_manager(void);
+
+// void flexflow_request_manager_destroy(flexflow_request_manager_t handle_);
+
+void flexflow_request_manager_register_tokenizer(
+ flexflow_request_manager_t handle_,
+ enum ModelType model_type,
+ int bos_token_id,
+ int eos_token_id,
+ char const *tokenizer_filepath);
+
+void flexflow_request_manager_register_output_filepath(
+ flexflow_request_manager_t handle_, char const *output_filepath);
+
+int flexflow_request_manager_register_ssm_model(
+ flexflow_request_manager_t handle_, flexflow_model_t model_handle_);
+
+// -----------------------------------------------------------------------
+// InferenceManager
+// -----------------------------------------------------------------------
+
+flexflow_inference_manager_t
+ flexflow_inference_manager_get_inference_manager(void);
+
+// void flexflow_inference_manager_destroy(flexflow_inference_manager_t
+// handle_);
+
+void flexflow_inference_manager_compile_model_and_allocate_buffer(
+ flexflow_inference_manager_t handle_, flexflow_model_t model_handle);
+
+void flexflow_inference_manager_init_operators_inference(
+ flexflow_inference_manager_t handle_, flexflow_model_t model_handle);
+
+// -----------------------------------------------------------------------
+// FileDataLoader
+// -----------------------------------------------------------------------
+
+flexflow_file_data_loader_t
+ flexflow_file_data_loader_create(char const *weight_file_path,
+ int num_q_heads,
+ int num_kv_heads,
+ int hidden_dim,
+ int qkv_inner_dim,
+ int tensor_parallelism_degree);
+
+void flexflow_file_data_loader_destroy(flexflow_file_data_loader_t handle_);
+
+void flexflow_file_data_loader_load_weights(flexflow_file_data_loader_t handle_,
+ flexflow_model_t model_handle_,
+ int num_layers,
+ char const **layer_names,
+ flexflow_op_t *layers,
+ bool use_full_precision);
+
#ifdef __cplusplus
}
#endif
diff --git a/include/flexflow/gpt_tokenizer.h b/include/flexflow/gpt_tokenizer.h
new file mode 100644
index 0000000000..ec08435809
--- /dev/null
+++ b/include/flexflow/gpt_tokenizer.h
@@ -0,0 +1,221 @@
+// version 0.1
+// Licensed under the MIT License .
+// SPDX-License-Identifier: MIT
+// Copyright (c) 2019-2020 zili wang .
+
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+#include
+
+using json = nlohmann::json;
+
+typedef std::pair bigram_pair;
+typedef std::pair wbigram_pair;
+
+struct hash_pair {
+ template
+ size_t operator()(std::pair const &p) const {
+ auto hash1 = std::hash{}(p.first);
+ auto hash2 = std::hash{}(p.second);
+ return hash1 ^ hash2;
+ }
+};
+
+enum tokenizer_mode { GPT2_TOKENIZER, OPT_TOKENIZER };
+
+class GPT_Tokenizer {
+
+public:
+ GPT_Tokenizer(tokenizer_mode mode_,
+ std::string const &vocab_file,
+ std::string const &merge_file,
+ std::string const &bos_token_str = "",
+ const std::string eos_token_str = "",
+ const std::string pad_token_str = "",
+ const std::string unk_token_str = "",
+ const std::string mask_token_str = "") {
+ mode = mode_;
+ load_vocab(vocab_file);
+ load_merge(merge_file);
+ bos_token = bos_token_str;
+ eos_token = eos_token_str;
+ pad_token = pad_token_str;
+ unk_token = unk_token_str;
+ mask_token = mask_token_str;
+ bytes_encoder = bytes_to_unicode();
+ unicode_to_bytes();
+ };
+ // ~GPT_Tokenizer();
+ std::vector bpe(std::wstring token);
+ std::vector tokenize(std::string str);
+ int32_t convert_token_to_id(std::string token);
+ void encode(std::string str,
+ size_t max_length,
+ std::vector *input_ids,
+ std::vector *mask_ids);
+ std::string decode(std::vector input_ids,
+ std::vector mask_ids);
+ tokenizer_mode mode;
+ std::string bos_token;
+ std::string eos_token;
+ std::string pad_token;
+ std::string unk_token;
+ std::string mask_token;
+ std::string strip(std::string const &inpt);
+
+private:
+ std::unordered_map vocab;
+ std::unordered_map inverse_vocab;
+ std::unordered_map bpe_ranks;
+ wchar_t *bytes_to_unicode();
+ void unicode_to_bytes();
+ wchar_t *bytes_encoder;
+ std::unordered_map bytes_decoder;
+ uint32_t cache_max_size = 500000;
+ uint32_t cache_word_max_length = 30;
+ std::string unicode_letter_expr =
+ "\\u0041-\\u005A\\u0061-\\u007A\\u00AA-\\u00AA\\u00B5-\\u00B5"
+ "\\u00BA-\\u00BA\\u00C0-\\u00D6\\u00D8-\\u00F6\\u00F8-\\u02C1"
+ "\\u02C6-\\u02D1\\u02E0-\\u02E4\\u02EC-\\u02EC\\u02EE-\\u02EE"
+ "\\u0370-\\u0374\\u0376-\\u0377\\u037A-\\u037D\\u037F-\\u037F"
+ "\\u0386-\\u0386\\u0388-\\u038A\\u038C-\\u038C\\u038E-\\u03A1"
+ "\\u03A3-\\u03F5\\u03F7-\\u0481\\u048A-\\u052F\\u0531-\\u0556"
+ "\\u0559-\\u0559\\u0560-\\u0588\\u05D0-\\u05EA\\u05EF-\\u05F2"
+ "\\u0620-\\u064A\\u066E-\\u066F\\u0671-\\u06D3\\u06D5-\\u06D5"
+ "\\u06E5-\\u06E6\\u06EE-\\u06EF\\u06FA-\\u06FC\\u06FF-\\u06FF"
+ "\\u0710-\\u0710\\u0712-\\u072F\\u074D-\\u07A5\\u07B1-\\u07B1"
+ "\\u07CA-\\u07EA\\u07F4-\\u07F5\\u07FA-\\u07FA\\u0800-\\u0815"
+ "\\u081A-\\u081A\\u0824-\\u0824\\u0828-\\u0828\\u0840-\\u0858"
+ "\\u0860-\\u086A\\u08A0-\\u08B4\\u08B6-\\u08C7\\u0904-\\u0939"
+ "\\u093D-\\u093D\\u0950-\\u0950\\u0958-\\u0961\\u0971-\\u0980"
+ "\\u0985-\\u098C\\u098F-\\u0990\\u0993-\\u09A8\\u09AA-\\u09B0"
+ "\\u09B2-\\u09B2\\u09B6-\\u09B9\\u09BD-\\u09BD\\u09CE-\\u09CE"
+ "\\u09DC-\\u09DD\\u09DF-\\u09E1\\u09F0-\\u09F1\\u09FC-\\u09FC"
+ "\\u0A05-\\u0A0A\\u0A0F-\\u0A10\\u0A13-\\u0A28\\u0A2A-\\u0A30"
+ "\\u0A32-\\u0A33\\u0A35-\\u0A36\\u0A38-\\u0A39\\u0A59-\\u0A5C"
+ "\\u0A5E-\\u0A5E\\u0A72-\\u0A74\\u0A85-\\u0A8D\\u0A8F-\\u0A91"
+ "\\u0A93-\\u0AA8\\u0AAA-\\u0AB0\\u0AB2-\\u0AB3\\u0AB5-\\u0AB9"
+ "\\u0ABD-\\u0ABD\\u0AD0-\\u0AD0\\u0AE0-\\u0AE1\\u0AF9-\\u0AF9"
+ "\\u0B05-\\u0B0C\\u0B0F-\\u0B10\\u0B13-\\u0B28\\u0B2A-\\u0B30"
+ "\\u0B32-\\u0B33\\u0B35-\\u0B39\\u0B3D-\\u0B3D\\u0B5C-\\u0B5D"
+ "\\u0B5F-\\u0B61\\u0B71-\\u0B71\\u0B83-\\u0B83\\u0B85-\\u0B8A"
+ "\\u0B8E-\\u0B90\\u0B92-\\u0B95\\u0B99-\\u0B9A\\u0B9C-\\u0B9C"
+ "\\u0B9E-\\u0B9F\\u0BA3-\\u0BA4\\u0BA8-\\u0BAA\\u0BAE-\\u0BB9"
+ "\\u0BD0-\\u0BD0\\u0C05-\\u0C0C\\u0C0E-\\u0C10\\u0C12-\\u0C28"
+ "\\u0C2A-\\u0C39\\u0C3D-\\u0C3D\\u0C58-\\u0C5A\\u0C60-\\u0C61"
+ "\\u0C80-\\u0C80\\u0C85-\\u0C8C\\u0C8E-\\u0C90\\u0C92-\\u0CA8"
+ "\\u0CAA-\\u0CB3\\u0CB5-\\u0CB9\\u0CBD-\\u0CBD\\u0CDE-\\u0CDE"
+ "\\u0CE0-\\u0CE1\\u0CF1-\\u0CF2\\u0D04-\\u0D0C\\u0D0E-\\u0D10"
+ "\\u0D12-\\u0D3A\\u0D3D-\\u0D3D\\u0D4E-\\u0D4E\\u0D54-\\u0D56"
+ "\\u0D5F-\\u0D61\\u0D7A-\\u0D7F\\u0D85-\\u0D96\\u0D9A-\\u0DB1"
+ "\\u0DB3-\\u0DBB\\u0DBD-\\u0DBD\\u0DC0-\\u0DC6\\u0E01-\\u0E30"
+ "\\u0E32-\\u0E33\\u0E40-\\u0E46\\u0E81-\\u0E82\\u0E84-\\u0E84"
+ "\\u0E86-\\u0E8A\\u0E8C-\\u0EA3\\u0EA5-\\u0EA5\\u0EA7-\\u0EB0"
+ "\\u0EB2-\\u0EB3\\u0EBD-\\u0EBD\\u0EC0-\\u0EC4\\u0EC6-\\u0EC6"
+ "\\u0EDC-\\u0EDF\\u0F00-\\u0F00\\u0F40-\\u0F47\\u0F49-\\u0F6C"
+ "\\u0F88-\\u0F8C\\u1000-\\u102A\\u103F-\\u103F\\u1050-\\u1055"
+ "\\u105A-\\u105D\\u1061-\\u1061\\u1065-\\u1066\\u106E-\\u1070"
+ "\\u1075-\\u1081\\u108E-\\u108E\\u10A0-\\u10C5\\u10C7-\\u10C7"
+ "\\u10CD-\\u10CD\\u10D0-\\u10FA\\u10FC-\\u1248\\u124A-\\u124D"
+ "\\u1250-\\u1256\\u1258-\\u1258\\u125A-\\u125D\\u1260-\\u1288"
+ "\\u128A-\\u128D\\u1290-\\u12B0\\u12B2-\\u12B5\\u12B8-\\u12BE"
+ "\\u12C0-\\u12C0\\u12C2-\\u12C5\\u12C8-\\u12D6\\u12D8-\\u1310"
+ "\\u1312-\\u1315\\u1318-\\u135A\\u1380-\\u138F\\u13A0-\\u13F5"
+ "\\u13F8-\\u13FD\\u1401-\\u166C\\u166F-\\u167F\\u1681-\\u169A"
+ "\\u16A0-\\u16EA\\u16F1-\\u16F8\\u1700-\\u170C\\u170E-\\u1711"
+ "\\u1720-\\u1731\\u1740-\\u1751\\u1760-\\u176C\\u176E-\\u1770"
+ "\\u1780-\\u17B3\\u17D7-\\u17D7\\u17DC-\\u17DC\\u1820-\\u1878"
+ "\\u1880-\\u1884\\u1887-\\u18A8\\u18AA-\\u18AA\\u18B0-\\u18F5"
+ "\\u1900-\\u191E\\u1950-\\u196D\\u1970-\\u1974\\u1980-\\u19AB"
+ "\\u19B0-\\u19C9\\u1A00-\\u1A16\\u1A20-\\u1A54\\u1AA7-\\u1AA7"
+ "\\u1B05-\\u1B33\\u1B45-\\u1B4B\\u1B83-\\u1BA0\\u1BAE-\\u1BAF"
+ "\\u1BBA-\\u1BE5\\u1C00-\\u1C23\\u1C4D-\\u1C4F\\u1C5A-\\u1C7D"
+ "\\u1C80-\\u1C88\\u1C90-\\u1CBA\\u1CBD-\\u1CBF\\u1CE9-\\u1CEC"
+ "\\u1CEE-\\u1CF3\\u1CF5-\\u1CF6\\u1CFA-\\u1CFA\\u1D00-\\u1DBF"
+ "\\u1E00-\\u1F15\\u1F18-\\u1F1D\\u1F20-\\u1F45\\u1F48-\\u1F4D"
+ "\\u1F50-\\u1F57\\u1F59-\\u1F59\\u1F5B-\\u1F5B\\u1F5D-\\u1F5D"
+ "\\u1F5F-\\u1F7D\\u1F80-\\u1FB4\\u1FB6-\\u1FBC\\u1FBE-\\u1FBE"
+ "\\u1FC2-\\u1FC4\\u1FC6-\\u1FCC\\u1FD0-\\u1FD3\\u1FD6-\\u1FDB"
+ "\\u1FE0-\\u1FEC\\u1FF2-\\u1FF4\\u1FF6-\\u1FFC\\u2071-\\u2071"
+ "\\u207F-\\u207F\\u2090-\\u209C\\u2102-\\u2102\\u2107-\\u2107"
+ "\\u210A-\\u2113\\u2115-\\u2115\\u2119-\\u211D\\u2124-\\u2124"
+ "\\u2126-\\u2126\\u2128-\\u2128\\u212A-\\u212D\\u212F-\\u2139"
+ "\\u213C-\\u213F\\u2145-\\u2149\\u214E-\\u214E\\u2183-\\u2184"
+ "\\u2C00-\\u2C2E\\u2C30-\\u2C5E\\u2C60-\\u2CE4\\u2CEB-\\u2CEE"
+ "\\u2CF2-\\u2CF3\\u2D00-\\u2D25\\u2D27-\\u2D27\\u2D2D-\\u2D2D"
+ "\\u2D30-\\u2D67\\u2D6F-\\u2D6F\\u2D80-\\u2D96\\u2DA0-\\u2DA6"
+ "\\u2DA8-\\u2DAE\\u2DB0-\\u2DB6\\u2DB8-\\u2DBE\\u2DC0-\\u2DC6"
+ "\\u2DC8-\\u2DCE\\u2DD0-\\u2DD6\\u2DD8-\\u2DDE\\u2E2F-\\u2E2F"
+ "\\u3005-\\u3006\\u3031-\\u3035\\u303B-\\u303C\\u3041-\\u3096"
+ "\\u309D-\\u309F\\u30A1-\\u30FA\\u30FC-\\u30FF\\u3105-\\u312F"
+ "\\u3131-\\u318E\\u31A0-\\u31BF\\u31F0-\\u31FF\\u3400-\\u4DBF"
+ "\\u4E00-\\u9FFC\\uA000-\\uA48C\\uA4D0-\\uA4FD\\uA500-\\uA60C"
+ "\\uA610-\\uA61F\\uA62A-\\uA62B\\uA640-\\uA66E\\uA67F-\\uA69D"
+ "\\uA6A0-\\uA6E5\\uA717-\\uA71F\\uA722-\\uA788\\uA78B-\\uA7BF"
+ "\\uA7C2-\\uA7CA\\uA7F5-\\uA801\\uA803-\\uA805\\uA807-\\uA80A"
+ "\\uA80C-\\uA822\\uA840-\\uA873\\uA882-\\uA8B3\\uA8F2-\\uA8F7"
+ "\\uA8FB-\\uA8FB\\uA8FD-\\uA8FE\\uA90A-\\uA925\\uA930-\\uA946"
+ "\\uA960-\\uA97C\\uA984-\\uA9B2\\uA9CF-\\uA9CF\\uA9E0-\\uA9E4"
+ "\\uA9E6-\\uA9EF\\uA9FA-\\uA9FE\\uAA00-\\uAA28\\uAA40-\\uAA42"
+ "\\uAA44-\\uAA4B\\uAA60-\\uAA76\\uAA7A-\\uAA7A\\uAA7E-\\uAAAF"
+ "\\uAAB1-\\uAAB1\\uAAB5-\\uAAB6\\uAAB9-\\uAABD\\uAAC0-\\uAAC0"
+ "\\uAAC2-\\uAAC2\\uAADB-\\uAADD\\uAAE0-\\uAAEA\\uAAF2-\\uAAF4"
+ "\\uAB01-\\uAB06\\uAB09-\\uAB0E\\uAB11-\\uAB16\\uAB20-\\uAB26"
+ "\\uAB28-\\uAB2E\\uAB30-\\uAB5A\\uAB5C-\\uAB69\\uAB70-\\uABE2"
+ "\\uAC00-\\uD7A3\\uD7B0-\\uD7C6\\uD7CB-\\uD7FB\\uF900-\\uFA6D"
+ "\\uFA70-\\uFAD9\\uFB00-\\uFB06\\uFB13-\\uFB17\\uFB1D-\\uFB1D"
+ "\\uFB1F-\\uFB28\\uFB2A-\\uFB36\\uFB38-\\uFB3C\\uFB3E-\\uFB3E"
+ "\\uFB40-\\uFB41\\uFB43-\\uFB44\\uFB46-\\uFBB1\\uFBD3-\\uFD3D"
+ "\\uFD50-\\uFD8F\\uFD92-\\uFDC7\\uFDF0-\\uFDFB\\uFE70-\\uFE74"
+ "\\uFE76-\\uFEFC\\uFF21-\\uFF3A\\uFF41-\\uFF5A\\uFF66-\\uFFBE"
+ "\\uFFC2-\\uFFC7\\uFFCA-\\uFFCF\\uFFD2-\\uFFD7\\uFFDA-\\uFFDC";
+
+ std::string unicode_number_expr =
+ "\\u0030-\\u0039\\u00B2-\\u00B3\\u00B9-\\u00B9\\u00BC-\\u00BE"
+ "\\u0660-\\u0669\\u06F0-\\u06F9\\u07C0-\\u07C9\\u0966-\\u096F"
+ "\\u09E6-\\u09EF\\u09F4-\\u09F9\\u0A66-\\u0A6F\\u0AE6-\\u0AEF"
+ "\\u0B66-\\u0B6F\\u0B72-\\u0B77\\u0BE6-\\u0BF2\\u0C66-\\u0C6F"
+ "\\u0C78-\\u0C7E\\u0CE6-\\u0CEF\\u0D58-\\u0D5E\\u0D66-\\u0D78"
+ "\\u0DE6-\\u0DEF\\u0E50-\\u0E59\\u0ED0-\\u0ED9\\u0F20-\\u0F33"
+ "\\u1040-\\u1049\\u1090-\\u1099\\u1369-\\u137C\\u16EE-\\u16F0"
+ "\\u17E0-\\u17E9\\u17F0-\\u17F9\\u1810-\\u1819\\u1946-\\u194F"
+ "\\u19D0-\\u19DA\\u1A80-\\u1A89\\u1A90-\\u1A99\\u1B50-\\u1B59"
+ "\\u1BB0-\\u1BB9\\u1C40-\\u1C49\\u1C50-\\u1C59\\u2070-\\u2070"
+ "\\u2074-\\u2079\\u2080-\\u2089\\u2150-\\u2182\\u2185-\\u2189"
+ "\\u2460-\\u249B\\u24EA-\\u24FF\\u2776-\\u2793\\u2CFD-\\u2CFD"
+ "\\u3007-\\u3007\\u3021-\\u3029\\u3038-\\u303A\\u3192-\\u3195"
+ "\\u3220-\\u3229\\u3248-\\u324F\\u3251-\\u325F\\u3280-\\u3289"
+ "\\u32B1-\\u32BF\\uA620-\\uA629\\uA6E6-\\uA6EF\\uA830-\\uA835"
+ "\\uA8D0-\\uA8D9\\uA900-\\uA909\\uA9D0-\\uA9D9\\uA9F0-\\uA9F9"
+ "\\uAA50-\\uAA59\\uABF0-\\uABF9\\uFF10-\\uFF19";
+
+ std::wstring wpat_expr = utf8_to_wstring(
+ "'s|'t|'re|'ve|'m|'ll|'d| ?[" + unicode_letter_expr + "]+| ?[" +
+ unicode_number_expr + "]+| ?[^\\s" + unicode_letter_expr +
+ unicode_number_expr + "]+|\\s+(?!\\S)|\\s+");
+
+ const std::wregex pat = std::wregex(wpat_expr);
+ std::unordered_map> cache;
+ void load_vocab(std::string const &vocab_file);
+ void load_merge(std::string const &merge_file);
+
+ std::unordered_set
+ get_pairs(std::vector word);
+ std::wstring utf8_to_wstring(std::string const &src);
+ std::u32string utf8_to_utf32(std::string const &src);
+ std::string wstring_to_utf8(std::wstring const &src);
+ std::string utf32_to_utf8(std::u32string const &src);
+
+ std::vector split(std::string const &s,
+ std::regex rgx = std::regex("\\s+"));
+};
diff --git a/include/flexflow/inference.h b/include/flexflow/inference.h
new file mode 100644
index 0000000000..f24a797ffd
--- /dev/null
+++ b/include/flexflow/inference.h
@@ -0,0 +1,50 @@
+/* Copyright 2022 CMU, Stanford, Facebook, LANL
+ *
+ * Licensed under the Apache License, Version 2.0 (the "License");
+ * you may not use this file except in compliance with the License.
+ * You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+#pragma once
+#include "flexflow/batch_config.h"
+#include
+#include
+
+namespace FlexFlow {
+
+struct GenerationConfig {
+ bool do_sample = false;
+ float temperature = 0.8;
+ float topp = 0.6;
+ GenerationConfig(bool _do_sample, float _temperature, float _topp) {
+ temperature = _temperature > 0 ? _temperature : temperature;
+ topp = _topp > 0 ? _topp : topp;
+ do_sample = _do_sample;
+ }
+ GenerationConfig() {}
+};
+
+struct GenerationResult {
+ using RequestGuid = BatchConfig::RequestGuid;
+ using TokenId = BatchConfig::TokenId;
+ RequestGuid guid;
+ std::string input_text;
+ std::string output_text;
+ std::vector input_tokens;
+ std::vector output_tokens;
+};
+
+#include
+#include
+
+std::string join_path(std::vector const &paths);
+
+} // namespace FlexFlow
diff --git a/include/flexflow/model.h b/include/flexflow/model.h
index cb1b26d624..bc3c7e6545 100644
--- a/include/flexflow/model.h
+++ b/include/flexflow/model.h
@@ -17,6 +17,7 @@
#include "accessor.h"
#include "config.h"
#include "device.h"
+#include "flexflow/inference.h"
#include "flexflow/memory_optimization.h"
#include "flexflow/node.h"
#include "flexflow/operator_params.h"
@@ -30,6 +31,7 @@
#include "optimizer.h"
#include "parallel_tensor.h"
#include "recompile.h"
+#include "runtime.h"
#include "simulator.h"
#include "tensor.h"
#include "tl/optional.hpp"
@@ -55,6 +57,10 @@ enum TaskIDs {
ELEMENTUNARY_INIT_TASK_ID,
ELEMENTUNARY_FWD_TASK_ID,
ELEMENTUNARY_BWD_TASK_ID,
+ EXPERTS_INIT_TASK_ID,
+ EXPERTS_FWD_TASK_ID,
+ EXPERTS_BWD_TASK_ID,
+ EXPERTS_INF_TASK_ID,
CONV2D_INIT_TASK_ID,
CONV2D_INIT_PARA_TASK_ID,
CONV2D_FWD_TASK_ID,
@@ -99,6 +105,7 @@ enum TaskIDs {
LAYERNORM_BWD_TASK_ID,
LINEAR_INIT_TASK_ID,
LINEAR_INIT_PARA_TASK_ID,
+ LINEAR_INF_TASK_ID,
LINEAR_FWD_TASK_ID,
LINEAR_BWD_TASK_ID,
LINEAR_BWD2_TASK_ID,
@@ -109,6 +116,7 @@ enum TaskIDs {
SOFTMAX_INIT_TASK_ID,
SOFTMAX_FWD_TASK_ID,
SOFTMAX_BWD_TASK_ID,
+ SOFTMAX_INF_TASK_ID,
CONCAT_INIT_TASK_ID,
CONCAT_FWD_TASK_ID,
CONCAT_BWD_TASK_ID,
@@ -127,16 +135,36 @@ enum TaskIDs {
TOPK_INIT_TASK_ID,
TOPK_FWD_TASK_ID,
TOPK_BWD_TASK_ID,
+ ARG_TOPK_INIT_TASK_ID,
+ ARG_TOPK_INF_TASK_ID,
+ SAMPLING_INIT_TASK_ID,
+ SAMPLING_INF_TASK_ID,
+ ARGMAX_INIT_TASK_ID,
+ ARGMAX_BEAM_INF_TASK_ID,
+ ARGMAX_NORM_INF_TASK_ID,
TRANSPOSE_INIT_TASK_ID,
TRANSPOSE_FWD_TASK_ID,
TRANSPOSE_BWD_TASK_ID,
ATTENTION_INIT_TASK_ID,
ATTENTION_FWD_TASK_ID,
ATTENTION_BWD_TASK_ID,
+ RMSNROM_INIT_TASK_ID,
+ RMSNROM_FWD_TASK_ID,
+ BEAM_TOPK_INIT_TASK_ID,
+ BEAM_TOPK_INF_TASK_ID,
+ INC_MULTIHEAD_SELF_ATTENTION_INIT_TASK_ID,
+ INC_MULTIHEAD_SELF_ATTENTION_FWD_TASK_ID,
+ INC_MULTIHEAD_SELF_ATTENTION_BWD_TASK_ID,
+ INC_MULTIHEAD_SELF_ATTENTION_INF_TASK_ID,
+ SPEC_INC_MULTIHEAD_SELF_ATTENTION_INIT_TASK_ID,
+ SPEC_INC_MULTIHEAD_SELF_ATTENTION_INF_TASK_ID,
+ TREE_INC_MULTIHEAD_SELF_ATTENTION_INIT_TASK_ID,
+ TREE_INC_MULTIHEAD_SELF_ATTENTION_INF_TASK_ID,
MSELOSS_BWD_TASK_ID,
FUSEDOP_INIT_TASK_ID,
FUSEDOP_FWD_TASK_ID,
FUSEDOP_BWD_TASK_ID,
+ FUSEDOP_INF_TASK_ID,
NOOP_INIT_TASK_ID,
// Metrics tasks
METRICS_COMP_TASK_ID,
@@ -190,9 +218,20 @@ enum TaskIDs {
PIPELINE_INIT_TASK_ID,
PIPELINE_FWD_TASK_ID,
PIPELINE_BWD_TASK_ID,
+ ALLREDUCE_INIT_TASK_ID,
+ ALLREDUCE_INF_TASK_ID,
+ ALLREDUCE_FWD_TASK_ID,
+ ALLREDUCE_BWD_TASK_ID,
FUSED_PARALLELOP_INIT_TASK_ID,
FUSED_PARALLELOP_FWD_TASK_ID,
FUSED_PARALLELOP_BWD_TASK_ID,
+ // InferenceManager & RequestManager
+ RM_LOAD_TOKENS_TASK_ID,
+ RM_LOAD_POSITION_TASK_ID,
+ RM_PREPARE_NEXT_BATCH_TASK_ID,
+ RM_PREPARE_NEXT_BATCH_BEAM_TASK_ID,
+ RM_PREPARE_NEXT_BATCH_INIT_TASK_ID,
+ RM_PREPARE_NEXT_BATCH_VERIFY_TASK_ID,
// Custom tasks
CUSTOM_GPU_TASK_ID_FIRST,
CUSTOM_GPU_TASK_ID_1,
@@ -216,6 +255,8 @@ enum TaskIDs {
// Make sure PYTHON_TOP_LEVEL_TASK_ID is
// consistent with python/main.cc
PYTHON_TOP_LEVEL_TASK_ID = 11111,
+ // Tensor Equal Task
+ TENSOR_EQUAL_TASK_ID,
};
enum ShardingID {
@@ -259,23 +300,33 @@ class Dropout;
class ElementBinary;
class ElementUnary;
class Embedding;
+class Experts;
class Flat;
class Gather;
class Group_by;
class LayerNorm;
class Linear;
class MultiHeadAttention;
+class IncMultiHeadSelfAttention;
+class TreeIncMultiHeadSelfAttention;
class Pool2D;
class Reduce;
class Reshape;
class Softmax;
class Split;
class TopK;
+class ArgTopK;
class Transpose;
+class RMSNorm;
+class BeamTopK;
+class SpecIncMultiHeadSelfAttention;
+class Sampling;
+class ArgMax;
class Combine;
class Repartition;
class Reduction;
class Replicate;
+class AllReduce;
class FusedParallelOp;
class ParallelOpInfo;
@@ -325,12 +376,13 @@ std::vector
class FFModel {
public:
- FFModel(FFConfig &config);
+ FFModel(FFConfig &config, bool cpu_offload = false);
static constexpr float PROPAGATION_CHANCE = 0.25;
static constexpr float CONTINUE_PROPAGATION_CHANCE = 0.75;
static constexpr float PROPAGATION_SIZE_WEIGHT = 1.0;
+ bool cpu_offload;
// C++ APIs for constructing models
// Add an exp layer
Tensor exp(const Tensor x, char const *name = NULL);
@@ -422,7 +474,7 @@ class FFModel {
char const *name = NULL);
// Add an embedding layer
Tensor embedding(const Tensor input,
- int num_entires,
+ int num_entries,
int outDim,
AggrMode aggr,
DataType dtype = DT_FLOAT,
@@ -468,11 +520,12 @@ class FFModel {
PoolType type = POOL_MAX,
ActiMode activation = AC_MODE_NONE,
char const *name = NULL);
- // Add a batch_norm layer
+ // Add a layer_norm layer
Tensor layer_norm(const Tensor input,
std::vector const &axes,
bool elementwise_affine,
float eps,
+ DataType data_type = DT_NONE,
char const *name = NULL);
// Add a batch_norm layer
Tensor
@@ -483,12 +536,24 @@ class FFModel {
int a_seq_length_dim = -1,
int b_seq_length_dim = -1,
char const *name = nullptr);
+ // Add a root mean square layer
+ Tensor rms_norm(const Tensor input,
+ float eps,
+ int dim,
+ DataType data_type = DT_NONE,
+ char const *name = NULL);
+ // Add a beam search top k layer
+ Tensor beam_top_k(const Tensor input,
+ int max_beam_size,
+ bool sorted,
+ char const *name = NULL);
+
// Add a dense layer
Tensor dense(const Tensor input,
int outDim,
ActiMode activation = AC_MODE_NONE,
bool use_bias = true,
- DataType data_type = DT_FLOAT,
+ DataType data_type = DT_NONE,
Layer const *shared_op = NULL,
Initializer *kernel_initializer = NULL,
Initializer *bias_initializer = NULL,
@@ -500,6 +565,16 @@ class FFModel {
// Add a concat layer
Tensor
concat(int n, Tensor const *tensors, int axis, char const *name = NULL);
+ // Add an experts layer
+ Tensor experts(
+ Tensor const *inputs,
+ int num_experts,
+ int experts_start_idx,
+ int experts_output_dim_size,
+ float alpha,
+ int experts_num_layers = 1, // number of linear layers per expert
+ int experts_internal_dim_size = 0, // hidden dimension for internal layers
+ char const *name = NULL);
// Add a mean layer
Tensor mean(const Tensor input,
std::vector const &dims,
@@ -521,7 +596,10 @@ class FFModel {
// Add a flat layer
Tensor flat(const Tensor input, char const *name = NULL);
// Add a softmax layer
- Tensor softmax(const Tensor input, int dim = -1, char const *name = NULL);
+ Tensor softmax(const Tensor input,
+ int dim = -1,
+ DataType data_type = DT_NONE,
+ char const *name = NULL);
// Create input tensors and constants
Tensor transpose(const Tensor input,
std::vector const &perm,
@@ -539,6 +617,13 @@ class FFModel {
int k,
bool sorted,
char const *name = NULL);
+ Tensor arg_top_k(const Tensor input,
+ // Tensor *outputs,
+ int k,
+ bool sorted,
+ char const *name = NULL);
+ Tensor argmax(const Tensor input, bool beam_search, char const *name = NULL);
+ Tensor sampling(const Tensor input, float top_p, char const *name = NULL);
Tensor multihead_attention(const Tensor query,
const Tensor key,
const Tensor value,
@@ -550,8 +635,117 @@ class FFModel {
bool bias = true,
bool add_bias_kv = false,
bool add_zero_attn = false,
+ DataType data_type = DT_NONE,
Initializer *kernel_initializer = NULL,
char const *name = NULL);
+ Tensor inc_multihead_self_attention(const Tensor input,
+ int embed_dim,
+ int num_heads,
+ int kdim = 0,
+ int vdim = 0,
+ float dropout = 0.0f,
+ bool bias = false,
+ bool add_bias_kv = false,
+ bool add_zero_attn = false,
+ DataType data_type = DT_NONE,
+ Initializer *kernel_initializer = NULL,
+ bool apply_rotary_embedding = false,
+ bool scaling_query = false,
+ float scaling_factor = 1.0f,
+ bool qk_prod_scaling = true,
+ char const *name = NULL);
+ Tensor
+ spec_inc_multihead_self_attention(const Tensor input,
+ int embed_dim,
+ int num_heads,
+ int kdim = 0,
+ int vdim = 0,
+ float dropout = 0.0f,
+ bool bias = false,
+ bool add_bias_kv = false,
+ bool add_zero_attn = false,
+ DataType data_type = DT_NONE,
+ Initializer *kernel_initializer = NULL,
+ bool apply_rotary_embedding = false,
+ bool scaling_query = false,
+ float scaling_factor = 1.0f,
+ bool qk_prod_scaling = true,
+ char const *name = NULL);
+ Tensor inc_multihead_self_attention_verify(
+ const Tensor input,
+ int embed_dim,
+ int num_heads,
+ int kdim = 0,
+ int vdim = 0,
+ float dropout = 0.0f,
+ bool bias = false,
+ bool add_bias_kv = false,
+ bool add_zero_attn = false,
+ DataType data_type = DT_NONE,
+ Initializer *kernel_initializer = NULL,
+ bool apply_rotary_embedding = false,
+ bool scaling_query = false,
+ float scaling_factor = 1.0f,
+ bool qk_prod_scaling = true,
+ char const *name = NULL);
+ Tensor inc_multiquery_self_attention(const Tensor input,
+ int embed_dim,
+ int num_q_heads,
+ int num_kv_heads,
+ int kdim = 0,
+ int vdim = 0,
+ float dropout = 0.0f,
+ bool bias = false,
+ bool add_bias_kv = false,
+ bool add_zero_attn = false,
+ DataType data_type = DT_NONE,
+ Initializer *kernel_initializer = NULL,
+ bool apply_rotary_embedding = false,
+ bool scaling_query = false,
+ float scaling_factor = 1.0f,
+ bool qk_prod_scaling = true,
+ char const *name = NULL);
+ Tensor
+ spec_inc_multiquery_self_attention(const Tensor input,
+ int embed_dim,
+ int num_q_heads,
+ int num_kv_heads,
+ int kdim = 0,
+ int vdim = 0,
+ float dropout = 0.0f,
+ bool bias = false,
+ bool add_bias_kv = false,
+ bool add_zero_attn = false,
+ DataType data_type = DT_NONE,
+ Initializer *kernel_initializer = NULL,
+ bool apply_rotary_embedding = false,
+ bool scaling_query = false,
+ float scaling_factor = 1.0f,
+ bool qk_prod_scaling = true,
+ char const *name = NULL);
+ Tensor inc_multiquery_self_attention_verify(
+ const Tensor input,
+ int embed_dim,
+ int num_q_heads,
+ int num_kv_heads,
+ int kdim = 0,
+ int vdim = 0,
+ float dropout = 0.0f,
+ bool bias = false,
+ bool add_bias_kv = false,
+ bool add_zero_attn = false,
+ DataType data_type = DT_NONE,
+ Initializer *kernel_initializer = NULL,
+ bool apply_rotary_embedding = false,
+ bool scaling_query = false,
+ float scaling_factor = 1.0f,
+ bool qk_prod_scaling = true,
+ char const *name = NULL);
+ // ========================================
+ // Inference APIs
+ // ========================================
+ GenerationResult generate(std::string const &text, int max_seq_length);
+
Tensor create_tensor_legion_ordering(int num_dim,
int const dims[],
DataType data_type,
@@ -683,6 +877,7 @@ class FFModel {
auto input_shapes = get_input_shape(input);
if (!params.is_valid(input_shapes)) {
+ printf("!params.is_valid(input_shapes)\n");
return PCG::Node::INVALID_NODE;
}
@@ -690,7 +885,7 @@ class FFModel {
std::pair::type, Params> key{
input_shapes, params};
- auto &cache = get::type, Params>,
T *>>(this->cached_ops);
auto const &it = cache.find(key);
@@ -765,8 +960,14 @@ class FFModel {
std::vector const ®ions,
Legion::Context ctx,
Legion::Runtime *runtime);
+ // ========================================
+ // Internal APIs that should not be invoked from applications
+ // ========================================
void reset_metrics();
void init_operators();
+ void init_operators_inference(
+ std::vector const &batch_inputs,
+ std::vector const &batch_outputs);
void prefetch();
void forward(int seq_length = -1);
void compute_metrics();
@@ -783,6 +984,9 @@ class FFModel {
LossType loss_type,
std::vector const &metrics,
CompMode comp_mode = COMP_MODE_TRAINING);
+ void compile_inference();
+ void set_transformer_layer_id(int id);
+ void set_position_offset(int offset);
void graph_optimize(size_t budget,
bool only_data_parallel,
std::unique_ptr &best_graph,
@@ -839,6 +1043,9 @@ class FFModel {
public:
size_t op_global_guid, layer_global_guid;
size_t tensor_global_guid, parallel_tensor_global_guid, node_global_guid;
+ size_t current_transformer_layer_id;
+ // positional embedding start offset
+ int position_offset;
FFConfig config;
FFIterationConfig iter_config;
Optimizer *optimizer;
@@ -883,6 +1090,9 @@ class FFModel {
ElementUnary *>,
std::unordered_map,
Embedding *>,
+ std::unordered_map<
+ std::pair, ExpertsParams>,
+ Experts *>,
std::unordered_map, Flat *>,
std::unordered_map<
std::pair,
@@ -903,6 +1113,21 @@ class FFModel {
ParallelTensorShape>,
MultiHeadAttentionParams>,
MultiHeadAttention *>,
+ std::unordered_map<
+ std::pair,
+ IncMultiHeadSelfAttention *>,
+ std::unordered_map,
+ BeamTopK *>,
+ std::unordered_map,
+ Sampling *>,
+ std::unordered_map,
+ ArgMax *>,
+ std::unordered_map<
+ std::pair,
+ SpecIncMultiHeadSelfAttention *>,
+ std::unordered_map<
+ std::pair,
+ TreeIncMultiHeadSelfAttention *>,
std::unordered_map,
Reduce *>,
std::unordered_map,
@@ -911,8 +1136,12 @@ class FFModel {
std::unordered_map,
Softmax *>,
std::unordered_map, TopK *>,
+ std::unordered_map,
+ ArgTopK *>,
std::unordered_map,
Transpose *>,
+ std::unordered_map,
+ RMSNorm *>,
std::unordered_map,
Repartition *>,
std::unordered_map,
@@ -921,6 +1150,8 @@ class FFModel {
Reduction *>,
std::unordered_map,
Combine *>,
+ std::unordered_map,
+ AllReduce *>,
std::unordered_map,
FusedParallelOp *>>
cached_ops;
diff --git a/include/flexflow/operator.h b/include/flexflow/operator.h
index 3fd84ce55b..1b2fc7bbfc 100644
--- a/include/flexflow/operator.h
+++ b/include/flexflow/operator.h
@@ -1,6 +1,7 @@
#ifndef _OPERATOR_H
#define _OPERATOR_H
+#include "flexflow/batch_config.h"
#include "flexflow/fftype.h"
#include "flexflow/machine_view.h"
#include "flexflow/parallel_tensor.h"
@@ -19,11 +20,33 @@ enum class MappingRecordType { INPUT_OUTPUT, INPUT_WEIGHT };
enum class MappingOperation { PARTITION, REPLICATE };
+/** @brief A class to keep track of a dimension relation between two tensors
+ * used by an operator.
+ *
+ * Dimension relations are one-to-one mappings between the dimensions of the
+ * input, weights, and output tensors of an operator. Introduced in the Unity
+ * paper, dimension relations allow FlexFlow to keep track of an operator's
+ * parallelization plans as part of the Parallel Computation Graph (PCG).
+ *
+ * Each ParallelDimMappingRecord only keeps track of a single dimension
+ * relation.
+ *
+ * ParallelDimMappingRecord objects must be initialized with a
+ * MappingRecordType, which can be INPUT_OUTPUT, if the ParallelDimMappingRecord
+ * is tracking a dimension relation between the input and the output tensor, or
+ * INPUT_WEIGHT, if the ParallelDimMappingRecord is tracking a dimension
+ * relation between the input tensor and the weights tensor.
+ *
+ */
class ParallelDimMappingRecord {
private:
ParallelDimMappingRecord(MappingRecordType);
public:
+ /**
+ * @brief We disable this constructor because ParallelDimMappingRecord objects
+ * must specify the MappingRecordType upon creation.
+ */
ParallelDimMappingRecord() = delete;
static ParallelDimMappingRecord input_output_record(
@@ -185,8 +208,22 @@ class Op {
virtual bool get_weight_parameter(TNParameter, DIMParameter, int *) const;
// Pure virtual functions that must be implemented
virtual void init(FFModel const &) = 0;
+ virtual void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) {
+ assert(false);
+ };
virtual void forward(FFModel const &) = 0;
virtual void backward(FFModel const &) = 0;
+ // Pure virtual functions for inference
+ virtual Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) {
+ assert(false);
+ };
virtual void print_layer(FFModel const &model) = 0;
virtual bool measure_operator_cost(Simulator *sim,
MachineView const &mv,
@@ -242,12 +279,21 @@ class Op {
#endif
protected:
void set_argumentmap_for_init(FFModel const &ff, Legion::ArgumentMap &argmap);
+ void set_argumentmap_for_init_inference(FFModel const &ff,
+ Legion::ArgumentMap &argmap,
+ ParallelTensor const output0);
void set_argumentmap_for_forward(FFModel const &ff,
Legion::ArgumentMap &argmap);
+ void set_argumentmap_for_inference(FFModel const &ff,
+ Legion::ArgumentMap &argmap,
+ ParallelTensor const output0);
void set_argumentmap_for_backward(FFModel const &ff,
Legion::ArgumentMap &argmap);
void set_opmeta_from_futuremap(FFModel const &ff,
Legion::FutureMap const &fm);
+ void set_opmeta_from_futuremap_inference(FFModel const &ff,
+ Legion::FutureMap const &fm,
+ ParallelTensor const output0);
void solve_parallel_dim_mappings(
std::vector const &inputs,
std::vector const &weights,
@@ -267,8 +313,10 @@ class Op {
ParallelParameter weights[MAX_NUM_WEIGHTS];
bool trainableInputs[MAX_NUM_INPUTS];
OpMeta *meta[MAX_NUM_WORKERS];
+ std::map inference_meta;
int numInputs, numWeights, numOutputs;
bool profiling;
+ bool add_bias_only_once;
#ifdef FF_USE_NCCL
ncclUniqueId ncclId;
#endif
diff --git a/include/flexflow/operator_params.h b/include/flexflow/operator_params.h
index 24c84a85ed..4f0432cb93 100644
--- a/include/flexflow/operator_params.h
+++ b/include/flexflow/operator_params.h
@@ -3,8 +3,11 @@
#include "flexflow/ops/aggregate_params.h"
#include "flexflow/ops/aggregate_spec_params.h"
+#include "flexflow/ops/arg_topk_params.h"
+#include "flexflow/ops/argmax_params.h"
#include "flexflow/ops/attention_params.h"
#include "flexflow/ops/batch_matmul_params.h"
+#include "flexflow/ops/beam_topk_params.h"
#include "flexflow/ops/cast_params.h"
#include "flexflow/ops/concat_params.h"
#include "flexflow/ops/conv_2d_params.h"
@@ -12,18 +15,25 @@
#include "flexflow/ops/element_binary_params.h"
#include "flexflow/ops/element_unary_params.h"
#include "flexflow/ops/embedding_params.h"
+#include "flexflow/ops/experts_params.h"
#include "flexflow/ops/flat_params.h"
#include "flexflow/ops/gather_params.h"
#include "flexflow/ops/groupby_params.h"
+#include "flexflow/ops/inc_multihead_self_attention_params.h"
#include "flexflow/ops/layer_norm_params.h"
#include "flexflow/ops/linear_params.h"
#include "flexflow/ops/pool_2d_params.h"
#include "flexflow/ops/reduce_params.h"
#include "flexflow/ops/reshape_params.h"
+#include "flexflow/ops/rms_norm_params.h"
+#include "flexflow/ops/sampling_params.h"
#include "flexflow/ops/softmax_params.h"
+#include "flexflow/ops/spec_inc_multihead_self_attention_params.h"
#include "flexflow/ops/split_params.h"
#include "flexflow/ops/topk_params.h"
#include "flexflow/ops/transpose_params.h"
+#include "flexflow/ops/tree_inc_multihead_self_attention_params.h"
+#include "flexflow/parallel_ops/allreduce_params.h"
#include "flexflow/parallel_ops/combine_params.h"
#include "flexflow/parallel_ops/fused_parallel_op_params.h"
#include "flexflow/parallel_ops/partition_params.h"
@@ -51,17 +61,26 @@ using OperatorParameters = mp::variant;
tl::optional get_op_parameters(Op const *op);
diff --git a/include/flexflow/ops/aggregate.h b/include/flexflow/ops/aggregate.h
index 4eeb695e92..3ba4f414d1 100644
--- a/include/flexflow/ops/aggregate.h
+++ b/include/flexflow/ops/aggregate.h
@@ -1,6 +1,7 @@
#ifndef _FLEXFLOW_AGGREGATE_H_
#define _FLEXFLOW_AGGREGATE_H_
+#include "flexflow/inference.h"
#include "flexflow/model.h"
#include "flexflow/ops/aggregate_params.h"
@@ -8,7 +9,7 @@ namespace FlexFlow {
#define AGGREGATE_MAX_K 4
#define AGGREGATE_MAX_BATCH_SIZE 64
-#define AGGREGATE_MAX_N 12
+#define AGGREGATE_MAX_N 128
class AggregateMeta : public OpMeta {
public:
@@ -26,7 +27,7 @@ class Aggregate : public Op {
ParallelTensor const *inputs,
int _n,
float _lambda_bal,
- char const *name);
+ char const *name = nullptr);
Aggregate(FFModel &model,
Aggregate const &other,
std::vector const &inputs);
@@ -35,7 +36,16 @@ class Aggregate : public Op {
Input const &inputs,
char const *name = nullptr);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void backward(FFModel const &) override;
void print_layer(FFModel const &model) override {
assert(0);
@@ -81,6 +91,10 @@ class Aggregate : public Op {
int const batch_size,
int out_dim);
void serialize(Legion::Serializer &s) const override;
+ static PCG::Node deserialize(FFModel &ff,
+ Legion::Deserializer &d,
+ Input const &inputs,
+ int num_inputs);
bool measure_operator_cost(Simulator *sim,
MachineView const &mv,
CostMetrics &cost_metrics) const override;
diff --git a/include/flexflow/ops/aggregate_spec.h b/include/flexflow/ops/aggregate_spec.h
index 8c1966e72a..4302dd0733 100644
--- a/include/flexflow/ops/aggregate_spec.h
+++ b/include/flexflow/ops/aggregate_spec.h
@@ -1,6 +1,7 @@
#ifndef _FLEXFLOW_AGGREGATE_SPEC_H_
#define _FLEXFLOW_AGGREGATE_SPEC_H_
+#include "flexflow/inference.h"
#include "flexflow/model.h"
#include "flexflow/ops/aggregate_spec_params.h"
@@ -27,7 +28,16 @@ class AggregateSpec : public Op {
float _lambda_bal,
char const *name);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void backward(FFModel const &) override;
void print_layer(FFModel const &model) override {
assert(0);
diff --git a/include/flexflow/ops/arg_topk.h b/include/flexflow/ops/arg_topk.h
new file mode 100644
index 0000000000..8b2d2aa11c
--- /dev/null
+++ b/include/flexflow/ops/arg_topk.h
@@ -0,0 +1,98 @@
+#ifndef _FLEXFLOW_ARG_TOPK_H_
+#define _FLEXFLOW_ARG_TOPK_H_
+
+#include "flexflow/inference.h"
+#include "flexflow/model.h"
+#include "flexflow/node.h"
+#include "flexflow/ops/arg_topk_params.h"
+
+namespace FlexFlow {
+
+class ArgTopKMeta : public OpMeta {
+public:
+ ArgTopKMeta(FFHandler handle, Op const *op);
+ bool sorted;
+};
+
+class ArgTopK : public Op {
+public:
+ using Params = ArgTopKParams;
+ using Input = ParallelTensor;
+ ArgTopK(FFModel &model,
+ LayerID const &layer_guid,
+ const ParallelTensor input,
+ int k,
+ bool sorted,
+ char const *name);
+ ArgTopK(FFModel &model,
+ LayerID const &layer_guid,
+ ArgTopK const &other,
+ const ParallelTensor input);
+ ArgTopK(FFModel &model,
+ Params const ¶ms,
+ Input const input,
+ char const *name = nullptr);
+ void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void forward(FFModel const &) override;
+ void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void print_layer(FFModel const &model) override {
+ assert(0);
+ }
+ static Op *
+ create_operator_from_layer(FFModel &model,
+ Layer const *layer,
+ std::vector const &inputs);
+
+ static OpMeta *init_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static InferenceResult
+ inference_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ void serialize(Legion::Serializer &s) const override;
+ static PCG::Node deserialize(FFModel &ff,
+ Legion::Deserializer &d,
+ ParallelTensor inputs[],
+ int num_inputs);
+ Op *materialize(FFModel &ff,
+ ParallelTensor inputs[],
+ int num_inputs) const override;
+ bool measure_operator_cost(Simulator *sim,
+ MachineView const &pc,
+ CostMetrics &cost_metrics) const override;
+ template
+ static void forward_kernel(ArgTopKMeta const *m,
+ DT const *input_ptr,
+ // float *output_ptr,
+ int *indices_ptr,
+ size_t batch_size,
+ int length,
+ int k,
+ bool sorted,
+ ffStream_t stream);
+ static void forward_kernel_wrapper(ArgTopKMeta const *m,
+ GenericTensorAccessorR const &input,
+ GenericTensorAccessorW const &indices,
+ int batch_size);
+ Params get_params() const;
+
+public:
+ int k;
+ bool sorted;
+};
+
+}; // namespace FlexFlow
+
+#endif
diff --git a/include/flexflow/ops/arg_topk_params.h b/include/flexflow/ops/arg_topk_params.h
new file mode 100644
index 0000000000..9d2a21034f
--- /dev/null
+++ b/include/flexflow/ops/arg_topk_params.h
@@ -0,0 +1,27 @@
+#ifndef _FLEXFLOW_ARG_TOPK_PARAMS_H
+#define _FLEXFLOW_ARG_TOPK_PARAMS_H
+
+#include "flexflow/ffconst.h"
+#include "flexflow/fftype.h"
+#include "flexflow/parallel_tensor.h"
+
+namespace FlexFlow {
+
+struct ArgTopKParams {
+ LayerID layer_guid;
+ int k;
+ bool sorted;
+ bool is_valid(ParallelTensorShape const &) const;
+};
+bool operator==(ArgTopKParams const &, ArgTopKParams const &);
+
+} // namespace FlexFlow
+
+namespace std {
+template <>
+struct hash {
+ size_t operator()(FlexFlow::ArgTopKParams const &) const;
+};
+} // namespace std
+
+#endif // _FLEXFLOW_ARG_TOPK_PARAMS_H
diff --git a/include/flexflow/ops/argmax.h b/include/flexflow/ops/argmax.h
new file mode 100644
index 0000000000..298059e3ed
--- /dev/null
+++ b/include/flexflow/ops/argmax.h
@@ -0,0 +1,112 @@
+#ifndef _FLEXFLOW_ARG_MAX_H_
+#define _FLEXFLOW_ARG_MAX_H_
+
+#include "flexflow/inference.h"
+#include "flexflow/model.h"
+#include "flexflow/node.h"
+#include "flexflow/ops/argmax_params.h"
+#include "flexflow/utils/memory_allocator.h"
+
+namespace FlexFlow {
+
+class ArgMaxMeta : public OpMeta {
+public:
+ bool beam_search;
+ float *probs;
+ void *d_temp_storage;
+ size_t temp_storage_bytes = 0;
+ int *d_offsets;
+ void *d_out;
+ Realm::RegionInstance reserveInst;
+ ArgMaxMeta(FFHandler handler,
+ Op const *op,
+ Legion::Domain const &input_domain,
+ Legion::Domain const &output_domain,
+ GenericTensorAccessorW input,
+ int batch_size,
+ int total_ele,
+ MemoryAllocator &gpu_mem_allocator);
+ ~ArgMaxMeta(void);
+};
+
+class ArgMax : public Op {
+public:
+ using Params = ArgMaxParams;
+ using Input = ParallelTensor;
+ ArgMax(FFModel &model,
+ const ParallelTensor input,
+ bool beam_search,
+ char const *name);
+ ArgMax(FFModel &model, ArgMax const &other, const ParallelTensor input);
+ ArgMax(FFModel &model,
+ Params const ¶ms,
+ Input const input,
+ char const *name = nullptr);
+ void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void forward(FFModel const &) override;
+ void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void print_layer(FFModel const &model) override {
+ assert(0);
+ }
+ static Op *
+ create_operator_from_layer(FFModel &model,
+ Layer const *layer,
+ std::vector const &inputs);
+
+ static OpMeta *init_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static BeamInferenceResult
+ inference_task_beam(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static InferenceResult
+ inference_task_norm(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ void serialize(Legion::Serializer &s) const override;
+ static PCG::Node deserialize(FFModel &ff,
+ Legion::Deserializer &d,
+ ParallelTensor inputs[],
+ int num_inputs);
+ Op *materialize(FFModel &ff,
+ ParallelTensor inputs[],
+ int num_inputs) const override;
+ bool measure_operator_cost(Simulator *sim,
+ MachineView const &pc,
+ CostMetrics &cost_metrics) const override;
+ template
+ static void forward_kernel(ArgMaxMeta const *m,
+ DT *input_ptr,
+ int *indices_ptr,
+ float *prob_ptr,
+ int *parent_ptr,
+ int length,
+ int batch_size,
+ ffStream_t stream);
+ static void forward_kernel_wrapper(ArgMaxMeta const *m,
+ GenericTensorAccessorW const &input,
+ GenericTensorAccessorW const &indices,
+ GenericTensorAccessorW const &parent,
+ int batch_size);
+ Params get_params() const;
+
+public:
+ bool beam_search;
+};
+
+}; // namespace FlexFlow
+
+#endif
\ No newline at end of file
diff --git a/include/flexflow/ops/argmax_params.h b/include/flexflow/ops/argmax_params.h
new file mode 100644
index 0000000000..a8f629619f
--- /dev/null
+++ b/include/flexflow/ops/argmax_params.h
@@ -0,0 +1,24 @@
+#ifndef _FLEXFLOW_ARGMAX_PARAMS_H
+#define _FLEXFLOW_ARGMAX_PARAMS_H
+
+#include "flexflow/ffconst.h"
+#include "flexflow/parallel_tensor.h"
+
+namespace FlexFlow {
+
+struct ArgMaxParams {
+ bool beam_search;
+ bool is_valid(ParallelTensorShape const &) const;
+};
+bool operator==(ArgMaxParams const &, ArgMaxParams const &);
+
+} // namespace FlexFlow
+
+namespace std {
+template <>
+struct hash {
+ size_t operator()(FlexFlow::ArgMaxParams const &) const;
+};
+} // namespace std
+
+#endif // _FLEXFLOW_ARGMAX_PARAMS_H
\ No newline at end of file
diff --git a/include/flexflow/ops/attention.h b/include/flexflow/ops/attention.h
index 2903497af9..7f52e0dad4 100644
--- a/include/flexflow/ops/attention.h
+++ b/include/flexflow/ops/attention.h
@@ -3,6 +3,7 @@
#include "flexflow/device.h"
#include "flexflow/fftype.h"
+#include "flexflow/inference.h"
#include "flexflow/layer.h"
#include "flexflow/node.h"
#include "flexflow/op_meta.h"
@@ -64,8 +65,17 @@ class MultiHeadAttention : public Op {
Layer const *layer,
std::vector const &inputs);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void print_layer(FFModel const &model) override {
assert(0);
}
diff --git a/include/flexflow/ops/beam_topk.h b/include/flexflow/ops/beam_topk.h
new file mode 100644
index 0000000000..9466ba2a3b
--- /dev/null
+++ b/include/flexflow/ops/beam_topk.h
@@ -0,0 +1,112 @@
+#ifndef _FLEXFLOW_BEAM_TOPK_H_
+#define _FLEXFLOW_BEAM_TOPK_H_
+
+#include "flexflow/inference.h"
+#include "flexflow/model.h"
+#include "flexflow/node.h"
+#include "flexflow/ops/beam_topk_params.h"
+#include "flexflow/utils/memory_allocator.h"
+
+namespace FlexFlow {
+
+class BeamTopKMeta : public OpMeta {
+public:
+ BeamTopKMeta(FFHandler handle,
+ Op const *op,
+ MemoryAllocator &gpu_mem_allocator);
+ ~BeamTopKMeta(void);
+ bool sorted;
+ int max_beam_width;
+ int *parent_ids;
+ void *acc_probs;
+ int *block_start_index;
+ int *request_id;
+ int *tokens_per_request;
+ Realm::RegionInstance reserveInst;
+};
+
+class BeamTopK : public Op {
+public:
+ using Params = BeamTopKParams;
+ using Input = ParallelTensor;
+ BeamTopK(FFModel &model,
+ const ParallelTensor input,
+ LayerID const &_layer_guid,
+ int max_beam_width,
+ bool sorted,
+ char const *name);
+ BeamTopK(FFModel &model, BeamTopK const &other, const ParallelTensor input);
+ BeamTopK(FFModel &model,
+ Params const ¶ms,
+ Input const input,
+ char const *name = nullptr);
+ void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void forward(FFModel const &) override;
+ void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void print_layer(FFModel const &model) override {
+ assert(0);
+ }
+ static Op *
+ create_operator_from_layer(FFModel &model,
+ Layer const *layer,
+ std::vector const &inputs);
+
+ static OpMeta *init_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static BeamInferenceResult
+ inference_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ void serialize(Legion::Serializer &s) const override;
+ static PCG::Node deserialize(FFModel &ff,
+ Legion::Deserializer &d,
+ ParallelTensor inputs[],
+ int num_inputs);
+ Op *materialize(FFModel &ff,
+ ParallelTensor inputs[],
+ int num_inputs) const override;
+ bool measure_operator_cost(Simulator *sim,
+ MachineView const &pc,
+ CostMetrics &cost_metrics) const override;
+ template
+ static void forward_kernel(BeamTopKMeta const *m,
+ BeamSearchBatchConfig const *bc,
+ DT const *input_ptr,
+ float *output_ptr,
+ int *indices_ptr,
+ int *parent_ptr,
+ int batch_size,
+ int length,
+ bool sorted,
+ ffStream_t stream);
+ static void forward_kernel_wrapper(BeamTopKMeta const *m,
+ BeamSearchBatchConfig const *bc,
+ GenericTensorAccessorR const &input,
+ float *output_ptr,
+ int *indices_ptr,
+ int *parent_ptr,
+ int batch_size,
+ int length,
+ bool sorted);
+ Params get_params() const;
+
+public:
+ bool sorted;
+ int max_beam_width;
+};
+
+}; // namespace FlexFlow
+
+#endif
diff --git a/include/flexflow/ops/beam_topk_params.h b/include/flexflow/ops/beam_topk_params.h
new file mode 100644
index 0000000000..c217b0f671
--- /dev/null
+++ b/include/flexflow/ops/beam_topk_params.h
@@ -0,0 +1,26 @@
+#ifndef _FLEXFLOW_BEAM_TOPK_PARAMS_H
+#define _FLEXFLOW_BEAM_TOPK_PARAMS_H
+
+#include "flexflow/ffconst.h"
+#include "flexflow/parallel_tensor.h"
+
+namespace FlexFlow {
+
+struct BeamTopKParams {
+ LayerID layer_guid;
+ bool sorted;
+ int max_beam_width;
+ bool is_valid(ParallelTensorShape const &) const;
+};
+bool operator==(BeamTopKParams const &, BeamTopKParams const &);
+
+} // namespace FlexFlow
+
+namespace std {
+template <>
+struct hash {
+ size_t operator()(FlexFlow::BeamTopKParams const &) const;
+};
+} // namespace std
+
+#endif // _FLEXFLOW_BEAM_TOPK_PARAMS_H
diff --git a/include/flexflow/ops/cast.h b/include/flexflow/ops/cast.h
index 2d69b9469e..a06f87b3c8 100644
--- a/include/flexflow/ops/cast.h
+++ b/include/flexflow/ops/cast.h
@@ -35,8 +35,17 @@ class Cast : public Op {
Input const &input,
char const *name = nullptr);
void init(FFModel const &);
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &);
void backward(FFModel const &);
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void print_layer(FFModel const &model) {
assert(0);
}
diff --git a/include/flexflow/ops/element_binary.h b/include/flexflow/ops/element_binary.h
index cfacec50f7..4aa41ed9e4 100644
--- a/include/flexflow/ops/element_binary.h
+++ b/include/flexflow/ops/element_binary.h
@@ -1,6 +1,7 @@
#ifndef _FLEXFLOW_ELEMENT_BINARY_H
#define _FLEXFLOW_ELEMENT_BINARY_H
+#include "flexflow/inference.h"
#include "flexflow/layer.h"
#include "flexflow/node.h"
#include "flexflow/operator.h"
@@ -14,6 +15,7 @@ class ElementBinary : public Op {
using Input = std::pair;
ElementBinary(FFModel &model,
+ LayerID const &layer_guid,
OperatorType type,
const ParallelTensor x,
const ParallelTensor y,
@@ -22,11 +24,19 @@ class ElementBinary : public Op {
ElementBinary(FFModel &model,
Params const ¶ms,
Input const &inputs,
- char const *name = nullptr,
- bool inplace_a = false);
+ char const *name = nullptr);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void print_layer(FFModel const &model) override {
assert(0);
}
@@ -53,6 +63,12 @@ class ElementBinary : public Op {
bool measure_operator_cost(Simulator *sim,
MachineView const &pc,
CostMetrics &cost_metrics) const override;
+
+ void serialize(Legion::Serializer &) const override;
+ static PCG::Node deserialize(FFModel &ff,
+ Legion::Deserializer &d,
+ ParallelTensor inputs[],
+ int num_inputs);
Params get_params() const;
public:
diff --git a/include/flexflow/ops/element_binary_params.h b/include/flexflow/ops/element_binary_params.h
index 5aa20e25a5..8b26877af2 100644
--- a/include/flexflow/ops/element_binary_params.h
+++ b/include/flexflow/ops/element_binary_params.h
@@ -7,7 +7,9 @@
namespace FlexFlow {
struct ElementBinaryParams {
+ LayerID layer_guid;
OperatorType type;
+ bool inplace_a;
bool is_valid(
std::pair const &) const;
diff --git a/include/flexflow/ops/element_unary.h b/include/flexflow/ops/element_unary.h
index 5291159aac..2df9ea61bc 100644
--- a/include/flexflow/ops/element_unary.h
+++ b/include/flexflow/ops/element_unary.h
@@ -3,6 +3,7 @@
#include "flexflow/device.h"
#include "flexflow/fftype.h"
+#include "flexflow/inference.h"
#include "flexflow/layer.h"
#include "flexflow/node.h"
#include "flexflow/op_meta.h"
@@ -45,8 +46,17 @@ class ElementUnary : public Op {
Input const x,
char const *name = nullptr);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void print_layer(FFModel const &model) override {
assert(0);
}
diff --git a/include/flexflow/ops/embedding.h b/include/flexflow/ops/embedding.h
index 91caf06af0..ae93ef4d1d 100644
--- a/include/flexflow/ops/embedding.h
+++ b/include/flexflow/ops/embedding.h
@@ -49,8 +49,17 @@ class Embedding : public Op {
bool allocate_weights = false,
char const *name = nullptr);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
// void update(const FFModel&);
void print_layer(FFModel const &model) override {
assert(0);
diff --git a/include/flexflow/ops/experts.h b/include/flexflow/ops/experts.h
new file mode 100644
index 0000000000..d68957d890
--- /dev/null
+++ b/include/flexflow/ops/experts.h
@@ -0,0 +1,172 @@
+#pragma once
+
+#include "flexflow/inference.h"
+#include "flexflow/model.h"
+#include "flexflow/ops/experts_params.h"
+
+namespace FlexFlow {
+
+class ExpertsMeta : public OpMeta {
+public:
+ ExpertsMeta(FFHandler handler,
+ int _num_experts,
+ int _experts_start_idx,
+ int _data_dim,
+ int _out_dim,
+ int _experts_num_layers,
+ int _experts_internal_dim_size,
+ int _effective_batch_size,
+ int _num_chosen_experts,
+ float _alpha,
+ bool _use_bias,
+ ActiMode _activation);
+ ~ExpertsMeta(void);
+
+ // Thrust helper arrays
+ int *sorted_indices;
+ int *original_indices;
+ int *non_zero_expert_labels;
+ int *temp_sequence;
+ int *exp_local_label_to_index;
+ int *expert_start_indexes;
+ int *num_assignments_per_expert; // numbers of tokes assigned to each expert.
+ // Values may exceed the expert capacity
+ int *capped_num_assignments_per_expert;
+ int *destination_start_indices;
+ float const **token_idx_array;
+ float const **dev_weights;
+ float const **weight_idx_array1;
+ float const **weight_idx_array2;
+ float const **coefficient_idx_array;
+ float **output_idx_array;
+ float const **bias_idx_array1;
+ float const **bias_idx_array2;
+ float const *one_ptr;
+ float const **one_ptr_array;
+
+ // array of arrays to store cublasGemmBatchedEx outputs before aggregation
+ float **batch_outputs1;
+ float **batch_outputs2;
+ float **dev_batch_outputs1;
+ float **dev_batch_outputs2;
+
+ int num_experts;
+ int experts_start_idx;
+ int data_dim;
+ int out_dim;
+ int experts_num_layers;
+ int experts_internal_dim_size;
+ int effective_batch_size;
+ int num_chosen_experts;
+ int expert_capacity;
+ float alpha;
+ bool use_bias;
+ ActiMode activation;
+#if defined(FF_USE_CUDA) || defined(FF_USE_HIP_CUDA)
+ cudnnActivationDescriptor_t actiDesc;
+ cudnnTensorDescriptor_t resultTensorDesc1;
+ cudnnTensorDescriptor_t resultTensorDesc2;
+#else
+ miopenActivationDescriptor_t actiDesc;
+ miopenTensorDescriptor_t resultTensorDesc1;
+ miopenTensorDescriptor_t resultTensorDesc2;
+#endif
+};
+
+// definitions for the CUDA kernel
+#define MAX_BATCH_SIZE 1024 * 2 // 32 * 10
+#define MAX_EXPERTS_PER_BLOCK 32
+
+class Experts : public Op {
+public:
+ using Params = ExpertsParams;
+ using Input = std::vector;
+ Experts(FFModel &model,
+ Params const ¶ms,
+ Input const &inputs,
+ bool allocate_weights = false,
+ char const *name = nullptr);
+ Experts(FFModel &model,
+ LayerID const &layer_guid,
+ ParallelTensor const *inputs,
+ int _num_experts,
+ int _experts_start_idx,
+ int _experts_output_dim_size,
+ float _alpha,
+ int _experts_num_layers,
+ int _experts_internal_dim_size,
+ bool _use_bias,
+ ActiMode _activation,
+ bool allocate_weights,
+ char const *name = nullptr);
+ static Op *
+ create_operator_from_layer(FFModel &model,
+ Layer const *layer,
+ std::vector const &inputs);
+
+ void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void forward(FFModel const &) override;
+ void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void print_layer(FFModel const &model) override;
+ void serialize(Legion::Serializer &) const override;
+ static PCG::Node deserialize(FFModel &ff,
+ Legion::Deserializer &d,
+ Input const &inputs,
+ int num_inputs);
+ Params get_params() const;
+ static OpMeta *init_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static void forward_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static void forward_kernel_wrapper(ExpertsMeta const *m,
+ float const *input,
+ int const *indices,
+ float const *topk_gate_preds,
+ float *output,
+ float const *weights,
+ float const *biases,
+ int num_active_tokens,
+ int chosen_experts,
+ int batch_size,
+ int out_dim);
+ static void backward_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static void inference_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ bool measure_operator_cost(Simulator *sim,
+ MachineView const &pc,
+ CostMetrics &cost_metrics) const override;
+
+public:
+ int num_experts;
+ int experts_start_idx;
+ int experts_output_dim_size;
+ int data_dim;
+ int out_dim;
+ int effective_batch_size;
+ int num_chosen_experts;
+ float alpha;
+ int experts_num_layers;
+ int experts_internal_dim_size;
+ bool use_bias;
+ ActiMode activation;
+};
+
+}; // namespace FlexFlow
diff --git a/include/flexflow/ops/experts_params.h b/include/flexflow/ops/experts_params.h
new file mode 100644
index 0000000000..b6ba88a96e
--- /dev/null
+++ b/include/flexflow/ops/experts_params.h
@@ -0,0 +1,31 @@
+#pragma once
+
+#include "flexflow/operator.h"
+#include "flexflow/parallel_tensor.h"
+
+namespace FlexFlow {
+
+struct ExpertsParams {
+ LayerID layer_guid;
+ int num_experts;
+ int experts_start_idx;
+ int experts_output_dim_size;
+ float alpha;
+ int experts_num_layers;
+ int experts_internal_dim_size;
+ bool use_bias;
+ ActiMode activation;
+
+ bool is_valid(std::vector const &) const;
+};
+
+bool operator==(ExpertsParams const &, ExpertsParams const &);
+
+} // namespace FlexFlow
+
+namespace std {
+template <>
+struct hash {
+ size_t operator()(FlexFlow::ExpertsParams const &) const;
+};
+} // namespace std
diff --git a/include/flexflow/ops/fused.h b/include/flexflow/ops/fused.h
index 87d35da902..87c2201c28 100644
--- a/include/flexflow/ops/fused.h
+++ b/include/flexflow/ops/fused.h
@@ -29,8 +29,17 @@ class FusedOp : public Op {
return ParallelTensor();
}
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void print_layer(FFModel const &model) override {
assert(0);
}
@@ -38,6 +47,10 @@ class FusedOp : public Op {
std::vector const ®ions,
Legion::Context ctx,
Legion::Runtime *runtime);
+ static void inference_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
static void forward_task(Legion::Task const *task,
std::vector const ®ions,
Legion::Context ctx,
diff --git a/include/flexflow/ops/groupby.h b/include/flexflow/ops/groupby.h
index 4a15f6f439..ec6cdfb9ab 100644
--- a/include/flexflow/ops/groupby.h
+++ b/include/flexflow/ops/groupby.h
@@ -1,6 +1,7 @@
#ifndef _FLEXFLOW_GROUPBY_H_
#define _FLEXFLOW_GROUPBY_H_
+#include "flexflow/inference.h"
#include "flexflow/model.h"
#include "flexflow/node.h"
#include "flexflow/ops/groupby_params.h"
@@ -9,8 +10,9 @@ namespace FlexFlow {
class GroupByMeta : public OpMeta {
public:
- GroupByMeta(FFHandler handle, int n);
+ GroupByMeta(FFHandler handle, int n, float _alpha);
~GroupByMeta(void);
+ float alpha;
float **dev_region_ptrs;
};
@@ -33,8 +35,17 @@ class Group_by : public Op {
Input const &inputs,
char const *name = nullptr);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void print_layer(FFModel const &model) override {
assert(0);
}
@@ -62,26 +73,22 @@ class Group_by : public Op {
Op *materialize(FFModel &ff,
ParallelTensor inputs[],
int num_inputs) const override;
- static void
- forward_kernel_wrapper(GroupByMeta const *m,
- float const *input,
- int const *exp_assign,
- float **outputs,
- int n, // num experts
- int k, // chosen experts
- float alpha, // factor additional memory assigned
- int batch_size,
- int data_dim);
- static void
- backward_kernel_wrapper(GroupByMeta const *m,
- float *input_grad,
- int const *exp_assign,
- float **output_grads,
- int n, // num experts
- int k, // chosen experts
- float alpha, // factor additional memory assigned
- int batch_size,
- int data_dim);
+ static void forward_kernel_wrapper(GroupByMeta const *m,
+ float const *input,
+ int const *exp_assign,
+ float **outputs,
+ int n, // num experts
+ int k, // chosen experts
+ int batch_size,
+ int data_dim);
+ static void backward_kernel_wrapper(GroupByMeta const *m,
+ float *input_grad,
+ int const *exp_assign,
+ float **output_grads,
+ int n, // num experts
+ int k, // chosen experts
+ int batch_size,
+ int data_dim);
bool measure_operator_cost(Simulator *sim,
MachineView const &pc,
CostMetrics &cost_metrics) const override;
diff --git a/include/flexflow/ops/inc_multihead_self_attention.h b/include/flexflow/ops/inc_multihead_self_attention.h
new file mode 100644
index 0000000000..91621074b3
--- /dev/null
+++ b/include/flexflow/ops/inc_multihead_self_attention.h
@@ -0,0 +1,199 @@
+#ifndef _FLEXFLOW_INC_MULTIHEAD_SELF_ATTENTION_H
+#define _FLEXFLOW_INC_MULTIHEAD_SELF_ATTENTION_H
+
+#include "flexflow/accessor.h"
+#include "flexflow/device.h"
+#include "flexflow/fftype.h"
+#include "flexflow/inference.h"
+#include "flexflow/layer.h"
+#include "flexflow/node.h"
+#include "flexflow/op_meta.h"
+#include "flexflow/operator.h"
+#include "flexflow/ops/inc_multihead_self_attention_params.h"
+#include "flexflow/utils/memory_allocator.h"
+#include "math.h"
+#include
+#include
+
+namespace FlexFlow {
+
+class IncMultiHeadSelfAttentionMeta;
+
+class IncMultiHeadSelfAttention : public Op {
+public:
+ using Params = IncMultiHeadSelfAttentionParams;
+ using Input = ParallelTensor;
+
+ IncMultiHeadSelfAttention(FFModel &model,
+ LayerID const &layer_guid,
+ const ParallelTensor _input,
+ int _embed_dim,
+ int _num_q_heads,
+ int _num_kv_heads,
+ int _kdim,
+ int _vdim,
+ float _dropout,
+ bool _bias,
+ bool _add_bias_kv,
+ bool _add_zero_attn,
+ bool _apply_rotary_embedding,
+ bool _scaling_query,
+ float _scaling_factor,
+ bool _qk_prod_scaling,
+ bool allocate_weights,
+ DataType _quantization_type,
+ bool _offload,
+ int _tensor_parallelism_degree,
+ char const *name);
+ IncMultiHeadSelfAttention(FFModel &model,
+ const ParallelTensor _input,
+ const ParallelTensor _weight,
+ int _embed_dim,
+ int _num_q_heads,
+ int _num_kv_heads,
+ int _kdim,
+ int _vdim,
+ float _dropout,
+ bool _bias,
+ bool _add_bias_kv,
+ bool _add_zero_attn,
+ bool _apply_rotary_embedding,
+ bool _scaling_query,
+ float _scaling_factor,
+ bool _qk_prod_scaling,
+ bool allocate_weights,
+ DataType _quantization_type,
+ bool _offload,
+ int _tensor_parallelism_degree,
+ char const *name);
+ IncMultiHeadSelfAttention(FFModel &model,
+ IncMultiHeadSelfAttention const &other,
+ const ParallelTensor input,
+ bool allocate_weights);
+ IncMultiHeadSelfAttention(FFModel &model,
+ Params const ¶ms,
+ Input const &inputs,
+ bool allocate_weights = false,
+ char const *name = nullptr);
+ static Op *
+ create_operator_from_layer(FFModel &model,
+ Layer const *layer,
+ std::vector const &inputs);
+ void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void forward(FFModel const &) override;
+ void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void print_layer(FFModel const &model) override {
+ assert(0);
+ }
+ bool get_int_parameter(PMParameter, int *) const override;
+
+ static OpMeta *init_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static void inference_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ bool measure_operator_cost(Simulator *sim,
+ MachineView const &mv,
+ CostMetrics &cost_metrics) const override;
+
+ static void inference_kernel_wrapper(IncMultiHeadSelfAttentionMeta const *m,
+ BatchConfig const *bc,
+ int shard_id,
+ GenericTensorAccessorR const &input,
+ GenericTensorAccessorR const &weight,
+ GenericTensorAccessorW const &output,
+ GenericTensorAccessorR const &bias);
+ Params get_params() const;
+
+public:
+ int num_q_heads, num_kv_heads, tensor_parallelism_degree;
+ float dropout, scaling_factor;
+ bool bias;
+ bool add_bias_kv, add_zero_attn, apply_rotary_embedding, scaling_query,
+ qk_prod_scaling;
+ int qSize, kSize, vSize, qProjSize, kProjSize, vProjSize, oProjSize;
+ int qoSeqLength, kvSeqLength;
+ DataType quantization_type;
+ bool offload;
+};
+
+class IncMultiHeadSelfAttentionMeta : public OpMeta {
+public:
+ IncMultiHeadSelfAttentionMeta(FFHandler handler,
+ IncMultiHeadSelfAttention const *attn,
+ GenericTensorAccessorR const &weight,
+ MemoryAllocator &gpu_mem_allocator,
+ int num_samples,
+ int _num_q_heads,
+ int _num_kv_heads);
+ IncMultiHeadSelfAttentionMeta(FFHandler handler,
+ InferenceMode infer_mode,
+ Op const *attn,
+ int _qSize,
+ int _kSize,
+ int _vSize,
+ int _qProjSize,
+ int _kProjSize,
+ int _vProjSize,
+ int _oProjSize,
+ bool _apply_rotary_embedding,
+ bool _bias,
+ bool _scaling_query,
+ bool _qk_prod_scaling,
+ bool _add_bias_kv,
+ float _scaling_factor,
+ GenericTensorAccessorR const &weight,
+ MemoryAllocator &gpu_mem_allocator,
+ int num_samples,
+ int _global_num_q_heads,
+ int _global_num_kv_heads,
+ int _num_q_heads,
+ int _num_kv_heads,
+ DataType _quantization_type,
+ bool _offload);
+ ~IncMultiHeadSelfAttentionMeta(void);
+
+public:
+ Realm::RegionInstance reserveInst;
+ size_t weights_params, weightSize, biasSize, reserveSpaceSize,
+ quantized_weightSize;
+ int qSize, kSize, vSize, qProjSize, kProjSize, vProjSize, oProjSize;
+ int global_num_q_heads, global_num_kv_heads, num_q_heads, num_kv_heads;
+ bool *has_load_weights;
+ bool *apply_rotary_embedding;
+ bool *bias;
+ bool *scaling_query;
+ bool *qk_prod_scaling;
+ float scaling_factor;
+#ifdef INFERENCE_TESTS
+ float *kcache, *vcache;
+#endif
+ void *weight_ptr, *bias_ptr; // for weight offload
+ void *devQKVProjArray, *keyCache, *valueCache;
+ void *qk_prods, *qk_prods_softmax;
+ void *attn_heads, *W_out_contiguous;
+ char *quantized_weight_ptr;
+ BatchConfig::PerTokenInfo *token_infos;
+ DataType quantization_type;
+ bool offload;
+#if defined(FF_USE_CUDA) || defined(FF_USE_HIP_CUDA)
+ cudnnTensorDescriptor_t qk_tensor;
+ cuFloatComplex *complex_input;
+#endif
+};
+
+}; // namespace FlexFlow
+
+#endif // _FLEXFLOW_ATTENTION_H
diff --git a/include/flexflow/ops/inc_multihead_self_attention_params.h b/include/flexflow/ops/inc_multihead_self_attention_params.h
new file mode 100644
index 0000000000..be38b9ab1b
--- /dev/null
+++ b/include/flexflow/ops/inc_multihead_self_attention_params.h
@@ -0,0 +1,33 @@
+#ifndef _FLEXFLOW_INC_MULTIHEAD_SELF_ATTENTION_PARAMS_H
+#define _FLEXFLOW_INC_MULTIHEAD_SELF_ATTENTION_PARAMS_H
+
+#include "flexflow/fftype.h"
+#include "flexflow/parallel_tensor.h"
+
+namespace FlexFlow {
+
+struct IncMultiHeadSelfAttentionParams {
+ LayerID layer_guid;
+ int embed_dim, num_q_heads, kdim, vdim, num_kv_heads,
+ tensor_parallelism_degree;
+ float dropout, scaling_factor;
+ bool bias, add_bias_kv, add_zero_attn, apply_rotary_embedding, scaling_query,
+ qk_prod_scaling;
+ DataType quantization_type;
+ bool offload;
+ bool is_valid(ParallelTensorShape const &) const;
+};
+
+bool operator==(IncMultiHeadSelfAttentionParams const &,
+ IncMultiHeadSelfAttentionParams const &);
+
+} // namespace FlexFlow
+
+namespace std {
+template <>
+struct hash {
+ size_t operator()(FlexFlow::IncMultiHeadSelfAttentionParams const &) const;
+};
+} // namespace std
+
+#endif // _FLEXFLOW_INC_MULTIHEAD_SELF_ATTENTION_PARAMS_H
diff --git a/include/flexflow/ops/kernels/decompress_kernels.h b/include/flexflow/ops/kernels/decompress_kernels.h
new file mode 100644
index 0000000000..7cfedd6265
--- /dev/null
+++ b/include/flexflow/ops/kernels/decompress_kernels.h
@@ -0,0 +1,43 @@
+#ifndef _FLEXFLOW_DECOMPRESS_KERNELS_H
+#define _FLEXFLOW_DECOMPRESS_KERNELS_H
+
+#include "flexflow/device.h"
+
+namespace FlexFlow {
+namespace Kernels {
+
+template
+__global__ void decompress_int4_general_weights(char const *input_weight_ptr,
+ DT *weight_ptr,
+ int in_dim,
+ int valueSize);
+template
+__global__ void decompress_int8_general_weights(char const *input_weight_ptr,
+ DT *weight_ptr,
+ int in_dim,
+ int valueSize);
+
+template
+__global__ void decompress_int4_attention_weights(char *input_weight_ptr,
+ DT *weight_ptr,
+ int qProjSize,
+ int qSize,
+ int num_heads);
+
+template
+__global__ void decompress_int8_attention_weights(char *input_weight_ptr,
+ DT *weight_ptr,
+ int qProjSize,
+ int qSize,
+ int num_heads);
+// template
+// void decompress_weight_bias(T1 *input_weight_ptr,
+// T2 *weight_ptr,
+// T2 *params,
+// int group_size,
+// int tensor_size);
+
+} // namespace Kernels
+} // namespace FlexFlow
+
+#endif // _FLEXFLOW_DECOMPRESS_KERNELS_H
diff --git a/include/flexflow/ops/kernels/element_binary_kernels.h b/include/flexflow/ops/kernels/element_binary_kernels.h
index 529859195e..b0c596301b 100644
--- a/include/flexflow/ops/kernels/element_binary_kernels.h
+++ b/include/flexflow/ops/kernels/element_binary_kernels.h
@@ -1,6 +1,7 @@
#ifndef _FLEXFLOW_OPS_KERNELS_ELEMENT_BINARY_KERNELS_H
#define _FLEXFLOW_OPS_KERNELS_ELEMENT_BINARY_KERNELS_H
+#include "flexflow/accessor.h"
#include "flexflow/device.h"
#include "flexflow/fftype.h"
#include "flexflow/op_meta.h"
@@ -9,7 +10,7 @@ namespace FlexFlow {
class ElementBinaryMeta : public OpMeta {
public:
- ElementBinaryMeta(FFHandler handle);
+ ElementBinaryMeta(FFHandler handle, Op const *op);
#if defined(FF_USE_CUDA) || defined(FF_USE_HIP_CUDA)
cudnnTensorDescriptor_t input1Tensor, input2Tensor, outputTensor;
cudnnOpTensorDescriptor_t opDesc;
@@ -34,9 +35,9 @@ void init_kernel(ElementBinaryMeta *m,
Legion::Domain const &output_domain);
void forward_kernel_wrapper(ElementBinaryMeta const *m,
- float const *in1_ptr,
- float const *in2_ptr,
- float *out_ptr);
+ GenericTensorAccessorR const &in1,
+ GenericTensorAccessorR const &in2,
+ GenericTensorAccessorW const &out);
void backward_kernel_wrapper(ElementBinaryMeta const *m,
float const *out_grad_ptr,
@@ -47,10 +48,11 @@ void backward_kernel_wrapper(ElementBinaryMeta const *m,
namespace Internal {
+template
void forward_kernel(ElementBinaryMeta const *m,
- float const *in1_ptr,
- float const *in2_ptr,
- float *out_ptr,
+ DT const *in1_ptr,
+ DT const *in2_ptr,
+ DT *out_ptr,
ffStream_t stream);
void backward_kernel(ElementBinaryMeta const *m,
float const *out_grad_ptr,
@@ -65,4 +67,4 @@ void backward_kernel(ElementBinaryMeta const *m,
} // namespace Kernels
} // namespace FlexFlow
-#endif // _FLEXFLOW_OPS_KERNELS_ELEMENT_BINARY_KERNELS_H
\ No newline at end of file
+#endif // _FLEXFLOW_OPS_KERNELS_ELEMENT_BINARY_KERNELS_H
diff --git a/include/flexflow/ops/kernels/inc_multihead_self_attention_kernels.h b/include/flexflow/ops/kernels/inc_multihead_self_attention_kernels.h
new file mode 100644
index 0000000000..6b294bc211
--- /dev/null
+++ b/include/flexflow/ops/kernels/inc_multihead_self_attention_kernels.h
@@ -0,0 +1,68 @@
+#ifndef _FLEXFLOW_OPS_KERNELS_INC_MULTIHEAD_SELF_ATTENTION_KERNELS_H
+#define _FLEXFLOW_OPS_KERNELS_INC_MULTIHEAD_SELF_ATTENTION_KERNELS_H
+
+#include "flexflow/batch_config.h"
+#include "flexflow/device.h"
+#include "flexflow/fftype.h"
+#include "flexflow/op_meta.h"
+#include "flexflow/ops/inc_multihead_self_attention.h"
+
+namespace FlexFlow {
+namespace Kernels {
+namespace IncMultiHeadAttention {
+
+template
+__global__ void apply_proj_bias_w(DT *input_ptr,
+ DT const *bias_ptr,
+ int num_tokens,
+ int qkv_weight_size,
+ int oProjSize);
+
+template
+__global__ void apply_proj_bias_qkv(DT *input_ptr,
+ DT const *bias_ptr,
+ int shard_id,
+ int num_tokens,
+ int qProjSize,
+ int kProjSize,
+ int vProjSize,
+ int num_heads,
+ int num_kv_heads,
+ bool scaling_query,
+ float scaling_factor);
+
+template
+__global__ void
+ apply_rotary_embedding(DT *input_ptr,
+ cuFloatComplex *complex_input,
+ BatchConfig::PerTokenInfo const *tokenInfos,
+ int qProjSize,
+ int kProjSize,
+ int num_heads,
+ int num_tokens,
+ int num_kv_heads,
+ int q_block_size,
+ int k_block_size,
+ int q_array_size,
+ bool q_tensor);
+
+template
+void compute_qkv_kernel(IncMultiHeadSelfAttentionMeta const *m,
+ BatchConfig const *bc,
+ int shard_id,
+ DT const *input_ptr,
+ DT const *weight_ptr,
+ DT *output_ptr,
+ DT const *bias_ptr,
+ cudaStream_t stream);
+
+template
+void pre_build_weight_kernel(IncMultiHeadSelfAttentionMeta const *m,
+ GenericTensorAccessorR const weight,
+ DataType data_type,
+ cudaStream_t stream);
+} // namespace IncMultiHeadAttention
+} // namespace Kernels
+} // namespace FlexFlow
+
+#endif // _FLEXFLOW_OPS_KERNELS_INC_MULTIHEAD_SELF_ATTENTION_KERNELS_H
diff --git a/include/flexflow/ops/kernels/linear_kernels.h b/include/flexflow/ops/kernels/linear_kernels.h
index 6ca9fb89ac..bbebe3c79b 100644
--- a/include/flexflow/ops/kernels/linear_kernels.h
+++ b/include/flexflow/ops/kernels/linear_kernels.h
@@ -4,12 +4,18 @@
#include "flexflow/device.h"
#include "flexflow/fftype.h"
#include "flexflow/op_meta.h"
+#include "flexflow/ops/linear.h"
namespace FlexFlow {
class LinearMeta : public OpMeta {
public:
- LinearMeta(FFHandler handle, int batch_size);
+ LinearMeta(FFHandler handle,
+ int batch_size,
+ Linear const *li,
+ MemoryAllocator gpu_mem_allocator,
+ int weightSize);
+ ~LinearMeta(void);
#if defined(FF_USE_CUDA) || defined(FF_USE_HIP_CUDA)
cudnnTensorDescriptor_t outputTensor;
cudnnActivationDescriptor_t actiDesc;
@@ -17,13 +23,19 @@ class LinearMeta : public OpMeta {
miopenTensorDescriptor_t outputTensor;
miopenActivationDescriptor_t actiDesc;
#endif
- float const *one_ptr;
+ void *one_ptr;
+ void *weight_ptr;
+ DataType weight_ptr_type;
+ DataType quantization_type;
+ bool offload;
+ char *quantized_weight_ptr;
+ size_t quantized_weightSize;
ActiMode activation;
RegularizerMode kernel_reg_type;
float kernel_reg_lambda;
- bool use_bias;
- DataType input_type, weight_type, output_type;
+ bool use_bias, add_bias_only_once;
char op_name[MAX_OPNAME];
+ Realm::RegionInstance reserveInst;
};
namespace Kernels {
@@ -51,6 +63,7 @@ void backward_kernel_wrapper(LinearMeta const *m,
bool use_activation(ActiMode mode);
namespace Internal {
+template
void forward_kernel(LinearMeta const *m,
void const *input_ptr,
void *output_ptr,
@@ -60,6 +73,7 @@ void forward_kernel(LinearMeta const *m,
int out_dim,
int batch_size,
ffStream_t stream);
+template
void backward_kernel(LinearMeta const *m,
void const *input_ptr,
void *input_grad_ptr,
@@ -72,6 +86,8 @@ void backward_kernel(LinearMeta const *m,
int out_dim,
int batch_size,
ffStream_t stream);
+template
+__global__ void build_one_ptr(DT *one_ptr, int batch_size);
} // namespace Internal
} // namespace Linear
} // namespace Kernels
diff --git a/include/flexflow/ops/kernels/rms_norm_kernels.h b/include/flexflow/ops/kernels/rms_norm_kernels.h
new file mode 100644
index 0000000000..2063777ef1
--- /dev/null
+++ b/include/flexflow/ops/kernels/rms_norm_kernels.h
@@ -0,0 +1,54 @@
+#ifndef _FLEXFLOW_OPS_KERNELS_RMSNORM_KERNELS_H
+#define _FLEXFLOW_OPS_KERNELS_RMSNORM_KERNELS_H
+
+#include "flexflow/accessor.h"
+#include "flexflow/device.h"
+#include "flexflow/fftype.h"
+#include "flexflow/op_meta.h"
+#include "flexflow/utils/memory_allocator.h"
+
+namespace FlexFlow {
+using Legion::coord_t;
+
+class RMSNorm;
+
+class RMSNormMeta : public OpMeta {
+public:
+ RMSNormMeta(FFHandler handler,
+ RMSNorm const *rms,
+ MemoryAllocator &gpu_mem_allocator);
+ ~RMSNormMeta(void);
+#if defined(FF_USE_CUDA) || defined(FF_USE_HIP_CUDA)
+ cudnnTensorDescriptor_t inputTensor, outputTensor;
+ cudnnReduceTensorDescriptor_t reduceDesc;
+#else
+ miopenTensorDescriptor_t inputTensor, outputTensor;
+ miopenReduceTensorDescriptor_t reduceDesc;
+#endif
+
+public:
+ float eps;
+ void *rms_ptr;
+ void *norm_ptr;
+
+ float alpha;
+ float beta;
+
+ int in_dim;
+ int batch_size;
+ int num_elements;
+ char op_name[MAX_OPNAME];
+ Realm::RegionInstance reserveInst;
+};
+
+namespace Kernels {
+namespace RMSNorm {
+void forward_kernel_wrapper(RMSNormMeta const *m,
+ GenericTensorAccessorR const &input,
+ GenericTensorAccessorR const &weight,
+ GenericTensorAccessorW const &output);
+} // namespace RMSNorm
+} // namespace Kernels
+} // namespace FlexFlow
+
+#endif // _FLEXFLOW_OPS_KERNELS_RMSNORM_KERNELS_H
diff --git a/include/flexflow/ops/kernels/softmax_kernels.h b/include/flexflow/ops/kernels/softmax_kernels.h
index 81b34d8558..14c07414e9 100644
--- a/include/flexflow/ops/kernels/softmax_kernels.h
+++ b/include/flexflow/ops/kernels/softmax_kernels.h
@@ -21,27 +21,31 @@ class SoftmaxMeta : public OpMeta {
bool profiling;
int dim;
char op_name[MAX_OPNAME];
+ DataType input_type, output_type;
};
namespace Kernels {
namespace Softmax {
-
+template
void forward_kernel_wrapper(SoftmaxMeta const *m,
- float const *input_ptr,
- float *output_ptr);
-
+ DT const *input_ptr,
+ DT *output_ptr);
+template
void backward_kernel_wrapper(SoftmaxMeta const *m,
- float *input_grad_ptr,
- float const *output_grad_ptr,
+ DT *input_grad_ptr,
+ DT const *output_grad_ptr,
size_t num_elements);
namespace Internal {
+template
void forward_kernel(SoftmaxMeta const *m,
- float const *input_ptr,
- float *output_ptr,
+ DT const *input_ptr,
+ DT *output_ptr,
ffStream_t stream);
-void backward_kernel(float *input_grad_ptr,
- float const *output_grad_ptr,
+
+template
+void backward_kernel(DT *input_grad_ptr,
+ DT const *output_grad_ptr,
size_t num_elements,
ffStream_t stream);
} // namespace Internal
diff --git a/include/flexflow/ops/layer_norm.h b/include/flexflow/ops/layer_norm.h
index 8273b9ab52..cb977fc6a6 100644
--- a/include/flexflow/ops/layer_norm.h
+++ b/include/flexflow/ops/layer_norm.h
@@ -1,7 +1,8 @@
#pragma once
+#include "flexflow/inference.h"
#include "flexflow/model.h"
-
+#include "flexflow/utils/memory_allocator.h"
namespace FlexFlow {
class LayerNormMeta;
@@ -24,8 +25,17 @@ class LayerNorm : public Op {
bool allocate_weights,
char const *name);
void init(FFModel const &);
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &);
void backward(FFModel const &);
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void print_layer(FFModel const &model) {
assert(0);
}
@@ -63,15 +73,14 @@ class LayerNorm : public Op {
static void forward_kernel(LayerNormMeta const *m,
T const *input_ptr,
T *output_ptr,
- T *gamma_ptr,
- T *beta_ptr,
+ T const *gamma_ptr,
+ T const *beta_ptr,
ffStream_t stream);
- template
static void forward_kernel_wrapper(LayerNormMeta const *m,
- T const *input_ptr,
- T *output_ptr,
- T *gamma_ptr,
- T *beta_ptr);
+ GenericTensorAccessorR const &input,
+ GenericTensorAccessorW &output,
+ GenericTensorAccessorR const &gamma,
+ GenericTensorAccessorR const &beta);
template
static void backward_kernel(LayerNormMeta const *m,
T const *output_grad_ptr,
@@ -99,14 +108,18 @@ class LayerNorm : public Op {
class LayerNormMeta : public OpMeta {
public:
- LayerNormMeta(FFHandler handle, LayerNorm const *ln);
+ LayerNormMeta(FFHandler handle,
+ LayerNorm const *ln,
+ MemoryAllocator &gpu_mem_allocator);
+ ~LayerNormMeta(void);
public:
bool elementwise_affine;
int64_t effective_batch_size, effective_num_elements;
float eps;
- float *mean_ptr, *rstd_ptr, *ds_ptr, *db_ptr, *scale_ptr, *bias_ptr;
+ void *mean_ptr, *rstd_ptr, *ds_ptr, *db_ptr, *scale_ptr, *bias_ptr;
char op_name[MAX_OPNAME];
+ Realm::RegionInstance reserveInst;
};
}; // namespace FlexFlow
diff --git a/include/flexflow/ops/linear.h b/include/flexflow/ops/linear.h
index 286bcdf717..025674c7ba 100644
--- a/include/flexflow/ops/linear.h
+++ b/include/flexflow/ops/linear.h
@@ -1,9 +1,11 @@
#ifndef _FLEXFLOW_LINEAR_H
#define _FLEXFLOW_LINEAR_H
+#include "flexflow/inference.h"
#include "flexflow/node.h"
#include "flexflow/operator.h"
#include "flexflow/ops/linear_params.h"
+#include "flexflow/utils/memory_allocator.h"
namespace FlexFlow {
@@ -24,6 +26,8 @@ class Linear : public Op {
float kernel_reg_lambda,
bool _use_bias,
DataType _data_type,
+ DataType _quantization_type,
+ bool offload,
bool allocate_weights,
char const *name);
Linear(FFModel &model,
@@ -37,8 +41,17 @@ class Linear : public Op {
bool allocate_weights = false);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void print_layer(FFModel const &model) override;
bool get_int_parameter(PMParameter, int *) const override;
static Op *
@@ -49,6 +62,10 @@ class Linear : public Op {
std::vector const ®ions,
Legion::Context ctx,
Legion::Runtime *runtime);
+ static void inference_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
static void forward_task(Legion::Task const *task,
std::vector const ®ions,
Legion::Context ctx,
@@ -86,19 +103,19 @@ class Linear : public Op {
bool allocate_weights,
char const *name);
- template
+ template
static OpMeta *
init_task_with_dim(Legion::Task const *task,
std::vector const ®ions,
Legion::Context ctx,
Legion::Runtime *runtime);
- template
+ template
static void
forward_task_with_dim(Legion::Task const *task,
std::vector const ®ions,
Legion::Context ctx,
Legion::Runtime *runtime);
- template
+ template
static void
backward_task_with_dim(Legion::Task const *task,
std::vector const ®ions,
@@ -116,6 +133,8 @@ class Linear : public Op {
float kernel_reg_lambda;
bool use_bias;
ParallelTensor replica;
+ DataType quantization_type;
+ bool offload;
};
}; // namespace FlexFlow
diff --git a/include/flexflow/ops/linear_params.h b/include/flexflow/ops/linear_params.h
index 2c41694960..563304e89f 100644
--- a/include/flexflow/ops/linear_params.h
+++ b/include/flexflow/ops/linear_params.h
@@ -18,6 +18,8 @@ class LinearParams {
ActiMode activation;
RegularizerMode kernel_reg_type;
float kernel_reg_lambda;
+ DataType quantization_type;
+ bool offload;
bool is_valid(ParallelTensorShape const &input_shape) const;
void solve_dims(const ParallelTensor input,
diff --git a/include/flexflow/ops/noop.h b/include/flexflow/ops/noop.h
index 5f39c999e6..e07d10a05e 100644
--- a/include/flexflow/ops/noop.h
+++ b/include/flexflow/ops/noop.h
@@ -1,6 +1,7 @@
#ifndef _FLEXFLOW_NOOP_H
#define _FLEXFLOW_NOOP_H
+#include "flexflow/inference.h"
#include "flexflow/model.h"
namespace FlexFlow {
@@ -17,7 +18,16 @@ class NoOp : public Op {
const ParallelTensor output,
char const *name = NULL);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void forward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
void backward(FFModel const &) override;
void print_layer(FFModel const &model) override {
assert(0);
diff --git a/include/flexflow/ops/rms_norm.h b/include/flexflow/ops/rms_norm.h
new file mode 100644
index 0000000000..979a20976c
--- /dev/null
+++ b/include/flexflow/ops/rms_norm.h
@@ -0,0 +1,83 @@
+#ifndef _FLEXFLOW_RMS_NORM_H
+#define _FLEXFLOW_RMS_NORM_H
+
+#include "flexflow/inference.h"
+#include "flexflow/model.h"
+#include "flexflow/ops/rms_norm_params.h"
+#include "flexflow/utils/memory_allocator.h"
+
+namespace FlexFlow {
+
+class RMSNormMeta;
+
+class RMSNorm : public Op {
+public:
+ using Params = RMSNormParams;
+ using Input = ParallelTensor;
+ RMSNorm(FFModel &model,
+ LayerID const &_layer_guid,
+ const ParallelTensor _input,
+ float _eps,
+ int dim,
+ bool allocate_weights,
+ char const *name);
+ RMSNorm(FFModel &model,
+ RMSNormParams const ¶ms,
+ ParallelTensor input,
+ bool allocate_weights,
+ char const *name = nullptr);
+
+ RMSNorm(FFModel &model,
+ RMSNorm const &other,
+ const ParallelTensor input,
+ bool allocate_weights);
+ void init(FFModel const &);
+ void forward(FFModel const &);
+ void backward(FFModel const &);
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void print_layer(FFModel const &model) {
+ assert(0);
+ }
+
+ static Op *
+ create_operator_from_layer(FFModel &model,
+ Layer const *layer,
+ std::vector const &inputs);
+ void serialize(Legion::Serializer &) const override;
+ static PCG::Node deserialize(FFModel &ff,
+ Legion::Deserializer &d,
+ ParallelTensor inputs[],
+ int num_inputs);
+ Op *materialize(FFModel &ff,
+ ParallelTensor inputs[],
+ int num_inputs) const override;
+ RMSNormParams get_params() const;
+
+ static OpMeta *init_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static void forward_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ bool measure_operator_cost(Simulator *sim,
+ MachineView const &pc,
+ CostMetrics &cost_metrics) const;
+
+public:
+ float eps;
+ char op_name[MAX_OPNAME];
+ int effective_batch_size;
+ int dim, data_dim;
+};
+} // namespace FlexFlow
+#endif // _FLEXFLOW_RMS_NORM_H
diff --git a/include/flexflow/ops/rms_norm_params.h b/include/flexflow/ops/rms_norm_params.h
new file mode 100644
index 0000000000..82a459009a
--- /dev/null
+++ b/include/flexflow/ops/rms_norm_params.h
@@ -0,0 +1,26 @@
+#ifndef _FLEXFLOW_RMSNORM_PARAMS_H
+#define _FLEXFLOW_RMSNORM_PARAMS_H
+
+#include "flexflow/parallel_tensor.h"
+
+namespace FlexFlow {
+
+struct RMSNormParams {
+ LayerID layer_guid;
+ float eps;
+ int dim;
+ bool is_valid(ParallelTensorShape const &) const;
+};
+
+bool operator==(RMSNormParams const &, RMSNormParams const &);
+
+} // namespace FlexFlow
+
+namespace std {
+template <>
+struct hash {
+ size_t operator()(FlexFlow::RMSNormParams const &) const;
+};
+} // namespace std
+
+#endif // _FLEXFLOW_RMSNORM_PARAMS_H
\ No newline at end of file
diff --git a/include/flexflow/ops/sampling.h b/include/flexflow/ops/sampling.h
new file mode 100644
index 0000000000..789904df32
--- /dev/null
+++ b/include/flexflow/ops/sampling.h
@@ -0,0 +1,112 @@
+#ifndef _FLEXFLOW_SAMPLING_TOPK_H_
+#define _FLEXFLOW_SAMPLING_TOPK_H_
+
+#include "flexflow/inference.h"
+#include "flexflow/model.h"
+#include "flexflow/node.h"
+#include "flexflow/ops/sampling_params.h"
+#if defined(FF_USE_CUDA) || defined(FF_USE_HIP_CUDA)
+#include
+#include
+#endif
+#include "flexflow/utils/memory_allocator.h"
+
+namespace FlexFlow {
+
+class SamplingMeta : public OpMeta {
+public:
+ float top_p;
+ void *sorted_logits;
+ int *sorted_idx;
+ int *begin_offset;
+ int *end_offset;
+ int *idx;
+ void *d_temp_storage;
+ size_t temp_storage_bytes;
+ Realm::RegionInstance reserveInst;
+#if defined(FF_USE_CUDA) || defined(FF_USE_HIP_CUDA)
+ curandState *state;
+#endif
+ SamplingMeta(FFHandler handle,
+ Op const *op,
+ int batch_size,
+ int total_ele,
+ GenericTensorAccessorW input,
+ MemoryAllocator &gpu_mem_allocator);
+ ~SamplingMeta(void);
+};
+
+class Sampling : public Op {
+public:
+ using Params = SamplingParams;
+ using Input = ParallelTensor;
+ Sampling(FFModel &model,
+ const ParallelTensor input,
+ float top_p,
+ char const *name);
+ Sampling(FFModel &model, Sampling const &other, const ParallelTensor input);
+ Sampling(FFModel &model,
+ Params const ¶ms,
+ Input const input,
+ char const *name = nullptr);
+ void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void forward(FFModel const &) override;
+ void backward(FFModel const &) override;
+ Legion::FutureMap inference(FFModel const &,
+ BatchConfigFuture const &,
+ std::vector const &,
+ std::vector const &,
+ MachineView const *mv = nullptr) override;
+ void print_layer(FFModel const &model) override {
+ assert(0);
+ }
+ static Op *
+ create_operator_from_layer(FFModel &model,
+ Layer const *layer,
+ std::vector const &inputs);
+
+ static OpMeta *init_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ static InferenceResult
+ inference_task(Legion::Task const *task,
+ std::vector const ®ions,
+ Legion::Context ctx,
+ Legion::Runtime *runtime);
+ void serialize(Legion::Serializer &s) const override;
+ static PCG::Node deserialize(FFModel &ff,
+ Legion::Deserializer &d,
+ ParallelTensor inputs[],
+ int num_inputs);
+ Op *materialize(FFModel &ff,
+ ParallelTensor inputs[],
+ int num_inputs) const override;
+ bool measure_operator_cost(Simulator *sim,
+ MachineView const &pc,
+ CostMetrics &cost_metrics) const override;
+ template
+ static void forward_kernel(SamplingMeta const *m,
+ DT *input_ptr,
+ int *indices_ptr,
+ float top_p,
+ int length,
+ int batch_size,
+ ffStream_t stream);
+ static void forward_kernel_wrapper(SamplingMeta const *m,
+ GenericTensorAccessorW const &input,
+ GenericTensorAccessorW const &indices,
+ int batch_size);
+ Params get_params() const;
+
+public:
+ float top_p;
+};
+
+}; // namespace FlexFlow
+
+#endif
\ No newline at end of file
diff --git a/include/flexflow/ops/sampling_params.h b/include/flexflow/ops/sampling_params.h
new file mode 100644
index 0000000000..1449ddbf54
--- /dev/null
+++ b/include/flexflow/ops/sampling_params.h
@@ -0,0 +1,24 @@
+#ifndef _FLEXFLOW_SAMPLING_PARAMS_H
+#define _FLEXFLOW_SAMPLING_PARAMS_H
+
+#include "flexflow/ffconst.h"
+#include "flexflow/parallel_tensor.h"
+
+namespace FlexFlow {
+
+struct SamplingParams {
+ float top_p;
+ bool is_valid(ParallelTensorShape const &) const;
+};
+bool operator==(SamplingParams const &, SamplingParams const &);
+
+} // namespace FlexFlow
+
+namespace std {
+template <>
+struct hash {
+ size_t operator()(FlexFlow::SamplingParams const &) const;
+};
+} // namespace std
+
+#endif // _FLEXFLOW_SAMPLING_PARAMS_H
\ No newline at end of file
diff --git a/include/flexflow/ops/softmax.h b/include/flexflow/ops/softmax.h
index 25a20315bd..1d5191d7ee 100644
--- a/include/flexflow/ops/softmax.h
+++ b/include/flexflow/ops/softmax.h
@@ -1,6 +1,7 @@
#ifndef _FLEXFLOW_SOFTMAX_H
#define _FLEXFLOW_SOFTMAX_H
+#include "flexflow/inference.h"
#include "flexflow/layer.h"
#include "flexflow/node.h"
#include "flexflow/operator.h"
@@ -21,7 +22,16 @@ class Softmax : public Op {
const Input input,
char const *name = nullptr);
void init(FFModel const &) override;
+ void init_inference(FFModel const &,
+ std::vector