概述
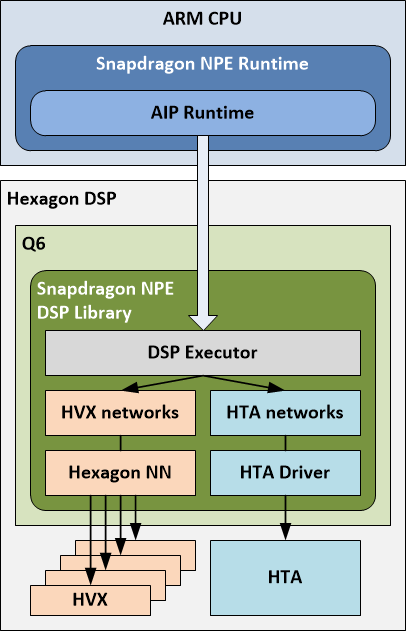
AIP (AI Processor) Runtime 是 Q6、HVX 和 HTA 的软件抽象,用于跨这三个处理器执行模型。用户将模型加载到 Snapdragon NPE 并选择 AIP Runtime 作为目标后,将在 HTA 和 HVX 上运行模型的部分,由 Q6 进行协调。注意:要在 HTA 上执行模型的部分,需要对模型进行离线分析,并将相关部分的二进制文件嵌入 DLC 中。有关详细信息,请参见添加 HTA 部分。
Snapdragon NPE 在 DSP 上加载一个库,该库与 AIP Runtime 通信。该 DSP 库包含一个执行器(管理 HTA 和 HVX 上的模型执行),用于在 HTA 上运行子网的 HTA 驱动程序以及用于使用 HVX 运行子网的 Hexagon NN。
执行器使用模型描述,其中还包含分区信息-描述模型的哪些部分将在 HTA 上运行,哪些部分将在 HVX 上运行。下面称分区的部分为"子网"。
DSP 执行器在各自的核心上执行子网,并根据需要协调缓冲区交换和格式转换以返回适当的输出到运行在 ARM CPU 上的 Snapdragon 运行时(包括必须的dequantization)。
让我们使用以下模型的说明性示例,该模型嵌入在由 Snapdragon NPE snpe-framework-to-dlc 转换工具之一创建的 DL Container 中。
- 圆圈表示模型中的操作
- 矩形表示包含和实现这些操作的层
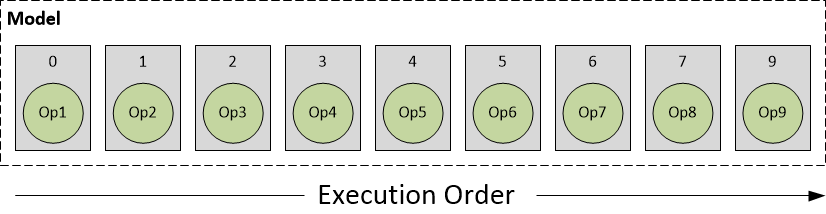
顶层 Snapdragon NPE 运行时根据层亲和性将模型的执行分解为在不同核心上运行的子网。
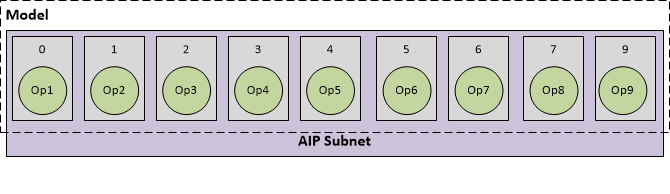
其中一个情况可能是整个网络都使用 AIP 运行时一起执行,如下所示:
或者,Snapdragon NPE 运行时可能会创建多个分区-其中几个分区在 AIP 运行时上执行,其余分区则回退到 CPU 运行时,如下所示:
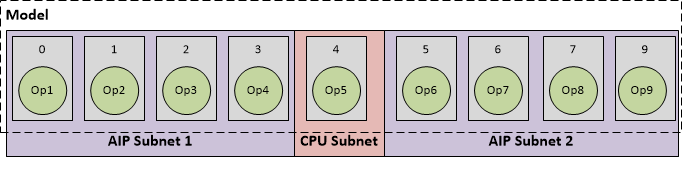
Snapdragon NPE 运行时将自动添加 CPU 运行时以执行其余部分被识别为回退到 CPU 的部分。
让我们使用上面的示例更仔细地检查 AIP 运行时的执行,其中整个模型都使用 AIP 作为参考进行执行。
AIP Runtime 进一步将 AIP 子网分解为以下内容:
- HTA 子网:由 HTA 编译器编译的子网的部分,其 HTA 编译器生成的元数据出现在 DLC 的 HTA 部分中。
- HNN 子网:其余可以使用 Hexagon NN 库在 DSP 上运行子网的子网,其元数据出现在 DLC 的 HVX 部分中。
在 AIP 运行时进行分区可能会产生几种可能的组合。下面是一些代表性的情况:
A. AIP 子网可以完全在 HTA 上运行
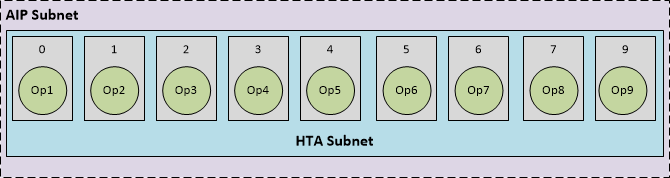
在这种情况下,整个 AIP 子网与 HTA 兼容。将 DLC 加载到 Snapdragon NPE 并选择 AIP 运行时后,运行时识别到有一个 HTA 部分,其中包含一个等于整个 AIP 子网的单个 HTA 子网。
B. AIP 子网的部分可以在 HTA 上运行,其余部分可以在 HNN 上运行
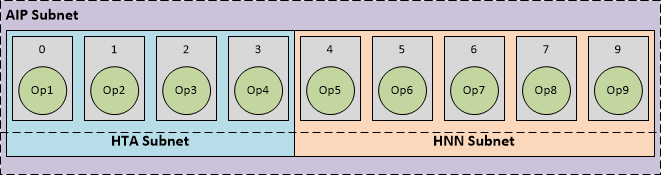
在某些情况下,整个 AIP 子网可能无法在 HTA 上处理。在这种情况下,HTA 编译器仅为网络中的较小一部分层生成 HTA 部分。或者,用户可能希望通过向 snpe-dlc-quantize 工具提供其他选项来手动分区网络,以选择他们希望在 HTA 上处理的子网(了解有关将网络分区为 HTA 的信息,请参见**添加 HTA 部分**)。在这两种情况下,HTA 编译器成功处理了较小的 HTA 子网,并嵌入了 DLC 中的相应 HTA 部分。将 DLC 加载到 Snapdragon NPE 并选择 AIP 运行时后,运行时识别到有一个 HTA 部分,其中包含一个仅覆盖 AIP 子网的一部分的单个 HTA 子网,以及其余部分可以使用 Hexagon NN 运行。
C. AIP 子网被分成多个分区
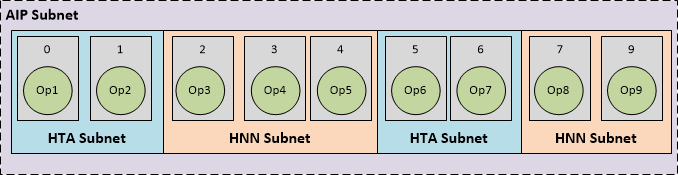
作为前面情况的扩展,可能会发现离线 HTA 编译器只能处理已识别的 AIP 子网的某些部分,从而使其余部分由多个 HNN 子网覆盖,如上所示。或者,用户可能希望通过向 snpe-dlc-quantize 工具提供其他选项来手动分区网络,以将网络分成多个 HTA 子网(了解有关将网络分区为 HTA 的信息,请参见添加 HTA 部分)。