- GitHub Topic
- Medium
- Roadmap
- Code Beautify
- Dev Docs
- QA
- Blogs JavaScript
- Interview
- Techmaster
- GPCoder
- Bytebytecode
- Master spring boot
- Security Zines
- All blogs from spring1
- All blogs from spring2
- All blogs from spring3
- Java By Examples
- Toptal
- All blogs from spring4
- Spring Framework Guru
- Piotr's TechBlog
- Dzone
- Viblo
- Java Tech Online
- openplanning
- kungfutech
- viettuts
- 200lab
- loda
- longnv
- stackjava
- Hackernoon
- Marcobehler Java
- PWSKILLS
- System Design Blog
- Java Re Visted
- Web-Dev
- Javascript info
- java point
- Developer Mozilla
- DevopsEdu
- Milan Newsletter
- Angular.io
- Angular api
- Angular vietnam
- Angular youtube
- Roadmap Angular
- Angular Vietnam Youtube
- Community
- SQL tutorial
- Oracle tutorial
- SQL server tutorial
- Mysql tutorial
- Postgres tutorial
- MarialDB tutorial
- Wecommit
- SpringDeveloper
- OpenAI
- IBM Technology
- Dan Vega
- Amigoscode
- freeCodeCamp.org
- in28minutes - Get Cloud Certified
- Telusko
- ByteByteGo
- Google Cloud Tech
- TechWorld with Nana
- Daily Coder
- VN - Hole Tex
- VN - Tips Javascript
- Code Generator
- Text Generator
- Netty: Netty is an asynchronous event-driven network application framework. It provides a high-performance, low-level networking API that enables the development of various network protocols and applications. Netty focuses on building scalable, high-performance network servers and clients.
-
Key features of Netty include:
-
- Non-blocking I/O: Netty uses an event-driven model with non-blocking I/O operations, allowing for efficient handling of multiple connections without requiring a large number of threads.
-
- High throughput: Netty is optimized for high throughput and low latency, making it suitable for applications that require high-performance networking.
-
- Protocol support: Netty provides built-in support for various network protocols and allows for custom protocol implementations.
-
- Flexibility: Netty offers a flexible and extensible API, making it possible to customize and extend the framework as per application requirements.
- Tomcat: Tomcat, officially known as Apache Tomcat, is a widely used web server and servlet container. It provides an environment for running Java web applications, including support for Java servlets, JavaServer Pages (JSP), and WebSocket applications.
-
Key features of Tomcat include:
-
- Servlet container: Tomcat implements the Java Servlet and JavaServer Pages specifications, allowing developers to deploy and run web applications written in Java. Web server capabilities: Tomcat can act as a standalone web server, serving static files and handling HTTP requests.
-
- Java EE compatibility: Tomcat supports Java Enterprise Edition (Java EE) specifications and can be used as a lightweight alternative to full-fledged Java EE application servers like JBoss or WebLogic.
-
- Management and monitoring: Tomcat provides various tools and interfaces for managing and monitoring deployed applications, including a web-based administration console. In summary, Netty is primarily focused on low-level network programming and building high-performance network applications, while Tomcat is designed for running Java web applications and serving HTTP requests. Depending on your specific use case, you would choose one over the other. https://github.com/angular-vietnam/100-days-of-angular
-
- Recapchar architectures
Frontend không cần nginx để deploy, nhưng việc sử dụng Nginx có nhiều lợi ích khi triển khai ứng dụng frontend trong môi trường sản phẩm. Dưới đây là một số lý do phổ biến:
-
Web Server: Nginx có thể hoạt động như một web server để phục vụ các tệp tĩnh (HTML, CSS, JavaScript) cho trình duyệt của người dùng. Điều này giúp tối ưu hóa việc phục vụ tệp tĩnh và cải thiện hiệu suất của ứng dụng.
-
Cân bằng tải (Load Balancing): Nếu bạn triển khai nhiều phiên bản của ứng dụng frontend trên các máy chủ khác nhau, Nginx có thể được cấu hình để cân bằng tải trên các máy chủ này. Điều này giúp phân phối công việc đồng đều và tăng khả năng chịu tải của hệ thống.
-
Bộ đệm (Caching): Nginx có khả năng lưu trữ tạm thời (cache) các tệp tĩnh, giúp giảm tải cho máy chủ ứng dụng và cung cấp thời gian phản hồi nhanh hơn cho người dùng. Bộ đệm này giúp giảm tải cho backend và cải thiện hiệu suất tổng thể.
-
Gzip Compression: Nginx hỗ trợ nén Gzip, giúp giảm kích thước các tệp tin trước khi gửi đến trình duyệt. Điều này giúp tăng tốc độ tải trang và giảm lưu lượng mạng cần thiết để truyền dữ liệu.
-
SSL/TLS Offloading: Nginx có thể được cấu hình để xử lý SSL/TLS, giải phóng máy chủ ứng dụng khỏi việc xử lý mã hóa và giải mã truyền thông bảo mật. Điều này giúp giảm tải cho backend và cải thiện hiệu suất.
-
Proxy Server: Nginx có khả năng hoạt động như một proxy server, giúp chuyển tiếp yêu cầu từ trình duyệt đến backend của ứng dụng. Điều này cho phép thực hiện các tác vụ như định tuyến yêu cầu, chuyển tiếp HTTP hoặc HTTPS, ẩn danh và nhiều hơn nữa.
-
Java library for canary checks on web services.
-
Canary checks are similar to a health check, with the main difference being that it tests the system much deeper. Health checks usually collect a number of indicators and for each of those the result is either UP or DOWN. If the service is unhealthy, a health endpoint usually returns a non-200 status code. This has important impacts on load balancers and orchestration systems like Kubernetes.
-
A canary endpoint reveals much more sophisticate information and can be used for general monitoring of service, as opposed to just detecting if it's functioning or not functioning.
-
For example, your service might depend on a third party for some API calls, but not all of them. In such case, the canary endpoint might return information about that third party being down. Your service might also depend on a scheduled task running every X hours. The canary endpoint could raise an alarm if no task was run in the last X+1 hours.
- Proxy: Một proxy (proxy server) là một máy chủ trung gian giữa người dùng và các nguồn tài nguyên mạng (ví dụ: máy chủ web hoặc dịch vụ trực tuyến). Khi người dùng gửi yêu cầu đến proxy, proxy sẽ chuyển tiếp yêu cầu đó đến nguồn tài nguyên tương ứng và trả về kết quả cho người dùng. Điều này giúp che giấu địa chỉ IP thực sự của người dùng và cung cấp các lợi ích khác như bảo mật, tăng tốc độ truy cập và kiểm soát truy cập vào nguồn tài nguyên.
- Reverse Proxy: Một reverse proxy (reverse proxy server) cũng là một máy chủ trung gian, nhưng nó chuyển tiếp yêu cầu từ người dùng đến các máy chủ back-end hoặc các nguồn tài nguyên khác. Khi người dùng gửi yêu cầu đến reverse proxy, reverse proxy sẽ định tuyến yêu cầu đến máy chủ back-end tương ứng và trả về kết quả cho người dùng. Điều này giúp tăng cường hiệu suất, phân tải tải và cân bằng tải cho hệ thống server. Ngoài ra, reverse proxy cũng có thể cung cấp các tính năng bảo mật như bảo vệ chống tấn công DDoS và bảo vệ ẩn danh.
- Forward proxy :
-
Ẩn danh và bảo mật: Forward proxy giúp che giấu địa chỉ IP thực sự của người dùng khi gửi yêu cầu đến các máy chủ hoặc dịch vụ. Điều này cung cấp một lớp ẩn danh và bảo mật cho người dùng.
-
Kiểm soát truy cập: Forward proxy cho phép người quản trị mạng kiểm soát truy cập vào các nguồn tài nguyên trên Internet. Bằng cách cấu hình forward proxy, các quy tắc và chính sách truy cập có thể được áp dụng để kiểm soát và giới hạn quyền truy cập từ các người dùng.
-
Tăng tốc truy cập: Forward proxy có thể lưu lại bộ nhớ cache của các yêu cầu trước đó từ người dùng. Khi có yêu cầu tương tự, forward proxy có thể trả về kết quả từ cache mà không cần gửi yêu cầu đến máy chủ hoặc dịch vụ, giúp tăng tốc độ truy cập.
-
Bộ lọc và bảo vệ: Forward proxy có thể được cấu hình để áp dụng các bộ lọc và quy tắc bảo vệ, như chặn truy cập vào các trang web độc hại, quảng cáo, hoặc nội dung không phù hợp.
5. Cách sử dụng file cấu hình application-dev.yml và application-aws.yml trong quá trình triển khai có thể phụ thuộc vào quy trình triển khai và cách bạn cấu hình ứng dụng.
-
Sử dụng trực tiếp: Một số framework và thư viện cho phép bạn sử dụng các file cấu hình này trực tiếp trong quá trình triển khai. Khi triển khai ứng dụng, bạn chỉ cần đảm bảo rằng các file application-dev.yml và application-aws.yml được đưa vào vị trí cấu hình chính xác và ứng dụng sẽ tự động đọc và áp dụng các cấu hình từ các file này.
-
Sử dụng thủ công: Trong một số trường hợp, bạn có thể cần sử dụng các công cụ hoặc kịch bản tùy chỉnh để xử lý các file cấu hình này. Ví dụ, bạn có thể sử dụng kịch bản triển khai (deployment script) để sao chép và đặt các file cấu hình vào vị trí cần thiết trên máy chủ triển khai. Sau đó, bạn có thể khởi động lại ứng dụng hoặc thực hiện các bước tiếp theo để áp dụng các cấu hình từ các file này.
-
Cách sử dụng trực tiếp hay thủ công phụ thuộc vào quy trình triển khai và các công cụ mà bạn đang sử dụng. Đối với các nền tảng và công cụ triển khai như Docker, Kubernetes, Ansible, hoặc các nền tảng điện toán đám mây, bạn có thể sử dụng các kịch bản triển khai hoặc công cụ quản lý cấu hình để tự động sao chép và áp dụng các file cấu hình này.
In the context of security systems, the concept of certificates revolves around the use of digital certificates to establish trust, authenticate entities, and ensure secure communication. Here's an overview of the certificate concept in security systems:
- Digital Certificates: In security systems, digital certificates are electronic documents that verify the identity of a particular entity, such as a person, device, or organization. They contain information about the entity, including its public key, and are issued and signed by a trusted certification authority (CA).
- Public Key Infrastructure (PKI): Digital certificates are a fundamental component of a PKI, which is a system that manages the creation, distribution, and revocation of certificates. PKI provides a framework for secure communication, encryption, and authentication in various security systems.
- Authentication and Trust: Certificates play a crucial role in verifying the authenticity and trustworthiness of entities involved in security systems. By digitally signing certificates, CAs vouch for the identity of the entity and confirm that the public key associated with the certificate belongs to the claimed entity.
- Secure Communication: Certificates are commonly used in secure communication protocols such as Transport Layer Security (TLS) and Secure Sockets Layer (SSL). In these protocols, certificates are used to authenticate the server's identity to the client and establish an encrypted and secure communication channel.
- Certificate Authorities (CAs): CAs are trusted entities responsible for issuing and managing digital certificates. They follow strict procedures to verify the identity of entities before issuing certificates. Popular CAs include public CAs like Let's Encrypt and private CAs within organizations.
- Certificate Chains and Trust Hierarchies: Certificates can form a chain of trust, where a root CA signs intermediate CAs, and intermediate CAs sign end-entity certificates. This hierarchical structure allows for the delegation of trust and enables verification of certificates by relying parties.
- Revocation and Expiration: Certificates have an expiration date after which they are no longer considered valid. Additionally, certificates can be revoked before expiration if the private key is compromised or if the entity no longer meets the trust criteria. Certificate revocation mechanisms, such as Certificate Revocation Lists (CRLs) and Online Certificate Status Protocol (OCSP), are used to manage revocations. Certificates in security systems provide a means to verify and establish trust in the digital realm. They are essential for securing communication channels, authenticating entities, and protecting sensitive information. By leveraging digital certificates, security systems can ensure confidentiality, integrity, and authenticity in various domains, including network security, web applications, e-commerce, and identity management.
An HTTP-only cookie is a type of cookie that is set with the HTTP-only flag. This flag is an additional attribute that can be included when a cookie is sent from the server to the client (usually through an HTTP response). When the HTTP-only flag is present, it instructs the client's web browser to restrict access to the cookie, preventing it from being accessed or modified by JavaScript code running on the client-side.
The purpose of using HTTP-only cookies is to enhance the security of web applications. By restricting access to cookies, it helps mitigate certain types of attacks, such as cross-site scripting (XSS) attacks. XSS attacks involve injecting malicious scripts into a website, which can be used to steal sensitive information, including cookies. However, since JavaScript code cannot access HTTP-only cookies, it significantly reduces the risk of such attacks.
HTTP-only cookies can only be accessed and sent back to the server by the client's web browser during subsequent HTTP requests. They are typically used for session management, storing user authentication tokens, and other sensitive information that should not be accessible to client-side scripts.
To set an HTTP-only cookie in an HTTP response, the server includes the HttpOnly attribute in the Set-Cookie header. Here's an example:
Set-Cookie: sessionid=abcd1234; Path=/; HttpOnly
In this example, the sessionid cookie is marked as HTTP-only with the HttpOnly attribute. The browser will honor this attribute and ensure that the cookie is only accessible through the HTTP protocol.
It's important to note that although HTTP-only cookies enhance security, they are not a complete solution for preventing all types of attacks. Other security measures, such as secure transmission of data over HTTPS, input validation, and proper server-side security practices, should also be implemented to ensure the overall security of a web application.
8 .Cơ chế hoạt động của HTTP Only cookie trong việc làm mới (refresh) token trong ứng dụng web có thể được mô tả như sau:
-
Đầu tiên, khi người dùng đăng nhập vào ứng dụng và gửi yêu cầu xác thực, máy chủ sẽ tạo một cặp cookie bao gồm một cookie session và một cookie refresh token. Cookie session thường có thời gian sống ngắn hơn, trong khi cookie refresh token sẽ có thời gian sống lâu hơn.

-
Cookie session được thiết lập với thuộc tính HTTP Only, điều này có nghĩa là nó chỉ có thể được truy cập thông qua giao thức HTTP và không thể truy cập bằng JavaScript. Điều này giúp ngăn chặn tấn công Cross-Site Scripting (XSS), trong đó kẻ tấn công có thể đánh cắp cookie thông qua mã JavaScript độc hại.
-
Khi access token hết hạn, người dùng tiếp tục sử dụng ứng dụng và gửi yêu cầu xác thực, máy chủ sẽ kiểm tra xem cookie session có tồn tại hay không. Nếu cookie session vẫn còn hiệu lực, máy chủ sẽ tạo lại access token mới và gửi nó đến client thông qua phản hồi HTTP.

-
Nếu cookie session đã hết hạn hoặc không tồn tại, máy chủ sẽ kiểm tra cookie refresh token. Nếu cookie refresh token còn hiệu lực, máy chủ sẽ sử dụng nó để tạo lại cặp cookie session và access token mới, và gửi chúng đến client.

-
Nếu cả cookie session và cookie refresh token đều đã hết hạn hoặc không tồn tại, người dùng sẽ bị đăng xuất khỏi ứng dụng và được yêu cầu đăng nhập lại.
-
Tóm lại, cơ chế hoạt động của HTTP Only cookie trong việc làm mới token (refresh token) giúp bảo vệ thông tin xác thực của người dùng bằng cách giới hạn truy cập của cookie chỉ thông qua giao thức HTTP và ngăn chặn tấn công XSS. Nó cho phép máy chủ sử dụng cookie refresh token để tạo lại session và access token khi cần thiết, giúp duy trì phiên làm việc của người dùng trong ứng dụng web.





9. Cơ chế ghi nhớ mật khẩu trong ứng dụng web thường được thực hiện bằng cách sử dụng một cookie ghi nhớ hoặc một phiên làm việc dài hạn. Dưới đây là một cơ chế thông thường để hiểu cách nó hoạt động:
-
Người dùng đăng nhập vào ứng dụng bằng tên đăng nhập và mật khẩu.
-
Khi người dùng chọn tùy chọn "Ghi nhớ mật khẩu", ứng dụng tạo một cookie hoặc phiên làm việc dài hạn chứa thông tin đăng nhập của người dùng, chẳng hạn như một mã thông báo (token) xác thực.
-
Cookie hoặc phiên làm việc dài hạn được lưu trữ trên máy tính của người dùng, thông qua trình duyệt web.
-
Khi người dùng truy cập lại ứng dụng web sau khi đã đăng xuất hoặc đóng trình duyệt, ứng dụng kiểm tra xem- có tồn tại cookie ghi nhớ hoặc phiên làm việc dài hạn hay không.
-
Nếu cookie hoặc phiên làm việc dài hạn tồn tại, ứng dụng sẽ sử dụng thông tin đăng nhập trong cookie hoặc phiên làm việc để tự động đăng nhập người dùng, mà không yêu cầu nhập lại tên đăng nhập và mật khẩu.
-
Trong trường hợp người dùng muốn đăng xuất hoặc xóa cookie ghi nhớ, ứng dụng sẽ xóa cookie hoặc phiên làm việc dài hạn khỏi máy tính của người dùng. Lưu ý rằng cơ chế ghi nhớ mật khẩu chỉ nên được sử dụng khi người dùng truy cập từ máy tính cá nhân hoặc thiết bị riêng. Trên các thiết bị công cộng hoặc chia sẻ, nên khuyến khích người dùng không sử dụng tính năng này để bảo vệ thông tin cá nhân và tài khoản.
10. MVC, MVP, MVVM Design Partern Reference article
- MVC Partern : The model has no understanding of the view or the controller. The model's observer will receive an alert whenever there's a change in the view and controller. The controller helps the routing process to connect the model to the relevant view. Some of the MVC partern's advantages are:
- Separation of concerns (more focused).
- Makes it easier to test and manage the code.
- Promotes decoupling of the application's layers.
- Better code organization and reusability.
- MVP Partern : Model-View-Presenter Pattern : The MVP pattern shares two components with MVC: model and view. It replaces the controller with the presenter. The presenter—as its name implies—is used to present something. It allows you to mock the view more easily. In MVP, the presenter has the functionality of the "middle-man" because all presentation logic is pushed to it. The view and presenter in MVP are also independent of one another and interact via an interface.
- MVVM Partern : Model-View-ViewModel Pattern : MVVM is the modern evolution of MVC. The main goal of MVVM is to provide a clear separation between the domain logic and presentation layer. MVVM supports two-way data binding between the view and viewmodel. The MVVM pattern allows you to separate your code’s view and model. This means that when the model changes the view doesn’t need to, and vice-versa. Using a viewmodel, you can do unit testing and test your logic behavior without involving your view.




Web Server is software and hardware that uses HTTP(Hypertext Transfer Protocol) and other protocols to respond to client requests made over the Word Wide Web. The main job of a web server is to display website content through storing, processing and delivering webpages to users. Besides HTTP, web servers also support SMTP(Simple Mail Transfer Protocol) and FTP(File Transfer Protocol), used for email, file transfer and storage. Webserver are used in web hosting, or the hosting of data of websites and web-based applications -- or web application.
- There are a number of common web servers available, some including:
- Apache HTTP Server : Developed by Apache Software Foundation, it is a free and open source web server for Windows, Mac OS X, Unix, Linux, Solaris and other operating systems; it needs the Apache license
- Microsoft Internet Information Services (IIS). Developed by Microsoft for Microsoft platforms; it is not open sourced, but widely used.
- Nginx : A popular open source web server for administrators because of its light resource utilization and scalability. It can handle many concurrent sessions due to its event-driven architecture. Nginx also can be used as a proxy server and load balancer. Should use
- Lighttpd: A free web server that comes with the FreeBSD operating system. It is seen as fast and secure, while consuming less CPU power.
- Sun Java System Web Server: A free web server from Sun Microsystems that can run on Windows, Linux and Unix. It is well-equipped to handle medium to large websites.
VPN, VPS, DNS are three different technologies that serve distinct purposes in the realm of computer networking and internet connectivity. Here's a brief explanation of each term
- VPN(Virtual Private Network): A VPN is a technology that creates a secure and encrypted connection between your device(such as a computer, smartphone, or tablet) and the internet. It acts as a tunnel, encrypting your data and routing it through a remote server located in a different geographical location. This process ensures that your online activities remain private and secure from potential eavesdropping, censorship, or data interception. VPNs are commonly used to enhance privacy, access geographically restricted content, and secure connections on public WIFI networks.
- VPS(Virtual Private Server) : A VPS is a virtual machine that is provided as a service by a hosting provider. It operates within a layer physical server but functions independently, allowing users to have root access and install their own software. Essentially, a VPS provides you with a dedicated portion of server resources such as CPU, RAM and Storage, which you can configure and manage as per your requirements. VPS hosting is commonly used by businesses and individuals who need more control, scalability, and customization options compared to shared hosting environments.
- DNS (Domain Name System): DNS is a fundamental part of the internet's infrastructure. It is a hierarchical naming system that translates human-readable domain names(such as www.example.com) into IP addresses (such as 192.0.2.1) that computers use to identify each other on the internet. When you type a website address into your browser, the DNS system is responsible for resolving the domain name to the corresponding IP address, enabling your device to connect to the correct server. DNS servers are distributed globally and help facilitate the translation process, allowing users to access websites and other online services using domain names rather than having to remember IP addresses. Overall, while VPNs focus on securing and encrypting internet connections, VPSs provide dedicated virtual server environments, and DNS enables the translation of domain names into IP addresses for efficient internet browsing.
 ### 13. Webhook
### 13. Webhook

A webhook is a way for two systems or application to communicate with each other in real-time. It is a mechanism that allows one system to send data another system automatically when a specific event or trigger occurs

Here's how a webhook typically works:
- Setting up the webhook: The receiving system(usually a server or web application) provides a URL where it expects to receive data. This URL acts as an endpoint for webhook.
- Trigger Event: The sending system(often an external service or application) monitors for a specific event or action. When this event occurs, the sending system generates data to be sent to the webhook.
- Sending data: The sending system initiates an HTTP POST request to the webhook URL, typically including the relevant data in the request payload. This request notifies the receiving system about the event.
- Processing the webhook: The receiving system receives the HTTP request from the webhook and performs actions based on the data received. This can involve updating a database, triggering further processes, sending notifications, or any other desired behavior.
Webhooks are commonly used in various scenarios, such as:
- Integrating third-party services: Webhooks allow external services to notify your application about events or data updates, enabling real-time synchronization. For example, a payment gateway might send a webhook when a payment is processed.
- Event-driven architectures: Webhooks facilitate event-driven communication between different components or microservices in a system. When an event occurs, a webhook can be used to trigger subsequent actions.
- Notifications and alerts: Webhooks are useful for sending notifications or alerts in real time. For instance, a monitoring system can send a webhook to notify about a system failure.
- Web API callbacks: Webhooks provide a way for API Clients to receive updates from the API server asynchronously. Instead of repeatedly polling for new data the server can push updates to the client via webhooks. Webhook là một cơ chế hoặc một phương thức để truyền tải dữ liệu tự động từ một ứng dụng hoặc dịch vụ mà bạn đã đăng ký đến một ứng dụng hoặc dịch vụ khác. Nó hoạt động dựa trên sự kích hoạt của sự kiện và thông qua việc gửi HTTP POST request từ nguồn gốc đến đích. Webhook cho phép các ứng dụng giao tiếp và chia sẻ thông tin một cách tự động và thời gian thực. Để sử dụng webhook, bạn cần có một ứng dụng hoặc dịch vụ đóng vai trò là nguồn gốc webhook, và một ứng dụng hoặc dịch vụ khác đóng vai trò là đích webhook. Khi xảy ra sự kiện quan trọng trong nguồn gốc webhook, nó sẽ gửi một HTTP POST request chứa dữ liệu liên quan đến sự kiện đó đến đích webhook. Đích webhook sau đó có thể xử lý dữ liệu và thực hiện các hành động tương ứng. Cách cấu hình và sử dụng webhook phụ thuộc vào từng ứng dụng hoặc dịch vụ cụ thể mà bạn đang sử dụng. Thông thường, bạn sẽ cần cung cấp URL đích webhook (endpoint URL) cho nguồn gốc webhook để nó biết nơi gửi dữ liệu. Đồng thời, bạn cũng sẽ cần xử lý và xác thực dữ liệu được gửi đến từ nguồn gốc webhook trong ứng dụng hoặc dịch vụ của mình. Webhook được sử dụng rộng rãi trong các lĩnh vực như tích hợp ứng dụng, thông báo thời gian thực, tự động hóa quy trình và liên kết dữ liệu giữa các hệ thống khác nhau.
AES (Advanced Encryption Standard): AES là một thuật toán mã hoá đối xứng được sử dụng rộng rãi. Nó được chọn làm tiêu chuẩn mã hoá cho chính phủ Hoa Kỳ và đã trở thành một trong những thuật toán mã hoá phổ biến nhất trên thế giới.RSA: RSA là một thuật toán mã hoá bất đối xứng, được sử dụng cho các mục đích như chứng thực, chữ ký số và trao đổi khóa. Nó dựa trên việc tính toán các phép toán số học trên các số nguyên lớn.SHA (Secure Hash Algorithm): SHA là một họ thuật toán băm (hash) được sử dụng để tạo ra các giá trị băm (hash value) duy nhất từ dữ liệu đầu vào. Các biến thể phổ biến của SHA bao gồm SHA-1, SHA-256, SHA-512, v.v.HMAC (Hash-based Message Authentication Code): HMAC là một thuật toán kết hợp việc sử dụng một hàm băm cùng với một khóa bí mật để tạo ra một mã xác thực (authentication code). Nó được sử dụng để đảm bảo tính toàn vẹn và xác thực của dữ liệu. HMAC thường được sử dụng trong các giao thức bảo mật, như HTTPS, SSH, và các thuật toán chứng thực như HMAC-SHA1, HMAC-SHA256, v.v. Nó cung cấp một cơ chế an toàn và tin cậy để xác thực thông điệp và ngăn chặn các cuộc tấn công giả mạo dữ liệu.Blowfish: Blowfish là một thuật toán mã hoá đối xứng nhanh và an toàn. Nó được sử dụng rộng rãi trong ứng dụng bảo mật và mã hóa dữ liệu.DES (Data Encryption Standard): DES là một thuật toán mã hoá đối xứng khá cổ điển. Mặc dù DES đã trở thành lỗi thời và không được khuyến nghị sử dụng cho các ứng dụng mới, nhưng nó vẫn có giá trị lịch sử và cơ bản.
When we use various applications and websites, three essential security steps are continuously at play:
- Identity
- Authentication
- Authorization

- Password Authentication Password authentication is a fundamental and widely used mechanism for verifying a user's identity on websites and applications. In this method, users enter a unique username and password combination to gain access to protected resources. The entered credentials are checked against stored user information in the system, and if they match, the user is granted access. While password authentication is a foundational method for user verification, it has some limitations. Users may forget their passwords, and managing unique usernames and passwords for multiple websites can be challenging. Furthermore, password-based systems can be vulnerable to attacks, such as brute-force or dictionary attacks, if proper security measures aren't in place To address these issues, modern systems often implement additional security measures, such as multi-factor authentication, or use other authentication mechanisms (e.g., session-cookie or token-based authentication) to complement to replace password-based authentication for subsequent access to protected resources.
- HTTP Basic Access Authentication HTTP basic access authentication requires a web browser to provide a username and a password when requesting protected resources. The credentials are encoded using the Base64 algorithm and included in the HTTP header field Authorization: Basic. Here's how it typecally works:
-
- The client sends a reuqest to access a protected resource on the server
-
- If the client has not yet provided any authentication credentials, the server responds with a 401 Unauthorized status code and includes the WWW-Authenticate: Basic header to indicate that it requires basic authentication.
-
- The client prompts the user to enter their username and password, which are combined into a single string in the format username: password.
-
- The combined string is Based64 encoded and included in the "Authorization: Basic" header in the subsequent request to the server, e.g., Authorization: Basic dXNlcm5hbWU6cGFzc3dvcmQ=.
-
- Upon receiving the request, the server decodes the Base64-encoded credentials and separates the username and password. The server then checks the provided credentials against its user database or authentication service.
-
- If the credentials match, the server grants access to the requested resource. If not, the server responds with a 401 Unauthorized status code.
HTTP Basic Access Authentication has limitations. The username and password, encoded using Base64, can be easily decoded. Most websites use TLS (Transport Layer Security) to encrypt data between the browser and server, improving security. However, users' credentials may still be exposed to interception or man-in-the-middle attacks
With HTTP Basic Access Authentication, the browser sends the Authorization header with the necessary credentials for each request to protected resources within the same domain. This provides a smoother user experience, without repeatedly entering the username and password. But, as each website maintains it own usernames and passwords, users may find it difficult to remember their credentials.
This authentication mechanism is obsolete for modern websites.
- If the credentials match, the server grants access to the requested resource. If not, the server responds with a 401 Unauthorized status code.
HTTP Basic Access Authentication has limitations. The username and password, encoded using Base64, can be easily decoded. Most websites use TLS (Transport Layer Security) to encrypt data between the browser and server, improving security. However, users' credentials may still be exposed to interception or man-in-the-middle attacks
With HTTP Basic Access Authentication, the browser sends the Authorization header with the necessary credentials for each request to protected resources within the same domain. This provides a smoother user experience, without repeatedly entering the username and password. But, as each website maintains it own usernames and passwords, users may find it difficult to remember their credentials.
This authentication mechanism is obsolete for modern websites.

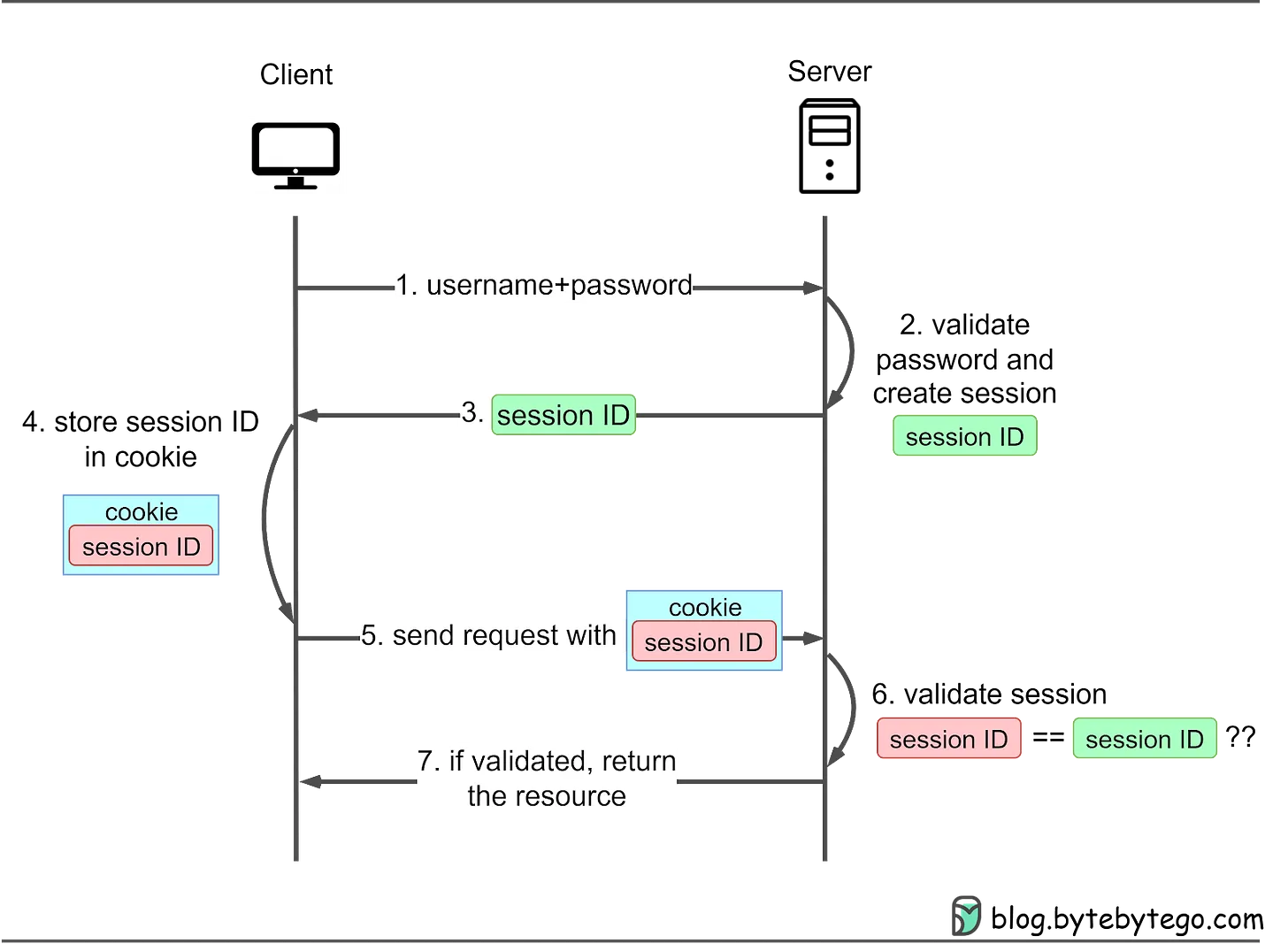
- Session-Cookie Authentication Session-cookie authentication addresses HTTP basic access authentication's inability to track user login status. A session ID is generated to track the user's status during their visit. This session ID is recorded both server-side and in the client’s cookie, serving as an authentication mechanism. It is called a session-cookie because it is a cookie with the session ID stored inside. Users must still provide their username and password initially, after which the server creates a session for the user's visit. Subsequent requests include the cookie, allowing the server to compare client-side and server-side session IDs. Let’s see how it works:
- The client sends a request to access a protected resource on the server. If the client has not yet authenticated, the server responds with a login prompt. The client submits their username and password to the server.
- The server verifies the provided credentials against its user database or authentication service. If the credentials match, the server generates a unique session ID and creates a corresponding session in the server-side storage (e.g., server memory, database, or session server).
- The server sends the session ID to the client as a cookie, typically with a Set-Cookie header
- The client stores the session cookie.
- For subsequent requests, it sends the cookie along with the request headers.
- The server checks the session ID in the cookie against the stored session data to authenticate the user.
- If validated, the server grants access to the requested resource. When the user logs out or after a predetermined expiration time, the server invalidates the session, and the client deletes the session cookie.
- Passwordless Authentication We have covered three types of authentication so far: HTTP basic authentication, session-cookie authentication, and token-based authentication. They all require a password. However, there are other ways to prove your identity without a password. When it comes to authentication, there are three factors to consider:
- Knowledge factors: something you know, such as a password
- Ownership factors: something you own, such as a device or phone number
- Inherence factors: something unique to you, such as your biometric features Passwords fall under “something you know”. One-Time Passwords (OTP) prove that the user owns a cell phone or a device, while biometric authentication proves "something unique to you".
- One-Time Passwords (OTP) One-Time Passwords (OTP) are widely used as a more secure method of authentication. Unlike static passwords, which can be reused, OTPs are valid for a limited time, typically a few minutes. This means that even if intercepts an OTP, they can't use it log in later, Additionally, OTPs requires "something you own" as well as "something you know" to log in. This can be a cell phone number or email address that the user has access to, making it harder for hackers to steal.
However, it's important to note that using SMS as the delivery method for OTPs can be less secure than other methods. This is because SMS messages can be intercepted or redirected by hackers, particularly if the user's phone number has been compromised. In some cases, attackers have been able to hijack phone numbers by convincing the mobile carrier to transfer the number to a new SIM card. Once the attacker has control of the number, they can intercept any OTPs sent via SMS. For this reason, it's recommended to use alternative delivery methods, such as email or mobile apps, whenever possible. Here’s how OTPs work in more detail:
- Step 1: The user wants to log in to a website and is asked to enter a username, cell phone number, or email.
- Step 2: The server generates an OTP with an expiration time.
- Step 3: The server sends the OTP to the user’s device via SMS or email.
- Step 4: The user enters the OTP received in the login box.
- Step 5-6: The server compares the generated OTP with the one the user entered. If they match, login is granted.
Alternatively, a hardware or software key can be used to generate OTPs for multi-factor authentication (MFA). For example, Google 2FA uses a software key that generates a new OTP every 30 seconds. When logging in, users enter their password and the current OTP displayed on their device. This adds an extra layer of security as hackers would need access to the user’s device to steal the OTP. More on MFA later.

- SSO (Single Sign-On) Single Sign-On (SSO) is a user authentication method that allows us to access multiple systems or applications with a single set of credentials. SSO streamlines the login process, providing a seamless user experience across various platforms. The SSO process mainly relies on a Central Authentication Service (CAS) server. Here's a step-by-step breakdown of the SSO process:
- When we attempt to log in to an application, such as Gmail, we're redirected to the CAS server.
- The CAS server verifies our login credentials and creates a Ticket Granting Ticket (TGT). This TGT is then stored in a Ticket Granting Cookie (TGC) on our browser, representing our global session.
- CAS generates a Service Ticket (ST) for our visit to Gmail and redirects us back to Gmail with the ST.
- Gmail uses the ST to validate our login with the CAS server. After validation, we can access Gmail. When we want to access another application, like YouTube, the process is simplified:
- Since we already have a TGC from our Gmail login, CAS recognizes our authenticated status.
- CAS generates a new ST for YouTube access, and we can use YouTube without inputting our credentials again.
This process reduces the need to remember and enter multiple sets of credentials for different applications.

- SAML (Security Assertion Markup Language) is widely used in enterprise applications. SAML communicates authentication and authorization data in an XML format.
- OIDC (OpenID Connect) is popular in consumer applications. OIDC handles authentication through JSON Web Tokens (JWT) and builds on the OAuth 2.0 framework. For new applications, OIDC is the preferred choice. It supports various client types, including web-based, mobile, and JavaScript clients.
SSO offers a streamlined and secure authentication method, providing a seamless user experience by requiring only one set of credentials for multiple applications. This approach enhances security through the use of strong, unique passwords and reduced phishing risks. It also minimizes administrative burdens for IT departments.
- OAuth 2.0 and OpenID Connect (OIDC) While OAuth 2.0 is primarily an authorization framework, it can be used in conjunction with OpenID Connect (OIDC) for authentication purposes. OIDC is an authentication layer built on top of OAuth 2.0, enabling the verification of a user's identity and granting controlled access to protected resources.
When using "Sign in with Google" or similar features, OAuth 2.0 and OIDC work together to streamline the authentication process. OIDC provides user identity data in the form of a standardized JSON Web Token (JWT). This token contains information about the authenticated user, allowing the third-party application to create a user profile without requiring a separate registration process.
In this setup, OAuth 2.0 provides "secure delegated access" by issuing short-lived tokens instead of passwords, allowing third-party services to access protected resources with the resource owner's permission. This method enhances security, as the third-party service does not handle or store the user's password directly.
The diagram below shows how the protocol works in the “Sign in with Google” scenario.

- Resource owner: The end user, who controls access to their personal data.
- Resource server: The Google server hosting user profiles as protected resources. It uses access tokens to respond to protected resource requests, ensuring that only authorized services can access the data.
- Client: The device (PC or smartphone) making requests on behalf of the resource owner. This device represents the third-party application seeking access to the user's data.
- Authorization server: The Google authorization server that issues tokens to clients, managing the secure exchange of tokens between the resource server and the client.
OAuth 2.0 offers four types of authorization grants to accommodate different situations:
- Authorization code grant: The most complete and versatile mode, suitable for most application types. More details below.
- Authorization code grant: The most complete and versatile mode, suitable for most application types. More details below.
- Resource owner password credentials grant: Used when users trust a third-party application with their credentials, such as a trusted mobile app.
- Client credentials grant: Suitable for cases without a frontend, like command-line tools or server-to-server communication, where resource owner interaction is not needed.
The standard provides multiple modes to cater to different application scenarios and requirements, ensuring flexibility and adaptability for diverse situations.
The authorization code grant is one example worth examining. The specifications for the other three grant types are available in RFC-6749.

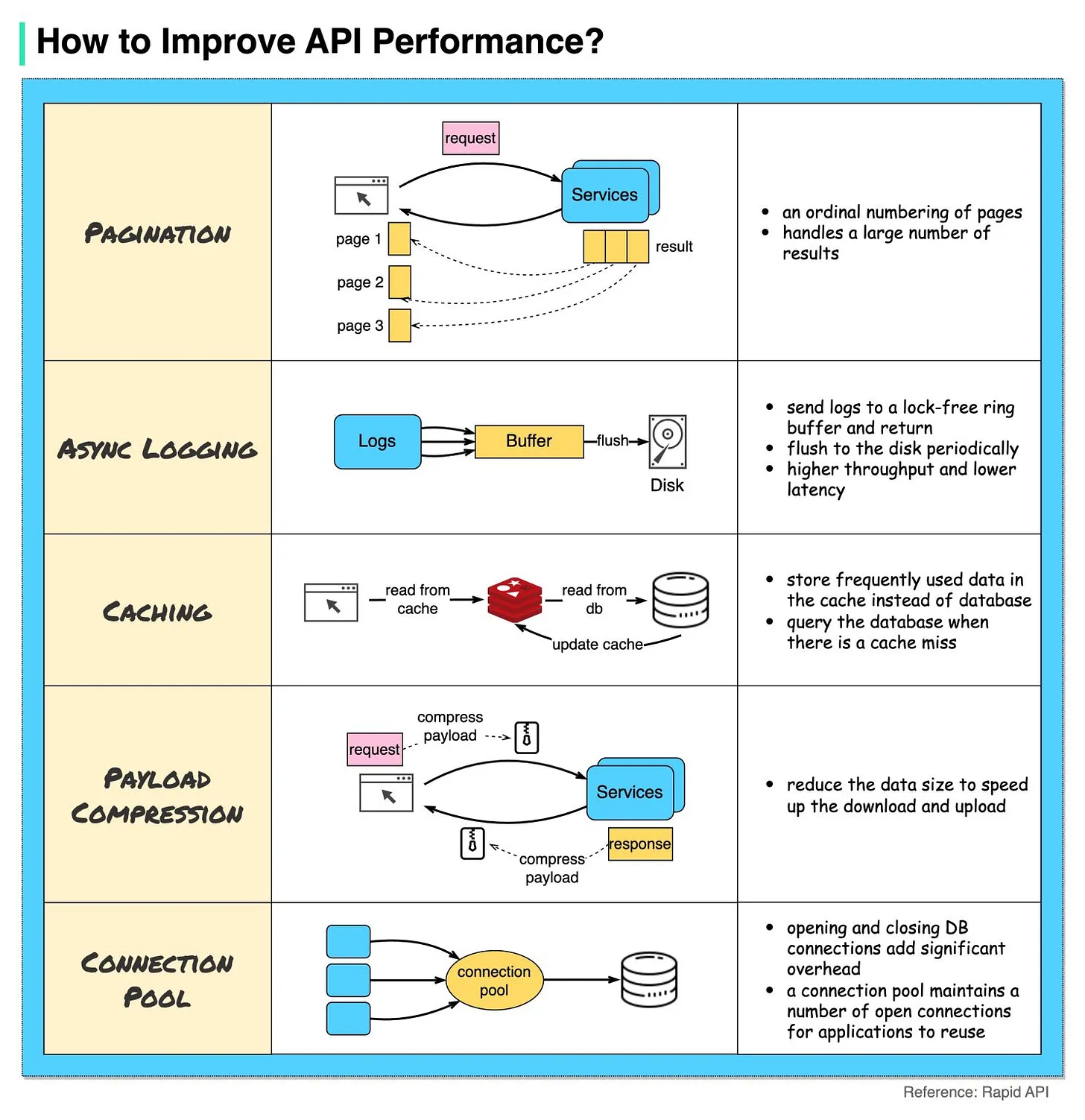
- Pagination This is a common optimization when the size of the result is large. The results are streaming back to the client to improve the service responsiveness.
- Asynchronous Logging Synchronous logging deals with the disk for every call and can slow down the system. Asynchronous logging sends logs to a lock-free buffer first and immediately returns. The logs will be flushed to the disk periodically. This significantly reduces the I/O overhead.
- Caching We can cache frequently accessed data into a cache. The client can query the cache first instead of visiting the database directly. If there is a cache miss, the client can query from the database. Caches like Redis store data in memory, so the data access is much faster than the database.
- Payload Compression The requests and responses can be compressed using gzip etc so that the transmitted data size is much smaller. This speeds up the upload and download.
- Connection Pool When accessing resources, we often need to load data from the database. Opening the closing db connections add significant overhead. So we should connect to the db via a pool of open connections. The connection pool is responsible for managing the connection lifecycle.
Teams often employ various branching strategies for managing their code, such as Git flow, feature branches, and trunk-based development.



The payload is like the actual message or information you want to send. It could be your name, age, or any other data you want to share. It's also written in JSON format, so it's easy to understand and work with.
Now, the signature is what makes the JWT secure. It's like a special seal that only the sender knows how to create. The signature is created using a secret code, kind of like a password. This signature ensures that nobody can tamper with the contents of the JWT without the sender knowing about it.
When you want to send the JWT to a server, you put the header, payload, and signature inside the box. Then you send it over to the server. The server can easily read the header and payload to understand who you are and what you want to do.

-
Docker client : The docker client talks to the Docker daemon.
-
Docker host :The Docker daemon listens for Docker API requests and manages Docker objects such as images, containers, networks, and volumes.
-
Docker registry: A Docker registry stores Docker images. Docker Hub is a public registry that anyone can use.
-
Let’s take the “docker run” command as an example.
-
Docker pulls the image from the registry.
-
Docker creates a new container.
-
Docker allocates a read-write filesystem to the container.
-
Docker creates a network interface to connect the container to the default network.
-
Docker starts the container.

-
Web Server: Hosts websites and delivers web content to clients over the internet
-
Mail Server: Handles the sending, receiving, and routing of emails across networks
-
DNS Server: Translates domain names (like bytebytego. com) into IP addresses, enabling users to access websites by their human-readable names.
-
Proxy Server: An intermediary server that acts as a gateway between clients and other servers, providing additional security, performance optimization, and anonymity.
-
FTP Server: Facilitates the transfer of files between clients and servers over a network
-
Origin Server: Hosts central source of content that is cached and distributed to edge servers for faster delivery to end users.
- OAuth 2.0 OAuth 2.0 is an authorization framework that allows a user to grant third-party applications limited access to their resources (e.g., data) on a resource server without sharing their credentials with the application directly. It is primarily used for delegated authorization, enabling applications to access APIs on behalf of the user. OAuth 2.0 defines various grant types (authorization flows) like Authorization Code, Implicit, Client Credentials, and Resource Owner Password Credentials, each suitable for different use cases. It is not designed for authentication purposes but focuses on authorization and access control.
- OpenID Connect (OIDC): OpenID Connect is an authentication layer built on top of OAuth 2.0. It extends OAuth 2.0 by providing a standardized way for clients to verify the identity of end-users based on the authentication performed by an authorization server. In other words, OIDC enables applications to obtain information about the user (claims) and verify their identity during the authorization process. It uses JSON Web Tokens (JWTs) to represent identity information. OpenID Connect is commonly used for Single Sign-On (SSO) scenarios, allowing users to log in once and then access multiple applications without re-entering their credentials.
- Security Assertion Markup Language (SAML) SAML is an XML-based standard used for exchanging authentication and authorization data between identity providers (IdP) and service providers (SP). Unlike OAuth 2.0 and OIDC, SAML is primarily focused on Web Browser SSO and federated identity scenarios. In a typical SAML flow, the user requests access to a service provided by an SP. The SP then redirects the user to the IdP, where the user is authenticated. After successful authentication, the IdP generates a SAML assertion containing user attributes and signs it cryptographically. The user is then redirected back to the SP with the SAML assertion, and the SP uses it to verify the user's identity and grant access to the requested service.
-
JWT (JSON Web Token): JSON Web Token (JWT) is a compact and self-contained way to represent information between two parties. It is commonly used to transmit claims (payload) between the authentication server (identity provider) and the application (service provider) securely. A JWT consists of three parts, separated by dots ('.'): header, payload, and signature. The header typically contains information about the type of token and the signing algorithm used. The payload contains the claims, which are statements about an entity (usually the user) and additional metadata. The signature is created by combining the header, payload, and a secret key, which is used to verify the integrity and authenticity of the JWT.
-
JWK (JSON Web Key): JSON Web Key (JWK) is a JSON format that represents a cryptographic key used in various web security protocols, including JWT. JWK provides a standardized way to describe cryptographic keys, such as RSA, ECDSA, or HMAC keys, along with additional key metadata. This format is especially useful when multiple parties need to exchange or share public keys securely.
-
JWS (JSON Web Signature): JSON Web Signature (JWS) is a standard for signing data, typically used to secure JWTs. A JWS allows you to take a payload (e.g., the contents of a JWT) and produce a digital signature that ensures the integrity and authenticity of the data. The signature is generated using a cryptographic algorithm (e.g., HMAC, RSA, or ECDSA) and a secret key (for symmetric algorithms) or a private key (for asymmetric algorithms). The recipient of the JWS can then use the corresponding public key (for asymmetric algorithms) or the shared secret key (for symmetric algorithms) to verify the signature and ensure that the data has not been tampered with.
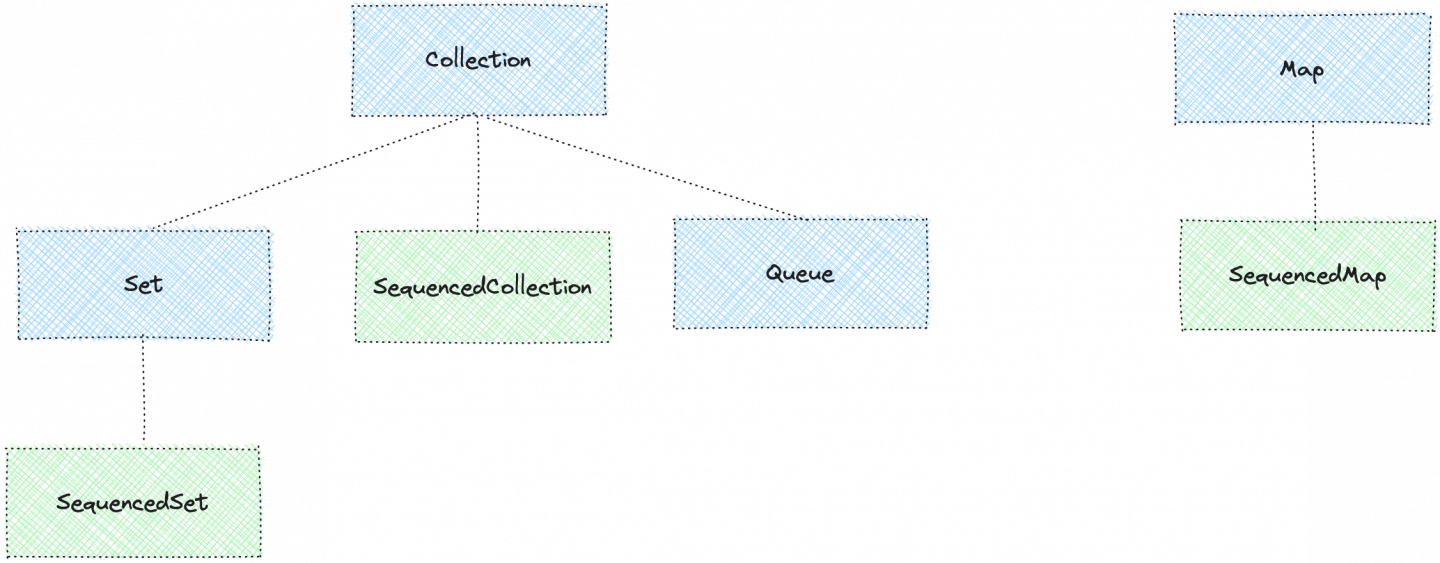
- Sequenced collections


- Cache A cache is an essential part of system. It provides a shortcut to access hot data and improves performance. A typical cache architecture has three layers:
- Application Cache: This sits inside the application's memory and is usually a hashmap holding frequently accessed data like user profiles. The cache size is small and data is lost when the app restarts.
- Second-level Cache: This is often an in-process or out-of-process cache like EhCache. It required configuring an eviction policy like LRU, LFU, or TTL-based eviction for automatic cache invalidation. The cache is local to each server.'
- Distributed Cache: This is usually Redis, deployed on separate servers from the application servers. Redis supports different eviction policies to control what data stays in the cache. The cache can be shared across multiple servers for horizontal scalability. The cache is shared across multiple apps. Redis offers persistence, replication for high availability, and a rich set of data structures.

- Session Store

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Validate the field
- fields required
- fields dropdown -> check exists
- fields default(0, 1 ; true, false)
- checking length fields as a number, string, array
- fields as array:
-
- check null or blank
-
- check duplicated
-
- with dropdown check exists
- Validate field as number(Number validation)
- check null
- check the field as a number
- check max, min
- check other
- Validate field as a string (String validation)
- check null or empty
- check length
- check regex
- Validate field as array (Array validation)
- check null or empty
- check length
- Validate field as an object (Object validation)
- check exists
- check contains properties
- Step by step to validate
- check exists if edit action
- check required field
- check length
- check existed field
- validate business
- Classpath Resource Loading:
Resource resource = new ClassPathResource("classpath:path/to/resource/file.txt");
InputStream inputStream = resource.getInputStream();
// Use the inputStream to read the contents of the resource- ServletContext Resource Loading
Resource resource = new ServletContextResource(servletContext, "/WEB-INF/resource/file.txt");
InputStream inputStream = resource.getInputStream();
// Use the inputStream to read the contents of the resource- File System Resource Loading
Resource resource = new FileSystemResource("/path/to/resource/file.txt");
InputStream inputStream = resource.getInputStream();
// Use the inputStream to read the contents of the resource- ResourceLoader Interface
@Autowired
private ResourceLoader resourceLoader;
Resource resource = resourceLoader.getResource("classpath:path/to/resource/file.txt");
InputStream inputStream = resource.getInputStream();
// Use the inputStream to read the contents of the resource- Using ResourceUtils
Resource resource = new ClassPathResource("classpath:path/to/resource/file.txt");
File file = ResourceUtils.getFile(resource.getURL());
// Now you can work with the File object directly- PropertiesLoaderUtils
Properties properties = PropertiesLoaderUtils.loadProperties(new ClassPathResource("classpath:config.properties"));- Thread
ClassLoader classLoader = Thread.currentThread().getContextClassLoader();
InputStream fileInputStream = classLoader.getResourceAsStream(template);- Using Paths and Files
Path path = Paths.get(ClassLoader.getSystemResource("file.txt").toURI());
List<String> lines = Files.readAllLines(path, StandardCharsets.UTF_8);
// Process the lines as neededRest(Representational State Transfer) and RPC(Remote Procedure Call) are two common architectural patterns used for communications in distributed systems. Rest is used for client-server (or server-server) communications, and RPC is used for server-server communications, as illustrated in the diagram below.

In a microservices architecture, an API gateway acts as a single entry point for client requests. The API gateway is responsible for request routing, composition, and protocol translation. It also provides additional features like,authentication, authorization, caching, and rate limiting.

- Step 1: The client sends an HTTP request to the API gateway.
- Step 2: The API gateway parses and validates the attributes in the HTTP request
- Step 3: The API gateway checks allow/deny lists.
- Step 4: The API gateway authenticates and authorizes through an identity provider.
- SteP 5: Rate-limiting rules are applied. Requests over the limit are rejected.
- Step 6 and 7: The API gateway routes the request to the relevant backend service by path matching.
- Step 8: The API gateway transforms the request into the appropriate protocol and forwards it to backend microservices.
- Step 9: The API gateway handles any errors that may arise during request processing for graceful degradation of service.
- Step 10: The API gateway implements resiliency patterns like circuit brakes to detect failures and prevent overloading interconnected services, avoiding cascading failures.
- Step 11: The API gateway utilizes observability tools like the ELK stack (Elastic Logstash KibanA) for logging, monitoring, tracing, and debugging.
- Step 12: The API gateway can optionally cache responses to common requests to improve responsiveness.
- Besides request routing, the API gateway can also aggregate responses from microservices into a single response for the client. The API gateway is different from a load balancer. While both handle network traffic, the API gateway operates at the application layer, mainly handling HTTP requests; the load balancer mostly operates at the transport layer, dealing with TCP/UDP protocols. The API gateway offers more functions as it sees the request payload. The API gateway differs from a load balancer in that it typically operates at the application layer to handle HTTP requests and understand message payloads, while traditional load balancers work at the transport layer to handle TCP/UDP connections without looking at the application data. However, the lines can blur between these two types of infrastructure. Some advanced load balancers are gaining application layer visibility and routing capabilities resembling API gateways. But in general, API gateways focus on application-level concerns like security, routing, composition, and resilience based on the payload, while traditional load balancers map requests to banked servers mainly based on transport-level metadata like IP and port numbers. We often have separate API gateways to handle requests from mobile architecture. We have different API gateways to handle requests from mobile devices and web applications because they have unique requirements for user experiences. Additionally, we separate WebSocket API Gateway because it has different connection persistence and rate-limiting requirements compared to HTTP gateways.
 Some recent API gateway trends:
Some recent API gateway trends: - GraphQL support. GraphQL is a type system and a query language for APIs. Many API gateways now offer integration with GraphQL
- Service Mesh integration. Service meshes like Istio and Linkerd are used to handle communications among microservices. API gateways are integrated with them to enhance traffic management capabilities.
- AI integration. API gateways are integrated with API capabilities to enable smarter request routing or anomaly detection in traffic patterns.
Authentication in Rest APis acts as the crucial gateway, ensuring that solely authorized users or applications gain access to the API's resources.
 Some popular authentication methods for REST APIs include:
Some popular authentication methods for REST APIs include:
- Base Authentication: Involves sending a username and password with each request, but can be less secure without encryption. When to use: Suitable for simple applications where security and encryption aren't the primary concern or when used over secured connections.
- Token Authentication: Uses generated tokens, like JSON Web Tokens (JWT), exchanged between client and server, offering enhanced security without sending login credentials with each request. When to use: Ideal for more secure and scalable systems, especially when avoiding sending login credentials with each request is a priority.
- OAuth Authentication: Enables third-party limited access to user resources without revealing credentials by issuing access tokens after user authentications. When to use: Ideal for scenarios requiring controlled access to use resources by third-party applications or services.
- API key Authentications: Assigns unique keys to users or applications, sent in header or parameters; while simple, it might lack the security features of token-based or OAuth methods. When to use: Convenient for straightforward access control in less sensitive environments or for granting access to certain functionalities without the need for user-specific permissions.
Symmetric encryption and asymmetric encryption are two types of cryptographic techniques used to secure data and communications, but they differ in their methods of encryption and decryption.

- In symmetric encryption, a single key is used for both encryption and decryption of data. It is faster and can be applied to bulk data encryption/decryption. For example, we can use it to encrypt massive amounts of PII(Personally Identifiable Information) data. It poses challenges in key management because the sender and receiver share the same key.
- Asymmetric encryption uses a pair of keys: a public key and a private key. The public key is freely distributed and used to encrypt data, while the private key is kept secret and used to decrypt the data, It is more secure than symmetric encryption is slower because of the complexity of key generation and maths computations. For example, HTTPS ares asymmetric encryption to exchange session keys during TLS handshake, and after that, HTTPS uses symmetric encryption for subsequent communications.
Redis is an in memory databases. If the server goes down. The data will lost Two ways to persist Redis data on disk:
- AOF (Append-Only File)
- RDB (Redis database)

- OAF: Unlike a write-ahead log, the Redis AOF log is a write-after log. Redis executes commands to modify the data in memory firts and then writes it to the log file. AOF log records the commands instead of the data. The event-based design simplifies data recovery. Additionally, AOF records commands after the command has been executed in memory, so it does not block the current write operation.
- RDB: The restriction of AOF is that it persists commands instead of data. When we use the AOF log for recovery, the whole log must be scanned. When the size of the log is large, Redis takes a long time to recover. So Redis provides another way to persist data
31. Handling multiple requests to a server in the backend involves various strategies to manage and process incoming requests efficiently.
- Concurrency and Parallelism:
- Concurrency: Manage multiple tasks simultaneously by switching between them.
- Parallelism: Execute multiple tasks simultaneously, using multiple threads or processes.
- Threading and Asynchronous Processing:
- Threads: Use multiple threads to handle different requests concurrently.
- Asynchronous Processing: Employ asynchronous programming techniques to handle requests without blocking resources. This can be achieved with libraries like asyncio in Python, async/await in JavaScript, or async/await in C#.
- Connection Pooling:
- Reuse existing connections to handle incoming requests rather than creating new connections for each request, reducing overhead.
- Load Balancing:
- Distribute incoming requests across multiple servers or resources to balance the load and prevent overload on a single server.
- Caching:
- Cache frequently requested data or responses to serve them quickly without reprocessing.
- Optimizing Database Queries:
- Optimize database queries to reduce the time spent on fetching or updating data.
- Rate Limiting and Queuing:
- Implement rate limiting to prevent overwhelming the server with too many requests at once.
- Use queues to manage requests when the server is busy and process them in a controlled manner.
- Optimizing Server Configuration:
- Tune server settings such as timeouts, buffer sizes, and connection limits to handle multiple requests efficiently.
- Monitoring and Scaling:
- Monitor server performance and scale resources (horizontal or vertical scaling) based on demand to maintain optimal performance.
- Error Handling and Retry Mechanisms:
- Implement robust error handling strategies and retry mechanisms for failed requests to ensure reliability.
- S = Single Responsibility Principle (SRP) Single Responsibility Principle(SRP) is one of the five S.O.L.I.D principles, which states the each class should have only one responsibility, in order to preserve meaningful separation of concerns. This pattern is a solution to a common anti-pattern called "The God Object" which simply refers to a class or object that holds too many responsibilities, making it difficult to understand, test and maintain.
- O = Open-Closed Principle(OCP)
Software enitites should be open for extension but closed for modificationThe Open-Closed Principle (OCP) is all about "write it once, write it well enough to be extensible and forget about it". The importance of this principle relies on the fact that a module may change from time to time based on new requirement. In case the new requirement arrive after the module was written, tested and uploaded to production, modifying this module is usually bad practice, especially when other modules depend on it. In order to prevent this situation, we can use the Open-Closed Principle. - L = Liskov Substitution Principle (LSP) The Liskov's Substitution Principle (LSP) is an important
- Making everything public When you get dropped into a Spring Boot project you have free rein to organize your project however you want. This is great because it allows you to put your code wherever you want. However, a lot of us follow a convention where we use a package by layer architecture. This cause code that is closely related to be split into different packages and therefore having to make everything public which is not how we would typically write code.
- Package by layer : Domain -> Controller -> Service -> Repository -> Configuration
- Package by feature: Product, customer, order, cart
- Field Injection A common mistake is choosing field injection for Dependency Injection. There are a number of reasons that you should favor constructor injection over field injection.
- Interface and implementation when not necessary There is a right place and a right time to create interfaces but in this common mistake we take a look at a time where it doesn't make a lot of sense.
- Proper Rest API Design Spring Boot gives you the tools to quickly and easily stand up a REST API. A common mistake I often see is creating REST resources with improperr URIs. When you create a Rest resources the request method should describe the intention, not the URI.
- Improper Exception Handling When a user expects a response and none is give that isn't a good experience. It's better to return something and in the case of asking for a resource by an invalid id it's often good practice to handle that exception.
34. Event-Driven Architecture (EDA) is a design pattern used in software development that emphasizes(nhấn mạnh) the production, detection, consumption(tiêu thụ), and reaction to events. Events, in this context, are notable(đáng chú ý) occurrences(lần xuất hiện) or changes in state that happen within a system. Event-Driven Architecture is wideky in various applications, ranging from simple systems to complex distributed systems. Here are key concepts to understand:
- Events:
- An event is a significant change or occurrence in the system. It could be a state change a user action, or an external trigger.
- Examples of events include a button click in a user interface, a sensor reading in an IOT device, or a database record update.
- Publishers and Subscribers:
- In an event-driven system, there are typically two main components: publishers and subscribers.
Publishersare responsible for producing events. When a notable action occurs, the publisher emits(publishes) an event.Subscribersare components or services that are interested in certain types of events. They subscribe to receive notifications when specific events occur.
- Event bus and message broker:
- Events are often communicated between publishers and subscribers through an event bus or a message broker.
- An event bus is communication channel that facilitates the flow of events between components. It can be implemented as a simple in-memory data structure or a more robus message broker system.
- Decoupling:
- One of the main advantages of EDA is decoupling. Publishers and subscribers are loosely connected, meaning they don't need to be aware of each other's existence. This makes the system more modular and scalable.
- Asynchronous Processing:
- EDA often involves asynchronous communication. When an event is published, subscribers are notified asynchronously, meaning they can process the event independently of the publisher.
- Event sourcing:
- Event sourcing is a related concept where the state of a system is determined by a sequence of events. Instead of storing the current state of an entity, you store the sequence of events that led to the current state.
- Scalability:
- Event-driven architecture is well-suited for scalable and distributed systems. Components can operate independently, and new components can be added without disrupting the existing ones.
- Fault Tolerance(Sức chịu đựng):
- EDA can contribute to fault tolerance. If a component fails, events can be replayed or processed by other components without losing critical information.
- Real-time Processing:
- EDA is often associated with real-time or near-real-time processing because events are processed as they occur.
- Use cases:
- Event-Driven Architecture is commonly used in various domains, including financial systems, e-commerce, IoT applications, and microservices architectures.
- Method 1: Validation Customer payments transactions are recorded in a table called payment. Structure of the table looks like.
CREATE TABLE `payments` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`order_id` varchar(50) NOT NULL DEFAULT '',
`status` varchar(10) NOT NULL DEFAULT '',
`amount` decimal DEFAULT NULL,
`transaction_id` varchar(50) DEFAULT NULL,
`gateway_response` json DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;Each time get a response or callback from the payment gateway, query the DB to check if there is an existsing transaction for the same user with simmilar "order_id"
SELECT * from payments where user_id = ? and order_id = ?;Pseudocode for the payment validation:
var payment = getPayment(userId, orderId);
if (payment) {
print 'Payment already exists!. Must be duplicate payment'
throw Error('duplicate') or return;
}
// else
var newPayment = createPayment(userId, reqParams)The problem with this method is that, when we are swamped with concurrent request with the same payload in a matter of seconds, we still can not a void duplication. Because it takes time to query and get the response from DB and during that period, we could have created multiple payment records already. 2. Method 2: Locking It is a very interesting mechanism that certainly could be applied in many cases not just dealing with concurrent requests. Implementation is quite similar to the above method, however, instead of DB, we could choose to implement this in in-memory data stores such as Redis
// make a unique reference key for each payment transaction
var paymentKey = 'PAYMENT' + user_id + order_id
var payment = getPayment(paymentKey) // assume that this method calls redis or any other in-memory store to get the key
if (payment) {
print 'Payment already exists!. Must be duplicate payment'
throw Error('duplicate') or return;
}
setPayment(paymentKey) // assume that this methods sets the new payment reference in in-memory
var newPayment = createPayment(userId, reqParams)From the above pseudocode, when we get the first request, we set the reference in in-memory and create the payment record. And for the subsequent payment records for the same transaction we ignore them. Unfortunately, even with this method, a query to in-memory was slow enough to record multiple payment records and still could not a void duplicates. Here are few interesting articles regarding locking mechanisms to explore.
- Method 3: Queuing his could be a more reliable method and gives more flexibility for the application to deal with concurrent requests.
The idea here is to queue all the incoming requests into a queue and deal with them slowly using a consumer and validate each incoming request to make sure we capture only one request. 4. Database table with composite UNIQUE constrain In this method, we design the payments table with a composite unique key that ensures us to have a unique record for each request.
CREATE TABLE `payments` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`order_id` varchar(50) NOT NULL DEFAULT '',
`status` varchar(10) NOT NULL DEFAULT '',
`amount` decimal DEFAULT NULL,
`transaction_id` varchar(50) DEFAULT NULL,
`gateway_response` json DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unique_payment_transaction` (`user_id`,`order_id`,`status`),
KEY `user_id` (`user_id`),
KEY `order_id` (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;