MTG Card Detector is a real-time application that can identify Magic: The Gathering playing cards from either an image or a video. It utilizes various computer vision techniques to process the input image, and uses perceptual hashing to identify the detected image of the cards with the matching cards from the database of MTG cards. Refer to opencv_dnn.py for more detailed implementation.
Demo:
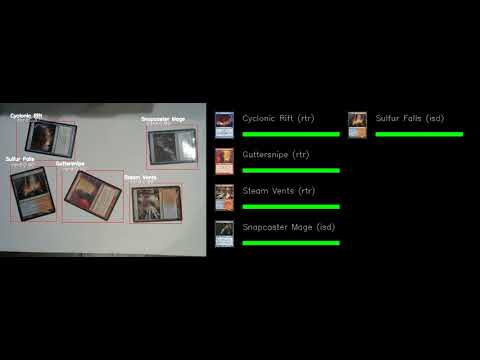
You can run the demo using the following:
python3 opencv_dnn.py [-i path/to/input/file -o path/to/output/directory -hs (one of 16/32) -dsp -dbg -gph]
Initially, the project used a powerful neural network named 'You Only Look Once (YOLO)' to detect individual cards, but it has been removed as of Oct 12th, 2018 (note) in favour of classical CV techniques.
Demo:

You can still find the files used to train them:
- tiny_yolo.cfg
- tiny_yolo_final.weights
- obj.data and obj.names
- fetch_data.py: aggregates card images and database from scryfall.com
- transform_data.py: generate training images using the aggregated card images and database
- setup_train.py: create train.txt and test.txt required to train YOLO from the training dataset
Uploading all the progresses on the model training for the last few days.
First batch of model training is completed, where I used ~40,000 generated images of MTG cards laid out in one of the pre-defined pattern.



After 5000 training epochs, the model got 88% validation accuracy on the generated test set.




However, there are some blind spots on the model, notably:
- Fails to spot some of the obscured cards, where only a fraction of them are shown.
- Fairly fragile against any glaring or light variations.
- Cannot detect any skewed cards.
Example of bad detections:



The second and third problems should easily be solved by further augmenting the dataset with random lighting and image skew. I'll have to think more about the first problem, though.
Added several image augmentation techniques to apply to the training set: noise, dropout, light variation, and glaring:




Currently trying to generate enough images to start model training. Hopefully this helps.
Recompiled darknet with OpenCV and CUDNN installed, and recalculated anchors.
I've ran a quick training with tiny_yolo configuration with new training data, and Voila! The model performs significantly better than the last iteration, even against some hard images with glaring & skew! The first prediction model can't detect anything from these new test images, so this is a huge improvement to the model :)







The video demo can be found here: https://www.youtube.com/watch?v=kFE_k-mWo2A&feature=youtu.be
I've been training a new model with a full YOLOv3 configuration (previous one used Tiny YOLOv3), and it's been taking a lot more resources:

The author of darknet did mention that full network will take significantly more training effort, so I'll just have to wait. At this rate, it should reach 50k epoch in about a week :/
The training for full YOLOv3 model has turned sour - the loss saturated around 0.45, and didn't seem like it would improve in any reasonable amount of time.

As expected, the performance of the model with 0.45 loss was fairly bad. Not to mention that it's quite slower, too. I've decided to continue with tiny YOLOv3 weights. I tried to train it further, but it was already saturated, and was the best it could get.
Bad news, I couldn't find any repo that has python wrapper for darknet to pursue this project further. There is a python example in the original repo of this fork, but it doesn't support video input. Other darknet repos are in the same situation.
I suppose there is a poor man's alternative - feed individual frames from the video into the detection script for image. I'll have to give it a shot.
Thankfully, OpenCV had an implementation for DNN, which supports YOLO as well. They have done quite an amazing job, and the speed isn't too bad, either. I can score about 20~25fps on my tiny YOLO, without using GPU.
I tried to do an alternate approach - instead of making model identify cards as annonymous, train the model for EVERY single card. As you may imagine, this isn't sustainable for 10000+ different cards that exists in MTG, but I thought it would be reasonable for classifying 10 different cards.
Result? Suprisingly effective.




They're of course slightly worse than annonymous detection and impractical for any large number of cardbase, but it was an interesting approach.
I've made a quick openCV algorithm to extract cards from the image, and it works decently well:

At the moment, it's fairly limited - the entire card must be shown without obstruction nor cropping, otherwise it won't detect at all.
Unfortunately, there is very little use case for my trained network in this algorithm. It's just using contour detection and perceptual hashing to match the card.
I've tweaked the openCV algorithm from yesterday and ran for a demo:
https://www.youtube.com/watch?v=BZkRZDyhMRE&feature=youtu.be
With the current model I have, there seems to be little hope - I simply don't have enough knowledge in classical CV technique to separate overlaying cards. Even if I could, perceptual hash will be harder to use if I were to use only a fraction of a card image to classify it.
There is an alternative to venture into instance segmentation with mask R-CNN, at the cost of losing real-time processing speed (and considerably more development time). Maybe worth a shot, although I'd have to nearly start from scratch (other than training data generation).
I've been trying to fiddle with the mask R-CNN using this repo's implementation, and got to train them with 60 manually labelled image set. The result is not too bad considering such a small dataset was used. However, there was a high FP rate overall (again, probably because of small dataset and the simplistic features of cards).





Although it may be worth to generate large training dataset and train the model more thoroughly, I'm being short on time, as there are other priorities to do. I may revisit this later. I will be cleaning this repo in the next few days, wrapping it up for now.
I've been able to significantly cut down the processing time of the current implementation. For n cards detected in the video, the latency has decreased from (65+50n)ms to (7+16n)ms. There were two major bottlenecks that was slowing the program down:
In order to identify the card from the snippet of the card image, I'm using perceptual hashing. When the card is detected in YOLO, I compute its pHash value from its image, and compare it with the pHash of every cards in the database to find the match. This process has a speed of O(n * m), where n is the number of cards detected in the image and m is the number of cards in the database. With more than 10000 different cards printed in MTG history, this computation was the first bottleneck. For the 50ms increment per detected card mentioned above, majority of that time was spent trying to subtract two 1024-bit hashes 10000+ times - that's more than 10^10 comparisons right there!
First, there were some overhead that was coming from the implementation of the library. The following is the elapsed time for subtracting pHash for all 10000 elements in pandas database:
| hash_size | elapsed_time (ms) |
|---|---|
| 8 | 23.01 |
| 16 | 25.72 |
| 32 | 33.38 |
| 64 | 65.98 |
If you plot them using (hash_size)^2 and elapsed_time, you get almost a linear graph with a huge constant y-intercept:

Where is this fat constant of 22.4ms coming from? Well, we'd better look at how the Imagehash library deals with subtraction:
def __sub__(self, other):
if other is None:
raise TypeError('Other hash must not be None.')
if self.hash.size != other.hash.size:
raise TypeError('ImageHashes must be of the same shape.', self.hash.shape, other.hash.shape)
return numpy.count_nonzero(self.hash.flatten() != other.hash.flatten())
The code flattens both hashes before comparison. You might think, "How slow is that going to be?" Apparently fair amount.
a = np.ones([1, 1024], dtype=np.bool)
start = time.time()
for _ in range(10000):
if a is None:
raise TypeError('Other hash must not be None.')
if a.size != a.size:
raise TypeError('ImageHashes must be of the same shape.', self.hash.shape, other.hash.shape)
a.flatten()
a.flatten()
end = time.time()
elapsed = (end - start) * 1000
print('%f' % elapsed)
The execution time of that code snippet on average is 11.65ms, which is slightly over half of 22.4ms of constant delay. That's a lot of time that can be cut out. By pre-emptively flattening the hashes and using the hash subtraction's code (yes I know it's not a good OOP design, but this is too much of a tradeoff), that constant time can be cut out significantly:
| hash_size | elapsed_time (ms) |
|---|---|
| 8 | 9.9 |
| 16 | 11.54 |
| 32 | 18.55 |
| 64 | 45.79 |
Furthermore, turns out that hash size of 16 is sufficient enough to distinguish each cards in most of the case. Halving the hash size further knocked down 7-9ms, as you only need to compare about quarter of the bits compared to hash size of 32.
The other bottleneck is a something unfortunate. Turns out feeding the image through YOLO network consumes a constant 50 - 60ms per frame. Remember the processing time of (65+50)ms above? Yeah, that's where the 65ms is coming from.
As hilarious and ironic it is, I would have to remove the network entirely to speed up the program... (((Facepalm into another dimension))) The program still works by replacing neural net with contour detection
Cleaning up everything to wrap up this project for now. If I can figure out how to move from bounding boxes of overlapping cards (notes), I may come back to upgrade the project in the future. If you have any suggestion regarding this issue, please don't hesitate to let me know.
Thank you for reading all the way up to here. Hope this project has helped you in some way.