{kind=link}
DBRdashboard is an automated AWS detailed billing record analyzer. You can use it to produce dashboards on your AWS spend and reserved instance utilization. Graphs are updated as frequently as AWS updates the DBR files themselves (multiple times per day).
DBRdashboard queries the detailed billing record using AWS Athena. The queries and metrics that it produces are completely customizable to your own needs and requirements.
Currently the system relies on Cloudwatch to produce the dashboards (dashboard setup is a manual setup step). With small code modifications any metrics / dashboard system could be utilized.
In addition, the system also maintains a set of AWS Athena tables for you - to query your detailed billing record as you wish. A table per month is created and kept upto date as new billing data is added to the underlying DBR CSV file.
AWS publishes detail billing reports periodically during the day. These reports contain very detailed line-by-line billing details for every AWS charge.
DBRdashboard periodically spins up a EC2 instance that checks and converts these CSV based reports into parquet format files (for performance purposes) and re-uploads these converted files to S3. It then utilizes AWS Athena and standard SQL to create database tables and query specific billing metrics within them. The results of the queries are then reported to AWS Cloudwatch as custom metrics.
Once the metrics are in Cloudwatch, it is then very easy to produce graphs and create a billing dashboard customized to your exact requirements.
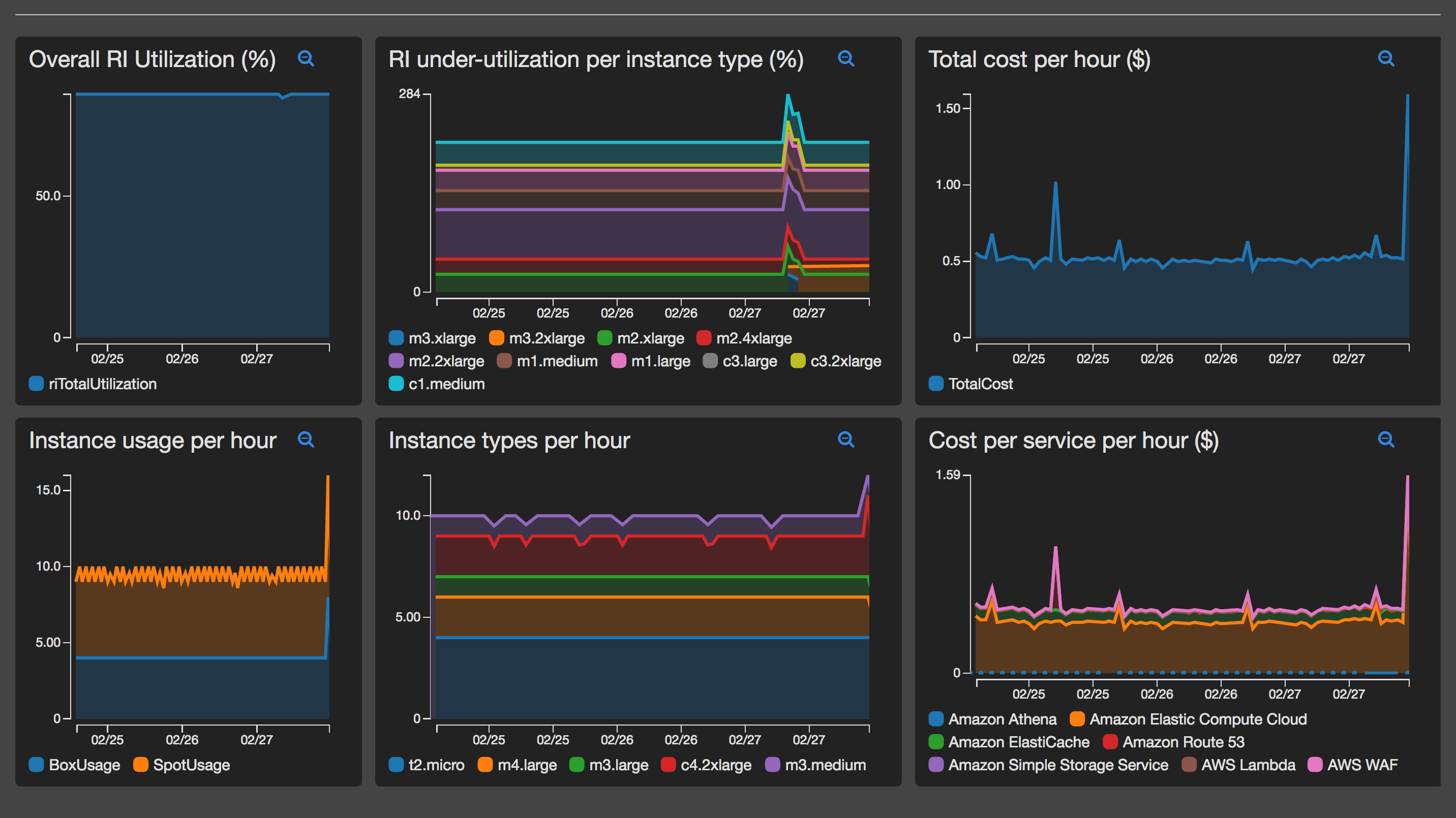
In addition to querying the detailed billing report. DBRdashboard also queries any reserved instances on the account and then correlates them against actual usage to generate utilization metrics. Overall utilization and per instance type under-utilization metrics are available.
Setup of DBR dashboard should take ~15 minutes if detailed billing records are already enabled.
NOTE: DBR Dashboard can only be spun-up in us-east-1 or us-west-2 AWS regions as of now.
If you have not already, turn on detailed billing records in your AWS account, configure and specify a DBR S3 bucket as per the instructions here (Look under section "To turn on detailed billing reports").
Fork this GIT repo.
The EC2 instance itself will bootstrap itself by cloning a configurable GIT repo and then run scripts and custom binaries to generate and upload the custom metrics. This custom binary utilizes a configuration file which will need to be edited to enable/disable certain functionality and customize the metrics and queries that are run.
Therefore, forking this repo allow you to commit configuration modifications which will automatically come into effect the next time the EC2 instance spins up.
Using cloudformation bring up both stacks that are within the cf directory in your newly forked repo.
The network stack create's exports which are then referenced by the app stack. To be able to keep multiple stacks operational a ResourcePrefix is used which is pre-pended to the exports. The ResourcePrefix can be any text string but must be identical across both stacks.
dbr_network.yaml is a CF template that will setup the VPC and general networking required. It is recomended to use a small CIDR block, as DBRdownload will only ever spin-up a single EC2 instance.
dbr_app.yaml is a CF template that sets up the required IAM role, Athena user as well as a auto-scale group with a configured time-based scale up policy. It is recommended to configure the schedule parameter to ~ 4-6 hours, as this is roughly how often the original DBR CSV file is updated by AWS.
Ensure you specify the GIT clone URL for your own repo. This will allow you to push configuration (or code) changes which will then be automatically picked up for the next time the EC2 instance spins up.
Once this is configured you will need to wait for the first auto-scale spin-up to occur. To speed this up, you could also manually set the desired capacity of the ASG to 1 so that an instance automatically spins up. Its safe to leave this up and running as it will be shutdown automatically by the automatic schedule before the end of the hour.
Once the instance has spun up it will bootstrap itself and run the code to generate the custom metrics. These should start to appear in Cloudwatch, typically these appear within 15 minutes of the instance coming up.
Using the custom metrics, generate graphs that you would like and start creating your very own DBRdashboard. Instructions on creating a Cloudwatch dashboard can be viewed here
DBRdashboard attempts to provide significant valuable insight to your overall costs with very little actual cost-overhead.
To this point DBRdashboard uses the following AWS services, with these approx costs
| AWS Service | Description | Expected Cost |
|---|---|---|
| EC2 Spot | Small m1 or m3 instances are used. | ~ 2c / hour, $2.50 / month* |
| Auto Scale | Incl scheduled scaling | Free |
| S3 | Storage costs depends on size of DBR | ~ 10c / month |
| Athena | Costs vary per query and size of DBR | ~ 50c / month |
| Cloudwatch | Costs depend on number of metrics** | $10 - $20 / month |
| **Expected Total** | $15 - $35 / month
* Based on schedule of 6 hours, instance running for 4 hours per day
** Cloudwatch custom metrics are 30c per metric per month over first free 10 metrics. Dashboard is $5 per month if it contains over 50 metrics.
Configuration for DBRdashboard is performed by editing the configuration file analyzeDBR.config this file is passed into the binary snalyzeDBR as a command line option.
The configuration file is in the TOML format and has a number of sections which are described below.
You can choose to edit this file in place (within your forked repo) or to create a new configuration file. In which case you will need to alter the file run.sh - look for the line that contains:
./bin/analyzeDBR -config ./analyzeDBR.config -key $4 -secret $5 -region $3 -account $2 -bucket $1 -date $(date +%Y%m) -blended=$DBR_BLENDED
Change the --config parameter to be the new configuration filename you have created.
These options are held within the [general] TOML section
| Option Name | Description | Default Value |
|---|---|---|
namespace |
The Cloudwatch namespace used for all metrics | DBR |
| Option Name | Description | Default Value |
|---|---|---|
enableRIanalysis |
Determines if DBRdashboard outputs RI metrics or not | true |
enableRITotalUtilization |
Determines if a "total" RI % utilization figure is generated or not | true |
riPercentageThreshold |
Determines the low boundary or % utilization not to report on (i.e. to ignore) | 5 |
riTotalThreshold |
Determines the low boundary of "number of RI's" not to report on (i.e. ignore instance types that have less than X total RIs) | 5 |
cwNameTotal |
Cloudwatch metric name for total utilization % | riTotalUtilization |
cwName |
Cloudwatch metric name for instance level under-utilization % | riUnderUtilization |
cwDimensionTotal |
Cloudwatch default total utilization dimension name | total |
cwDimension |
Cloudwatch default instance level dimension name | instance |
cwType |
Cloudwatch "type" for RI metrics | percentage |
sql |
Athena SQL query used to retrieve RI instance usage hours | see config file |
ri.ignore |
TOML map of instances that are ignored when calculating % under-utilization | see config file |
Each DBR metric is held within a TOML array in the configuration file. This array is iterated over to query Athena and then send the results as metrics to Cloudwatch.
To add new metrics simply copy-and-paste an existing [[metric]] entry and then modify the various attributes, which are
| Metric Attribute | Description |
|---|---|
enabled |
Determines if the metric is used or not |
type |
Reserved for future use. value of dimension-per-row is only accepted value currently |
cwName |
The metric name that will be sent to Cloudwatch |
cwDimension |
The dimension name that will be sent to Cloudwatch (the value of the dimension will be taken from the "dimension" row value (see below) |
cwType |
The cloudwatch metric type that will be sent to cloudwatch |
sql |
The SQL that will be executed on the Athena DBR table to fetch the metric information (see below) |
Each metric that you wish to display on the dashboard is obtained by querying the DBR Athena table. Each row that is returned is considered a new metric value. The date column is used as the time-series "divider" and is converted to a timestamp which is sent for this row.
Default useful metrics are pre-configured within the original configuration file. These can be disabled if required or even completely removed. New metrics can be added as described above.
Effectively if you can write SQL that fetches the data you need it can be turned into a metric and graphed on cloudwatch, no custom-coding required.
Each row in the query results MUST contain the following aliased columns
| Column Name | Description |
|---|---|
date |
the timeperiod for the metric. Typically the hour (format YYYY-MM-DD HH) or day |
value |
The metric value for this time period (normally a count(*) in SQL |
dimension |
The dimension value that will be sent for this row. |
For example if a query returns a row with
date |
dimension |
value |
|---|---|---|
| 2017-02-01 17 | m3.xlarge | 50 |
Then a custom metric (named using the cwName parameter) will be sent to Cloudwatch as follows:
- The timestamp will be set to
2017-02-01 17:00:00 - The dimension name will be set to the parameter value
cwDimension - The dimension value will be set to
m3.xlarge - The value will be set to
50
Every row returned will send a metric using put-metric-data
Note. Athena uses Presto under-the-hood. Hence all Presto SQL functions are available for you to utilize. These can be found here.
- Only RI's under the "running" account are fetched and used to generate % RI utilization. If RI's exist under linked accounts they are not currently included and will cause incorrect results. Temporary work around for this is to move all RI's into the payer account if possible.
- Add Cloudwatch Logs support so that the code logs into cloudwatch
- Add configuration to fetch RI data from multiple linked accounts. This will require additional permissions across all accounts to be able to make the API call.
- Document process for multi-dimension metrics (code supports it, just need to document)
- Modify code to not store user key/secret in ASG user-data and potentially use KMS instead. Hopefully support for Athena to use IAM roles will make this un-necessary