This is now deployed under the https://redten.io cloud service for analyzing datasets.
Sci-Pype is a framework for analyzing datasets using Python 2.7 and extended from the Jupyter Scipy-Notebook with a supported command line version (no docker or Jupyter required). It was built to make data analysis easier by providing an API to build, train, test, predict, validate, analyze, extract, archive, and import Models and Analysis datasets with: S3 and redis (Kafka coming soon). After building and training the requested Models with a dataset, they are cached in redis along with their respective Analysis. After they are cached, they can be extracted and shared using S3. From S3, the Models can be imported back into redis for making new predictions using the same API.

Analyzing the IRIS dataset with Sci-Pype
Common use cases for this framework are sharing Analysis notebooks and then automating new predictions with email delivery using AWS SES. With this native caching + deployment layer, you can build, train and use the supported Machine Learning Algorithms and Models across multiple environments (including multi-tenant ones). Once trained, you can extract the Models as a compressed, serialized Model file (like a build artifact) that is uploaded to S3. Importing a Model file decompresses the file and stores the Pickle-serialized Models + Analysis objects in redis. In production, it might be useful to house larger Models in something like a load-balanced redis cluster for sharing and making new predictions across a team or by automation.
Please note this is a large docker container so it may take some time to download and it extracts to ~8.1 GB on disk.
Please refer to the examples directory for the latest notebooks. Most of the notebooks and command line tools require running with a redis server listening on port 6000 (<repo base dir>/dev-start.sh will start one).
ML-IRIS-Analysis-Workflow-Classification.ipynb
Build a unique Machine Learning Classifier (parameterized XGB by default) for each column in the IRIS dataset. After training and testing the Models, perform a general analysis on each column and save + display images generated during each step. After running, the Models + Analysis are Pickled into a set of objects stored in a set of unique redis cache keys. These leaf nodes are organized into a set of redis keys contained in the
manifestnode for retrieval as needed in the future (like a tree of Machine Learning Algorithm Models with their associated pre-computed Analysis in memory).ML-IRIS-Analysis-Workflow-Regression.ipynb
Build a unique Machine Learning Regressor (parameterized XGB by default) for each column in the IRIS dataset. After training and testing the Models, perform a general analysis on each column and save + display images generated during each step. After running, the Models + Analysis are Pickled into a set of objects stored in a set of unique redis cache keys. These leaf nodes are organized into a set of redis keys contained in the
manifestnode for retrieval as needed in the future (like a tree of Machine Learning Algorithm Models with their associated pre-computed Analysis in memory).ML-IRIS-Extract-Models-From-Cache.ipynb
Extract all Models and Analysis records from redis and compile a large Pickle-serialized dictionary. Create a
manifestfor decoupling Model + Analysis nodes and compress the dictionary object (using zlib) and write it to disk as aModel file(*.cache.pickle.zlib). After creating the file on disk, upload it to the configured S3 Bucket and Key.Once uploaded to the S3 Bucket you should be able to view, download and share the
Model files:
S3 Bucket containing the IRIS
Model FilesML-IRIS-Import-and-Cache-Models-From-S3.ipynb
Download the S3 IRIS
Model filefrom the configured S3 Bucket + Key and decompress the previously-built Analysis and Models using Pickle to store them all in the redis cache according to themanifest. This includes examples from the IRIS sample dataset and requires you to have a valid S3 Bucket storing the Models and are comfortable paying for the download costs to retrieve theModel filefrom S3 (https://aws.amazon.com/s3/pricing/).ML-IRIS-Predict-From-Cache-for-New-Predictions-and-Analysis-Classifier.ipynb
This notebook shows how to make new predictions with cached IRIS Classifier Models + Analysis housed in redis.
ML-IRIS-Predict-From-Cache-for-New-Predictions-and-Analysis-Regressor.ipynb
This notebook shows how to make new predictions with cached IRIS Regressor Models + Analysis housed in redis.

Most of the notebooks and command line tools require running with a redis server listening on port 6000 (<repo base dir>/dev-start.sh will start one). The command line versions that do not require docker or Jupyter can be found:
<repo base dir> ├── bins │ ├── demo-running-locally.py - Simple validate env is working test │ ├── ml │ │ ├── builders - Build and Train Models then Analyze Predictions without display any plotted images (automation examples) │ │ │ ├── build-classifier-iris.py │ │ │ ├── build-regressor-iris.py │ │ │ ├── rl-build-regressor-iris.py │ │ │ └── secure-rl-build-regressor-iris.py │ │ ├── demo-ml-classifier-iris.py - Command line version of: ML-IRIS-Analysis-Workflow-Classification.ipynb │ │ ├── demo-ml-regressor-iris.py - Command line version of: ML-IRIS-Analysis-Workflow-Regression.ipynb │ │ ├── demo-rl-regressor-iris.py - Command line version of: ML-IRIS-Redis-Labs-Cache-XGB-Regressors.ipynb │ │ ├── demo-secure-ml-regressor-iris.py - Demo with a Password-Required Redis Server running locally │ │ ├── demo-secure-rl-regressor-iris.py - Demo with a Password-Required Redis Labs Cloud endpoint │ │ ├── downloaders │ │ │ ├── download_boston_house_prices.py │ │ │ └── download_iris.py - Command line tool for downloading + preparing the IRIS dataset │ │ ├── extractors │ │ │ ├── extract_and_upload_iris_classifier.py - Command line version of: ML-IRIS-Extract-Models-From-Cache.ipynb (Classifier) │ │ │ ├── extract_and_upload_iris_regressor.py - Command line version of: ML-IRIS-Extract-Models-From-Cache.ipynb (Regressor) │ │ │ ├── rl_extract_and_upload_iris_regressor.py - Command line version of: ML-IRIS-Redis-Labs-Extract-From-Cache.ipynb │ │ │ └── secure_rl_extract_and_upload_iris_regressor.py - Command line version with a password for: ML-IRIS-Redis-Labs-Extract-From-Cache.ipynb │ │ ├── importers │ │ │ ├── import_iris_classifier.py - ML-IRIS-Import-and-Cache-Models-From-S3.ipynb (Classifier) │ │ │ ├── import_iris_regressor.py - ML-IRIS-Import-and-Cache-Models-From-S3.ipynb (Regressor) │ │ │ ├── rl_import_iris_regressor.py - Command line version of: ML-IRIS-Redis-Labs-Import-From-S3.ipynb │ │ │ └── secure_rl_import_iris_regressor.py - Command line version with a password for: ML-IRIS-Redis-Labs-Import-From-S3.ipynb │ │ └── predictors │ │ ├── predict-from-cache-iris-classifier.py - ML-IRIS-Predict-From-Cache-for-New-Predictions-and-Analysis-Classifier.ipynb (Classifier) │ │ ├── predict-from-cache-iris-regressor.py - ML-IRIS-Predict-From-Cache-for-New-Predictions-and-Analysis-Regressor.ipynb (Regressor) │ │ ├── rl-predict-from-cache-iris-regressor.py - Command line version of: ML-IRIS-Redis-Labs-Predict-From-Cached-XGB.ipynb │ │ └── secure-rl-predict-from-cache-iris-regressor.py - Command line version with a password for: ML-IRIS-Redis-Labs-Predict-From-Cached-XGB.ipynb
Now you can share, test, and deploy Models and their respective Analysis from a file in S3 for other Sci-Pype users running on different environments.
The docker container runs a Jupyter web application. The web application runs Jupyter Notebooks as kernels. For now the examples and core included in this repository will only work with Python 2.
This container can run in four modes:
Default development
This mode will mount your changes from the repository into the container at runtime for local testing.
To start the local development version run: dev-start.sh
./dev-start.sh
You can login to the container with:
./ssh.shDocker Run Single Container
To start the local development version run: start.sh
./start.sh
You can login to the container with:
./ssh.shFull Stack
To start the full stack mode run: compose-start-full.sh
./compose-start-full.sh
The full-stack-compose.yml will deploy three docker containers using docker compose:
- MySQL Database container with phpMyAdmin for Stock Data (from the schemaprototyping repo)
- Jupyter
- Redis server (jayjohnson/redis-single-node) on port 6000
Standalone Testing
To start the full stack mode run: compose-start-jupyter.sh
./compose-start-jupyter.sh
The jupyter-docker-compose.yml is used to deploy a single Jupyter container.
Here is how to run locally without using docker (and Lambda deployments in the future).
Clone the repo without the dash character in the name
$ git clone git@github.com:jay-johnson/sci-pype.git scipype
Go to the base dir of the repository
dev$ cd scipype
Set up a local virtual environment using the installer
This will take some time and may fail due to missing packages on your host. Please refer to the Coming Soon and Known Issues section for help getting passed these issues.
scipype$ ./setup-new-dev.sh
After this finishes you should see the lines:
--------------------------------------------------------- Activate the new Scipype virtualenv with: source ./dev-properties.sh" or: source ./properties.sh
Activate the
scipypevirtual environment for development:$ source ./dev-properties.sh
Confirm your virtual environment is ready for use
(scipype) scipype$ pip list --format=columns | grep -E -i "tensorflow|pandas|redis|kafka|xgboost|scipy|scikit" confluent-kafka 0.9.2 kafka-python 1.3.1 pandas 0.19.2 pandas-datareader 0.2.2 pandas-ml 0.4.0 redis 2.10.5 scikit-image 0.12.3 scikit-learn 0.18.1 scikit-neuralnetwork 0.7 scipy 0.18.1 tensorflow 0.12.0 xgboost 0.6a2 (scipype) scipype$
Setup the /opt/work symlink
When running outside docker, I find it easiest to just symlink the repo's base dir to
/opt/workto emulate the container's internal directory deployment structure. In a future release, a local-properties.sh file will set all the environment variables relative to the repository, but for now this works.scipype$ ln -s $(pwd) /opt/work
Confirm the symlink is setup
scipype$ ll /opt/work lrwxrwxrwx 1 driver driver 32 Mar 6 22:38 /opt/work -> /home/driver/dev/scipype/ scipype$
If you want to always use this virtual environment add this to your
~/.bashrcecho 'source /opt/venv/scipype/bin/activate' >> ~/.bashrc
Confirm the Demo downloader works using the Virtual Environment
Please note: this assumes running from a new terminal to validate the virtual environment activation
Activate it
scipype$ source ./dev-properties.sh
Run the Demo
(scipype) scipype$ ./bins/demo-running-locally.py Downloading(SPY) Dates[Jan, 02 2016 - Jan, 02 2017] Storing CSV File(/opt/scipype/data/src/spy.csv) Done Downloading CSV for Ticker(SPY) Success File exists: /opt/scipype/data/src/spy.csv
Deactivate it
(scipype) scipype$ deactivate scipype$
If you want to automatically load the full Scipype environment
properties.shfor any new shell terminal add this to your user's~/.bashrcecho 'source /opt/work/properties.sh' >> ~/.bashrc
You can lock redis down with a password by setting it in the redis.conf before starting the redis server (https://redis.io/topics/security#authentication-feature). Here is how to use the machine learning API with a password-locked Redis Labs endpoint or a local one.
If you are running sci-pype in a docker container it will load the following env vars to ensure the redis application system's clients are setup with the password and database:
# Redis Password where Empty = No Password like: # ENV_REDIS_PASSWORD= ENV_REDIS_PASSWORD=2603648a854c4f3ba7c93e8449319380 ENV_REDIS_DB_ID=0
You can run without a password by either not defining the ENV_REDIS_PASSWORD environment variable or making it set to an empty string.
Run the Secure Redis Labs Cloud Demo
bins/ml$ ./demo-secure-rl-regressor-iris.py
Connect to the Redis Labs Cloud endpoint
After running it you can verify the models were stored on the secured endpoint:
bins/ml$ redis-cli -h pub-redis-12515.us-west-2-1.1.ec2.garantiadata.com -p 12515
Verify the server is enforcing the password
pub-redis-12515.us-west-2-1.1.ec2.garantiadata.com:12515> KEYS * (error) NOAUTH Authentication required
Authenticate with the password
pub-redis-12515.us-west-2-1.1.ec2.garantiadata.com:12515> auth 2603648a854c4f3ba7c93e8449319380 OK
View the redis keys
pub-redis-12515.us-west-2-1.1.ec2.garantiadata.com:12515> KEYS * 1) "_MD_IRIS_REGRESSOR_PetalWidth" 2) "_MD_IRIS_REGRESSOR_PredictionsDF" 3) "_MD_IRIS_REGRESSOR_SepalWidth" 4) "_MODELS_IRIS_REGRESSOR_LATEST" 5) "_MD_IRIS_REGRESSOR_ResultTargetValue" 6) "_MD_IRIS_REGRESSOR_Accuracy" 7) "_MD_IRIS_REGRESSOR_PetalLength" 8) "_MD_IRIS_REGRESSOR_SepalLength" pub-redis-12515.us-west-2-1.1.ec2.garantiadata.com:12515> exit bins/ml$
You can run a password-locked, standalone redis server with docker compose using this script:
https://github.com/jay-johnson/sci-pype/blob/master/bins/redis/auth-start.sh
Once the redis server is started you can run the local secure demo with the script:
bins/ml$ ./demo-secure-ml-regressor-iris.py
After the demo finishes you can authenticate with the local redis server and view the cached models:
bins/ml$ redis-cli -p 6400 127.0.0.1:6400> KEYS * (error) NOAUTH Authentication required. 127.0.0.1:6400> AUTH 2603648a854c4f3ba7c93e8449319380 OK 127.0.0.1:6400> KEYS * 1) "_MD_IRIS_REGRESSOR_PetalWidth" 2) "_MD_IRIS_REGRESSOR_PetalLength" 3) "_MD_IRIS_REGRESSOR_PredictionsDF" 4) "_MD_IRIS_REGRESSOR_SepalWidth" 5) "_MODELS_IRIS_REGRESSOR_LATEST" 6) "_MD_IRIS_REGRESSOR_Accuracy" 7) "_MD_IRIS_REGRESSOR_ResultTargetValue" 8) "_MD_IRIS_REGRESSOR_SepalLength" 127.0.0.1:6400> exit bins/ml$
If you want to stop the redis server run:
https://github.com/jay-johnson/sci-pype/blob/master/bins/redis/stop.sh
-
How to use the python core from a Jupyter notebook. It also shows how to debug the JSON application configs which are used to connect to external database(s) and redis server(s).
-
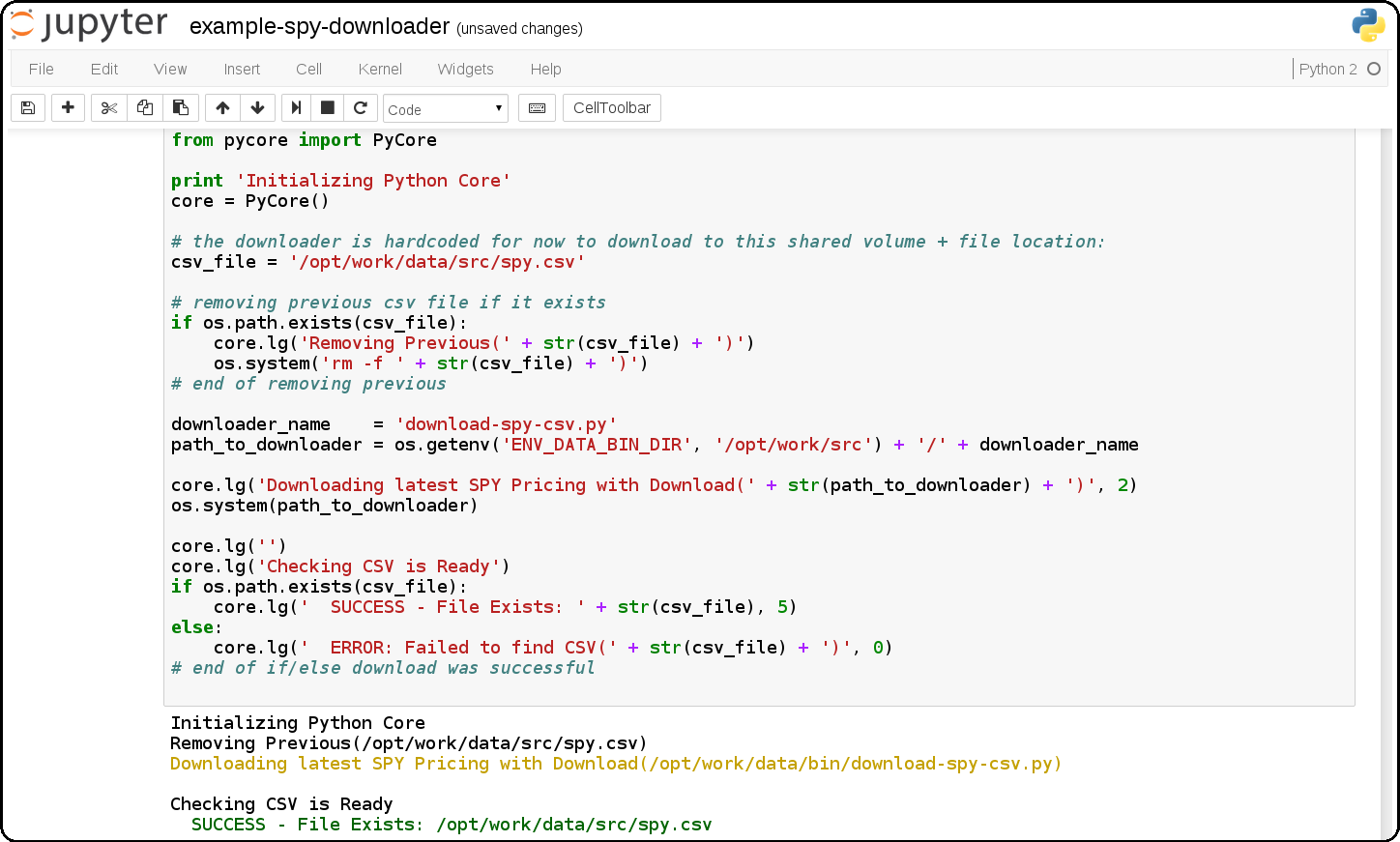
Jupyter + Downloading the SPY Pricing Data
Download the SPY ETF Pricing Data from Google Finance and store it in the shared
ENV_PYTHON_SRC_DIRdirectory that is mounted from the host and into the Jupyter container. It uses a script that downloads the SPY daily pricing data as a csv file. -
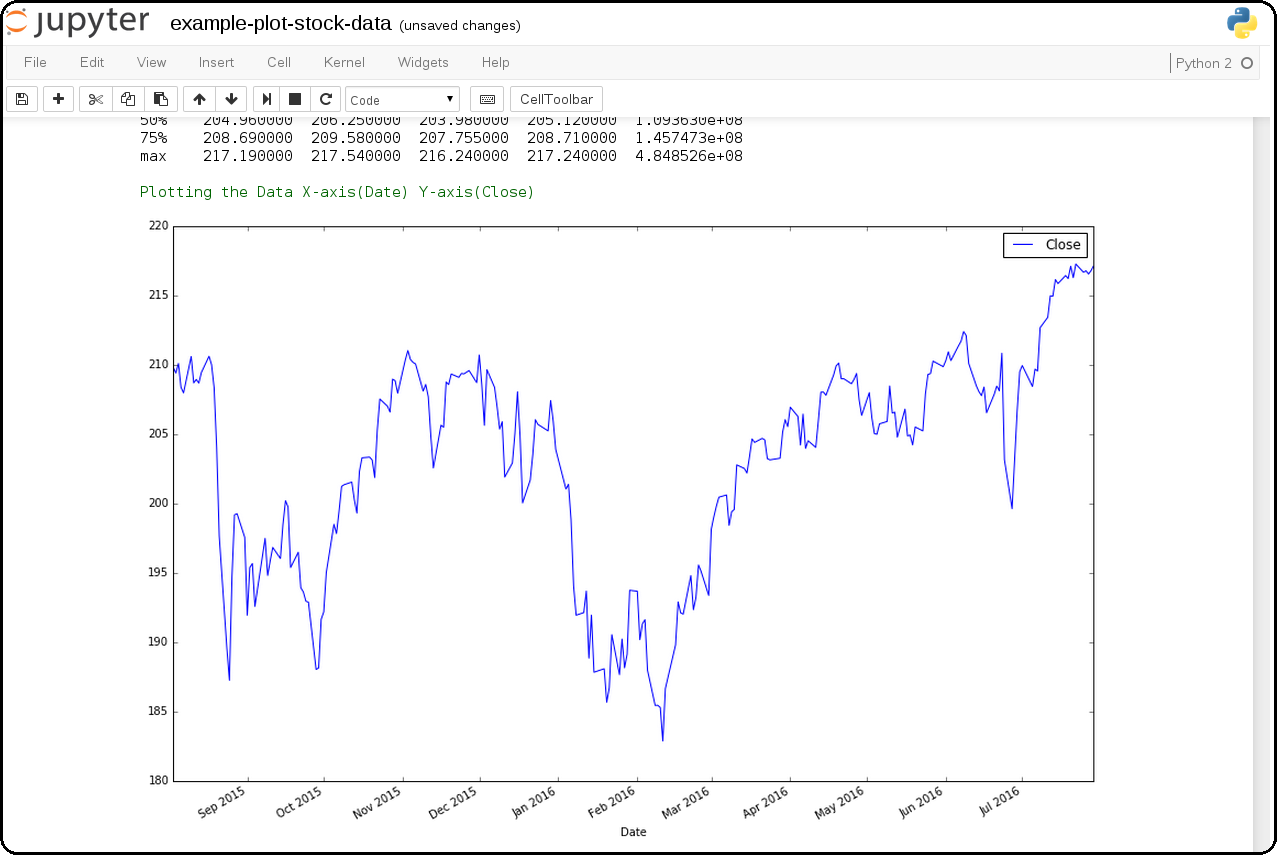
Download SPY and use Pandas + Matlab to Plot Pricing by the Close
This shows how to download the SPY daily prices from Google Finance as a csv then load it using Pandas for plotting on the Close prices with Matlab.
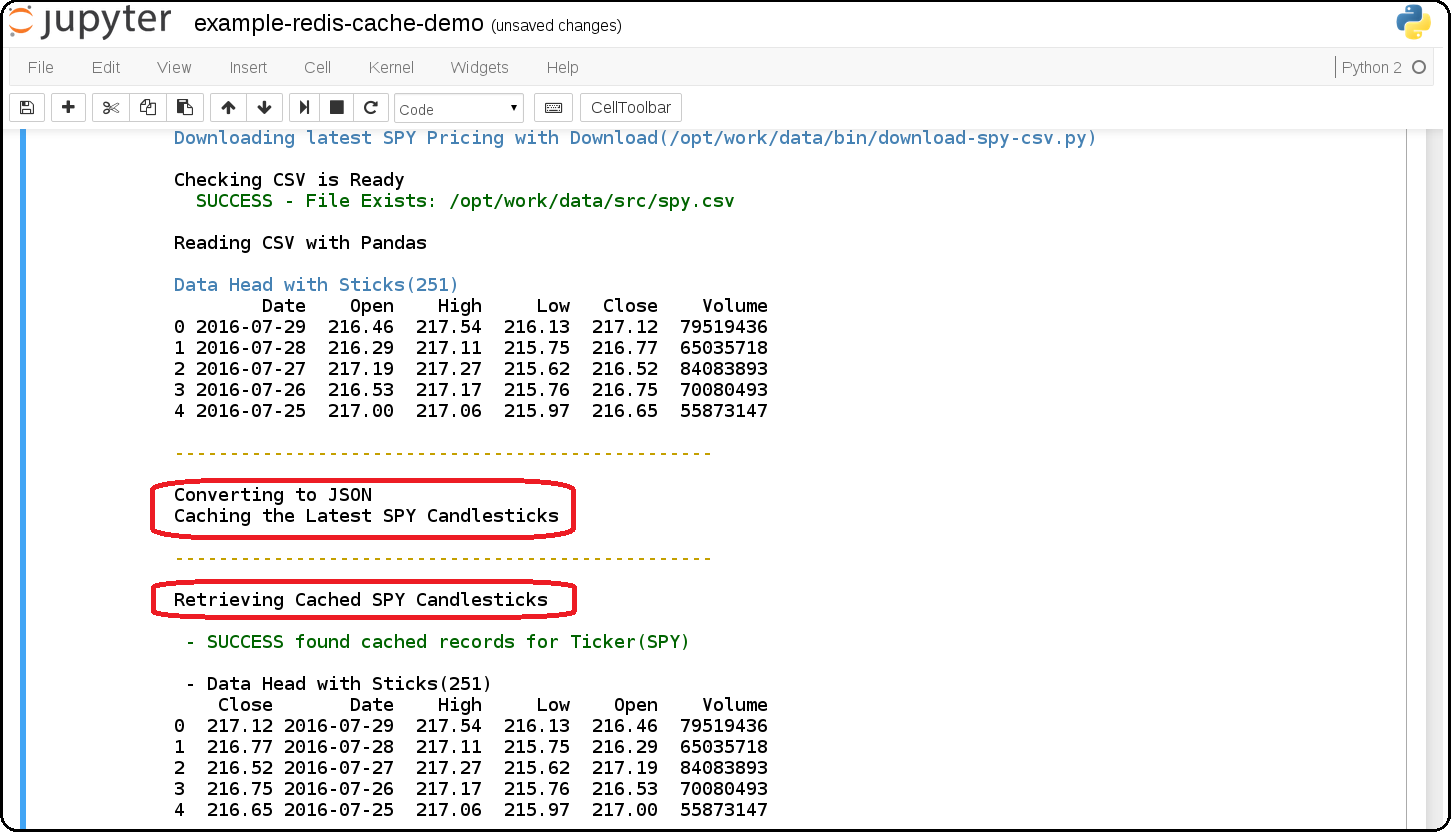
example-redis-cache-demo.ipynb
Building a Jupyter + Redis Data Pipeline
This extends the previous SPY pricing demo and publishes + retreives the pricing data by using a targeted
CACHEredis server (that runs inside the Jupyter container). It stores the Pandas dataframe as JSON in theLATEST_SPY_DAILY_STICKSredis key.example-db-extract-and-cache.ipynb
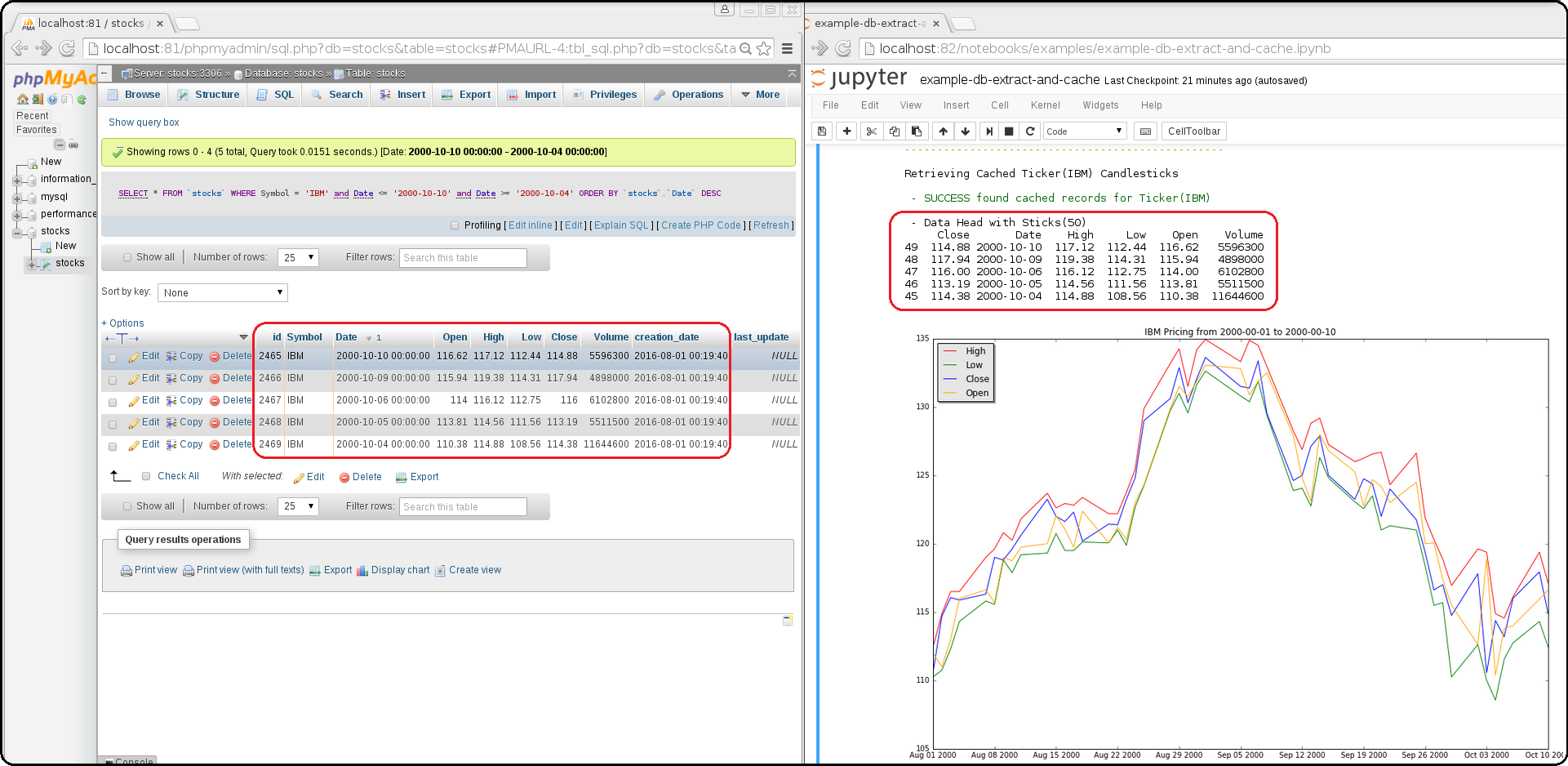
Building a Jupyter + MySQL + Redis Data Pipeline
This requires running the Full Stack which uses the https://github.com/jay-johnson/sci-pype/blob/master/full-stack-compose.yml to deploy three docker containers on the same host:
- MySQL (https://hub.docker.com/r/jayjohnson/schemaprototyping/)
- Jupyter (https://hub.docker.com/r/jayjohnson/jupyter/)
- Redis (https://hub.docker.com/r/jayjohnson/redis-single-node/)
How it works
Extract the IBM stock data from the MySQL dataset and store it as a csv inside the /opt/work/data/src/ibm.csv file
Load the IBM pricing data with Pandas
Plot the pricing data with Matlab
Publish the Pandas Dataframe as JSON to Redis
Retrieve the Pandas Dataframe from Redis
Test the cached pricing data exists outside the Jupyter container with:
$ ./redis.sh SSH-ing into Docker image(redis-server) [root@redis-server container]# redis-cli -h localhost -p 6000 localhost:6000> LRANGE LATEST_IBM_DAILY_STICKS 0 0 1) "(dp0\nS'Data'\np1\nS'{\"Date\":{\"49\":971136000000,\"48\":971049600000,\"47\":970790400000,\"46\":970704000000,\"45\":970617600000,\"44\":970531200000,\"43\":970444800000,\"42\":970185600000,\"41\":970099200000,\"40\":970012800000,\"39\":969926400000,\"38\":969 ... removed for docs ... localhost:6000> exit [root@redis-server container]# exit exit $
-
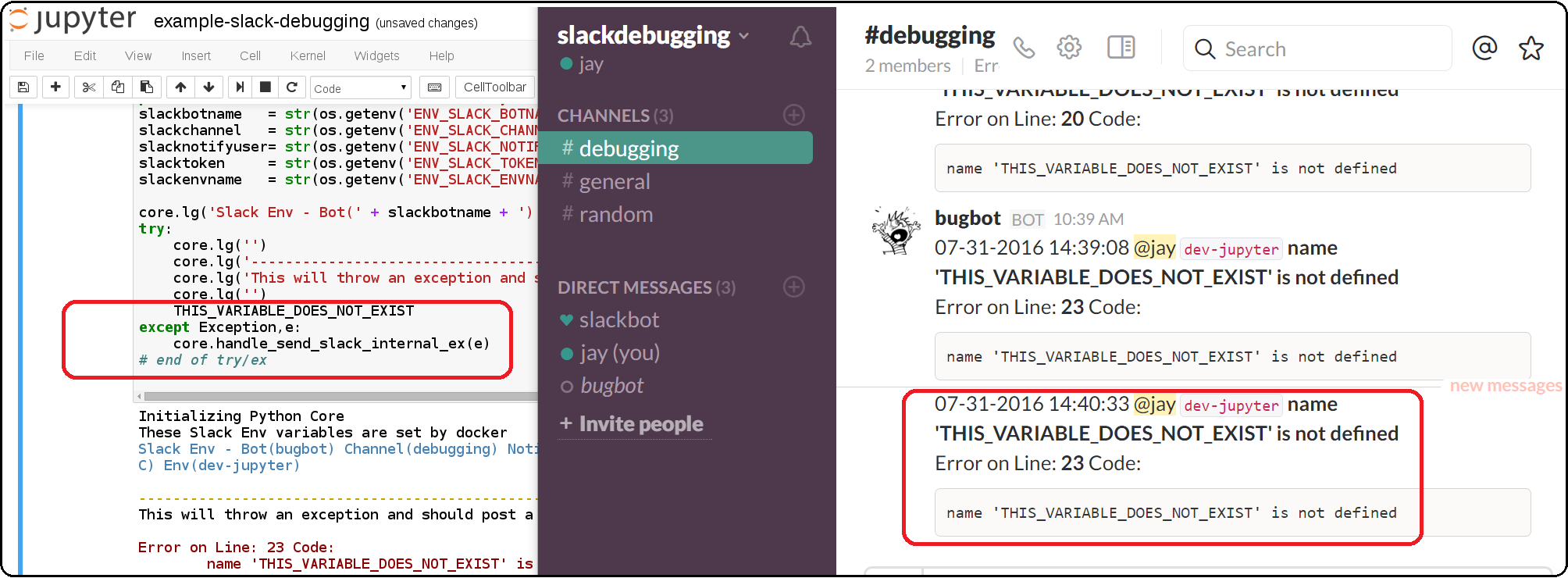
Jupyter + Slack Driven Development
This example shows how environment variables allow the python core to publish a message into Slack to notify the associated user with a message containing the line number and source code that threw the exception.

Python 2 Core
The PyCore uses a JSON config file for connecting to redis servers and configurable databases (MySQL and Postgres) using SQLAlchemy. It has only been tested with the Python 2.7 kernel.
Local Redis Server
When starting the container with
ENV_DEPLOYMENT_TYPEset to anything notJustDB, the container will start a local redis server inside the container on port6000for iterating on your pipeline analysis, Model deployment and caching strategies.Loading Database and Redis Applications
By default the jupyter.json config supports multiple environments for integrating notebooks with external resources. Here is table on what they define:
Name
Purpose
Redis Applications
Database Applications
Local
Use the internal redis server with the stock db
NoApps
Run the core without redis servers or databases
JustRedis
Run with just the redis servers and no databases
JustDB
Run without redis servers and load the databases
Test
Connect to external redis servers and databases
Live
Connect to external redis servers and databases
Inside a notebook you can target a different environment before loading the core with:
Changing to the JustRedis Environment:
import os os.environ["ENV_DEPLOYMENT_TYPE"] = "JustRedis" core = PyCore()
Changing to the NoApps Environment:
import os os.environ["ENV_DEPLOYMENT_TYPE"] = "NoApps" core = PyCore()
Customize the Jupyter Container Lifecycle
The following environment variables can be used for defining pre-start, start, and post-start Jupyter actions as needed.
Environment Variable
Default Value
Purpose
ENV_PRESTART_SCRIPT
Run custom actions before starting Jupyter
ENV_START_SCRIPT
Start Jupyter
ENV_POSTSTART_SCRIPT
Run custom actions after starting Jupyter
Slack Debugging
The core supports publishing exceptions into Slack based off the environment variables passed in using docker or docker compose.
Tracking Installed Dependencies for Notebook Sharing
This docker container uses these files for tracking Python 2 and Python 3 pips:
- /opt/work/pips/python2-requirements.txt
- /opt/work/pips/python3-requirements.txt
Shared Volumes
These are the mounted volumes and directories that can be changed as needed. Also the core uses them as environment variables.
Host Mount
Container Mount
Purpose
/opt/project
/opt/project
Sharing a project from the host machine
/opt/work/data
/opt/work/data
Sharing a common data dir between host and containers
/opt/work/data/src
/opt/work/data/src
Passing data source files into the container
/opt/work/data/dst
/opt/work/data/dst
Passing processed data files outside the container
/opt/work/data/bin
/opt/work/data/bin
Exchanging data binaries from the host into the container
/opt/work/data/synthesize
/opt/work/data/synthesize
Sharing files used for synthesizing data
/opt/work/data/tidy
/opt/work/data/tidy
Sharing files used to tidy and marshall data
/opt/work/data/analyze
/opt/work/data/analyze
Sharing files used for data analysis and processing
/opt/work/data/output
/opt/work/data/output
Sharing processed files and analyzed output
Start the Container in Local development mode
$ ./start.sh Starting new Docker image(docker.io/jayjohnson/jupyter) 4275447ef6a3aa06fb06097837deeb202bd80b15969a9c1269a5ee042d8df13d $
Browse to the local Jupyter website
The full-stack-compose.yml patches the Jupyter and redis containers to ensure the MySQL database is listening on port 3306 before starting. It does this by defining a custom entrypoint wrapper for each in the wait-for-its tools directory.
Start the Composition
This can take around 20 seconds for MySQL to set up the seed pricing records, and it requires assigning the shared data directory permissions for read/write access from inside the Jupyter container.
$ ./compose-start-full.sh Before starting changing permissions with: chown -R driver:users /opt/work/data/* [sudo] password for driver: Starting Composition: full-stack-compose.yml Starting stocksdb Starting jupyter Starting redis-server Done $
Check the Composition
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1fd9bd22987f jayjohnson/redis-single-node:1.0.0 "/wait-for-its/redis-" 12 minutes ago Up 25 seconds 0.0.0.0:6000->6000/tcp redis-server 2bcb6b8d2994 jayjohnson/jupyter:1.0.0 "/wait-for-its/jupyte" 12 minutes ago Up 25 seconds 0.0.0.0:8888->8888/tcp jupyter b7bce846b9af jayjohnson/schemaprototyping:1.0.0 "/root/start_containe" 25 minutes ago Up 25 seconds 0.0.0.0:81->80/tcp, 0.0.0.0:3307->3306/tcp stocksdb $
- Optional - Login to the database container
$ ./db.ssh SSH-ing into Docker image(stocksdb) [root@stocksdb db-loaders]# ps auwwx | grep mysql | grep -v grep root 28 0.0 0.0 11648 2752 ? S 17:00 0:00 /bin/sh /usr/bin/mysqld_safe mysql 656 1.3 12.0 1279736 474276 ? Sl 17:00 0:01 /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --user=mysql --log-error=/var/log/mysql/error.log --pid-file=/var/lib/mysql/mysqld.pid --socket=/var/lib/mysql/mysqld.sock --port=3306 [root@stocksdb db-loaders]# exit
View the Stocks Database with phpMyAdmin: http://localhost:81/phpmyadmin/sql.php?db=stocks&table=stocks
Note
By default the login to this sample db is:
dbadmin/dbadmin123which can be configured in the db.env- Optional - Login to the Redis container
$ ./redis.sh SSH-ing into Docker image(redis-server) [root@redis-server container]# ps auwwx | grep redis root 1 0.0 0.0 11644 2616 ? Ss 17:00 0:00 bash /wait-for-its/redis-wait-for-it.sh root 28 0.0 0.2 114800 11208 ? Ss 17:00 0:00 /usr/bin/python /usr/bin/supervisord -c /etc/supervisor.d/rediscluster.ini root 30 0.3 0.0 37268 3720 ? Sl 17:00 0:00 redis-server *:6000 root 47 0.0 0.0 9044 892 ? S+ 17:02 0:00 grep --color=auto redis [root@redis-server container]# exit
- Optional - Login to the Jupyter container
$ ./ssh.sh SSH-ing into Docker image(jupyter) jovyan:/opt/work$ ps auwwx | grep jupyter jovyan 1 0.0 0.0 13244 2908 ? Ss 17:00 0:00 bash /wait-for-its/jupyter-wait-for-it.sh jovyan 38 0.3 1.2 180564 48068 ? S 17:00 0:00 /opt/conda/bin/python /opt/conda/bin/jupyter-notebook jovyan:/opt/work$ exit
Run the Database Extraction Jupyter Demo
Open the notebook with this url: http://localhost:82/notebooks/examples/example-db-extract-and-cache.ipynb
Click the Run Button
This example will connect to the
stocksdbMySQL container and pull 50 records from IBM's pricing data. It will then render plot lines for Open, Close, High, and Low using Pandas and Matlab. Next it will cache the IBM records in theredis-servercontainer and then verify those records were cached correctly by retrieving it again.From outside the Jupyter container confirm the redis key holds the processed IBM data
$ ./redis.sh SSH-ing into Docker image(redis-server) [root@redis-server container]# redis-cli -h localhost -p 6000 localhost:6000> LRANGE LATEST_IBM_DAILY_STICKS 0 0 1) "(dp0\nS'Data'\np1\nS'{\"Date\":{\"49\":971136000000,\"48\":971049600000,\"47\":970790400000,\"46\":970704000000,\"45\":970617600000,\"44\":970531200000,\"43\":970444800000,\"42\":970185600000,\"41\":970099200000,\"40\":970012800000,\"39\":969926400000,\"38\":969 ... removed for docs ... localhost:6000> exit [root@redis-server container]# exit exit $Stop the Composition
$ ./compose-stop-full.sh Stopping Composition: full-stack-compose.yml Stopping redis-server ... done Stopping jupyter ... done Stopping stocksdb ... done Done $
Start Standalone
Start the standalone Jupyter container using the jupyter-docker-compose.yml file. This compose file requires access to
/opt/work/datahost directory like the Full Stack version for sharing files between the container and the host.$ ./compose-start-jupyter.sh Before starting changing permissions with: chown -R driver:users /opt/work/data/* [sudo] password for driver: Starting Composition: jupyter-docker-compose.yml Starting jupyter Done $
Stop Standalone
Stop the standalone Jupyter composition with:
$ ./compose-stop-jupyter.sh Stopping Composition: jupyter-docker-compose.yml Stopping jupyter ... done Done $
Remove the containers with the command:
$ docker rm jupyter redis-server stocksdb jupyter redis-server stocksdb $
Delete them from the host with:
$ docker rmi jayjohnson/schemaprototyping $ docker rmi jayjohnson/jupyter $ docker rmi jayjohnson/redis-single-node
By default, the host will have this directory structure available for passing files in and out of the container:
$ tree /opt/work
/opt/work
└── data
├── analyze
├── bin
├── dst
├── output
├── src
│ └── spy.csv
├── synthesize
└── tidy
8 directories, 1 file
From inside the container here is where the directories are mapped:
$ ./ssh.sh SSH-ing into Docker image(jupyter) driver:/opt/work$ tree data/ data/ ├── analyze ├── bin ├── dst ├── output ├── src │ └── spy.csv ├── synthesize └── tidy 7 directories, 1 file
Missing xattr.h
If you see this error:
xattr.c:29:24: fatal error: attr/xattr.h: No such file or directory
Install RPM:
sudo yum install -y libattr-devel
Install Deb:
sudo apt-get install -y libattr1-dev
Retry the install
Local Install Confluent:
If you're trying to setup the local development environment and missing the kafka headers:
In file included from confluent_kafka/src/confluent_kafka.c:17:0: confluent_kafka/src/confluent_kafka.h:21:32: fatal error: librdkafka/rdkafka.h: No such file or directory #include <librdkafka/rdkafka.h>
Please install Kafka by adding their repository and then installing:
$ sudo yum install confluent-platform-oss-2.11 $ sudo yum install librdkafka1 librdkafka-devel
Official RPM Guide: http://docs.confluent.io/3.1.1/installation.html#rpm-packages-via-yum
Official DEB Guide: http://docs.confluent.io/3.1.1/installation.html#deb-packages-via-apt
For
Fedora 24/RHEL 7/CentOS 7users here's a tool to help:scipype/python2$ sudo ./install_confluent_platform.sh
Install PyQt4 for
ImportError: No module named PyQt4errors:(python2) jovyan:/opt/work/bins$ conda install -y pyqt=4.11 Fetching package metadata ......... Solving package specifications: .......... Package plan for installation in environment /opt/conda/envs/python2: The following packages will be downloaded: package | build ---------------------------|----------------- qt-4.8.7 | 3 31.3 MB conda-forge pyqt-4.11.4 | py27_2 3.5 MB conda-forge ------------------------------------------------------------ Total: 34.8 MB The following NEW packages will be INSTALLED: pyqt: 4.11.4-py27_2 conda-forge qt: 4.8.7-3 conda-forge (copy) Pruning fetched packages from the cache ... Fetching packages ... qt-4.8.7-3.tar 100% |##########################################################################################################################################| Time: 0:00:06 5.23 MB/s pyqt-4.11.4-py 100% |##########################################################################################################################################| Time: 0:00:02 1.28 MB/s Extracting packages ... [ COMPLETE ]|#############################################################################################################################################################| 100% Linking packages ... [ COMPLETE ]|#############################################################################################################################################################| 100%Now try running a script from the shell:
(python2) jovyan:/opt/work/bins$ ./download-spy-csv.py Downloading(SPY) Dates[Jan, 02 2016 - Jan, 02 2017] Storing CSV File(/opt/work/data/src/spy.csv) Done Downloading CSV for Ticker(SPY) Success File exists: /opt/work/data/src/spy.csv (python2) jovyan:/opt/work/bins$
How to build a customized Python Core mounted from outside the Jupyter container
Fixing the docker compose networking so the stocksdb container does not need to know the compose-generated docker network.
Right now it is defining the sci-pype_datapype as the expected docker network. This may not work on older versions of docker.
Building Jupyter containers that are smaller and only run one kernel to reduce the overall size of the image
Testing on an older docker version
This was tested with
1.12.1$ docker -v Docker version 1.12.1, build 23cf638 $
Setting up the Jupyter wait-for-it to ensure the stocks database is loaded before starting...not just the port is up
For now just shutdown the notebook kernel if you see an error related to the stocks database not being there when running the full stack.
- Examples for using the Timestamp Forecasting API
- Post Processing Event API support
- Confluent Kafka integration notebooks (the python client is already installed in the virtual env and docker container https://github.com/confluentinc/confluent-kafka-python)
- PySpark integration notebooks
- Tensorflow integration notebooks
- Adding more support and optional third-party mounting for customized Machine Learning Algorithms (like https://github.com/pandas-ml/pandas-ml)
- Odo (http://odo.readthedocs.io/en/latest/) examples
- Lambda deployment integration (http://docs.aws.amazon.com/lambda/latest/dg/lambda-python-how-to-create-deployment-package.html) and likely FPM (https://github.com/jordansissel/fpm) for package building.
This project is not related to SciPy.org or the scipy library. It was originally built for exchanging and loading datasets using Redis for creating near-realtime data pipelines for streaming analysis (like a scientific pypeline).
This repo is Apache 2.0 License: https://github.com/jay-johnson/sci-pype/blob/master/LICENSE
Jupyter - BSD: https://github.com/jupyter/jupyter/blob/master/LICENSE
Please refer to the Conda Licenses for individual Python libraries: https://docs.continuum.io/anaconda/pkg-docs
Redis - https://redis.io/topics/license