Home
JWSACruncher is the Java implementation of the .NET application "WSACruncher". It is a console tool that re-estimates all the multi-processing defined in a workspace. The workspace may have been generated by means of Demetra+ (.NET), of JDemetra+ (Java) or by any user tool.
JWSACruncher runs on any operating systems that support the Java VM (Virtual Machine) such as Microsoft Windows, Solaris OS, Apple macOS, Ubuntu and other various Linux distributions.
JWSACruncher requires a Java SE Runtime Environment (JRE) version 8 or later to run on such as OpenJDK.
You can download a free, binary distribution of the OpenJDK at one of the following provider:
Note that JWSACruncher is a standalone application that doesn't need Demetra+ or JDemetra+ to be installed.
- Download the platform-independent zip package (
jwsacruncher-x.y.z-bin.zip) at:
https://github.com/jdemetra/jwsacruncher/releases - Extract it to any folder on your system (i.e.
_CRUNCHER_PATH_) - Create a shortcut to the executable file located in the
_CRUNCHER_PATH_/bindirectory:
Windows:jwsacruncher.bat
Linux, Solaris and macOS:$ ./jwsacruncher
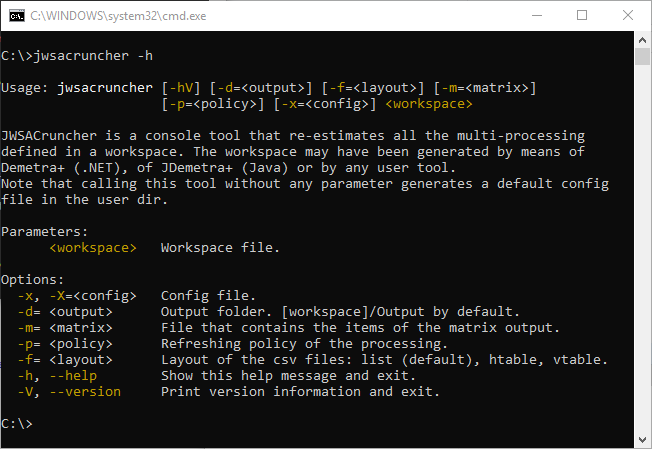
You can check that the command line is properly installed by calling jwsacruncher --help
JWSACruncher uses the same parameters as WSACruncher. The command line for launching the tool is the following:
jwsacruncher[.bat][-x <parameters file>]
For instance:
jwsacruncher d:\repository\MyWS.xml -x d:\repository\MyWS.params
Jwsacruncher is located in the “bin” sub-folder
Be aware that some operating systems are case sensitive. The only mandatory parameter is the name of a workspace defined with JDemetra+. It is supposed that the depending files are available. The second parameter, identified by "-x", is an xml file containing detailed information on the batch processing. See below for further explanations. If that file is unavailable, the default specifications will be used. The other parameters used with WSACruncher are still operational but obsolete. See the documentation of WSACruncher for further information.
The following output is generated:
- The processing xxx.xml used as input is saved as xxx.bak and the new results replace the file xxx.xml
- The series specified in the in the file of parameters are generated in separate csv files, named series_zzz.csv; by default, each row of the csv files contains the identifier of the series, its frequency, its starting year and period, its length and the data; however, they can be formatted in a way that can be immediately read by software like Excel (vertical or horizontal tables).
- The csv file "demetra_m.csv", containing a matrix with all the results specified in the file of parameters is also generated.
The different outputs are located by default in the folder(s) /Output/[_x] ,
where:
- "processing name" is the name of the processing in the workspace
- the [_x] prefix ("_1", "_2"...) correspond to an automatic splitting of large processing in smaller groups (see "bundle" option in the parameters file) So, if the workspace "d:\sa\myWs.xml" contains the large processing "Processing-1", "Processing-2", the folder "d:\sa will contain:
- Inputs:
- myWs.xml
- .\myWs\SAProcessing\Processing-1.xml
- .\myWs \SAProcessing\Processing-2.xml
- ...
- Outputs:
- .\myWs \Output\Processing-1_1\demetra_m.csv
- .\myWs \Output\Processing-1_1\series_sa.csv
- .\myWs \Output\Processing-1_1...
- .\myWs \Output\Processing-1_2\demetra_m.csv
- .\myWs \Output\Processing-1_2\series_sa.csv
- .\myWs \Output\Processing-1_2...
- .\myWs \Output\Processing-1_.........
- .\myWs \Output\Processing-2_1\demetra_m.csv
- .\myWs \Output\Processing-2_1\series_sa.csv
- .\myWs \Output\Processing-2_1...
- .\myWs \Output\Processing-2_2\demetra_m.csv
- .\myWs \Output\Processing-2_2\series_sa.csv
- .\myWs \Output\Processing-2_2...
- .\myWs \Output\Processing-2_2...
JWSACruncher is designed to be used with (J)Demetra+. We present below a typical scenario for the use of both applications.
-
Creation of the workspace with JDemetra+ You should use JDemetra+ to create a new workspace and to add in it the processing that should be re-estimated. Tips Don't run the processing in JDemetra+ If need be, create as many processing as needed.
-
Copy of the complete workspace in a suitable folder You can copy the complete workspace at the folder where you want to process it using the command: file->Save workspace as... You can also copy it manually: the files that belongs to a workspace xxx are
- xxx.xml, which contains the description of the workspace
- the folder ./xxx and all its sub-folders, which contain the description of processing, the calendars...
- Run JWSACruncher (as defined above) You can re-use JDemetra+ to visualize the results and/or to correct some of them.
Tips: launch jwsacruncher (without parameter) for generating a default parameters file
The parameters file has the following structure:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<wsaConfig bundle="1000" csvlayout="list" csvseparator="," ndecs="6”>
<policy>parameters</policy>
<output>d:\saresults</output>
<matrix>
<item>span.start</item>
<item>span.end</item>
<item>span.n</item>
<item>likelihood.neffectiveobs</item>
...
</matrix>
<tsmatrix>
<series>y</series>
<series>sa</series>
...
</tsmatrix>
<paths>
<path>C:\Documents and Settings\me\Data\Excel</path>
<path>C:\Documents and Settings\me\Data\Xml</path>
...
</paths>
</wsaConfig>
The meaning of the different tags and their possible values are defined below
| Tag | Meaning | Value |
|---|---|---|
| bundle | Maximum size for a group of series (in output) | 1000 by default |
| csvlayout | Layout of the csv files (series only) | list (default), htable, vtable |
| csvseparator | List separator of the csv file | (“,”) by default |
| ndecs | Number of decimals used in the output | 6 by default |
| policy | refreshing policy of the processing | see below; parameters by default |
| output | Output folder | Full path of the output folder; ([workspace]/Output by default) |
| matrix.item | Items of the matrix output | See the output dictionary for details |
| tsmatrix.series | Generated series | See the output dictionary for details |
| paths | The paths used for relative addresses (see the "Demetra Paths" of the graphical interface) |
The refreshing policy ( policy tag) is defined by the following options
| Policy | Full name | Short name |
|---|---|---|
| Current[AO]: fixed model + AO for new data | current | n |
| Fixed model | fixed | f |
| Re-estimation of the coefficients of the regression variables | fixedparameters | fp |
| + re-estimation of ARIMA coefficients | parameters | p |
| + re-estimation of last outliers | lastoutliers | l |
| + re-estimation of all outliers | outliers | o |
| + estimation of ARIMA orders | stochastic | s |
| Concurrent | complete or concurrent | c |