This project was conducted as part of my engineering degree. The goal was to build a lip reading AI that could output words or sentences from a silent video input.
There is different ways to tackle this problem (sorted from the lowest to the highest level of abstraction) :
- Lip reading on the phoneme level: For every frame of the input, predict the corresponding phoneme. The classification problem is easier (only 44 different phonemes in English), but going up to a higher level to form words or sentences can be challenging : (1) a phoneme can be spread over multiple frames, (2) and some phonemes are impossible to differentiate (from a lip movement perspective, there is no way to distinguish between and “p” and a “b” for example).
- Lip reading on the word level: Parse the video sequence into different subsequences with each one of them containing a single word. Then classify those sequences using a predefined dictionary. This classification problem is more difficult, given that the dictionary should contain a lot of words (>100). But also because we first need to parse the input into different subsequences.
- Lip reading on the sentence level: Predict words in a sentence using predefined phrasing. Not really useful in my own opinion.
Here I chose to work on the word level because even if a high accuracy is not achieved, the output can still be used to enhance speech recognition models.
For humans, adding sight of the speaker to heard speeches improves speech processing. In the same way, a lip reading AI can be used to enhance some already existing speech recognition models, especially if the audio is noisy (low quality, music in the background, etc.)
The dataset consists of ~1000 utterances of 500 different words, spoken by different speakers. All videos are 29 frames in length, and the word occurs in the middle of the video. The frames were cropped around the speaker’s mouth and downsized to 64x64.

Link : http://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrw1.html
This repository contains the source code for two different architectures :
The Multiple Towers architecture is largely inspired by the VGG-M architecture, but adapted to a video input. A convolutional layer and a pooling layer is first applied on every frame. We then concatenate all the outputs into a single 3D matrix. We finally apply a set a convolutions/poolings (see paper for more details)
Paper : Joon Son Chung and Andrew Zisserman, “Lip Reading in the Wild”
The other model is a slightly modified Inception-v4 architecture. This model is based on several very small convolutions, grouped in “blocks”, in order to drastically reduce the number of parameters Here, multiple frames pass through the same layers in the “stem” block because of the video input. We then concatenate the output in the same way that we did with the Multiple Towers architecture. The main advantage of this architecture is to allow us to have a very deep model with multiple blocks and layers without bearing the weight of a huge number of parameters.
Paper : C.Szegedy, S.Ioffe, V.Vanhoucke, A.Alemi, “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning”
One of the most important, but also time consuming aspect of this project was setting up a good data pipeline. Given the fact that the dataset couldn’t fit in memory, the performance of the pipeline was very important : at every iteration, it needed to fetch a batch of training examples from the disk, apply preprocessing on it, data-augmentation, and finally feed it to the neural network. To achieve that I chose to use Tensorflow’s data input pipeline. It allow us to do everything mentioned above, but also to achieve a peak level of performance by using the CPU and GPU at the same time. As a result the data for the next step is ready before the current step has finished.
Pipelining overlaps the preprocessing and model execution of a training step. While the accelerator is performing training step N, the CPU is preparing the data for step N+1. Doing so reduces the step time to the maximum (as opposed to the sum) of the training and the time it takes to extract and transform the data. https://www.tensorflow.org/guide/performance/datasets
The two networks were trained on a Nvidia GTX 1080 Ti GPU and an Intel Xeon CPU for 25 epochs or until the validation loss started increasing, whichever come first. The best results were obtained using Momentum SGD and Adam. The hyperparameters for the fine tuned models are stored in .json files (hyperparameter directory, see repo).
_ The following table summarizes the results obtained and compares them with other methods.
| Top-1 accuracy | Top-10 accuracy | Size of the model | Training time | |
|---|---|---|---|---|
| Human experts | ~30% | - | - | (years?) |
| Multiple Towers / VGG-M | 61.1% | 90.4% | ~40 million parameters | 7 hours |
| Inception-v4 | 64.2% | 93.8% | ~8 million parameters | 12.5 hours |
Momentum SGD (after tuning) and Adam gave equal results.
The main goal of this project was to build an end-to-end lipreader generic enough to be used on any video. The preprocessing required to go from the input to a 64x64x29 matrix gives rise to two problems : (1) how to reduce the spacial dimension of the video, ie cropping it around the speaker's mouth, but also (2) how to reduce the temporal dimension, ie going from x numbers of frames to 29. The first problem is solved by using Adam Geitgey's face recognition Python API (see lipReader.py for more interesting details). The solution to the second one is pretty straightforward : we just select 29 evenly spaced frames from the input video.
The script produces 2 outputs.
- A video that represents the input that is fed to the neural network (it was used a lot during debugging).
- A bar graph that summarises the output of the model. For the word "Change" for example, the following graph is obtained:
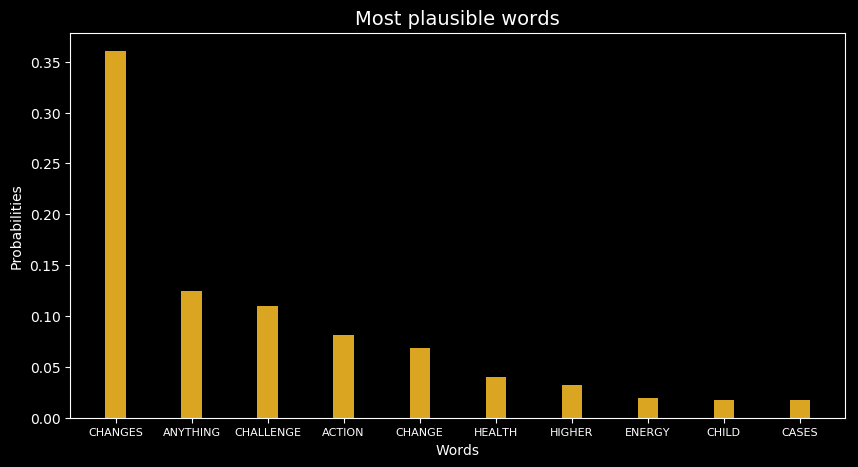
The results were very promising. The model is however tricky when used on videos that are poorly framed or videos with low contrast and high brightness.
When tested on videos that were not part of the initial dataset (Demo video), the model did pretty good, but showed the following flaws :
- Couldn't distinguish between singular/plural
- Even though everytime, the ground truth was in the top-5 predictions, the model couldn't achieve a top-1 accuracy comparable to that of the dataset (~64% accuracy on the validation and test sets).
However in every example, the model did recognize nearly all the phonemes. But it had trouble with the temporal aspect, giving a nearly equal probability to the words that contain one of those phonemes.
The Inception-v4 architecture achieved SOTA in both top-1 and top-10 accuracies. However the margin is small. There appears to be a plateau in the accuracy results, which can be attributed to different factors :
- Some words in the dataset that are nearly homophones (“groups” and “troops”, or “ground” and “around”).
- The distinction between the singular and plural form is also difficult to establish (as in “report” and “reports” which are considered different words in the dataset).
- Some videos in the dataset are poorly framed.
Using LSTMs and a RNN architecture could help increase the accuracy of the model, as they are more effective with temporal data. Conditional probability can also be used to enhance the model. In the sentence “The experiments were conducted in [unknown word]”, it’s obvious that the missing word is “groups” and not “troops” for example. A CNN used in pair with a Markov Chain can be extremely powerful to go from words to sentences.
The progress made during this project is still very significant. We achieved higher accuracy with a smaller model (5 times less parameters), which is very important for putting it in production.
Advice given by my supervisor, Clement Chatelain, has been a great help in this project and I would like to thank him for his valuable and constructive suggestions. I’m also grateful to Rob Cooper at BBC Research & Development for his help in obtaining the dataset.