The objective of this project is to examine the relationship between various features in a dataset, focusing on the impact of the diagnosis variable, which consists of Malignant (M) and Benign (B) categories. The study employs Exploratory Data Analysis (EDA) and Descriptive Statistics to clarify how measurement results relate to health conditions. The analysis includes boxplots, scatterplots, correlation charts, k-means clustering, and logistic regression.
Dataset Details:
- Format: CSV
- Rows: 569
- Columns: 32 (excluding the "X" column with
NaNvalues)
📱 Data Preparation 📱
- Load and preprocess the dataset.
- Remove unnecessary columns and scale numerical data.
🌟 Descriptive Statistics 🌟
- Generate summary statistics for the features.
⚡ Visualization ⚡
- Boxplots: Display the distribution and outliers of features.
- Scatterplots: Illustrate the relationship between features like
radius_meanandperimeter_mean.
🚨 Correlation Analysis 🚨
- Pearson’s and Spearman’s Correlation: Analyze correlations and their significance between features.
🔥 Principal Component Analysis (PCA) 🔥
- Perform PCA to reduce dimensionality and visualize feature relationships.
🌱 Clustering 🌱
- K-Means Clustering: Determine optimal cluster numbers and visualize clusters.
🔔 Logistic Regression 🔔
- Compare features like
compactness_meanandradius_sewith the diagnosis variable to analyze their relationship.
# Load required libraries
library(tidyverse)
library(cluster)
library(Hmisc)
library(plotly)
library(ggfortify)
library(factoextra)
library(NbClust)
library(ggpubr)
library(dplyr)
library(PerformanceAnalytics)
library(ggplot2)
# Load and prepare data
data <- read.csv("/Users/admin/Desktop/Workplace/Data/cancer.csv", sep=",", row.names=1, stringsAsFactors = T)
data_rest <- data[, -32]
numerical_data <- data_rest[, -1]
numerical_data_scaled <- scale(numerical_data)
# Export data for Excel
export_data <- data[,1] %>% mutate_if(is.numeric, round, digits=3)
export_data$X <- data$X
export_data$diagnosis <- data$diagnosis
write.table(export_data, file='/Users/admin/Desktop/data.txt', sep=',', row.names = T)
# Descriptive statistics summary
summary_data <- round(apply(numerical_data, 2, summary),3)
clip <- pipe("pbcopy", "w")
write.table(summary_data, file=clip, sep = '\t', row.names = FALSE)
close(clip)
# Boxplot visualization
png("/Users/admin/Desktop/boxplot.png", width = 20, height = 10, units = 'in', res = 300)
boxplot(scale(numerical_data), col = rainbow(ncol(numerical_data)), notch = TRUE, xlab = "Features", ylab = "Values")
dev.off()
# Scatter plot visualization
png("/Users/admin/Desktop/scatter_plot.png", width = 4, height = 4, units = 'in', res = 300)
ggplot(data = data_rest, mapping = aes(x = data_rest$radius_mean, y = data_rest$perimeter_mean)) +
geom_point(mapping = aes(color = diagnosis)) +
labs(x = "radius_mean", y = "perimeter_mean")
dev.off()
# Correlation analysis
chart.Correlation(numerical_data, histogram=TRUE, pch="+", method = "pearson")
chart.Correlation(numerical_data, histogram=TRUE, pch="+", method = "spearman")
corr_matrix <- as.matrix(round(cor(numerical_data)), 2)
corr_matrix[corr_matrix< 0.05]=NA
# PCA
PCA_result <- prcomp(numerical_data, center = TRUE, scale. = TRUE)
summary(PCA_result)
PCA_plot <- autoplot(PCA_result, data = data_rest, colour = 'diagnosis', label.size = 3, shape = FALSE,
loadings = TRUE, loadings.colour = 'blue',
loadings.label = TRUE, loadings.label.size = 2)
ggplotly(PCA_plot)
# K-Means Clustering
set.seed(1)
NbClust(numerical_data, distance = "euclidean", min.nc = 2, max.nc = 10, method = "kmeans")
km.res <- kmeans(numerical_data_scaled, 2)
fviz_cluster(km.res, numerical_data, ellipse.type = "norm", repel = TRUE)
ggsave("kmeans_graph.png")
pam.res <- pam(numerical_data_scaled, 2)
fviz_cluster(pam.res, geom = "point", ellipse.type = "norm")


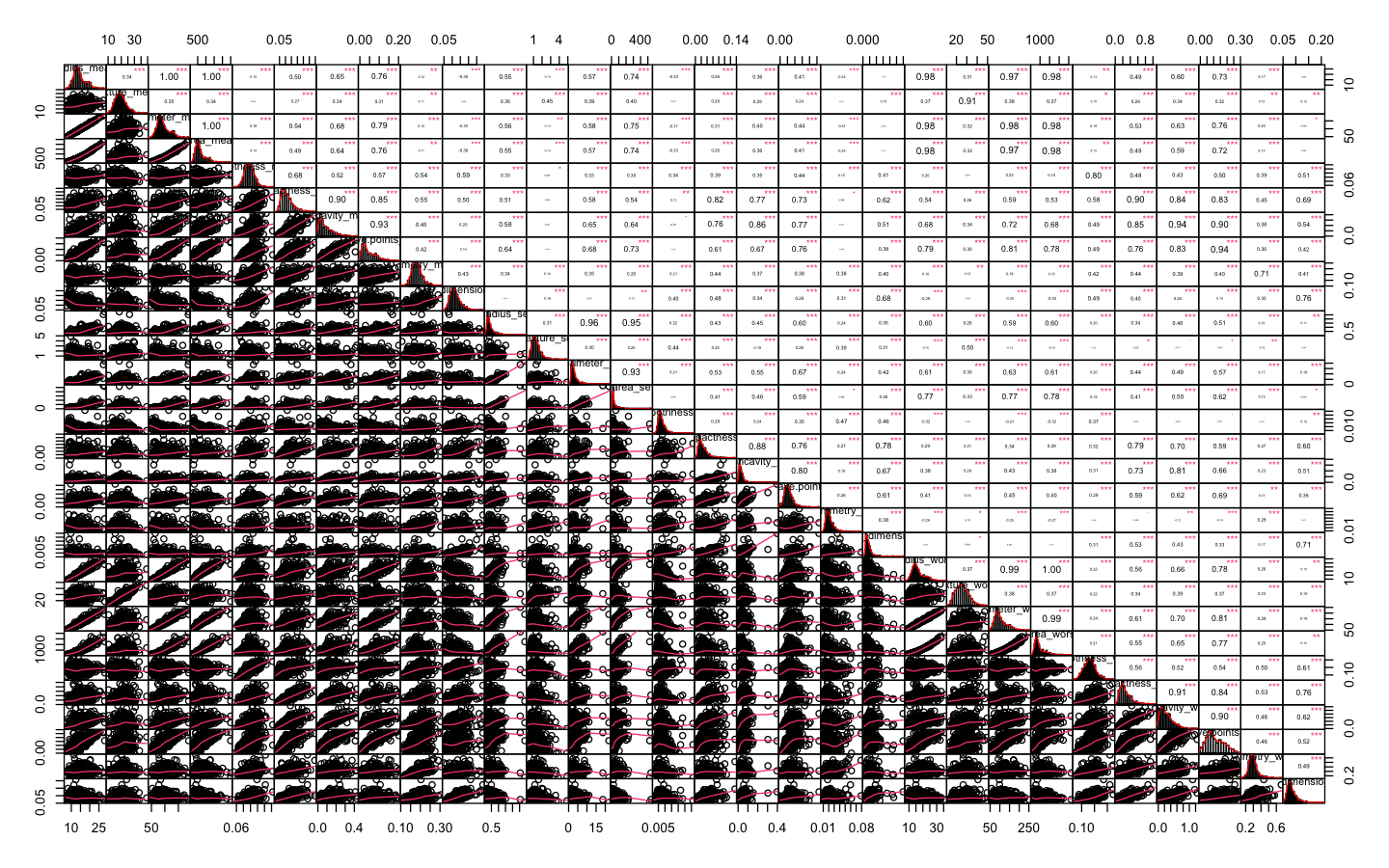


Through exploratory data analysis and statistical modeling, this project reveals significant insights into the relationships between features and their impact on the diagnosis variable. The use of correlation analysis, PCA, and clustering methods provides a comprehensive understanding of the data and highlights key patterns and relationships.
- More comprehensive report is avalable in the project folder within
report.docx.
- The original dataset that is used in this project is called 'Breast Cancer Wisconsin (Diagnostic) Data Set' and it can be accessed here.
This project is licensed under the GNU General Public License v3.0 (GPL-3.0) - see the LICENSE file for details.
Let me know if there are any specific details you’d like to adjust or additional sections you want to include!
- Email: kivancgordu@hotmail.com
- Version: 1.0.0
- Date: 23-06-2024