You're welcome to come to this repository. If you like the repository, hope you could give me a Star. If you are interested, the current English translation is in progress. Really welcome the fork project and assist to translate and send PR :)
scraper-fourone-jobs is a anti-scraping cracker for extracting apply information of one of Taiwan famous jobs recruiting website, this program only for learning and researching how to crack anti-scraping, please DO NOT use for commercial.
The reason for creating the project is that saw a question that someone asked how to do scraping for this website in "Python Taiwan Community" of Facebook group, and in the processing of answering, I think that need to write program by myself, and then will know what the detail, even though there are some tips how to crack.
The project was completed in 2019.06.28, and the website will change to other anti-scraping method by the time, so the program will crashed in the future. If you discover the problem, free feel to send a PR or Issue thanks!
The data would lke to scrape and show the HTML source.
- Development enviroment:
vscode - Language version:
Python 3.7 - Package:
pipenv,fonttools,lxml,requests
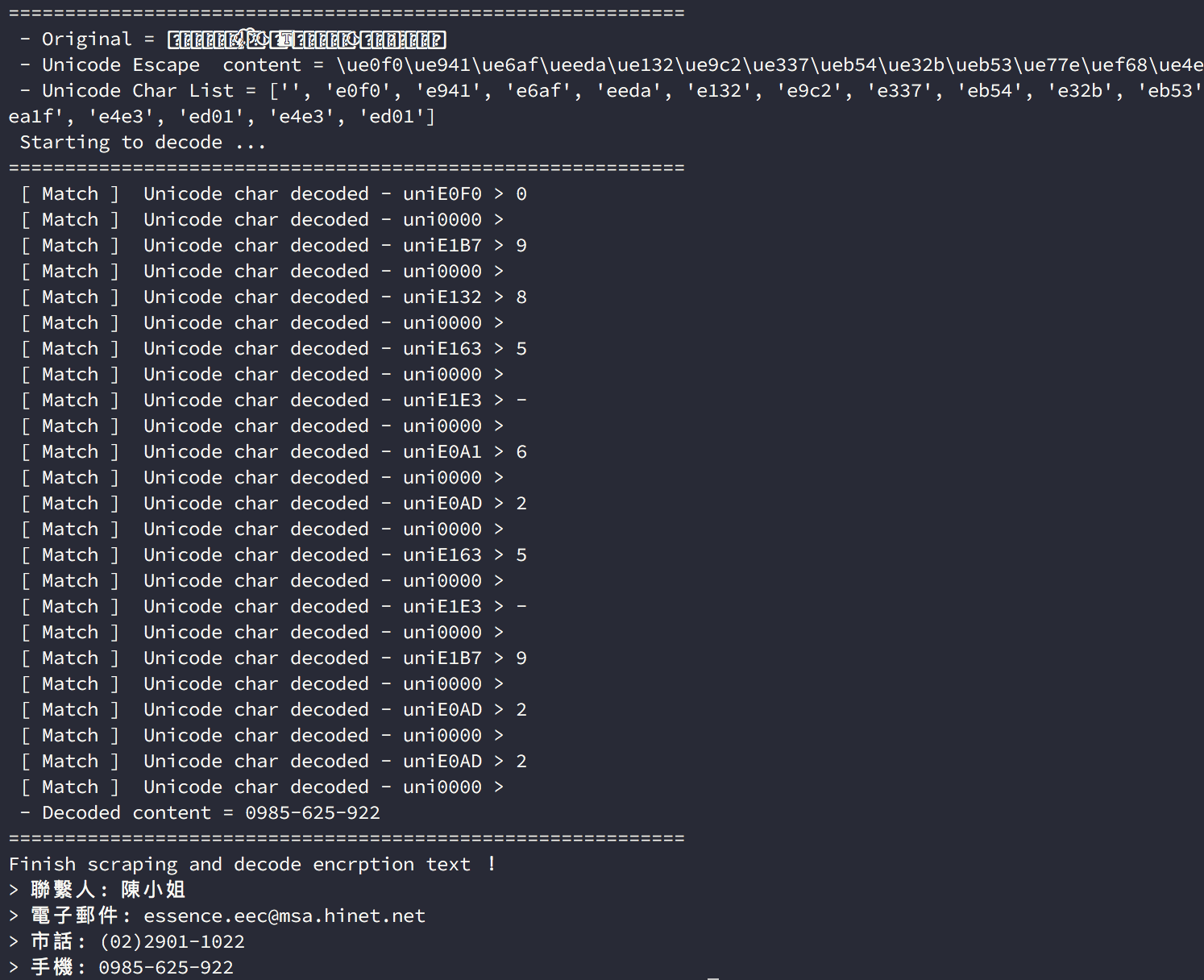
The program which would like to scrape and extract data is from the recruitment page and the data "email", "telephone" and "mobile" could not scrape from correct way like XPATH, it's will show unmeaningful data and encoding, here is the HTML page source as below.
HTML Page Source Content

In anti-scraping, ths situation for showing data correct but HTML page source is unmeaningful and weired content, the reason almost caused by Javascript dynamic handling or CSS font encoding. For the javascript, it could change the content after DOM loaded or some event triggred. In CSS, it could change the text style by CSS attribute.
As time goes by analyzing and reading the source by DevTools, found the possible source is txticon ths class selector from CSS, and discover the user-defined font value 'runes' from font-family attribute:
The CSS style declaration of txticon
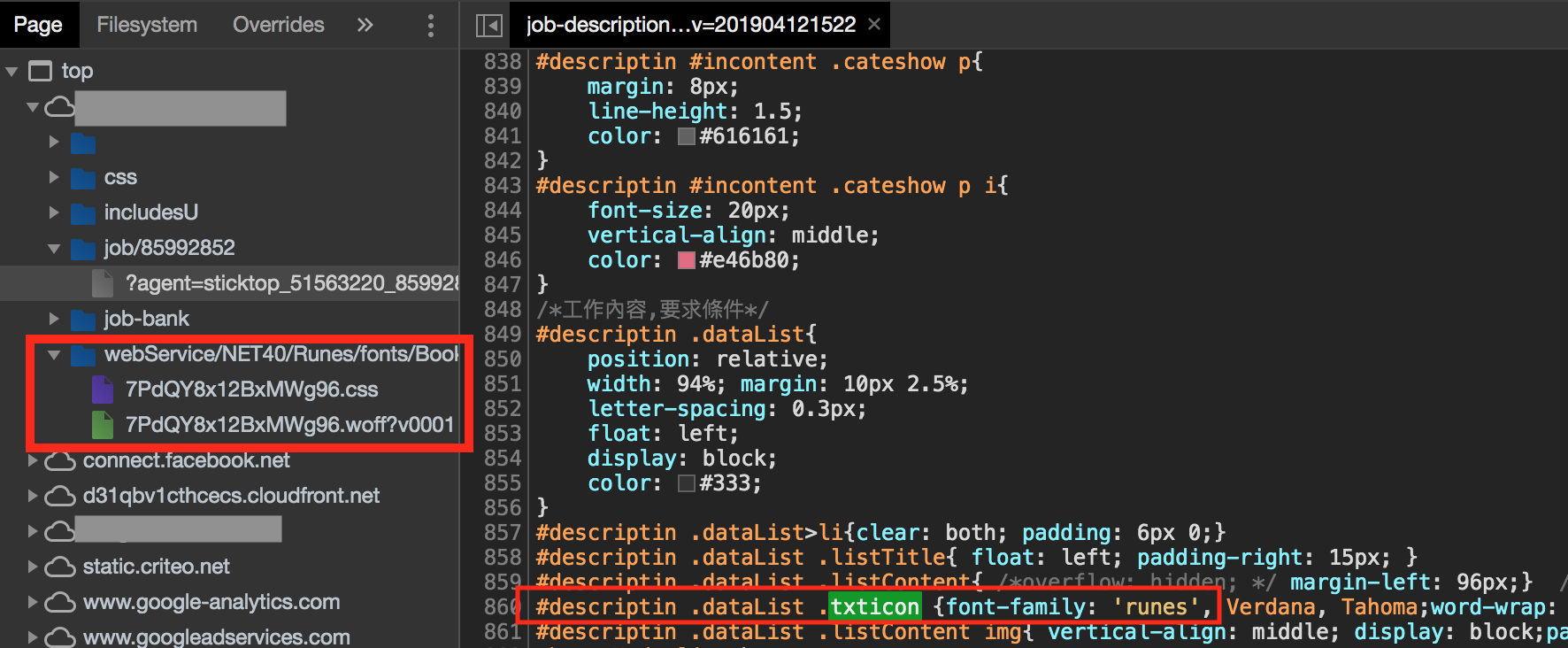
Usually when you found the user-defined font value from font-family, it's means the anti-scraping method from CSS font encoding.
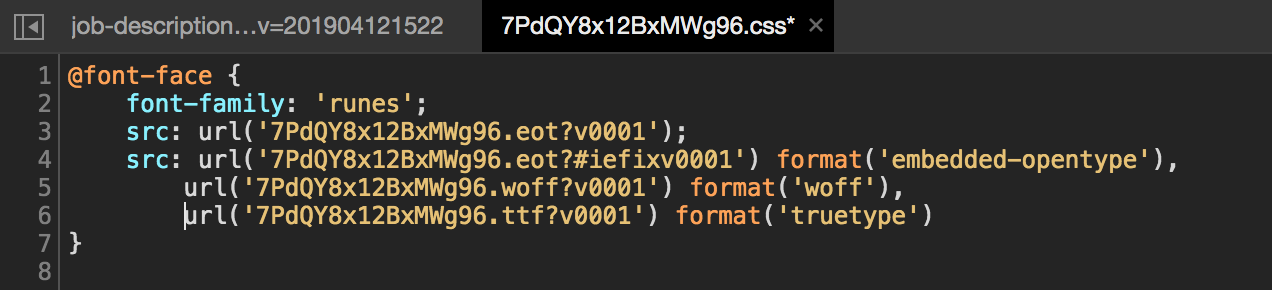
Because the font of font-family is user-defined, the source font file must exsit, so the website could show the correct content. After searching the files location further, there were a path called webService/NET40/Runes/fonts/Books and the user-defined font CSS xxxxx.css was put in here with the font file xxxxx.woff?v0001 and named randomly.
First, open the file which the extension is .css and you will see the font-face attribute and the user-defined value runes. The font-face is CSS3 new property and it could assist the developer providing more types of fonts to users, but the more interesting usuage is that font-face was used for anti-scraping protection.
User-defined font-family font named runes location
And the attribute url could discover which font format was used, but only find (Web Open Font Format), and mapped the file of directory webService/NET40/Runes/fonts/Books, the font extension is .woff?v0001.
But the file name looks like automatically and randomly generated, the encoding of font content also could be different, so I have to download the file more times and check the HTML scraping source font of encoding again for checking the encoding is different or not.
Then copy the font file URL path and download it for tring to analyze the content of font. After we know the rule, we could build a scraper process to automatically download file and parse garbled words, then map word to the encoding for translation to correct contents.
After downloading the font files, then start to analyze the content of font, because the font record different character and the encoding for translating to show character.
Although the words are garbled when we parsed them from HTML, but if we put the garbled words into font file, then the font file will figure out these character of garbled words and map to translate correct character.
This is reason why we need to download the font file first. But the problem is the scraping process not a browser, so we need to make more effort to analyze and parse it by ourself.
After we know the reason, then we start to talk about analysing, if the people use the Windows operation, then suggest to install the software called FontCreator. The software could assist us to understand th contents of font file and visualizing the contents, like we could see the 16 bit Unicode each font.
FontCreator Viewer Sample
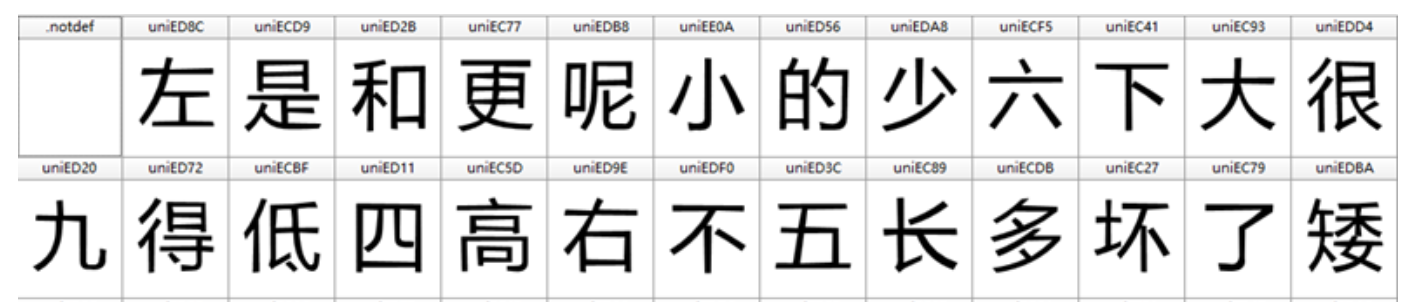
The above image sample are not from "jobs recruiting website", it's another anti-scraping tutorial sample. We'll see the font 左 map to the unicode encoding uniED8C. (The prefix uni we could omit it)
But we could use the FontCreator software on a MacOS, so I recommend to use the website service called FontDrop!. FontDrop! has the powerful functions on viewer, we just need to import font file, now upload the font file downloaded from "jobs recruiting website":
FontDrop! Viewer
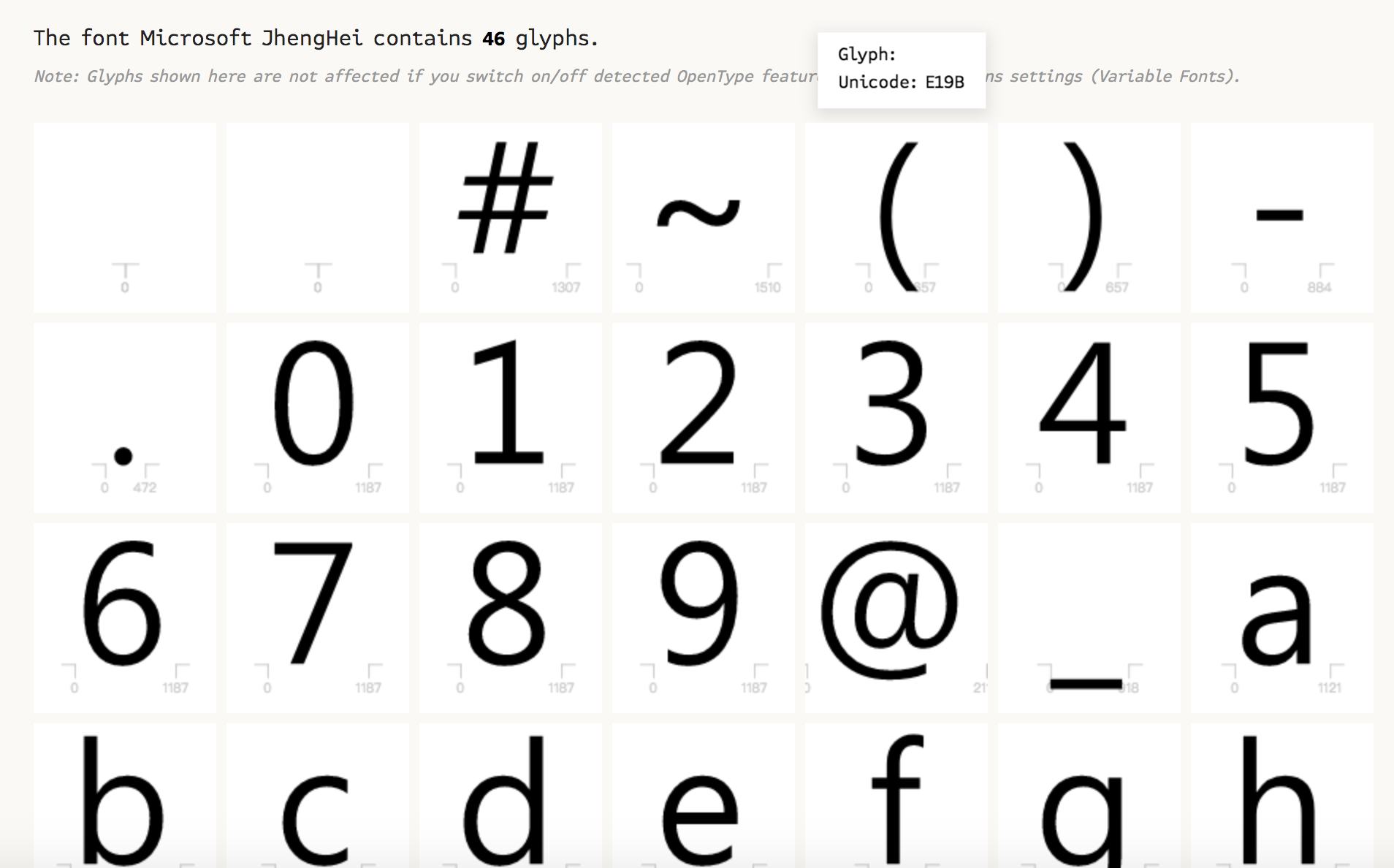
We'll see the different fonts on the above image and all of the font map to one unicode encoding, we could click the font to see the detail information:
FontDrop! Detail Font Viewer
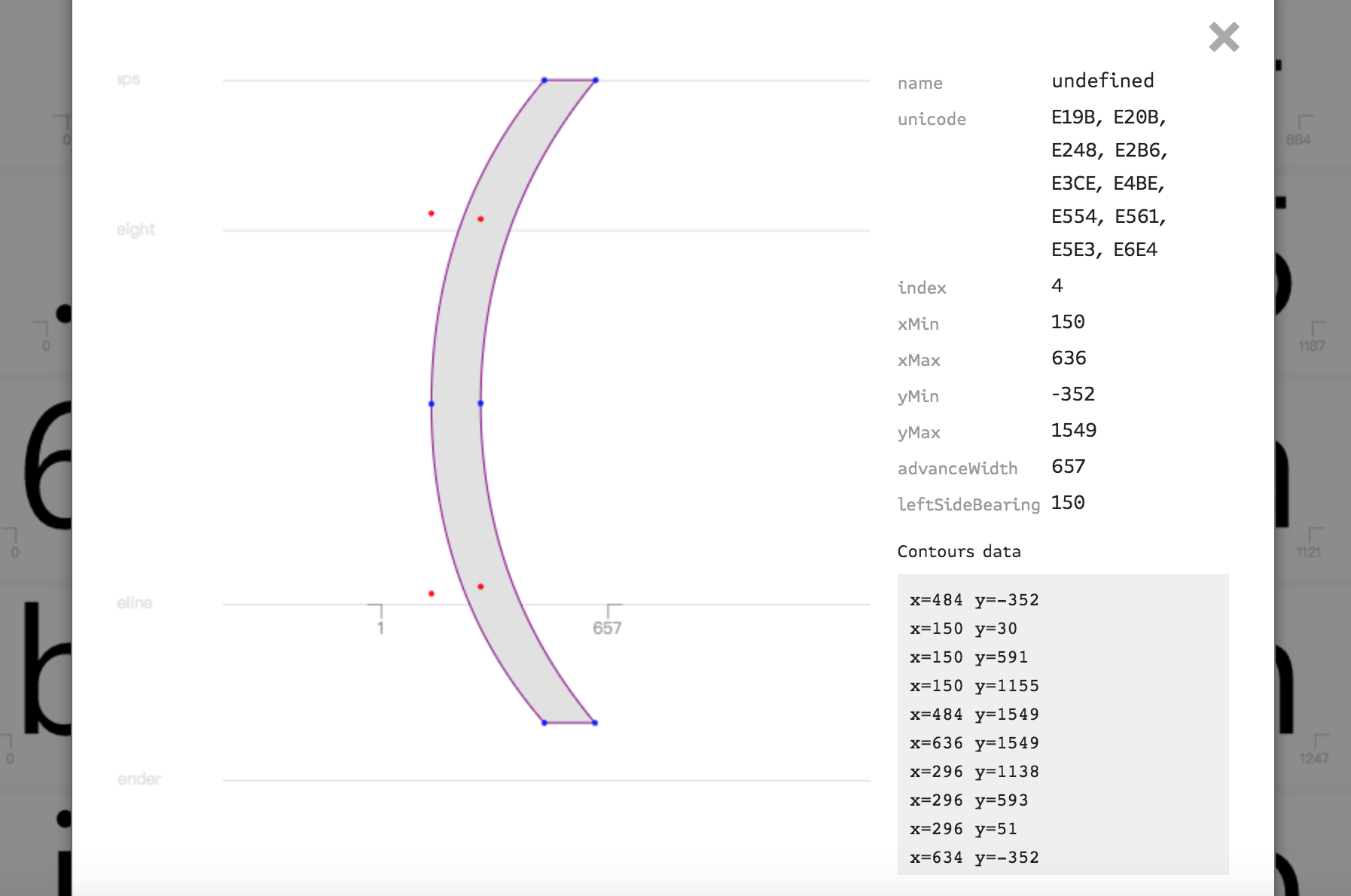
First thing is why there are many unicode encoding? Acutually not only one unicode encoding map to one character in the font file, but each font have a main unicode encoding, like the sample ( map to E19B encoding.
The other two important information is Index and Contours data :
- Index : Means the order of the font list.
- Contours data : Means the contours of the font and will represent by coordinates to draw.
The above two arguments are the keypoint for assisting check the font if CSS anti-scraping difficulty increase, and we'll talk later.
After we know the reason, we could write a program to do it automatically. Install the Python package called fonttools. The package could get the content from font file through reading file path or binary content with TTFont and then saved to XML format with saveXML:
import io
import requests
from fontTools.ttLib import TTFont
...
url = "The URL path of font file "
resp = requests.get(url)
# If read the font file directly => TTFont("Font file path")
font = TTFont(io.BytesIO(resp.content))
font.saveXML("saved file path")The reason for saving to XML format file is that it's still hard to read the right data from fonttools even although we know the content of font by visualizing from FontCreator and FontDrop! tools before.
Because we could not know which methods could find the data we want. and that why we need to save to XML file format first and then call the right method by mapping to the content in the XML.
Here, TTFont could analyze and parse content from font according to different font format. Each font format has different specification to to recording encoding font, like WOFF - Web Open Font Format, TTF - TrueType and EOT - Embedded OpenType and record encoding and description of font with different tags and attributes.
Okay, let's open the saved font file of XML format to analyze the contents.
GlyphOrder and GlyphID tags:These two tags could record the all different fonts orderly. Each tags of GlyphID describe the font through Unicode and Index attribute. The information is the same information as Index int the FontDrop!, so we could know every font meaning through the visualization in the FontDrop!.
Here is a sample that shows the index 4 have a attribute Unicode is uniE19B and after we checking the FontDrop! website, we could know the meaning of font is (
XML Font format - GlyphOrder and GlyphID tags

Now, we could call the getGlyphOrder method to get the contents of GlyphOrder tags by using fonttools package :
# The getGlyphOrder method will return array and the array will show the data orderly according to the index attribue of GlyphID tag in the GlyphOrder parent tag.
orders: List[str] = font.getGlyphOrder()The data after calling the getGlyphOrder method

TTGlyph and contour tags: TTGlyph could record the contour information which mapping to unicode encoding in the GlyphID. The information about contour include the minimum and maximun width of X coordniate, height of Y coordniate width and contour coordinate in contour tag.
Because the fonts in the font file are described and identified by the contour, there won't be any tags telling the word what the word is. It only record the 「Contour」of the word, but we could understand what the text is by using software like FontDrop!, [FontCreator] ..so on and we could also find the contour coordinate in these software.
for example, the previous information shows the tag index of GlyphID is 4 and the Unicode is uniE19B , so we could find the contour information by encoding number uniE19B. Here you could see the contour coordinate is the same as the font ( in the FontDrop!.
XML Font format - TTGlyph and contour tags

In fonttools library, we could get all TTGlyph tags and find the contour information through call get method and set the glyf tag value :
XML Font format - How to get the information of TTGlyph and contour tags

cmap and map tags:
These two tags record the other Unicode encoding of each word in the font, for example 例如這邊的 uniE0AF, 首先 code 屬性會看到同樣是同樣數值的 0xe0af (其中的 0x 可以忽略),而這個 code 屬性表示了其他可以匹配的 Unicode 編碼。
字型 XML 格式 - cmaps 與 cmap 標籤
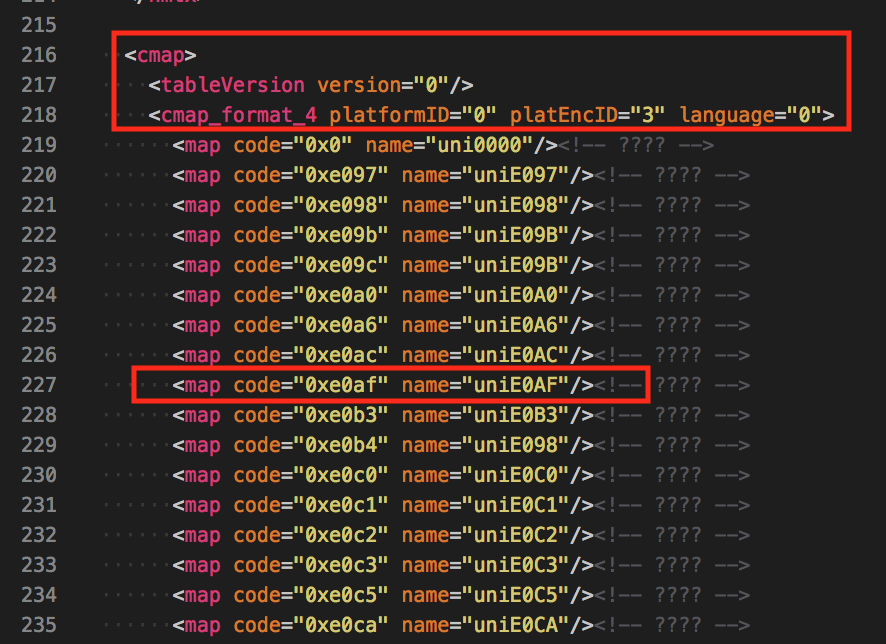
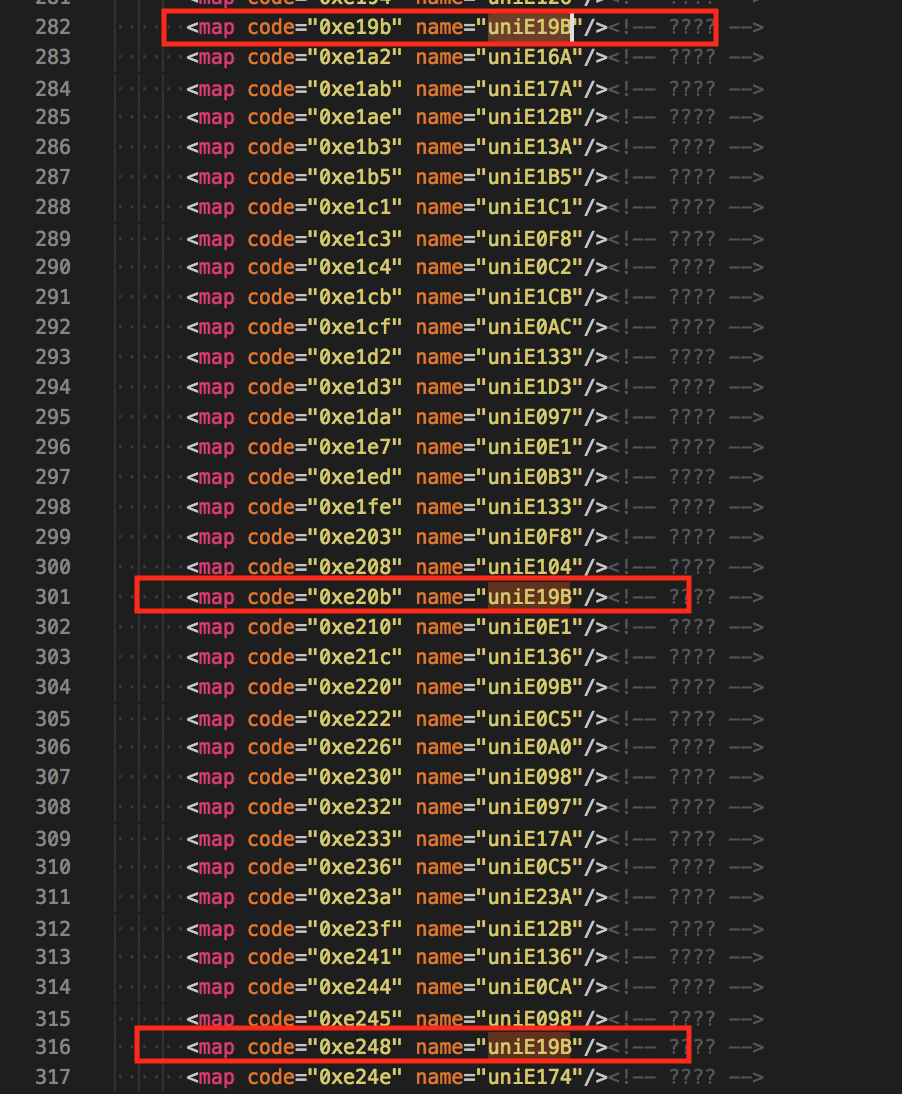
再來尋找原先想要的例子 uniE19B,可以接著看到該字型 ( 其他的 Unicode 編碼,如下圖中除了自己本身的 code 為 0xe19b 外,其他對應到 uniE19B 編碼的 code 包含了 0xe20b 與 0xe248,把這兩個 Unicode 編碼 E20B 與 E248 對照一下 FontDrop! 中便可以找到有一模一樣的數值。
字型 XML 格式 - 其他的 Unicode 編碼
在 fonttools 中,可以透過呼叫 getBestCamp 方法來取得最佳的 cmap 標籤與資訊,因為字型檔案中有對應不同 platform 的版本 - cmap_format_4 與 cmap_format_6。
# 回傳的會是字典格式
orders: Dict[str, str] = font.getBestCamp()getBestCamp 方法取得最佳的 cmap 資訊
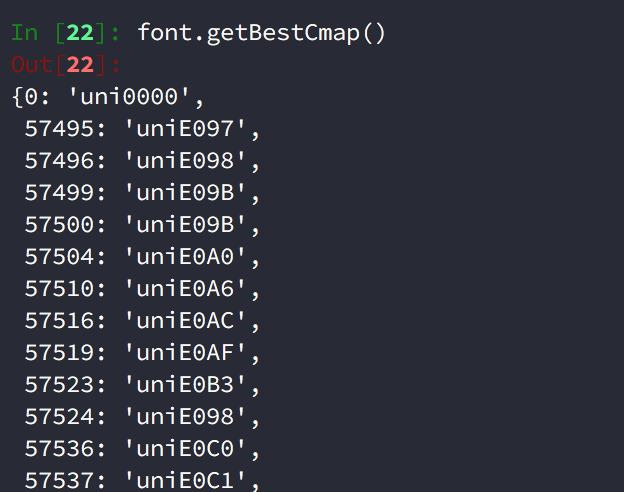
如上圖在 fonttools 中會把 code 轉換成 10 進制的資料,因此原本的 uniE19B 的 code 為 0xe19b 便會轉換成 57755,所以在使用時,要近得處理進制轉換,看是要以十進制比對,還是把 57755 轉換成 0xe19b 比對。
到此這些就是在實作解析字型檔時,可以協助判斷的「標籤」與「屬性」,雖然也可以透過一些軟體,如 FontCreator 或 FontDrop! 以視覺化的方式快速分析字型檔,但是仍建議儲存成 XML 檔案來分析細節。
接下來就來回到一開始爬取下來的亂碼資料,透過先前所介紹的方式來解析與翻譯吧!
雖然在 HTML 源碼看到的亂碼,但那其實代表的只是因為該「編碼」魔有對應的文字而已,所以當抓下來貼到 Python 上時會看到該 Unicode 的編碼,如下圖:
Python 3 顯示該 HTML 源碼字串編碼

不過因為 Python 3 的字串是 Unicode 格式,所以在 Python 中 print 顯示時會被自動轉換,也就看不到原來的編碼樣子。當然在做字串中的字元比對翻譯時也會照成影響,所們可以透過 encode 指定 unicode-escape 跳脫字元協助並轉換回 UTF8 編碼,這樣再對 \\u 做字串切割並依序匹配即可。
藉由 unicode-escape 協助字元比對

知道了如何分析與查看 HTML 亂碼後,再來就要驗證一開始的在2.尋找 CSS 編碼反爬蟲的字型檔中提到的是否每次請求的 HTML 亂碼編碼與字型檔皆不同,並且非常可惜的是沒有錯...每次都會改變編碼:
再次請求後的 HTML 編碼
再次請求後的字型檔

這也使翻爬蟲的麻煩度多了一些,但是好在不同的字型檔的索引順序與字型的輪廓ㄧ致,所以只要透過以下五個步驟便可以解決。
- 每次 Request 請求時,同時取得字型檔案下載。
- 爬取 HTML 內容比透過
unicode-escape編碼處理,與字串切割取得每個編碼。 - 把編碼轉換成 10 進制,透過
fonttools字型套件的cmaps找出代表的編碼,比對原先切割好的 HTML 編碼做 10 進制轉換int("轉換的字串", 16)。 - 在透過代表的編碼找出
GlyphOrder的索引 - 建立一個索引與字型文字的字典匹配並轉換
當然這還算是容易的,如果每次請求下來的字型檔案內部的索引文字順序皆不同,那麼就要透過 TTFGlyph 的 contour 比對字型輪廓座標。
更複雜的,若是連每一次的輪廓座標也不同,那麼步驟五的建立索引與文字字典,就不能使用了,要改成 OCR 做辨認了..。
The source code adopt GNU General Public License v2.0.