Unofficial implementation of SNGAN in PyTorch
Spectral Normalization for Generative Adversarial Networks
https://arxiv.org/abs/1802.05957
Experiments mostly based on the paper.
- Generator: Standard CNN
- Discriminator : Standard CNN
- n_epochs : 321 (approx. 50k G updates)
- n_dis = 5
- Adam parameters : lr=0.0002, beta1=0.0, beta2 = 0.9
- Using training data (10 classes, 50k images)

| Case | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Loss | Cross Entropy | Hinge | Cross Entropy | Hinge |
| Conditional | FALSE | FALSE | TRUE | TRUE |
| Inception Score | 5.844 | 6.077 | 6.094 | 5.821 |
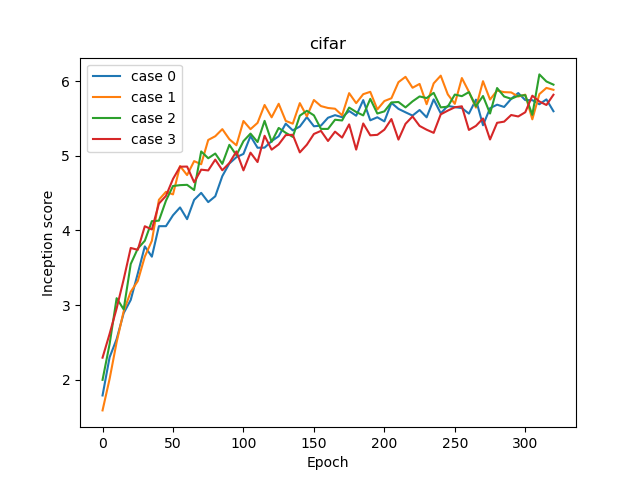
IS = 5.844

IS = 6.077

IS = 6.094 (Best)

IS = 5.821

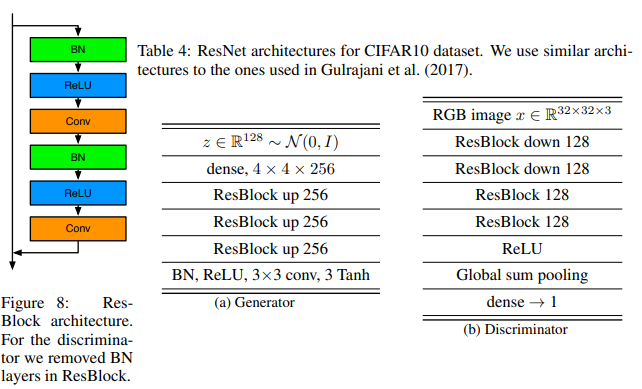
- Generator: ResNet (32x32)
- Discriminator : ResNet (32x32)
- n_epochs : 321 (approx. 50k G updates)
- n_dis = 5
- Adam parameters : lr=0.0002, beta1=0.5, beta2 = 0.9
- Using training data (10 classes, 50k images)
Note: beta1=0.0 failed to converge (seems to stuck into saddle points).
| Case | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Loss | Cross Entropy | Hinge | Cross Entropy | Hinge |
| Conditional | FALSE | FALSE | TRUE | TRUE |
| Inception Score | 3.916 | 5.962 | 3.908 | 5.900 |
Hinge loss performs well.
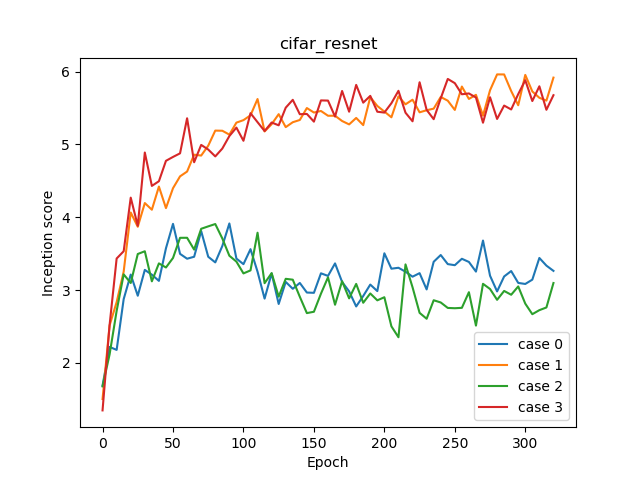
IS = 3.916

IS = 5.962 (Best)

IS = 3.908

IS = 5.900

- Generator: Standard CNN (48x48)
- Discriminator : Standard CNN (48x48)
- n_epochs : 1301 (approx. 53k G updates)
- n_dis = 5
- Hinge loss
- Adam parameters : lr=0.0002, beta2 = 0.9
- Using training + test data (10 classes, 13k (5k + 8k) images)
| Case | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Conditional | FALSE | FALSE | TRUE | TRUE |
| Beta1 | 0.5 | 0 | 0.5 | 0 |
| IS | 5.932 | 6.058 | 6.157 | 5.813 |
GANs in STL-10 is bit difficult than CIFAR-10 (Too sensitive to hyper parameters.).
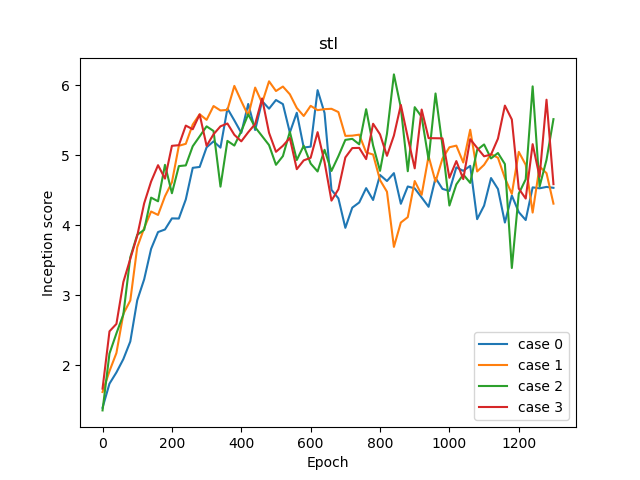
IS = 5.932

IS = 6.058

IS = 6.157 (Best)

IS = 5.813
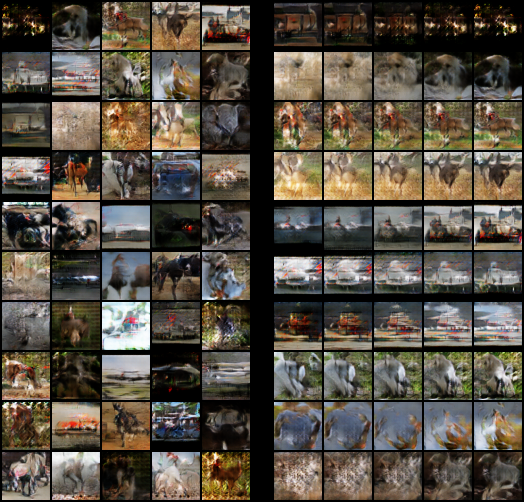
- Generator: Res Net (48x48)
- Discriminator : Res Net (48x48)
- n_epochs : 1301 if n_dis=5, 261 if n_dis=1 (approx. 53k G updates)
- Hinge loss
- Adam parameters : lr=0.0002, beta1=0.5, beta2 = 0.9
- Using training + test data (10 classes, 13k (5k + 8k) images)
| Case | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Conditional | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE |
| N dis update | 5 | 5 | 1 | 1 | 5 | 5 | 1 | 1 |
| D last ch | 512 | 512 | 512 | 512 | 1024 | 1024 | 1024 | 1024 |
| IS | 5.795 | 7.136 | 3.421 | 3.883 | 6.538 | 7.314 | 3.444 | 3.653 |
Trainings in n_dis = 1 are very difficult. Some additional experiments are written in appendix.
IS = 5.795

IS = 7.136 (2nd)

IS = 3.421

IS = 3.883

IS = 6.538

IS = 7.314 (Best)

IS = 3.444

IS = 3.653

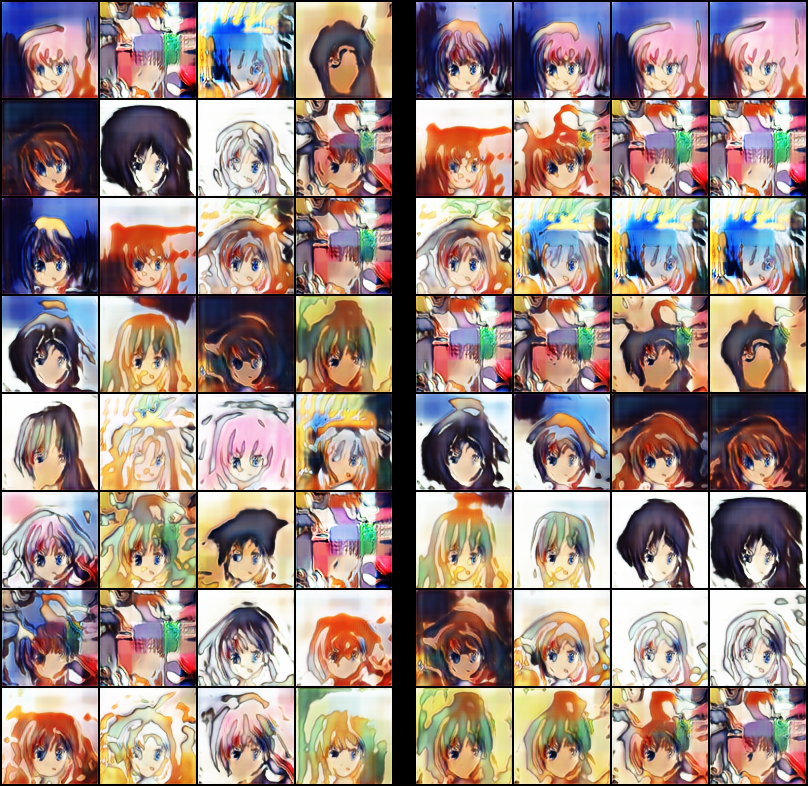
Experiments with datasets that were not written in the paper.
http://www.nurs.or.jp/~nagadomi/animeface-character-dataset/
14490 images with 176 classes. Much less images per class than CIFAR-10 and STL-10.
- Generator: Res Net (96x96)
- Discriminator : Res Net (96x96)
- n_epochs : 1301 (approx. 53k G updates)
- Hinge loss, n_dis = 5
- Adam parameters : lr=0.0002, beta1=0.5, beta2 = 0.9
The network architecture is based on a 128x128 paper and the resolution is changed to 96x96 (dense : 4x4x1024 -> 3x3x1024).

- Case 0 = unconditional
- Case 1 = conditional
Inception score was not measured. Because the domain is different and pre-trained inception is useless.
Sampling and interpolation uses the final epoch model.

http://www.robots.ox.ac.uk/~vgg/data/flowers/
8189 images with 102 classes. Much less images per class than CIFAR-10 and STL-10.
- Case 0 = unconditional
- Case 1 = conditional
Sampling and interpolation uses the final epoch model.


It seems that the generation of flowers is still difficult (outlines are too complicated).
The goal is to train with n_dis = 1, but there are many negative results
- Generator: Post-act Res Net (48x48)
- Discriminator : Standard CNN (48x48)
- Generator leraning rate : 0.0002
For generator, ResNet implementation in the paper was pre-act ResNet (BN / SN-> ReLU-> Conv), but change this to post-act (Conv-> BN / SN-> ReLU).
For discriminator, simply used Standard CNN to reduce computation.
| Case | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| N dis | 5 | 5 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Beta2 in Adam | 0.9 | 0.9 | 0.9 | 0.9 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 | 0.999 |
| Leaky relu slope in D | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.1 | 0.2 | 0.2 | 0.2 | 0.2 |
| D learning rate | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.001 | 0.001 |
| Conditional | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE | FALSE | TRUE |
| Inception Score | 6.419 | 5.663 | 1.285 | 2.634 | 2.342 | 2.447 | 2.499 | 2.722 | 2.355 | 2.544 |
- case 8, 9 = inbalanced learning rate, G:0.0002, D=0.001
| Case | Condition | IS |
|---|---|---|
| 0 | uncoditional n_dis = 5 | 6.419 |
| 2 | uncoditional n_dis = 1 | 1.285 |
| 4 | + beta2 = 0.999 | 2.342 |
| 6 | + lrelu slope = 0.2 | 2.499 |
| 8 | + lr_d = 0.001 | 2.355 |
| Case | Condition | IS |
|---|---|---|
| 1 | coditional n_dis = 5 | 5.663 |
| 3 | coditional n_dis = 1 | 2.634 |
| 5 | + beta2 = 0.999 | 2.447 |
| 7 | + lrelu slope = 0.2 | 2.722 |
| 9 | + lr_d = 0.001 | 2.544 |
It's not good at training with n_dis = 1. Other tunings are also subtle.
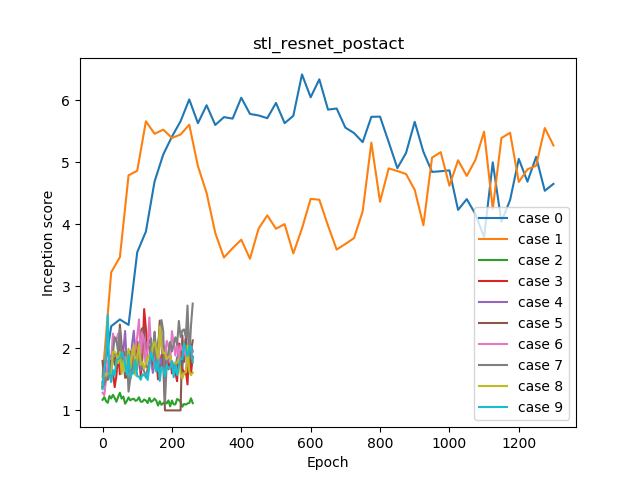
Only a part is described. The rest, please refer to them in the repository folder.
IS = 6.419

IS = 5.663

IS = 2.499

IS = 2.722

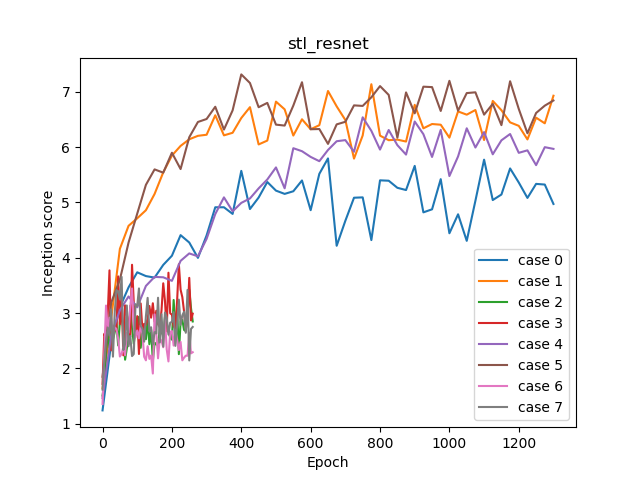
These are loss plot of case 0, 6 (both uncoditional). Case 0(n_dis=5) works well, but case 6(n_dis=1) does not.
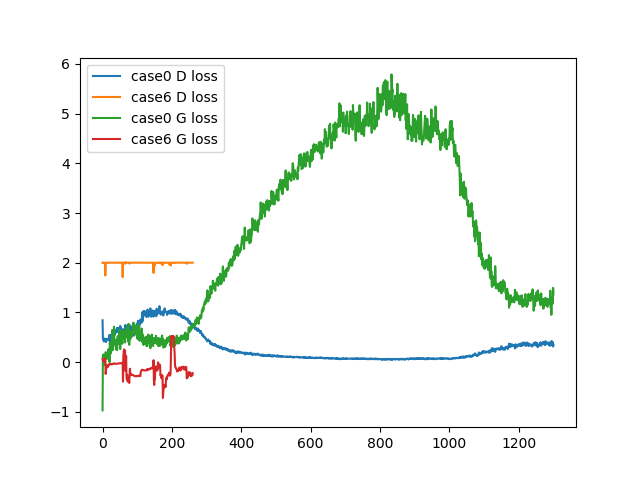
As you can see, the loss of D in case 6 has hardly decreased. If it doesn’t work, G is too strong to learn nothing. This is due to set Spectral Norm in D.
Therefore, n_dis=5 which increases D update is easier to work.
- Generator: Post-act Res Net (48x48)
- Discriminator : Post-act Res Net (48x48, initial ch changeable)
- Generator leraning rate : 0.0002
- n_epochs : 1301 if n_dis=5, 261 if n_dis=1 (approx. 53k G updates)
- Adam parameters : beta1=0.5, beta2 = 0.999
| Case | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| D initial ch | 16 | 16 | 32 | 32 | 64 | 64 |
| N dis | 5 | 1 | 5 | 1 | 5 | 1 |
| Inception Score | 4.621 | 3.004 | 4.789 | 4.365 | 4.990 | 4.341 |
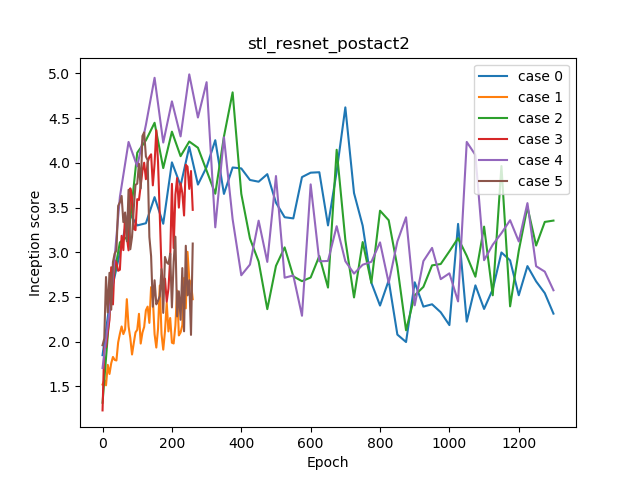
IS = 4.621

IS = 4.789
IS = 4.990

- Generator: Res Net in the paper (48x48)
- Generator leraning rate : 0.0002
- n_dis : 5
- n_epochs : 1301
- All conditional
- Adam parameters : lr=0.0002, beta1=0.5
| Case | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Beta2 in Adam | 0.9 | 0.999 | 0.9 | 0.999 |
| D architecture | postact | postact | strided resnet | strided resnet |
| Inception Score | 5.955 | 5.708 | 6.906 | 7.222 |
Strided ResNet is the original ResNet D with stride conv at the beginning. This reduces the amount of computation.
IS = 5.955

IS = 5.708

IS = 6.906

IS = 7.222 (Best)

Larger D model will improve IS slightly. But in any case, I could not find a way to generate clearly with n_dis = 1.
In image classification, the diffrence between pre-act and post-act is slightly. But in gan, the difference seems to be quite large.