数据库系统的萌芽出现于 60 年代。当时计算机开始广泛地应用于数据管理,对数据的共享提出了越来越高的要求。传统的文件系统已经不能满足人们的需要。能够统一管理和共享数据的数据库管理系统(DBMS)应运而生。1961 年通用电气公司(General ElectricCo.)的 Charles Bachman 成功地开发出世界上第一个网状 DBMS 也是第一个数据库管理系统—— 集成数据存储(Integrated DataStore IDS),奠定了网状数据库的基础。
1970 年,IBM 的研究员 E.F.Codd 博士在刊物 Communication of the ACM 上发表了一篇名为“A Relational Modelof Data for Large Shared Data Banks”的论文,提出了关系模型的概念,奠定了关系模型的理论基础。1974 年,IBM 的 Ray Boyce 和 DonChamberlin 将 Codd 关系数据库的 12 条准则的数学定义以简单的关键字语法表现出来,里程碑式地提出了 SQL(Structured Query Language)语言。在很长的时间内,关系数据库(如 MySQL 和 Oracle)对于开发任何类型的应用程序都是首选,巨石型架构也是应用程序开发的标准架构。
近年来随着互联网的迅猛发展,产生了庞大的数据,也催生了 NoSQL、NewSQL 等新一代数据库的出现。2009 年 MongoDB 开源,掀开了 NoSQL 的序幕,一时之间 NoSQL 的概念受人追捧,MongoDB 也因为其易用性迅速在社区普及。NoSQL 抛弃了传统关系数据库中的事务和数据一致性,从而在性能上取得了极大提升,并且天然支持分布式集群。
然而,不支持事务始终是 NoSQL 的痛点,让它无法在关键系统中使用。2012 年,Google 发布了 Spanner 论文,从此既支持分布式又支持事务的数据库逐渐诞生,。以 TiDB、蟑螂数据库等为代表的 NewSQL 身兼传统关系数据库和 NoSQL 的优点,开始崭露头角。2014 年亚马逊推出了基于新型 NVME SSD 虚拟存储层的 Aurora,它实现了完全兼容 MySQL 的超大单机数据库,于单点写多点读的主从架构做了进一步的发展,使得事务和存储引擎分离,为数据库架构的发展提供了具有实战意义的已实践用例。另外,各种不同用途的数据库也纷纷诞生并取得了较大的发展,比如用于 LBS 的地理信息数据库,用于监控和物联网的时序数据库,用于知识图谱的图数据库等。
与数据库技术的历史发展类似,数据库的托管方式在过去几十年中也发生了很大变化。在网络发展的早期,每个人都必须在自己的物理服务器上运行数据库,EC2 和 Digital Ocean 使这变得更容易,但仍需要深入的技术理解来手动操作数据库。诸如 Heroku 的 Postgres 服务,AWS RDS 和 Mongo Atlas 等托管服务抽象出了许多复杂的细节,数据库管理变得更加简单,但底层模型仍然相同,需要开发人员提前配置计算容量。最新开发的无服务器数据库使开发人员无需担心基础架构,因为他们的数据库只需根据实际使用情况进行扩展和缩小以匹配当前负载,其中 Aurora Serverless 和 CosmosDB 就是一个突出的例子。
对于数据库的期许往往会包含以下几方面,首先是易用与灵活,尽可能可以用贴近业务语言的方式存取数据,而不需要理解太多抽象的语义或者函数;然后是高性能,无论存取皆可以迅速完成;然后是高可用与可扩展,我们能够根据实际的业务需要快速扩展数据库,提供长期的可用性与数据的安全一致,而不会因为数据的爆炸性增长导致数据库的崩溃。
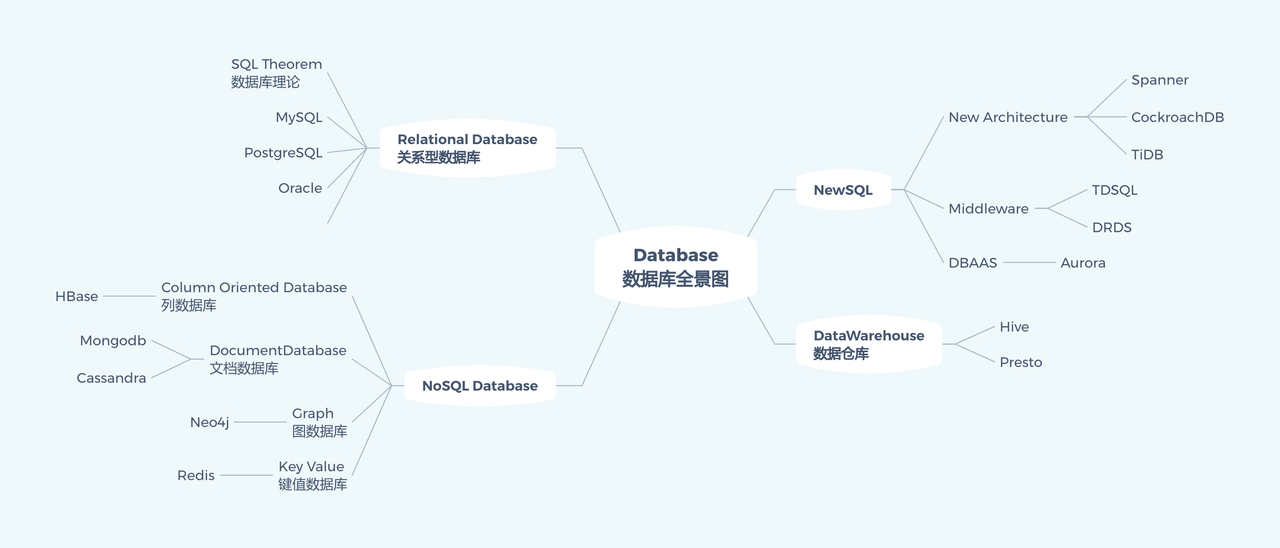
以 Oracle, MySQL, SQLServer, PostgreSQL 为代表的关系型数据库,以行存储的方式结构化地存储数据。搜索引擎擅长文本查询;与 SQL 数据库中的文本匹配(例如 LIKE)相比,搜索引擎提供了更高的查询功能和更好的开箱即用性能。文档存储提供比传统数据库更好的数据模式适应性;通过将数据存储为单个文档对象(通常表示为 JSON),它们不需要预定义模式。列式存储专门用于单列查询和值聚合,在列式存储中,诸如 SUM 和 AVG 之类的 SQL 操作要快得多,因为同一列的数据在硬盘驱动器上更紧密地存储在一起。而 OceanBase, TiDB, Spanner/F1 等 NewSQL 数据库兼具了 SQL 以及可扩展性,数据被拆分成一个个 Range,分散在不同的服务器中,通过增加服务器就可以一定程度上的线性扩容;其通过 Paxos 或者 Raft 保证多副本之间的一致性,通过 2PC,MVCC 支持不同隔离级别的事务等。

实际上,各个数据库之间也并发泾渭分明,多模异构是指在单个数据库平台中支持非结构化结构化数据在内的多种数据类型。一直以来,传统关系型数据库仅支持表单类型的结构化数据存储和访问能力,而对于层次型对象、图片影像等半结构化与非结构化数据管理无能为力。如今,随着应用类型的多样化和存储成本的降低,单一数据类型已经无法满足许多综合性业务平台的需求。数据库层面的多模异构和非结构化数据管理,将能实现结构化、半结构化和非结构化数据的统一管理,实现非结构化数据的实时访问,大大降低了运维和应用的成本。同时,非关系型数据库在访问模式上也渐渐将 SQL、K/V、文档、宽表、图等分支互相融合,支持除了 SQL 查询语言之外的其他访问模式,大大丰富了过去 NoSQL 数据库单一的设计用途。
本篇即是希望能够概述常见数据库的使用与内部原理,让我们对数据库有更深入的理解。
笔者所有文章遵循 知识共享 署名-非商业性使用-禁止演绎 4.0 国际许可协议,欢迎转载,尊重版权。如果觉得本系列对你有所帮助,欢迎给我家布丁买点狗粮(支付宝扫码)~

您可以通过以下导航来在 Gitbook 中阅读笔者的系列文章,涵盖了技术资料归纳、编程语言与理论、Web 与大前端、服务端开发与基础架构、云计算与大数据、数据科学与人工智能、产品设计等多个领域:
-
知识体系:《Awesome Lists | CS 资料集锦》、《Awesome CheatSheets | 速学速查手册》、《Awesome Interviews | 求职面试必备》、《Awesome RoadMaps | 程序员进阶指南》、《Awesome MindMaps | 知识脉络思维脑图》、《Awesome-CS-Books | 开源书籍(.pdf)汇总》
-
编程语言:《编程语言理论》、《Java 实战》、《JavaScript 实战》、《Go 实战》、《Python 实战》、《Rust 实战》
-
Web 与大前端:《现代 Web 全栈开发与工程架构》、《数据可视化》、《iOS》、《Android》、《混合开发与跨端应用》
-
服务端开发实践与工程架构:《服务端基础》、《微服务与云原生》、《测试与高可用保障》、《DevOps》、《Spring》、《信息安全与渗透测试》
-
数据科学,人工智能与深度学习:《数理统计》、《数据分析》、《机器学习》、《深度学习》、《自然语言处理》、《工具与工程化》、《行业应用》
此外,你还可前往 xCompass 交互式地检索、查找需要的文章/链接/书籍/课程;或者在 MATRIX 文章与代码索引矩阵中查看文章与项目源代码等更详细的目录导航信息。最后,你也可以关注微信公众号:『某熊的技术之路』以获取最新资讯。