🌏 English | Chinese |
Everyone has their own habits when it comes to using language. For those with strong habits, we can often identify the author of a document or email by human judgment alone, even if the document or email is unsigned. However, some people’s writing habits are more subtle, making it difficult to identify the author manually. In such cases, building a Machine Learning model can help solve the problem.
Text Learning uses Machine Learning techniques to analyze the types of words in a document and their frequency to build a model that can distinguish between different authors.
The Enron Dataset contains numerous email documents. By selecting emails from Chris and Sara as senders, we can apply Machine Learning to a subset of these emails to build a model that can identify whether an email is from Chris or Sara based solely on its content, even without knowing the sender.
For a more detailed explanation of the algorithm used in this program, please click here
This program runs on Python 3.6.0 and uses the nltk, numpy, scipy, sklearn, pandas, and matplotlib libraries.
In the Terminal, enter: git clone https://github.com/linhung0319/text-learning.git
Run the main program svm_author_id.py located in the svm folder.
The Enron Dataset emails from Chris and Sara are processed as follows
Only the content of the emails is retained.
The content is then processed with stemming and TFIDF transformation to obtain the importance weight of each word.
The main program uses preprocessed data files, word_data.pkl and email_authors.pkl. To generate these processed data files, you need to download the Enron Dataset:
-
Run startup.py to download and extract the Enron Dataset into the ./maildir directory.
-
Run pickle_email_text.py to process the raw data into word_data.pkl and email_authors.pkl.
-
Run pickle_email_text.py
- Perform stemming on the text content of the emails using parse_out_email_text.py.
- Save the processed text as a list in word_data.pkl.
- Save the corresponding authors for each word as a list in email_authors.pkl.
-
email_preprocess.py
- Reads word_data.pkl and email_authors.pkl and performs TFIDF transformation on the words to calculate the importance weight of each term.
- Removes words that appear too frequently (as they are not representative).
- Splits the words and their corresponding authors into a Training Set and a Testing Set.
A model is constructed using the Support Vector Machine (SVM) algorithm to determine whether an email belongs to Sara or Chris based on the words used in the email.
Adjust the SVM parameters to find the best result for classification accuracy (Tuning Parameters in SVM).
Use the coefficients of the SVM Hyperplane to identify the words with the highest discriminative power for classification (Top Features).
Calculate the accuracy of the SVM classification results (Accuracy Score, Confusion Matrix, Precision, Recall Score).
-
Run svm_author_id.py
- Test different SVM parameters to achieve the highest classification accuracy (find_best_param).
- Use the optimal SVM parameters to build the email classification model.
- Identify the most important words for email classification in this SVM model.
- Calculate the model's accuracy.
-
plot_gallery.py
- Plot the classification accuracy of the SVM model for emails under different parameters.
- Create plots showing the most important words for determining whether an email belongs to Sara or Chris in the SVM model, along with their relative weights.
- Accuracy Score of the SVM Model with Different Parameters
The figure below shows the Accuracy Score when using C and gamma as tuning parameters under the linear kernel and rbf (Gaussian distribution) kernel, using only 1/10 of the Training Data (approximately 200 emails).
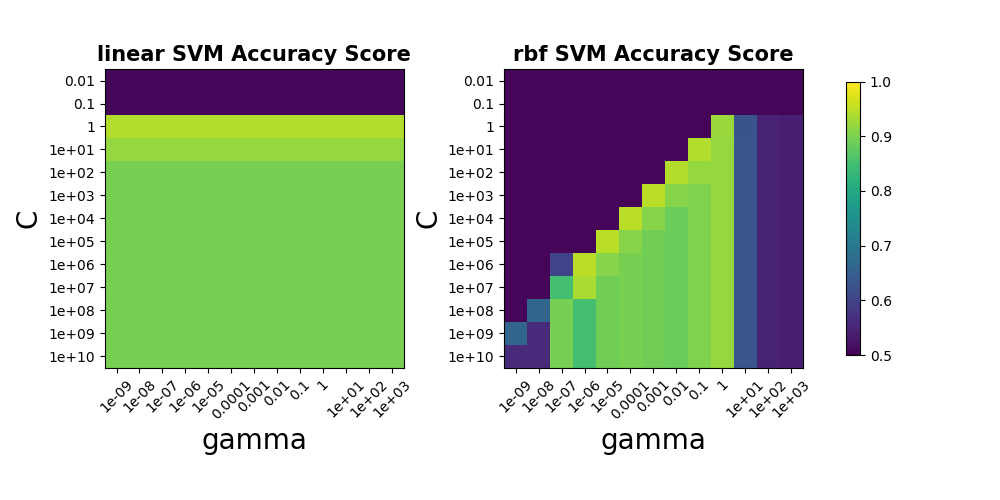
Typically, SVM models use the rbf kernel to build the model. However, when the feature dimensions of the data are very high, it is often unnecessary to project the samples into a higher-dimensional space; a linear hyperplane can usually be found directly in the current dimensions.
As seen in the figure, because the Word Feature dimension is as high as 1708, the accuracy of the SVM model with the linear kernel is not lower than that of the rbf kernel.
Since identifying the most discriminative words from the linear kernel SVM model is simpler, the linear kernel SVM is used for analysis.
- Identify the Most Discriminative Words
The figure below shows the top 20 most discriminative words for emails from Sara and Chris.
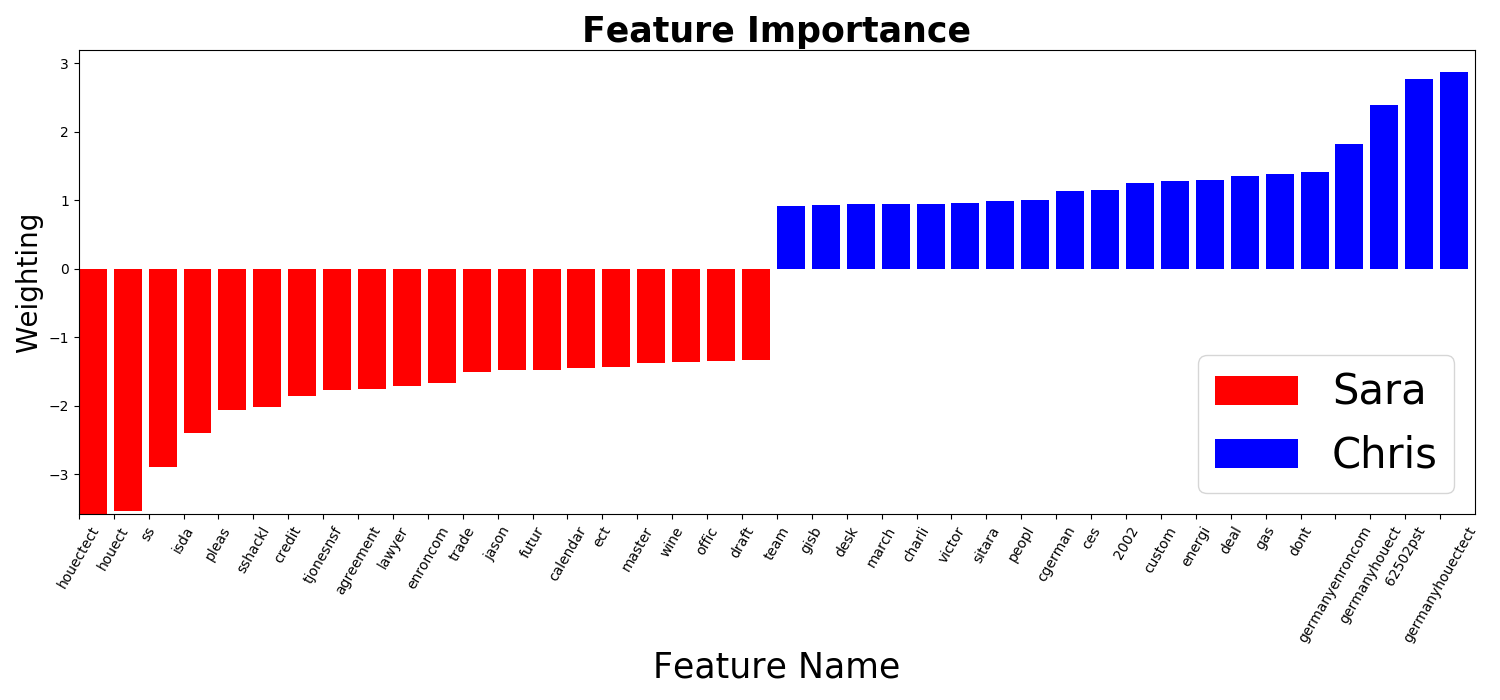
The hyperplane normal vector in a linear kernel SVM can be seen as the direction that best classifies the data. If a particular dimension (word) has a large weight in this direction, it indicates that this dimension (word) is highly effective at classifying the data; conversely, if the weight in this direction is small, it means that this dimension (word) is less effective and less important.
Therefore, by examining the hyperplane normal vector of the linear kernel SVM, you can determine which words in the emails are most influential in classification based on their weights.
- Analyze the Accuracy of the SVM Model
- Accuracy Score = 97%
- Number of successfully classified emails / Total number of emails
- A high Accuracy Score indicates that the model is very effective at distinguishing between Sara's and Chris's emails.
| Confusion Matrix | Predicted Sara | Predicted Chris |
|---|---|---|
| True Sara | 7568 (TP) | 312 (FP) |
| True Chris | 146 (FN) | 7795 (TN) |
-
Precision Score = 96%
- TP / (TP + FP)
- A higher Precision Score indicates a lower probability of Sara's emails being misclassified as Chris's emails.
-
Recall Score = 98%
- TP / (TP + FN)
- A higher Recall Score indicates a lower probability of Chris's emails being misclassified as Sara's emails.
Since the Precision Score is slightly lower than the Recall Score, it indicates that Sara's emails are more likely to be misclassified as Chris's emails. Therefore, this model is more effective at distinguishing Chris's emails than Sara's.
The Confusion Matrix also clearly shows that, with approximately equal numbers of emails from Sara and Chris, there are 312 instances of Sara's emails being misclassified as Chris's, while there are 146 instances of Chris's emails being misclassified as Sara's.
The main algorithms of this program, including the data processing methods before building the analysis model and the use of SVM to build the analysis model, are based on the Udacity Nano Degree course Intro to Machine Learning
The method for adjusting different SVM parameters is based on the sklearn example page
The method for identifying the most discriminative words (Word Features) in email text is based on Visualising Top Features in Linear SVM with Scikit Learn and Matplotlib
If you have any questions or suggestions about this project, feel free to contact me:
- Email: linhung0319@gmail.com
- Portfolio: My Portfolio
- Linkedin: My Linkedin