Replication
The replication service runs on top of the store. The store itself is agnostic to replication. On startup, a replication manager starts up some threads and allocates partitions to these threads. The thread is then responsible for replicating the partition from remote nodes. The assignment strategy of partition to threads is done in such a way to isolate data centers and increase batching. A typical replication for a replica of partition A in one machine with another replica involves the following steps -
Initially, replica 2 has a subset of messages in replica1. Also, replica 2 remembers the offset in replica 1 till which it has seen the content and replicated them locally if they were missing.

Replica 2 then initiates a metadata exchange with replica 1. This call returns all the new blob ids that were put in replica 1 since the offset specified.

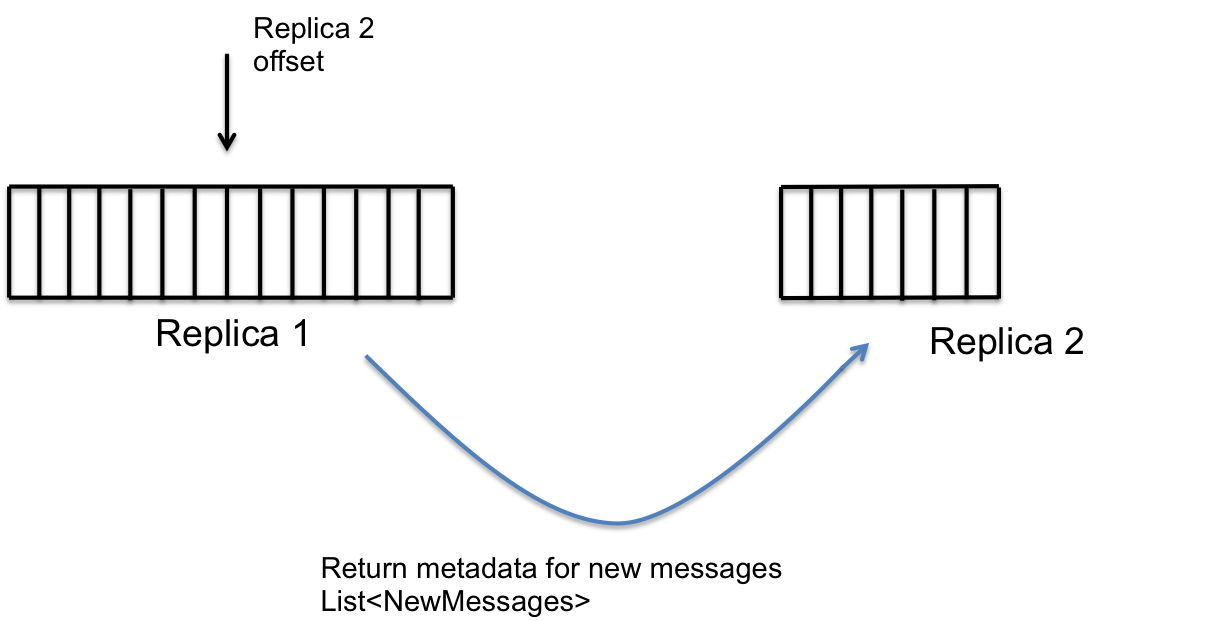
Replica 2 then scans the ids and looks up its local store to find if the blob is missing. The reason that the blob could be available is because replica 2 could have got the blob from the router or from another replica. Replica 2 makes a list of blobs that it does not have.
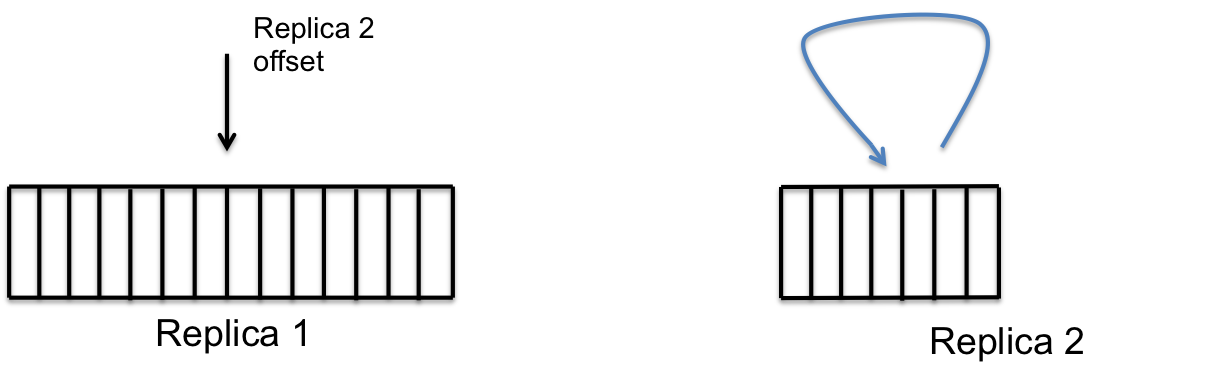
Replica 2 then send a request to replica 1 to send all the messages that are missing. Replica1 sends all the messages in a single batch that replica 2 writes to its store.



This is a simplified version of the actual protocol. There are more optimizations such as zero copy, crc checking, prioritizing higher lag etc in the actual implementation. This gossip protocol helps Ambry to converge really fast.