This repository connects the two theoretical computer science disciplines formal languages and automatons with
the rather technical discipline of compiler construction (F.A.C.).
The goal is to specify a new programming language, which is deterministic and executable.
It contains the language specification, as well as possibilities to execute the toy-language from
the terminal or from a mini-IDE (implemented with javafx).
- Language design
1.1 Scope
1.2 Lexical rules
1.3 Syntactical rules
1.4 Semantic rules
1.5 Execution - Repository handling
2.1 Clone
2.2 Package structure
2.3 Run with console
2.4 Run with gui
2.5 Generate
In this section, the language design will be documented with its rules and a few examples.
Our new toy language design has roughly following scope:
- variable declarations and assignments
- string concatenation
- arithmetic expressions
- conditional expressions
- conditional statements
- loops
- function calls
- function definitions
- built-in print function
It is a type safe programming language with three available data types: strings, numbers and booleans, while
null will never be an acceptable value.
Classes and other complex concepts are not supported.
The look-and-feel will be Java-like. Here's a small code sample:
number one = 1;
while (one < 5) {
one += 1;
print('hello world');
}
Lexical rules are applied when the toy code is scanned by the Scanner. During this process, one or multiple
characters will be transformed to so-called tokens (i.e. words of the code). There is a limited set of allowed tokens,
meaning that unknown tokens will result in an error automatically.
The scanner used in this repository was generated with jflex. It can be found in the
package src\main\java\scanner.
The token identification is implemented with regular expressions.
// sample section of .flex file
== { return collectToken(EQ, "EQ"); }
\!= { return collectToken(NEQ, "NEQ"); }
>= { return collectToken(GREQ, "GREQ"); }
\<= { return collectToken(LEQ, "LEQ"); }
Java-like comments are allowed. They will be ignored in further processing of the code.
Pattern: \/*[^\*]~\*\/ | \/\*(\*)+\/ | \/\/[^\r\n]*(\r|\n|\r\n)? | \/(\*)+[^\*]*(\*)+\/
Whitespace may consist of spaces and newlines. It will be ignored in further processing steps, but
is initially useful to separate tokens from each other.
Pattern: [ \t\f\r\n]+
Reserved words are: string, number, boolean (for data types), while, break,
if, else, def, return (for statements) and print (for printing to the console).
Boolean values may be either true or false.
Numeric values will be interpreted as Double. The length will not be checked.
Pattern: -?[0-9]\d*(\.\d+)?
Strings may contain lowercase letters, digits and a few special characters. They must be enclosed
in apostrophes.
Pattern: '[a-z0-9_\,\.\(\)\;\:\/\+\-\*\/ \s\t\f\r\n]*'
Variable identifiers may consist of lowercase letters, underscores and optional digits at the end.
Pattern: [a-z_]+([0-9])*.
Additionally, there is a set of basic operators.
- Arithmetic operators:
+,-,*,/,%. - Conditional operators:
==,!=,<,>,<=,>=. - Assignment operators:
=,+=,-=,*=,/=,%=. - Evaluation operators:
&&,||. - Unary operators:
-,++,--,!.
Finally, there are two types of brackets: (, ), {, }, as well as the comma ,
and the infamous semicolon ;.
Syntactical rules are applied by the Parser. During the processing of the code, it will receive token by token
from the scanner. The parser then validates if the sequence of tokens follows the defined grammatical rules (e.g.
a statement must stop always with a semicolon). If the code is valid, the parser will organize the identified components
in a so called 'parse tree', which will be handy for further processing.
The parser used in this repository was generated with cup. It can be found in the
package src\main\java\parser.
The syntactical rules are designed in the form of the Backus-Naur-notation, which allows context-free validation only.
// sample section of .cup file
ASSIGN ::= VAR:e1 ASSIGN_OP:op EXPR:e2 STOP {: RESULT = Statement.assgn(op, e1, e2); :}
;
ASSIGN_OP ::= EQUAL:op {: RESULT = op; :}
| PLUSEQ:op {: RESULT = op; :}
| MINEQ:op {: RESULT = op; :}
| DIVEQ:op {: RESULT = op; :}
| MULEQ:op {: RESULT = op; :}
;
- Variable declarations must start with a data type (
string,numberorboolean). - The data type is followed by an identifier and an equal character.
- Then, a value is assigned. The value can be:
- a string, number or boolean value according to lexical definition.
- another variable identifier.
- an arithmetic or conditional expression.
- a string concatenation.
- a function call.
- omitted. in this case, the equal character is omitted as well and the variable would get its default value (
'',0.0orfalse).
- The variable declaration must end with a semicolon.
- As the parser is context free, the data types of variable and assigned value cannot be evaluated further at this step.
Sample code:
string x1 = 1; // valid (no type safety yet)
number y; // valid (variable will get default value)
number y7 = (true && false); // valid (conditional expressions can be assigned)
boolean 1z7 = (true && false); // scanner fails, as variable identifier starts with a digit
string x8 = fun1(); // valid (function calls can be assigned)
number y8 = print(); // parser fails, as print is a reserved word
- Variable assignments share the rules of variable declarations, except:
- the preceding data type must be omitted.
- a value must be assigned.
- arithmetic assignment operators are additionally allowed.
- incrementing or decrementing (
++or--) is allowed at this place only.
Sample code:
x1 = 1 + true; // valid (no type safety yet)
y; // parser fails, as a value must be assigned
x1++; // valid
y7 = (true && false); // valid (conditional expressions can be assigned)
x8 = fun1() // parser fails, as semicolon is missing
- Expressions in general cannot exist as isolated statement. They need to be part of a declaration or be assigned.
- Arithmetic expressions are meant to perform numeric calculations. Therefore, they use specific operators (
+,-,*,/,%). - For string concatenation, the
+operator is allowed. - By default, their components can be either 'raw' values, expressions or function calls.
- Precedence is handled as follows:
- unary expressions have highest precedence.
- multiplications, divisions and modulo operations follow.
- then, addition, subtraction follow.
- conditional expressions will always be in brackets, thus precedence must not be handled specifically.
- assignments have least precedence.
- if not handled otherwise, precedence applies left to right.
- Expressions must never have brackets, except they are conditional expressions.
- As expressions can be potentially assigned anywhere.
- Also here, data types are not evaluated any further.
Sample code:
1 + 2 // parser fails as expression cannot be isolated
x = 1 + 2 - 3; // valid, interpreted as ((1 + 2) - 3)
x = 2 * 4 + 2 / 3; // valid, interpreted as ((2 * 4) + (2 / 3))
x = fun(); // valid (function calls can be assigned)
x = 'x' + 'abc'; // valid (will result in string concatenation)
x = 123 + true; // valid (no type safety in parser)
x = (1 + 2); // parser fails, as brackets are not allowed
- Conditional expressions are quite similar to generic expressions, except they must be enclosed in (round) brackets.
- Conditional expressions use comparing (
<,<=,==, ...) or evaluating (&&,||) operators. - Strings can be compared with
==. - Conditional expressions or boolean values can be switched by exclamation marks. The exclamation marks cannot be placed before the outer brackets if a conditional expression is used in a if-then or while statement.
Sample code:
x = (true || false); // valid
x = (1 < 2); // valid
x = true && true; // parser fails, as brackets are missing
x = (true && true && false); // parser fails, as round brackets must always enclose two components
- Function calls consist of an identifier, followed by an opening round bracket, arguments, a closing bracket and a semicolon.
- Arguments can be zero, one or multiple (comma separated) expressions.
- Without the semicolon, a function call can be used as value within an expression, as it is expected to always have a return value.
Sample code:
fun1(); // valid (no parameter)
//fun() // parser fails, as semicolon is missing
fun2(1 + 2 + 4); // valid (expression as one parameter)
fun3(true && false); // valid (condition as parameter - in this case, one set of brackets is enough)
fun3((true && false), 1, 'abc'); // valid (multiple parameters)
fun(fun()); // valid (but probably not nice)
Print calls work the same way as function calls, except:
- they cannot have multiple parameters.
- they do not have any return value. Therefore, they cannot be assigned to variables or be used in expressions.
Sample code:
print(); // valid (no parameter)
print(1 + 2 + 4); // valid (expression as one parameter)
print(1 + 2 + 4, 'x'); // parser fails, as multiple parameters are not allowed
print(fun()); // valid
x = print(); // parser fails, as print calls cannot be used in assignments
- Function definitions must start with the
defkeyword, a data type and an identifier. - After the identifier, a parameter declaration list (which must be enclosed in round brackets) follows.
- This declaration list can be empty or consist of one or multiple declarations.
- A parameter declaration consists of a data type and an identifier.
- After the parameter declarations, curly brackets open and close.
- The function body may contain zero, one or multiple nested statements.
- Just before the curly brackets are closed, a return statement must be placed.
- The return statement consists of the return keyword, a return value (an expression) and a semicolon.
Sample code:
def number fun() { return 1; } // valid (minimal example)
boolean fun() { return x; } // parser fails, as def keyword is missing
def fun() { return 1 + 1; } // parser fails, as data type is missing
def string fun() { } // parser fails, as return keyword is missing
def boolean f1(string x) { // valid
print(x);
return x;
}
- Conditional statements must start with the
ifkeyword and a conditional expression (in round brackets). - Then, a body in curly brackets follows, which can contain zero, one or more statements.
- Optionally, an
elsekeyword may follow, with another body as above.
Sample code:
if (true) {} // valid
if (1 < 2) {}; // parser fails, as no semicolon is allowed at end
if (false) { // valid
print('x');
} else {}
- while loops must start with the while keyword and a conditional expression (in round brackets).
- Then, a body in curly braces follows, which can contain zero, one or more statements.
Sample code:
while (true) {} // valid (but maybe not smart)
while false {} // parser fails, as conditional brackets are missing
while (false) { // parser fails, as body is not closed
while (false) { // valid
print('x');
}
- Statements are basically all grammatical structures, which do not require another surrounding construct to be valid.
They always must end with a semicolon (if they do not end with a body in curly brackets). Implemented statements are:
- variable declarations
- variable assignments
- function calls (including print calls)
- function definitions
- conditional statements
- while loops
- Additionally, break statements do also count as statements. They are meant to be used within while loop bodies. As they cannot be strictly at the end of a while body (they could be nested deeper within if-then-structures), the parser will not perform any further syntactical validations in this case.
- Nested statements are a list of statements. This is a helper structure to fill bodies of conditional statements, while loops and function definitions.
- Function definitions must be 'top level' components (e.g. it is not possible to nest them in a while loop).
- ll 'top level' statements and function definitions will finally be added to the program statements list.
Sample code:
x; // parser fails, as this is not a statement
number x = 1 // parser fails, as semicolon is missing
if (true) {
def number x() { // parser fails, as function definitions may not be nested
return 0;
}
}
- The program is a container for the 'top level' list of program statements.
- If the parser finishes without error, the program will be the root of the generated parse tree.
So far, our toy language is defined and we have the tools to validate if a code belongs to our language or not. But at this point, there is no type safety, variables can be assigned before they are declared and break statements are a mere decoration.
The required semantic validation must now be performed by a Validator (see src\main\java\validator).
The validator will receive the parse tree from the parser and traverse it depth-first.
- A variable must be declared before it can be referenced.
- he same rule applies to function definitions and function calls.
- Identifiers are valid within the same and lower levels of the parse tree, starting from the location where they are declared. Within nested scope, they can be overwritten by local variables.
- Identifiers must be unique within their scope, except for function identifiers, which can be overloaded.
Sample code:
number x = 1; // valid
y = x; // validator fails as y was not instantiated
def string fun(string z) { // valid
return z;
}
x = z; // validator fails, as z is out of scope
- A variable can only assign values of the declared type.
- A function must return the same type as it defines as return value.
- If expressions are nested, the types are evaluated for every segment (assignment has least precedence).
- If a segment of an expression is a string, the resulting type will be cast to a string, if possible.
- String casting will not work within subtractions, multiplications, divisions and conditional expressions.
Sample code:
string x = 1 + 2 + 'a'; // valid (nesting & string casting)
number y = true; // validator fails, as boolean is assigned to number type
x += true; // valid (string casting)
x = true; // validator fails, string casting can only occur in binary expression
x = 1 * 2; // validator fails, string casting can only occur in binary expression
def number fun() { // validator fails, as returned string is not a number
return 'x'; }
- In assignments, the operator
=can be used for all data types,+=for numeric and string values, other operators (-=,*=,/=,%=) for numeric values only. - In conditional expressions,
==and != may be used for all types,!,&&and||may used for boolean values only, comparing operators (<,<=,>=,>) can be used for numeric values only. - In expressions,
+is valid for numeric values or if at least one of the components is a string. All other available operators (-,*,/,%) are for numeric values only.
Sample code:
string x = 'x' + 'b'; // valid
x = 'x' - 'b'; // validator fails, as minus cannot be used for string concatenation
boolean y = (true && 1); // validator fails, as the binaryOperator && can be used for booleans only
boolean z = (1 < 2); // valid
x = 1 * 'x'; // validator fails, multiplication binaryOperator is not valid for strings
- In general, both operands of a binary expression must have the same type.
- The only exception is string casting.
- The resulting value of a conditional expression must always be a boolean, generic expressions can evaluate to all data types.
Sample code:
string a = '1' + 'abc' + '2'; // valid
string b = a + true; // valid (string casting)
number c = 1 + true; // validator fails, as not both operands are of type numeric
number d = 1 + 2 * 3 % 5; // valid
boolean e = (true && !false); // valid
boolean f = (true || 2); // validator fails, as second operand is numeric
- The declared return type must match the effective return type.
- A function is identified by its identifier, return type, parameter count and parameter types. This means, overloading is possible.
- Overloading may occur only, if the identifier matches, the return type matches and parameter count differs.
- If a caller calls a function, the callee must have according parameter count, parameter types and return type.
- A function can call itself, thus, recursion is allowed.
Sample code:
def number x() { // validator fails, as 'seven' is a string
return 'seven'; }
def number y() { // valid
return 0; }
def number y() { // validator fails, as function y() is already defined with 0 params and same return type
return 1; }
- part from the break statement validation, no additional semantic validation is required in this case, as the syntactical checks are sufficient.
- Break statements are only allowed within while loops, and never as top-level-statement.
- Per while loop and nesting level, one break statement is allowed.
- Exception: if a break loop contains an if-then-else statement, two breaks are allowed.
- A break must be the last statement of a statement list, but can be nested within other statement lists. Thus, a simple validation for unreachable code occurs at this place.
Sample code:
break; // validator fails, as break statement is dangling outside loop
while(true) { // validator fails, as there is unreachable code
break; number x = 1; }
while(false) { // valid
break; }
The 'execution' is handled by the Interpreter during runtime (i.e. no compilation occurs). It can be found in the
package src\main\java\execution. It is built on a validator, which means that it will automatically also
validate code semantically before execution - even if the code itself will never run (e.g. in a dead if-then-else branch).
Please note that global variables and function definitions must be declared always before being referenced. Thus, declarations must be placed always before callers (not like Java, where global variables and functions may be defined anywhere in a file).
In the execute mode, code will be processed character by character, in one go.
In the console mode, entered code will be validated after pressing ENTER on a blank input line. This means, multiple lines
can be entered before validating (e.g. line breaks are allowed in between complex statements).
If an entry is not valid, it will be rejected, the user may then try again (so far valid code will remain in memory).
After every ENTER, the whole so-far-valid code is validated, which means the parse tree may be built multiple times.
Also, only the last print statement may be actually printed, to give the user a scripting-like experience.
In the gui mode, code can be executed at once by pressing on the button go, or by editing the input, if the input ends with two newline characters.
If the go button is used, the mini-IDE may open the execution or validation tab, and - in case of errors - select the faulty input section (if possible).
In general, exceptions and errors are supposed to be catched by the application. The purpose is to allow the user to apply corrections for the next run. In case an exception or error occurs, an according message (if possible) and the stack trace will be visualized. Following incidents are taken to account:
- Unknown tokens will throw errors during scanning.
- The parser may throw an exception if the parse tree cannot be build.
- Semantic validation may throw more specific exceptions.
- During runtime, arithmetic exceptions and stack overflow exceptions may occur.
One edge case is an infinite while loop. If discovered, a stack overflow error will be thrown to avoid the program to hang.
This section contains a few technical notes about this repository.
Clone the repository with following command.
git clone https://github.com/lpapailiou/fac <target path>
The code is written in java 8.
Once the repository is cloned, maven may take care about the build, plugins and the dependencies. The javafx dependency will
not be handled by maven.
You may also just download the jar file from latest release.
Below, the structure of the package tree is listed for better overview.
+ src
+ main
+ java
+ exceptions // custom exceptions
+ execution // code execution handling by interpreter
+ main // --> starts program
+ parser // syntactical analysis
+ parsetree // parse tree components
+ scanner // lexical analysis & token generation
+ validator // semantic validation
+ resources
+ lib // external dependecies (jflex & cup)
+ samples // code sample files
By default, a start within the IDE or by a double click on the jar file, the graphic user interface will be launched.
The console mode can be started, if the jar file is started from within the command line of your os.
The restriction is, that an additional argument must be used.
Build the jar file yourself or download directly. Then run it with following command:
java -jar fac.jar <argument>
The main class Main has to be run with options to use the terminal. If ambiguous options (i.e. 'press any key') are given,
the interactive console mode will be launched.
There's also a small menu available which provides some orientation:
// output of help menu (accessed with -h)
Following options are available:
-o scan
-o parse
-o validate
-o execute
-o gui // with this method, the javafx gui is launched
Optionally you may enter a file path after the mode.
If a file path follows the mode, this specific file will be processed. Otherwise, a sample file will be run.
Several sample files are available in the directory src\main\resources\samples.
The scanner will take a file and tokenize its content. The output is verbose, every processed token will be printed accordingly to the console.
// sample output
scanning token {NUMTYPE}: found match <number> at line 1, column 0.
scanning token {VAR}: found match <one> at line 1, column 7.
scanning token {EQUAL}: found match <=> at line 1, column 11.
scanning token {NUM}: found match <1> at line 1, column 13.
scanning token {STOP}: found match <;> at line 1, column 14.
[...]
...end of file reached at line 1, column 1.
The parser will initialize a scanner. During processing, the parser will take token by token and validate if
the sequence follows the syntactical definition of the grammar. If no error occurs, the parser will generate
a parse tree. This means, that the syntax of the scanned code is valid.
Additionally to the parse tree, it will print the parsed code to the console.
// sample output
[...]
***** PARSE TREE *****
$ Program
$ StatementList
$ ProgramStatement
$ Statement
$ VariableDeclaration
$ Type
$ number
[...]
***** PARSER RESULT *****
number one = 1;
while (one < 5) {
one += 1;
print('hello world');
}
This mode will run a parser as above. As soon as the parse tree is ready, the validator will traverse the tree and validate semantic rules.
// sample output
[...]
***** SEMANTIC CHECK SUCCEEDED *****
The interpreter is built on an validator. The process is similar to the validator mode, but the interpreter will similarly validate and execute the interpreted code.
// sample output
***** EXECUTION RESULT *****
>>>> hello world
>>>> hello world
>>>> hello world
>>>> hello world
The console mode starts an interpreter in the console. This version is interactive. For every entered code block, the whole so-far valid code will be scanned, parsed, interpreted and directly be executed.
In case of an error, the last entry will be ignored. New code can be added to the so-far valid code.
The console mode can be escaped with -h or -q.
// sample output
(press -h for help or -q to quit)
**************************************************************
* WELCOME TO JLANG *
**************************************************************
> ... initialized & ready to code! // from here on, user input is accepted
> number one = 1;
> while (one < 2) {one += 1; print('hello world'); }
> // empty line triggering execution
>>>> hello world
>
To run the gui, you may do so directly from the IDE or from the jar file. The jar file must be started by double click or without arguments within the terminal:
java -jar fac.jar
The mini-IDE is implemented with javafx, which may be a restriction depending on the java version you use.
There are multiple options to input code.
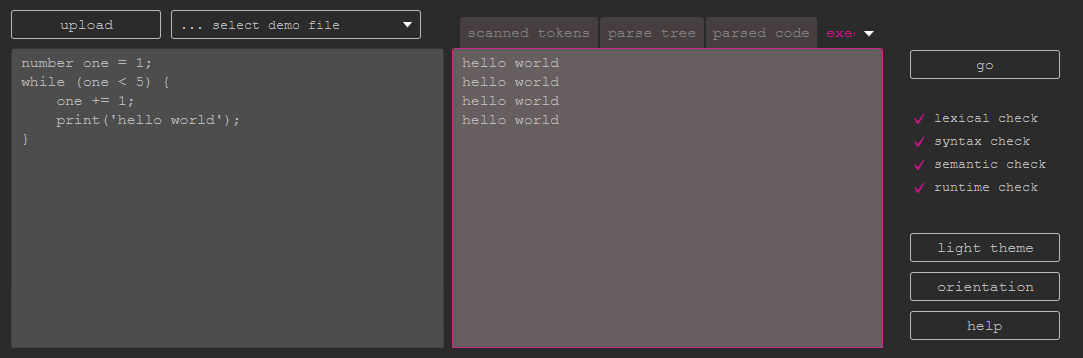
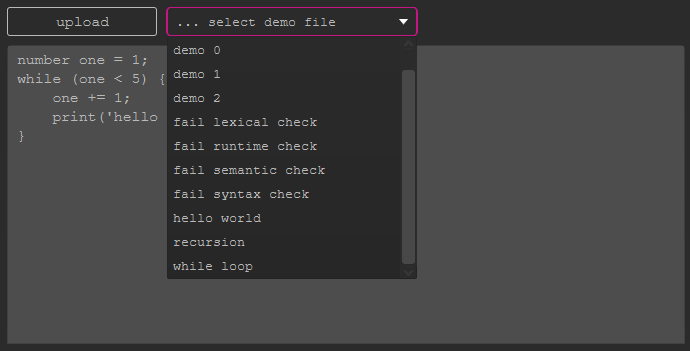
You may enter code directly to the primary text area. Alternatively, you may upload
a file or choose a demo file provided by the according combobox. The available demo files are the ones from the directory src\main\resources\samples.
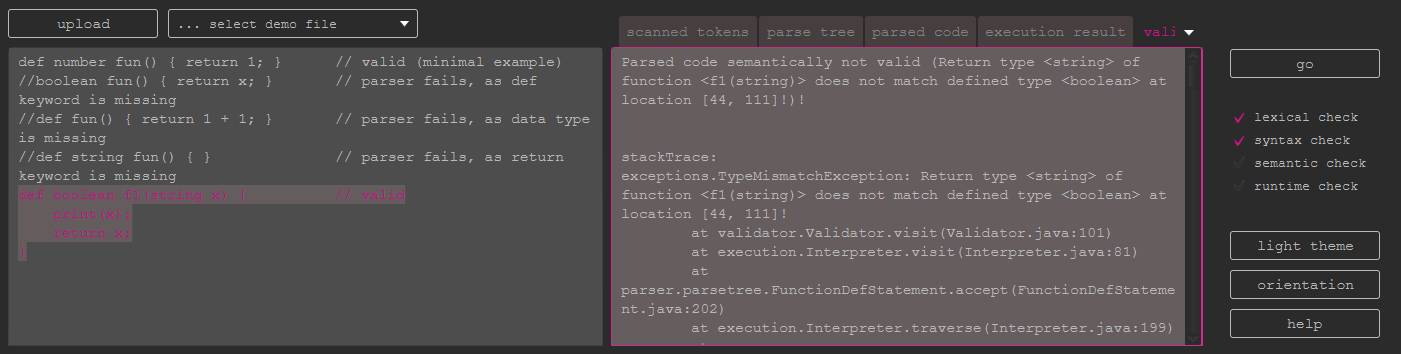
If the input is validated and turns out to be invalid, the invalid section will be highlighted.
If code is edited manually and the code ends with two newlines, the code will be processed dynamically while
you are typing.
In this case, the tabs won't switch automatically, so you can observe the tab of your choice.
The secondary area is split up in multiple tabs. It will show the results of the processing of your code in the order of processing.

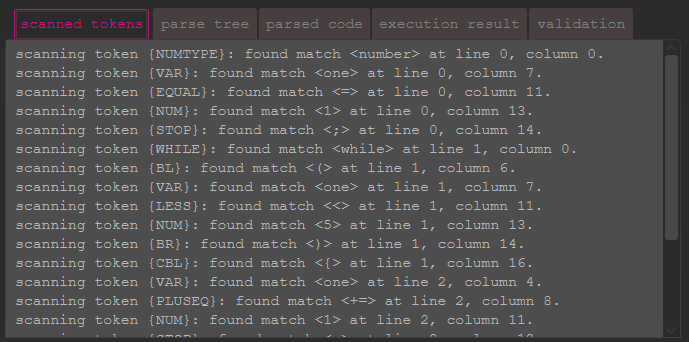
In this tab, the scanned tokens are listed in the order of scanning.
All tokens appearing are valid. If an error occurs, the according token is hinted specifically.
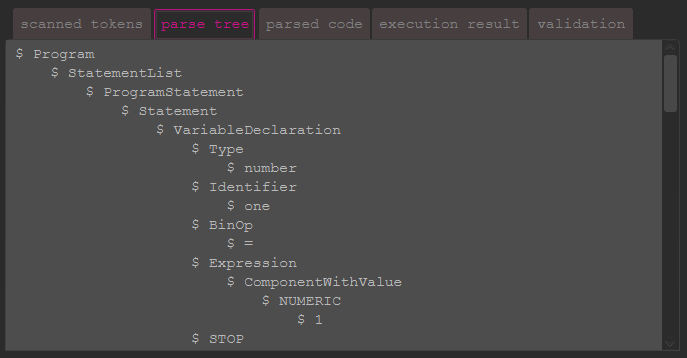
This tab shows a visualization of the parse tree. The format does whether completely match the parse tree of the parser, nor the structure of the classes generated while parsing. The result is basically a close-as-possible reconstruction. Important is: if the parse tree could be generated, the syntax of the code is valid.
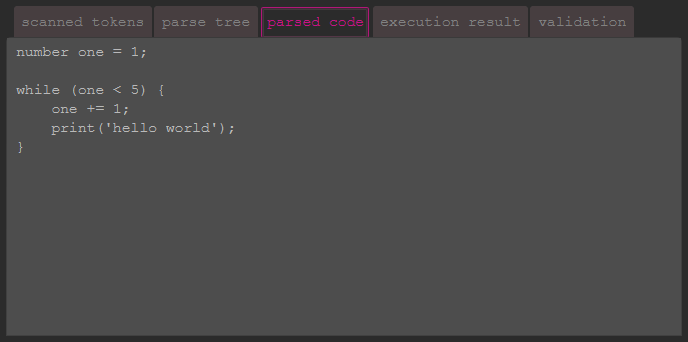
This tab shows the code as pretty-printed interpretation of the input by the parser.
It should match the input, except the comments and excess whitespaces / line breaks are gone.
Also here: if the code is visible, the syntax of the code is valid.
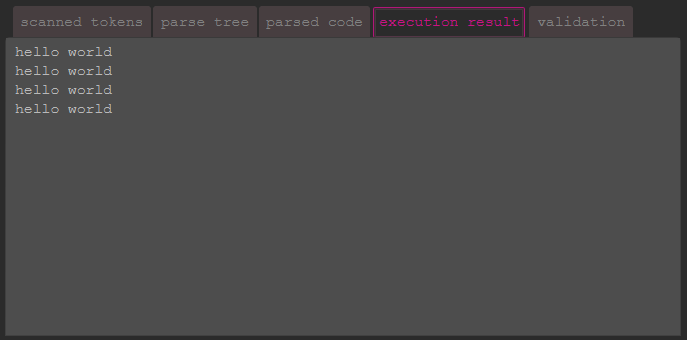
This is probably the most interesting tab, as it shows the result of the execution of the code.
If it appears, it means that all validations (lexical, syntax, semantics) were successful. At this point,
it is still possible that runtime errors occur (e.g. stack overflow, division by zero, etc.).
This is the 'annoying' tab, as it will open as soon as something went wrong. It will show a short error message and reveal further details about the problem. The stack trace is printed additionally. With this tab, the toy code can be debugged if needed.
The mini-IDE has also a little 'action area', which should improve usability.
The code processing can be triggered at once by pushing the button go. As soon as the input is
validated, check marks will indicate if the processing was successful, or - if not - at which step the problem occurred.
Additionally, a tab switch is triggered by the go button. If the code is valid, it will show the execution result, otherwise
the validation tab.
Furthermore, there are additional minor features:
- The theme can be switched between dark mode and light mode.
- The orientation of the split pane an be switched (vertical vs. horizontal).
- The help button will open this very page for easy access to additional information.
In case you may want to modify the language rules, the scanner and parser can be generated easily with following commands.
To generate a new scanner from the flex file, run following command (java path must be set).
java -jar src/main/resources/lib/jflex-full-1.8.2.jar src/main/java/scanner/jscanner.flex
Or use following maven command:
mvn jflex:generate
Here's the link to the external jflex documentation.
To generate a new parser from the cup file, run following command (java path must be set).
java -jar src/main/resources/lib/java-cup-11b.jar -interface -destdir src/main/java/parser/ -symbols JSymbol -parser JParser src/main/java/parser/jparser.cup
Or use following maven command:
mvn cup:generate
Here's the link to the external cup documentation.