- Part 3 Screenshots
- Part 2 Screenshots
- Part 3 Terminal Outputs
- Terminal log output from running
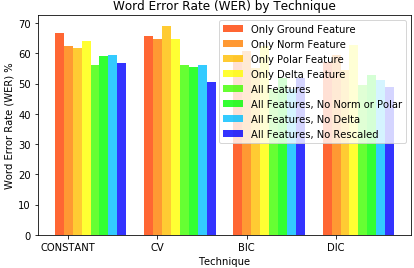
main.pyfor Model Selectors including Constant, CV, BIC, and DIC against ground, norm, polar, and delta Feature Sets are included in:part3_results/log_features_originals.md - Terminal log output from running
main.pyfor Model Selectors including Constant, CV, BIC, and DIC against All Features Sets (i.e. ground, norm, polar, and delta), All Features Sets (excluding Norm and Polar), All Features Sets (excluding Delta), and All Features Sets (excluding Rescaled), are included in:part3_results/log_features_all_and_withouts.md
- Terminal log output from running
-
Use Python 3.4 or higher
-
IntelliJ: File > Project Structure > Project Settings > Project > Project SDK > Python 3.6.0 (~/miniconda3/bin/python)
-
IntelliJ: Preferences > Editor > File Types > Python
- Add *.py
-
Switch to Miniconda env
source activate aind(same steps as in https://github.com/ltfschoen/aind/blob/master/README.md)
-
Install dependencies
python3 -m pip3 install mypy typing
python3 -m pip3 install numpy scipy scikit-learn pandas matplotlib jupyter
python3 -m pip3 install git+https://github.com/hmmlearn/hmmlearn.git
-
Run with
jupyter notebook asl_recognizer.ipynband wait for browser to open -
Select a snippet of code and go to menu
- "Kernel" > "Restart & Clear Output"
- "Kernel" > "Restart & Run All"
-
Debug using IntelliJ breakpoints (instead of time-consuming iPython) by setting up configurating that runs
main.py -
Troubleshooting
- If get errors in Jupyter Notebook, it may be becaue
compiled .pyc files are out of sync with .py files. Try resolving by
deleting .pyc files
rm *.pycand restarting the Jupyter notebook
- If get errors in Jupyter Notebook, it may be becaue
compiled .pyc files are out of sync with .py files. Try resolving by
deleting .pyc files
Build system that recognizes words communicated using American Sign Language (ASL). Given a preprocessed dataset of tracked hand and nose positions extracted from video. Goal is to train a set of Hidden Markov Models (HMMs) using part of the given dataset to try and identify individual words from test sequences.
Optional challenge is to incorporate Statistical Language Models (SLMs) that capture the conditional probability of particular sequences of words occurring, in order to help you improve the recognition accuracy of the system.
Project Specification Checklist https://review.udacity.com/#!/rubrics/749/view
Complete each of these parts by implementing segments of code as instructed, and filling out any written responses to questions in markdown cells. Make sure you run each cell and include the output. The code must be free of errors and needs to meet the specified requirements.
-
PART 1: Data
-
Prepare data for modeling
-
- Student provides correct alternate feature sets: delta, polar, normalized, and custom.
-
- Student passes unit tests.
-
- Student provides a reasonable explanation for what custom set was chosen and why (Q1).
-
-
-
PART 2: Model Selection
-
Implement model selection techniques
-
- Student correctly implements BIC model selection technique in "my_model_selectors.py".
-
- Student correctly implements DIC model selection technique in "my_model_selectors.py".
-
- Student correctly implements CV model selection technique in "my_model_selectors.py".
-
- Student code runs error-free in notebook, passes unit tests and code review of the algorithms.
-
- Student provides a brief but thoughtful comparison of the selectors (Q2).
-
-
-
PART 3: Recognizer
-
Recognize ASL words
-
- Student implements a recognizer in "my_recognizer.py" which runs error-free in the notebook and passes all unit tests
-
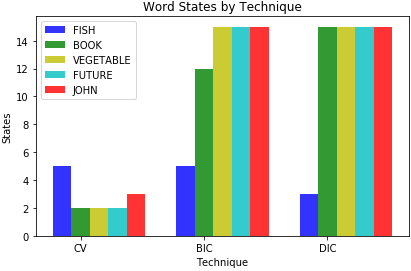
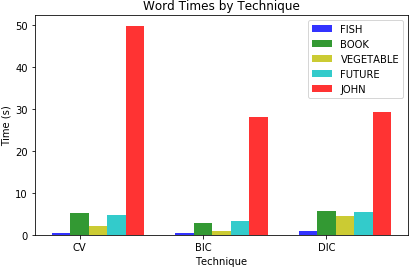
- Student provides three examples of feature/selector combinations in the submission cells of the notebook.
-
- Student code provides the correct words within <60% WER for at least one of the three examples student provided.
-
- Student provides a summary of results and speculates on how to improve the WER.
-
-
-
PART 4: (OPTIONAL)
-
Improve the WER with Language Models
- - The recognizer you implemented in Part 3 is equivalent to a "0-gram" SLM. Improve the WER with the SLM data provided with the data set in the link above using "1-gram", "2-gram", and/or "3-gram" statistics.
-
-
Submission:
-
Once you have completed the project and met all the requirements set in the rubric, save the notebook as an HTML file by going to the File menu in the notebook and choosing "Download as" > HTML. Submit the following files (and only these files) in a .zip archive:
- asl_recognizer.ipynb
- asl_recognizer.html
- my_model_selectors.py
- my_recognizer.py
-
Note: Do not include the data directory as it will lead to a huge .zip file, and may be rejected by our reviews system.
-
This project requires Python 3 and the following Python libraries installed:
Notes:
- It is highly recommended that you install the Anaconda distribution of Python and load the environment included in the "Your conda env for AI ND" lesson.
- The most recent development version of hmmlearn, 0.2.1, contains a bugfix related to the log function, which is used in this project. In order to install this version of hmmearn, install it directly from its repo with the following command from within your activated Anaconda environment:
pip install git+https://github.com/hmmlearn/hmmlearn.gitTemplate notebook provided is asl_recognizer.ipynb (combined tutorial/submission doc)
Some of the codebase and some
of your implementation will be external to the notebook. For submission,
complete the Submission sections of each part. This will include running
your implementations in code notebook cells, answering analysis questions, and
passing provided unit tests provided in the codebase and called out in the notebook.
- Go to project directory
cd AIND_recognizer/and runjupyter notebook asl_recognizer.ipynbto open the Jupyter Notebook in browser. - Follow the instructions in notebook to complete the project.
The data in the asl_recognizer/data/ directory was derived from
the RWTH-BOSTON-104 Database.
The handpositions (hand_condensed.csv) are pulled directly from
the database boston104.handpositions.rybach-forster-dreuw-2009-09-25.full.xml. The three markers are:
- 0 speaker's left hand
- 1 speaker's right hand
- 2 speaker's nose
- X and Y values of the video frame increase left to right and top to bottom.
Take a look at the sample ASL recognizer video to see how the hand locations are tracked.
The videos are sentences with translations provided in the database.
For purposes of this project, the sentences have been pre-segmented into words
based on slow motion examination of the files.
These segments are provided in the train_words.csv and test_words.csv files
in the form of start and end frames (inclusive).
The videos in the corpus include recordings from three different ASL speakers.
The mappings for the three speakers to video are included in the speaker.csv
file.