
Manuel J. Parra Royón (manuelparra@decsai.ugr.es), Alberto Fernandez (alberto@decsai.ugr.es) & José. M. Benítez Sánchez (j.m.benitez@decsai.ugr.es)

The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware. It has many similarities with existing distributed file systems. However, the differences from other distributed file systems are significant. HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS provides high throughput access to application data and is suitable for applications that have large data sets. HDFS relaxes a few POSIX requirements to enable streaming access to file system data. HDFS was originally built as infrastructure for the Apache Nutch web search engine project. HDFS is now an Apache Hadoop subproject. The project URL is http://hadoop.apache.org/hdfs/.
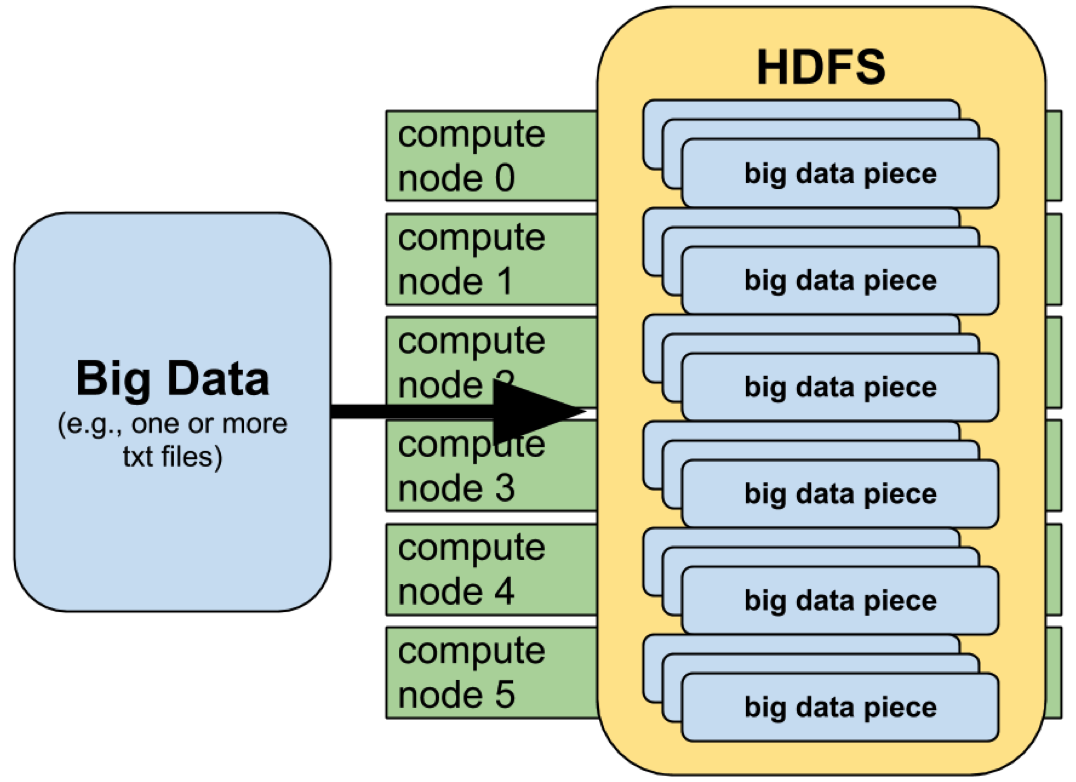
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
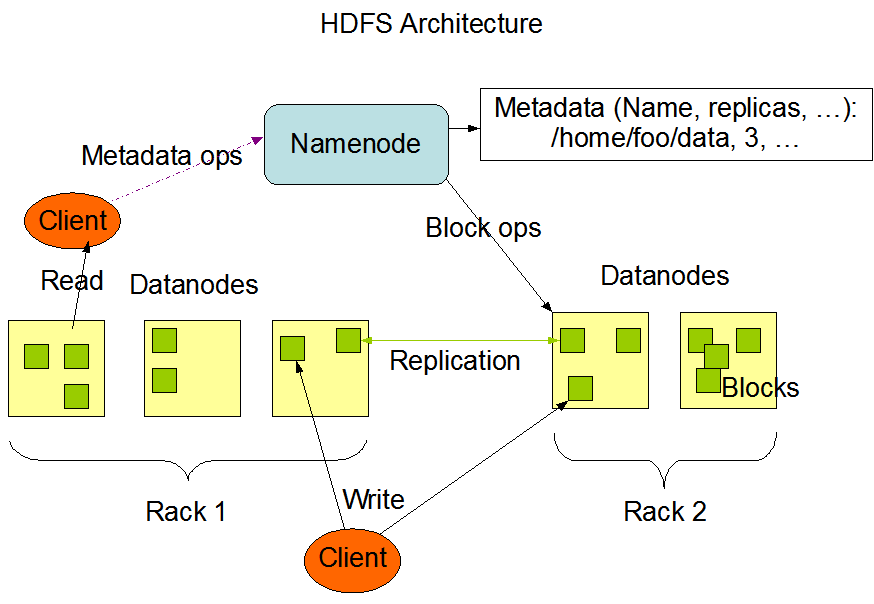
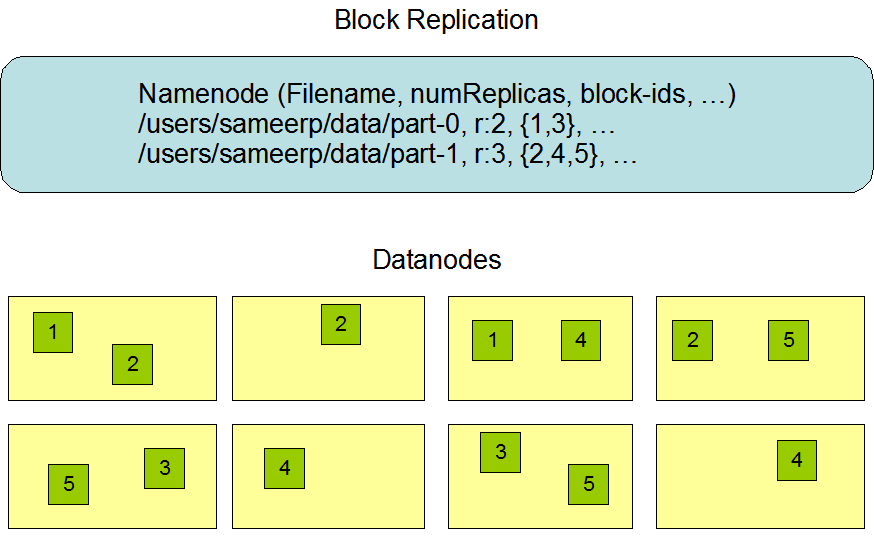
Data Replication
HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks; all blocks in a file except the last block are the same size. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file. An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once and have strictly one writer at any time.
Log in hadoop ugr server with your credentials (the same way):
ssh manuparra@hadoop...
The management of the files in HDFS works in a different way of the files of the local system. The file system is stored in a special space for HDFS. The directory structure of HDFS is as follows:
/tmp Temp storage
/user User storage
/usr Application storage
/var Logs storage
Each user has in HDFS a folder in /user/ with the username, for example for the user with login mcc50600265 in HDFS have:
/user/mcc50600265/
Attention!! The HDFS storage space is different from the user's local storage space in hadoop.ugr.es
/user/mcc506000265/ NOT EQUAL /home/mcc506000265/
hdfs dfs <options>
Options are (simplified):
-ls List of files
-cp Copy files
-rm Delete files
-rmdir Remove folder
-mv Move files or rename
-cat Similar to Cat
-mkdir Create a folder
-tail Last lines of the file
-get Get a file from HDFS to local
-put Put a file from local to HDFS
List the content of your HDFS folder:
hdfs dfs -ls
Create a test file:
echo “HOLA HDFS” > fichero.txt
Move the loca file fichero.txt to HDFS:
hdfs dfs -put fichero.txt ./
or, the same:
hdfs dfs -put fichero.txt /user/<your user login>/
List again your folder:
hdfs dfs -ls
Create a folder:
hdfs dfs -mkdir test
Move fichero.txt to test folder:
hdfs dfs -mv fichero.txt test
Show the content:
hdfs dfs -cat test/fichero.txt
or, the same:
hdfs dfs -cat /user/<your user login>/test/fichero.txt
Delete file and folder:
hdfs dfs -rm test/fichero.txt
and
hdfs dfs -rmdir test
Create two files:
echo “HOLA HDFS 1” > f1.txt
echo “HOLA HDFS 2” > f2.txt
Store in HDFS:
hdfs dfs -put f1.txt
hdfs dfs -put f2.txt
Cocatenate both files:
hdfs dfs -getmerge ./ merged.txt
- Create 5 files in yout local account with the following names:
- part1.dat ,part2.dat, part3.dat. part4.dat. part5.dat
- Copy files to HDFS
- Create the following HDFS folder structure:
- /test/p1/
- /train/p1/
- /train/p2/
- Copy part1 in /test/p1/ and part2 in /train/p2/
- Move part3, and part4 to /train/p1/
- Finally merge folder /train/p2 and store as data_merged.txt