Zero/Low code based business model representation automation
Kolle is for working on data models, data-contract, data quality, data profiling, and data linage instead of technical tooling or platform.
Today for business continuation, the business model needs to represent in many ways - normalized form for transactional data, a time-series database for process mining, a knowledge graph for semantics search or link data, a data-vault or snowflake model for data warehouse, a streaming model for the real-time event and columnar storage for machine learning. To move or prepare the data and model for multiple types of consumption is not only expensive but has a lot of repetition costs for the team and technology setup. Automation needs to be in place to reduce repetition costs.
There are many ways to start automation of data processing or data ingestion. Some starts with infrastructure or tooling or starts writing code immediately. But Kolle uses data model and data modeling is the first class citizen to this automation process.
Kolle enables users to work on data models, data contracts, metadata, data quality, and data lineage. Users will spend 90% of their time focusing on business work instead of spending time on different sets of tooling. End to end data integration will be generated based on data model and data contract.
It is just 5 to 10 min of work to create end-to-end integration different types of producers and consumers.
End to end data integration from semi structure mangodb dataset to different type of KPI distribuation without writing any single line of source code.
- Metadata harvesting from any source format
- Share data model within an organization or internet
- Data(XML, JSON, CSV, ZIP) to model generator
- Model to model transformation
- Data quality based on micro type
- Data contract UI with data grid
- Data profiling
- Data linage automatically
- Custom micro type
- Captuaring source model change automatically
- Real time code generation and visualization
- Real time collaboration within multiple user
- Incremental deployment
- Batch cleanup (only flow or only storage or both flow and storage)
- Data view for xml, json, csv
- Download data in many different format like xml, rdf, json, and csv
- Integration with any (cloud, on-promise) confluent platform
- Many pattern - dead latter queue, distinct, data-vault model converter and more

- Source model: One to one copy from any source system, it can be any format like - csv, xml, json etc. Consumer should not access this model and source system is the owner of this model
- Raw model: Input model for a data contract. Only technical transformation will happen from the source model to the raw model conversation i.e flatten, distinct, etc. The raw model can be optional if it is the same as the source model. Source and raw model values will be the same. It is also private model same as source model. Raw model should be access only from data contract.
- Data contract: Explicit task between producer and consumer.
- Refined model: Output model of data contract. It is a type-based model. All attributes must have the proper type based on data contract consumer specifications. Permission based on consumer specification.
- Target model: Target system model, only technical transformation will be happened from refined to target model i.e graph, data-vault, etc. The target model can be optional if it is the same as the refined model.
- Logicaltype/Tinytype/Microtype: It is domain type - like email, claim_amount, customer_name, etc. Microtype will be driven from core type systems like string, int, float, etc.
- Macro: Model to model transformation. It is a plug-in to the system and it removes repetition tasks.
- System config: It contains different runtime configurations for the platform like partition, replication, window time, runtime service url, etc.
- Metadata repo: Main repo to contain user, metadata, system config, micro type or everything. It is unique with in the whole system. Every user can have multiple repositories.
- User: Users can be either owners or have read-only permission to each repository. The owner can set different types of permission for the repo.
- Builder: Glue different concepts that can be changed independently to create execution code for the platform.
Security: Source, raw and refined models are private for consumer. Consumer should access data only from consumer model or target model
Ownership: Producers are the owner of source model and Consumer are the owner of target model.
End to end example
- Convert flatten model to knowledge graph model
- Convert document model to data vault model
- Ingest and process document data and download as knowledge graph or flatten data
Specific example
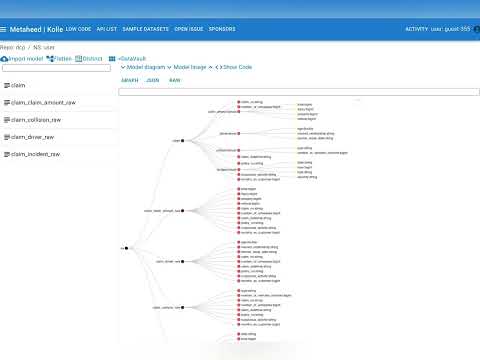
- Meta model visualization
- Data profiling before and after data contract
- Data lineage
- Data contract and Logical type
Collaboration & Version
Low code
- Try in cloud Kolle.
- Run locally
$ docker pull ghcr.io/metaheed/kolle
$ docker run -it -p 3000:3000 --rm ghcr.io/metaheed/kolle- Run Kolle Sandbox
Copyright © 2022-2023 Abdullah Mamun
Distributed under the Apache License. See LICENSE.