Separation of app logic and framework code #4062
Replies: 2 comments 2 replies
-
Tasks
|
Beta Was this translation helpful? Give feedback.
-
|
Adding a few more recent thoughts, I'll try to combine these when I've settled on a de-risked approach:
|
Beta Was this translation helpful? Give feedback.
-
|
I've been experimenting with gRPC APIs in this repo, initially in Python. The code there's extremely sketchy, but should be a testing ground for a PoC protobuf service definition. |
Beta Was this translation helpful? Give feedback.
-
|
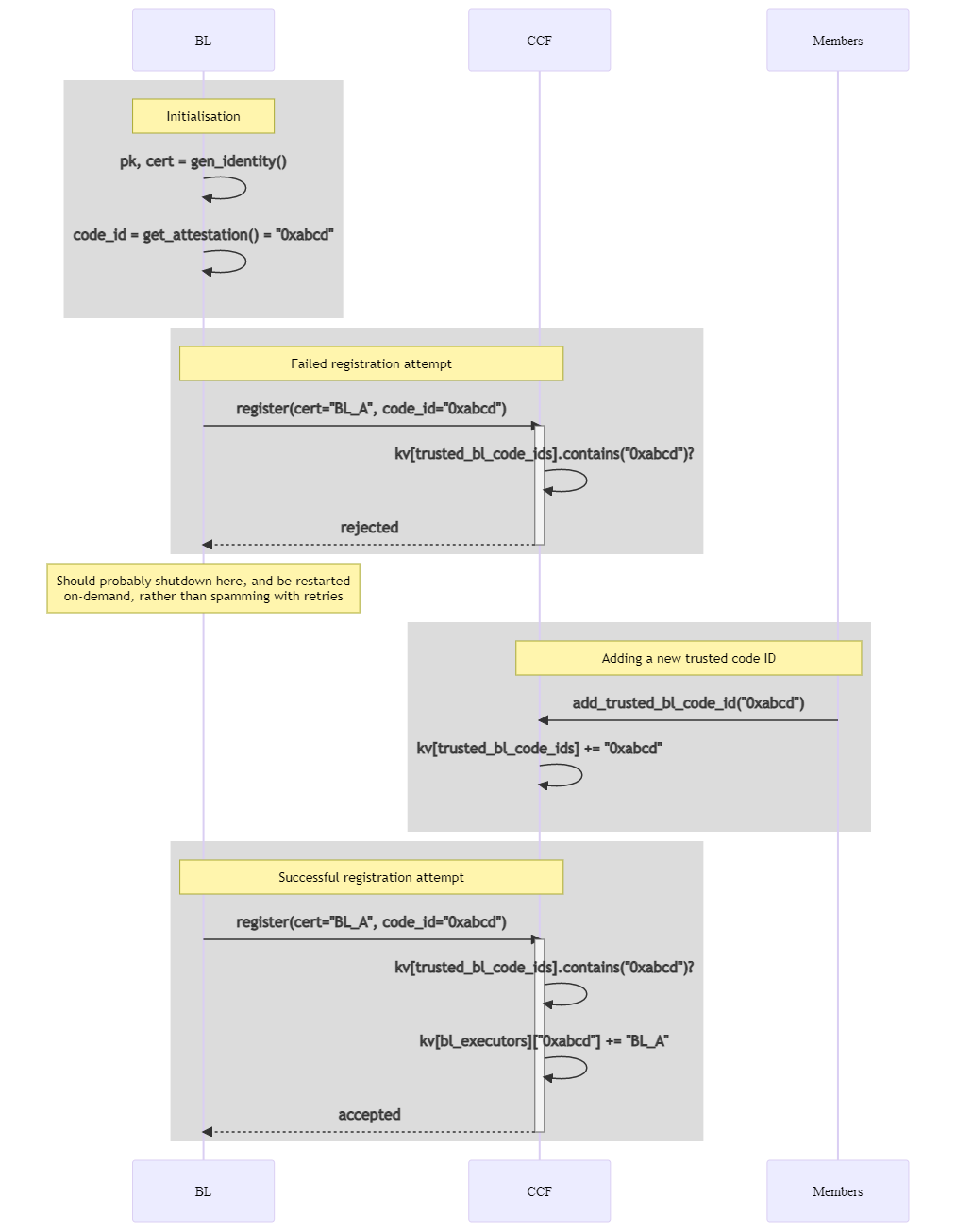
I've added some Mermaid diagrams to this repo sketching the currently planned flow. Including here with some comments on implications and open decisions. Registration of a new Business-Logic instance
The initialisation block is something that each Business-Logic container must be able to do, so should be achievable with standard libraries in supported languages (ie - not require CCF code in each language). It's possible we do that through a sidecar. I show a single BL instance here for simplicity, but really we'd expect it to shutdown on a rejected registration rather than retrying - imagine it's a new instance for the successful attempt. Each BL generates a new secure identity, in-enclave, and uses that to establish a secure channel with CCF. CCF needs to listen for registration traffic. The BL instance should be given the CCF service identity, so it does not connect to arbitrary services (if it contains sensitive/confidential code). A big design choice I haven't solved yet - is the set of supported endpoints part of the attestation (ie - determined by governance), or dynamically set by each BL when it registers? Either approach needs a new dispatch mechanism. The latter is more generic/powerful (allows Execution of a user request
Activations are trying to show the presumed-to-be "blocking" bits, but this is missing some subtleties. In particular, when the request first arrives, there's technically an async wait before the CCF node actually begins processing it, and it's likely that this processing is itself several async steps. Eventually it finds a BL instance to dispatch to. This dispatch lookup needs to be transactional, so that if the BL's code ID is revoked mid-execution, this transaction automatically fails. This tries to show requests as solid lines, and responses in dotted lines. The CCF->BL execute..done block is a bit odd here, because CCF is actually the server for this gRPC service. This may be a server-streaming RPC, or we may expect the BL to submit an initial "Ready" request, or maybe that can be implicit in TLS connection/registration? TBC. |
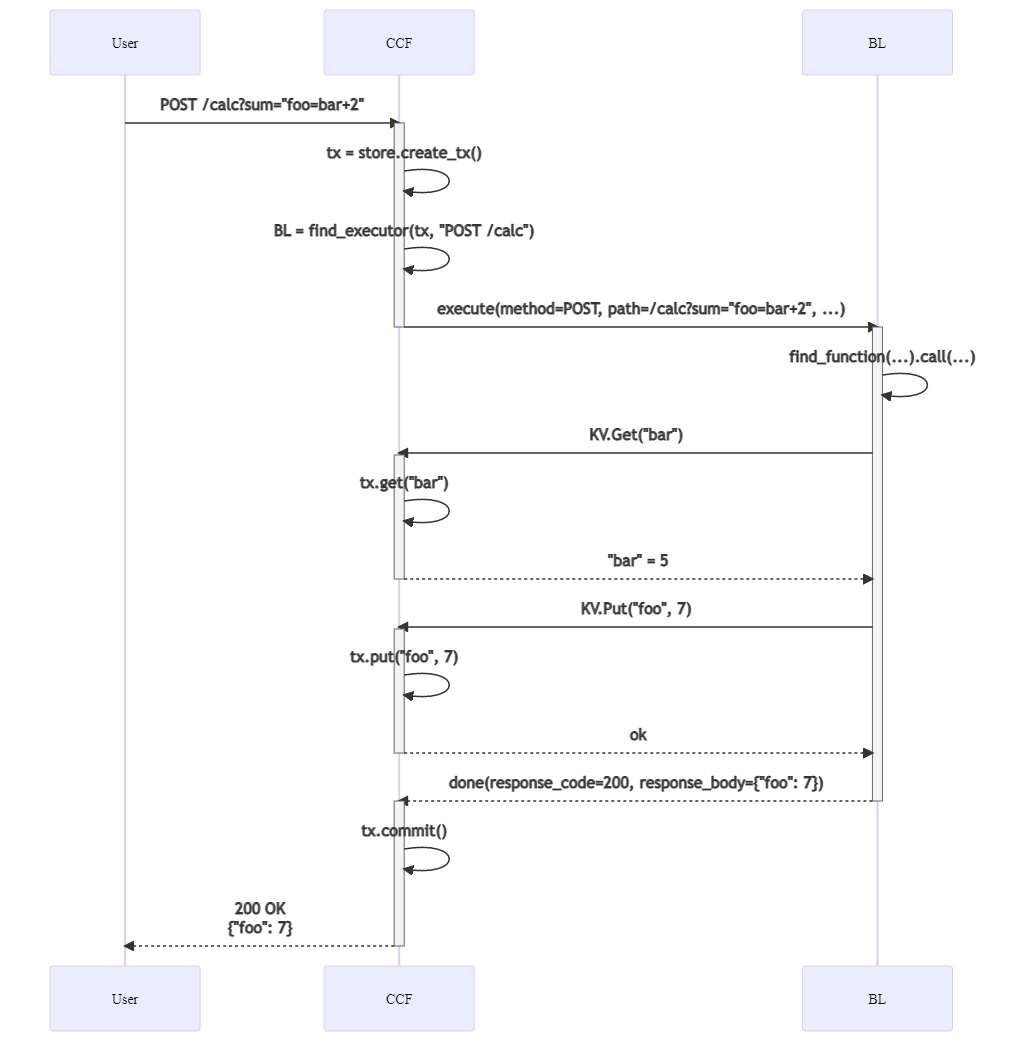
Beta Was this translation helpful? Give feedback.
-
Each CCF node currently executes a single binary containing both framework systems and application code. This means an update to either component requires a rebuild of this binary, the application code has a limited API and dependency list, and the application code must be written in C++ (or a scripting language via an embeddable interpreter).
We want to remove this coupling in future to support independent versioning and updates, broad support for alternative languages and dependencies, and separate scaling of application capacity.
The plan is to do this by separating each CCF node into multiple binaries, each deployed and managed as a separate container: a CCF-Core container written and maintained by the framework, communicating over a well-defined interface with Business Logic containers written in any other language. We will use gRPC for this inter-container communication interface, so that the Business-Logic containers can easily be written in any language with gRPC support.
Business-Logic containers will need to attest to their own identity, and CCF governance will determine the set of acceptable identities - those containers will then have full access to the confidential ledger contents, in the same way that application code does today.
A Business-Logic container will register to handle some set of
(HTTP-method, HTTP-url)pairs (as endpoint handlers currently do), will receive requests parsed by a CCF-Core node over a gRPC interface, will execute their business logic using a gRPC KV API to read and write ledger entries, and produce some HTTP response to be returned when the transaction is to be applied. Beyond that, the containers may do any additional indexing or book-keeping they wish inside or outside that container (while considering confidentiality of everything they process). They may execute long-lived async requests to resolve user queries, or utilise external hardware for expensive computations.This discussion is intended to be a central collection of the various decisions, designs, and tasks to achieve this.
Beta Was this translation helpful? Give feedback.
All reactions