diff --git a/configs/pvt/README.md b/configs/pvt/README.md
index e33f3b78c..2b680bee8 100644
--- a/configs/pvt/README.md
+++ b/configs/pvt/README.md
@@ -4,7 +4,11 @@
## Introduction
-PVT is a general backbone network for dense prediction without convolution operation. PVT introduces a pyramid structure in Transformer to generate multi-scale feature maps for dense prediction tasks. PVT uses a gradual reduction strategy to control the size of the feature maps through the patch embedding layer, and proposes a spatial reduction attention (SRA) layer to replace the traditional multi head attention layer in the encoder, which greatly reduces the computing/memory overhead.[[1](#References)]
+PVT is a general backbone network for dense prediction without convolution operation. PVT introduces a pyramid structure
+in Transformer to generate multi-scale feature maps for dense prediction tasks. PVT uses a gradual reduction strategy to
+control the size of the feature maps through the patch embedding layer, and proposes a spatial reduction attention (SRA)
+layer to replace the traditional multi head attention layer in the encoder, which greatly reduces the computing/memory
+overhead.[[1](#References)]

@@ -12,20 +16,28 @@ PVT is a general backbone network for dense prediction without convolution opera
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|:----------:|:--------:|:---------:|:---------:|:----------:|----------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------|
-| pvt_tiny | D910x8-G | 74.81 | 92.18 | 13.23 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvt/pvt_tiny_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt/pvt_tiny-6abb953d.ckpt) |
-| pvt_small | D910x8-G | 79.66 | 94.71 | 24.49 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvt/pvt_small_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt/pvt_small-213c2ed1.ckpt) |
-| pvt_medium | D910x8-G | 81.82 | 95.81 | 44.21 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvt/pvt_medium_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt/pvt_medium-469e6802.ckpt) |
-| pvt_large | D910x8-G | 81.75 | 95.70 | 61.36 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvt/pvt_large_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt/pvt_large-bb6895d7.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------|
+| pvt_tiny | 74.88 | 92.12 | 13.23 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvt/pvt_tiny_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/pvt/pvt_tiny-6676051f-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------|
+| pvt_tiny | 74.81 | 92.18 | 13.23 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvt/pvt_tiny_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt/pvt_tiny-6abb953d.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -38,26 +50,31 @@ Please refer to the [installation instruction](https://github.com/mindspore-lab/
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
- Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config configs/pvt/pvt_tiny_ascend.yaml --data_dir /path/to/imagenet
```
+
> If the script is executed by the root user, the `--allow-run-as-root` parameter must be added to `mpirun`.
> If use Ascend 910 devices, need to open SATURATION_MODE via `export MS_ASCEND_CHECK_OVERFLOW_MODE="SATURATION_MODE"`
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep
+the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -67,11 +84,13 @@ If you want to train or finetune the model on a smaller dataset without distribu
# standalone training on a CPU/GPU/Ascend device
python train.py --config configs/pvt/pvt_tiny_ascend.yaml --data_dir /path/to/imagenet --distribute False
```
+
> If use Ascend 910 devices, need to open SATURATION_MODE via `export MS_ASCEND_CHECK_OVERFLOW_MODE="SATURATION_MODE"`
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py --model=pvt_tiny --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -79,8 +98,10 @@ python validate.py --model=pvt_tiny --data_dir /path/to/imagenet --ckpt_path /pa
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1]. Wang W, Xie E, Li X, et al. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 568-578.
+[1]. Wang W, Xie E, Li X, et al. Pyramid vision transformer: A versatile backbone for dense prediction without
+convolutions[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 568-578.
diff --git a/configs/pvtv2/README.md b/configs/pvtv2/README.md
index 7c691bd34..bdd6f951c 100644
--- a/configs/pvtv2/README.md
+++ b/configs/pvtv2/README.md
@@ -1,4 +1,5 @@
# PVTV2
+
> [PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/abs/2106.13797)
## Introduction
@@ -20,21 +21,28 @@ segmentation.[[1](#references)]
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:---------:|:---------:|:---------:|:----------:|------------|-----------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------|
+| pvt_v2_b0 | 71.25 | 90.50 | 3.67 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvtv2/pvt_v2_b0_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/pvt_v2/pvt_v2_b0-d9cd9d6a-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|-----------|----------|-----------|-----------|------------|------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|
-| pvt_v2_b0 | D910x8-G | 71.50 | 90.60 | 3.67 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvtv2/pvt_v2_b0_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt_v2/pvt_v2_b0-1c4f6683.ckpt) |
-| pvt_v2_b1 | D910x8-G | 78.91 | 94.49 | 14.01 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvtv2/pvt_v2_b1_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt_v2/pvt_v2_b1-3ceb171a.ckpt) |
-| pvt_v2_b2 | D910x8-G | 81.99 | 95.74 | 25.35 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvtv2/pvt_v2_b2_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt_v2/pvt_v2_b2-0565d18e.ckpt) |
-| pvt_v2_b3 | D910x8-G | 82.84 | 96.24 | 45.24 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvtv2/pvt_v2_b3_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt_v2/pvt_v2_b3-feaae3fc.ckpt) |
-| pvt_v2_b4 | D910x8-G | 83.14 | 96.27 | 62.56 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvtv2/pvt_v2_b4_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt_v2/pvt_v2_b4-1cf4bc03.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:---------:|:---------:|:---------:|:----------:|------------|-----------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|
+| pvt_v2_b0 | 71.50 | 90.60 | 3.67 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/pvtv2/pvt_v2_b0_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/pvt_v2/pvt_v2_b0-1c4f6683.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -42,16 +50,20 @@ Our reproduced model performance on ImageNet-1K is reported as follows.
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-ecosystem/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distrubted training on multiple GPU/Ascend devices
@@ -62,9 +74,11 @@ mpirun -n 8 python train.py --config configs/pvtv2/pvt_v2_b0_ascend.yaml --data_
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -77,7 +91,8 @@ python train.py --config configs/pvtv2/pvt_v2_b0_ascend.yaml --data_dir /path/to
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/pvtv2/pvt_v2_b0_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -89,4 +104,5 @@ Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv
## References
-[1] Wang W, Xie E, Li X, et al. Pvt v2: Improved baselines with pyramid vision transformer[J]. Computational Visual Media, 2022, 8(3): 415-424.
+[1] Wang W, Xie E, Li X, et al. Pvt v2: Improved baselines with pyramid vision transformer[J]. Computational Visual
+Media, 2022, 8(3): 415-424.
diff --git a/configs/regnet/README.md b/configs/regnet/README.md
index 6dbb32979..2fdbd850f 100644
--- a/configs/regnet/README.md
+++ b/configs/regnet/README.md
@@ -4,7 +4,20 @@
## Introduction
-In this work, the authors present a new network design paradigm that combines the advantages of manual design and NAS. Instead of focusing on designing individual network instances, they design design spaces that parametrize populations of networks. Like in manual design, the authors aim for interpretability and to discover general design principles that describe networks that are simple, work well, and generalize across settings. Like in NAS, the authors aim to take advantage of semi-automated procedures to help achieve these goals The general strategy they adopt is to progressively design simplified versions of an initial, relatively unconstrained, design space while maintaining or improving its quality. The overall process is analogous to manual design, elevated to the population level and guided via distribution estimates of network design spaces. As a testbed for this paradigm, their focus is on exploring network structure (e.g., width, depth, groups, etc.) assuming standard model families including VGG, ResNet, and ResNeXt. The authors start with a relatively unconstrained design space they call AnyNet (e.g., widths and depths vary freely across stages) and apply their humanin-the-loop methodology to arrive at a low-dimensional design space consisting of simple “regular” networks, that they call RegNet. The core of the RegNet design space is simple: stage widths and depths are determined by a quantized linear function. Compared to AnyNet, the RegNet design space has simpler models, is easier to interpret, and has a higher concentration of good models.[[1](#References)]
+In this work, the authors present a new network design paradigm that combines the advantages of manual design and NAS.
+Instead of focusing on designing individual network instances, they design design spaces that parametrize populations of
+networks. Like in manual design, the authors aim for interpretability and to discover general design principles that
+describe networks that are simple, work well, and generalize across settings. Like in NAS, the authors aim to take
+advantage of semi-automated procedures to help achieve these goals The general strategy they adopt is to progressively
+design simplified versions of an initial, relatively unconstrained, design space while maintaining or improving its
+quality. The overall process is analogous to manual design, elevated to the population level and guided via distribution
+estimates of network design spaces. As a testbed for this paradigm, their focus is on exploring network structure (e.g.,
+width, depth, groups, etc.) assuming standard model families including VGG, ResNet, and ResNeXt. The authors start with
+a relatively unconstrained design space they call AnyNet (e.g., widths and depths vary freely across stages) and apply
+their humanin-the-loop methodology to arrive at a low-dimensional design space consisting of simple “regular” networks,
+that they call RegNet. The core of the RegNet design space is simple: stage widths and depths are determined by a
+quantized linear function. Compared to AnyNet, the RegNet design space has simpler models, is easier to interpret, and
+has a higher concentration of good models.[[1](#References)]

@@ -12,25 +25,28 @@ In this work, the authors present a new network design paradigm that combines th
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------------:|:---------:|:---------:|:----------:|------------|-----------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------|
+| regnet_x_800mf | 76.11 | 93.00 | 7.26 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_x_800mf_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/regnet/regnet_x_800mf-68fe1cca-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|:--------------:|:--------:|:---------:|:---------:|:----------:|-----------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
-| regnet_x_200mf | D910x8-G | 68.74 | 88.38 | 2.68 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_x_200mf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_x_200mf-0c2b1eb5.ckpt) |
-| regnet_x_400mf | D910x8-G | 73.16 | 91.35 | 5.16 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_x_400mf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_x_400mf-4848837d.ckpt) |
-| regnet_x_600mf | D910x8-G | 74.34 | 92.00 | 6.20 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_x_600mf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_x_600mf-ccd76c94.ckpt) |
-| regnet_x_800mf | D910x8-G | 76.04 | 92.97 | 7.26 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_x_800mf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_x_800mf-617227f4.ckpt) |
-| regnet_y_200mf | D910x8-G | 70.30 | 89.61 | 3.16 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_y_200mf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_y_200mf-76a2f720.ckpt) |
-| regnet_y_400mf | D910x8-G | 73.91 | 91.84 | 4.34 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_y_400mf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_y_400mf-d496799d.ckpt) |
-| regnet_y_600mf | D910x8-G | 75.69 | 92.50 | 6.06 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_y_600mf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_y_600mf-a84e19b2.ckpt) |
-| regnet_y_800mf | D910x8-G | 76.52 | 93.10 | 6.26 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_y_800mf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_y_800mf-9b5211bd.ckpt) |
-| regnet_y_16gf | D910x8-G | 82.92 | 96.29 | 83.71 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_y_16gf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_y_16gf-c30a856f.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------------:|:---------:|:---------:|:----------:|------------|-----------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
+| regnet_x_800mf | 76.04 | 92.97 | 7.26 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/regnet/regnet_x_800mf_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/regnet/regnet_x_800mf-617227f4.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -43,25 +59,30 @@ Please refer to the [installation instruction](https://github.com/mindspore-lab/
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
- Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config configs/regnet/regnet_x_800mf_ascend.yaml --data_dir /path/to/imagenet
```
+
> If the script is executed by the root user, the `--allow-run-as-root` parameter must be added to `mpirun`.
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep
+the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -74,7 +95,8 @@ python train.py --config configs/regnet/regnet_x_800mf_ascend.yaml --data_dir /p
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py --model=regnet_x_800mf --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -82,8 +104,10 @@ python validate.py --model=regnet_x_800mf --data_dir /path/to/imagenet --ckpt_pa
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1]. Radosavovic I, Kosaraju R P, Girshick R, et al. Designing network design spaces[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 10428-10436.
+[1]. Radosavovic I, Kosaraju R P, Girshick R, et al. Designing network design spaces[C]//Proceedings of the IEEE/CVF
+conference on computer vision and pattern recognition. 2020: 10428-10436.
diff --git a/configs/repmlp/README.md b/configs/repmlp/README.md
index 18fcca20a..88fa95ec1 100644
--- a/configs/repmlp/README.md
+++ b/configs/repmlp/README.md
@@ -5,15 +5,21 @@
## Introduction
Compared to convolutional layers, fully-connected (FC) layers are better at modeling the long-range dependencies
-but worse at capturing the local patterns, hence usually less favored for image recognition. In this paper, the authors propose a
+but worse at capturing the local patterns, hence usually less favored for image recognition. In this paper, the authors
+propose a
methodology, Locality Injection, to incorporate local priors into an FC layer via merging the trained parameters of a
parallel conv kernel into the FC kernel. Locality Injection can be viewed as a novel Structural Re-parameterization
-method since it equivalently converts the structures via transforming the parameters. Based on that, the authors propose a
+method since it equivalently converts the structures via transforming the parameters. Based on that, the authors propose
+a
multi-layer-perceptron (MLP) block named RepMLP Block, which uses three FC layers to extract features, and a novel
-architecture named RepMLPNet. The hierarchical design distinguishes RepMLPNet from the other concurrently proposed vision MLPs.
-As it produces feature maps of different levels, it qualifies as a backbone model for downstream tasks like semantic segmentation.
-Their results reveal that 1) Locality Injection is a general methodology for MLP models; 2) RepMLPNet has favorable accuracy-efficiency
-trade-off compared to the other MLPs; 3) RepMLPNet is the first MLP that seamlessly transfer to Cityscapes semantic segmentation.
+architecture named RepMLPNet. The hierarchical design distinguishes RepMLPNet from the other concurrently proposed
+vision MLPs.
+As it produces feature maps of different levels, it qualifies as a backbone model for downstream tasks like semantic
+segmentation.
+Their results reveal that 1) Locality Injection is a general methodology for MLP models; 2) RepMLPNet has favorable
+accuracy-efficiency
+trade-off compared to the other MLPs; 3) RepMLPNet is the first MLP that seamlessly transfer to Cityscapes semantic
+segmentation.
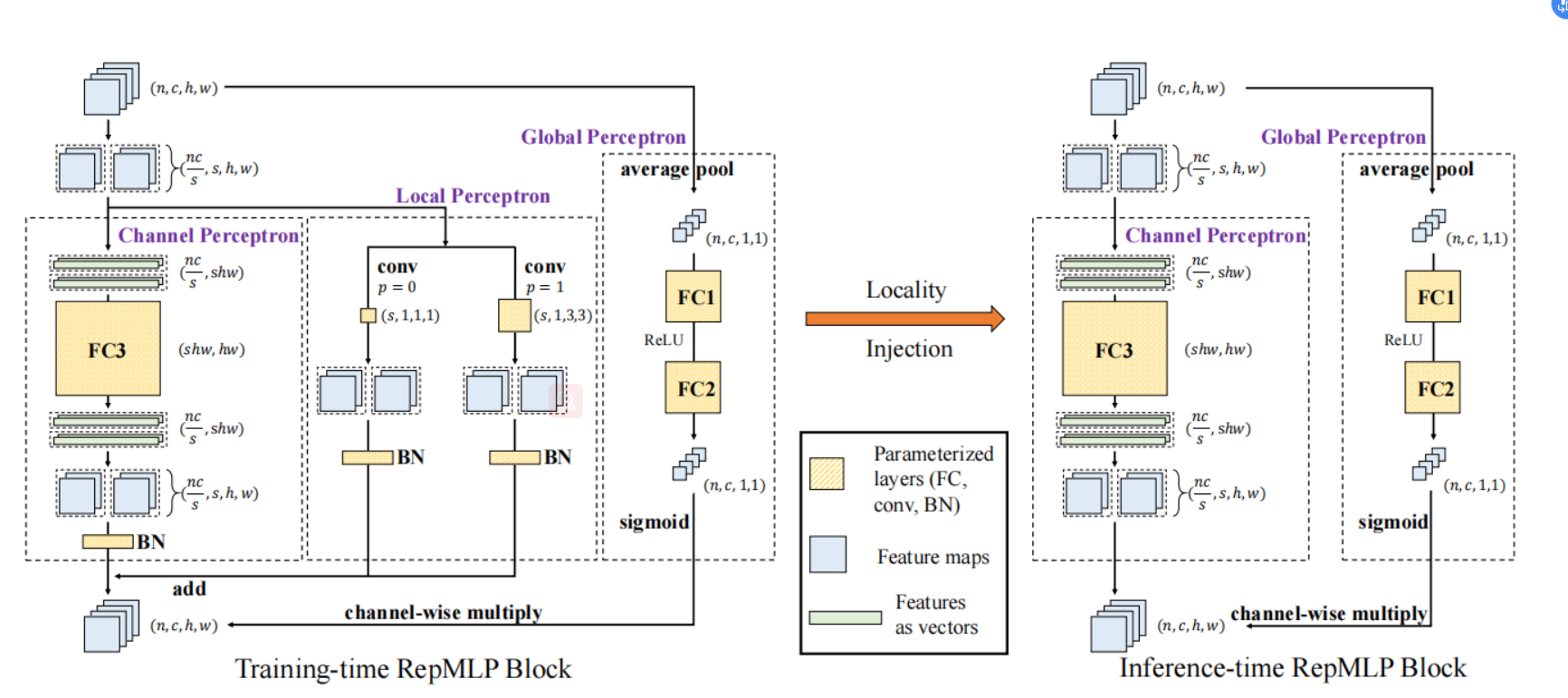
Figure 1. RepMLP Block.[[1](#References)]
@@ -22,17 +28,22 @@ Figure 1. RepMLP Block.[[1](#References)]
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+*coming soon*
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|:--------------:|:--------:|:---------:|:---------:|:----------:|-----------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------|
-| repmlp_t224 | D910x8-G | 76.71 | 93.30 | 38.30 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/repmlp/repmlp_t224_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/repmlp/repmlp_t224-8dbedd00.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-----------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|
+| repmlp_t224 | 76.71 | 93.30 | 38.30 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/repmlp/repmlp_t224_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/repmlp/repmlp_t224-8dbedd00.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -45,25 +56,30 @@ Please refer to the [installation instruction](https://github.com/mindspore-lab/
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
- Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config configs/repmlp/repmlp_t224_ascend.yaml --data_dir /path/to/imagenet
```
+
> If the script is executed by the root user, the `--allow-run-as-root` parameter must be added to `mpirun`.
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep
+the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -76,7 +92,8 @@ python train.py --config configs/repmlp/repmlp_t224_ascend.yaml --data_dir /path
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py --model=repmlp_t224 --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -84,8 +101,10 @@ python validate.py --model=repmlp_t224 --data_dir /path/to/imagenet --ckpt_path
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1]. Ding X, Chen H, Zhang X, et al. Repmlpnet: Hierarchical vision mlp with re-parameterized locality[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 578-587.
+[1]. Ding X, Chen H, Zhang X, et al. Repmlpnet: Hierarchical vision mlp with re-parameterized locality[C]//Proceedings
+of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 578-587.
diff --git a/configs/repvgg/README.md b/configs/repvgg/README.md
index 8d58a3897..fb2bbb99e 100644
--- a/configs/repvgg/README.md
+++ b/configs/repvgg/README.md
@@ -1,14 +1,19 @@
# RepVGG
+
> [RepVGG: Making VGG-style ConvNets Great Again](https://arxiv.org/abs/2101.03697)
## Introduction
+
-The key idea of Repvgg is that by using re-parameterization, the model architecture could be trained in multi-branch but validated in single branch.
-Figure 1 shows the basic model architecture of Repvgg. By utilizing different values for a and b, we could get various repvgg models.
-Repvgg could achieve better model performance with smaller model parameters on ImageNet-1K dataset compared with previous methods.[[1](#references)]
+The key idea of Repvgg is that by using re-parameterization, the model architecture could be trained in multi-branch but
+validated in single branch.
+Figure 1 shows the basic model architecture of Repvgg. By utilizing different values for a and b, we could get various
+repvgg models.
+Repvgg could achieve better model performance with smaller model parameters on ImageNet-1K dataset compared with
+previous methods.[[1](#references)]
 @@ -18,6 +23,7 @@ Repvgg could achieve better model performance with smaller model parameters on I
@@ -18,6 +23,7 @@ Repvgg could achieve better model performance with smaller model parameters on I
## Results
+
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config configs/repvgg/repvgg_a1_ascend.yaml --data_dir /path/to/imagenet
```
+
> If the script is executed by the root user, the `--allow-run-as-root` parameter must be added to `mpirun`.
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -92,7 +110,8 @@ python train.py --config configs/repvgg/repvgg_a1_ascend.yaml --data_dir /path/t
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```
python validate.py -c configs/repvgg/repvgg_a1_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -103,6 +122,8 @@ python validate.py -c configs/repvgg/repvgg_a1_ascend.yaml --data_dir /path/to/i
Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/) in MindCV.
## References
+
-[1] Ding X, Zhang X, Ma N, et al. Repvgg: Making vgg-style convnets great again[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 13733-13742.
+[1] Ding X, Zhang X, Ma N, et al. Repvgg: Making vgg-style convnets great again[C]//Proceedings of the IEEE/CVF
+conference on computer vision and pattern recognition. 2021: 13733-13742.
diff --git a/configs/res2net/README.md b/configs/res2net/README.md
index 0576c3527..44af1cf55 100644
--- a/configs/res2net/README.md
+++ b/configs/res2net/README.md
@@ -4,7 +4,12 @@
## Introduction
-Res2Net is a novel building block for CNNs proposed by constructing hierarchical residual-like connections within one single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of receptive fields for each network layer. Res2Net block can be plugged into the state-of-the-art backbone CNN models, e.g., ResNet, ResNeXt, and DLA. Ablation studies and experimental results on representative computer vision tasks, i.e., object detection, class activation mapping, and salient object detection, verify the superiority of the Res2Net over the state-of-the-art baseline methods such as ResNet-50, DLA-60 and etc.
+Res2Net is a novel building block for CNNs proposed by constructing hierarchical residual-like connections within one
+single residual block. The Res2Net represents multi-scale features at a granular level and increases the range of
+receptive fields for each network layer. Res2Net block can be plugged into the state-of-the-art backbone CNN models,
+e.g., ResNet, ResNeXt, and DLA. Ablation studies and experimental results on representative computer vision tasks, i.e.,
+object detection, class activation mapping, and salient object detection, verify the superiority of the Res2Net over the
+state-of-the-art baseline methods such as ResNet-50, DLA-60 and etc.
 @@ -17,37 +22,49 @@ Res2Net is a novel building block for CNNs proposed by constructing hierarchical
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
@@ -17,37 +22,49 @@ Res2Net is a novel building block for CNNs proposed by constructing hierarchical
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|----------------|-----------|-----------|-------|------------|-------------------------------------------------------------------------------------------------------|---|
-| res2net50 | D910x8-G | 79.35 | 94.64 | 25.76 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/res2net/res2net_50_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/res2net/res2net50-f42cf71b.ckpt) |
-| res2net101 | D910x8-G | 79.56 | 94.70 | 45.33 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/res2net/res2net_101_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/res2net/res2net101-8ae60132.ckpt) |
-| res2net50_v1b | D910x8-G | 80.32 | 95.09 | 25.77 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/res2net/res2net_50_v1b_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/res2net/res2net50_v1b-99304e92.ckpt) |
-| res2net101_v1b | D910x8-G | 81.14 | 95.41 | 45.35 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/res2net/res2net_101_v1b_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/res2net/res2net101_v1b-7e6db001.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:---------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------|
+| res2net50 | 79.33 | 94.64 | 25.76 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/res2net/res2net_50_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/res2net/res2net50-aa758355-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:---------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------|
+| res2net50 | 79.35 | 94.64 | 25.76 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/res2net/res2net_50_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/res2net/res2net50-f42cf71b.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
-- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
+- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -58,9 +75,11 @@ mpirun -n 8 python train.py --config configs/res2net/res2net_50_ascend.yaml --da
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -73,7 +92,8 @@ python train.py --config configs/res2net/res2net_50_ascend.yaml --data_dir /path
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/res2net/res2net_50_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -81,8 +101,10 @@ python validate.py -c configs/res2net/res2net_50_ascend.yaml --data_dir /path/to
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1] Gao S H, Cheng M M, Zhao K, et al. Res2net: A new multi-scale backbone architecture[J]. IEEE transactions on pattern analysis and machine intelligence, 2019, 43(2): 652-662.
+[1] Gao S H, Cheng M M, Zhao K, et al. Res2net: A new multi-scale backbone architecture[J]. IEEE transactions on pattern
+analysis and machine intelligence, 2019, 43(2): 652-662.
diff --git a/configs/resnest/README.md b/configs/resnest/README.md
index 4e79305d5..1dfe88180 100644
--- a/configs/resnest/README.md
+++ b/configs/resnest/README.md
@@ -1,4 +1,5 @@
# ResNeSt
+
> [ResNeSt: Split-Attention Networks](https://arxiv.org/abs/2004.08955)
## Introduction
@@ -20,18 +21,22 @@ classification.[[1](#references)]
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+*coming soon*
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|------------|----------|-----------|-----------|------------|--------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|
-| resnest50 | D910x8-G | 80.81 | 95.16 | 27.55 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnest/resnest50_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnest/resnest50-f2e7fc9c.ckpt) |
-| resnest101 | D910x8-G | 82.90 | 96.12 | 48.41 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnest/resnest101_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnest/resnest101-7cc5c258.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:---------:|:---------:|:---------:|:----------:|------------|-------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------|
+| resnest50 | 80.81 | 95.16 | 27.55 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnest/resnest50_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnest/resnest50-f2e7fc9c.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -39,16 +44,20 @@ Our reproduced model performance on ImageNet-1K is reported as follows.
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-ecosystem/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -59,9 +68,11 @@ mpirun -n 8 python train.py --config configs/resnest/resnest50_ascend.yaml --dat
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -74,7 +85,8 @@ python train.py --config configs/resnest/resnest50_ascend.yaml --data_dir /path/
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/resnest/resnest50_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -86,4 +98,5 @@ Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv
## References
-[1] Zhang H, Wu C, Zhang Z, et al. Resnest: Split-attention networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 2736-2746.
+[1] Zhang H, Wu C, Zhang Z, et al. Resnest: Split-attention networks[C]//Proceedings of the IEEE/CVF Conference on
+Computer Vision and Pattern Recognition. 2022: 2736-2746.
diff --git a/configs/resnet/README.md b/configs/resnet/README.md
index 3eaaf7c89..6a60e32cb 100644
--- a/configs/resnet/README.md
+++ b/configs/resnet/README.md
@@ -4,7 +4,10 @@
## Introduction
-Resnet is a residual learning framework to ease the training of networks that are substantially deeper than those used previously, which is explicitly reformulated that the layers are learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. Lots of comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth.
+Resnet is a residual learning framework to ease the training of networks that are substantially deeper than those used
+previously, which is explicitly reformulated that the layers are learning residual functions with reference to the layer
+inputs, instead of learning unreferenced functions. Lots of comprehensive empirical evidence showing that these residual
+networks are easier to optimize, and can gain accuracy from considerably increased depth.
 @@ -17,38 +20,49 @@ Resnet is a residual learning framework to ease the training of networks that ar
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
@@ -17,38 +20,49 @@ Resnet is a residual learning framework to ease the training of networks that ar
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|-----------------|-----------|-----------|-----------|-------|-------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------|
-| resnet18 | D910x8-G | 70.21 | 89.62 | 11.70 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnet/resnet_18_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnet/resnet18-1e65cd21.ckpt) |
-| resnet34 | D910x8-G | 74.15 | 91.98 | 21.81 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnet/resnet_34_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnet/resnet34-f297d27e.ckpt) |
-| resnet50 | D910x8-G | 76.69 | 93.50 | 25.61 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnet/resnet_50_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnet/resnet50-e0733ab8.ckpt) |
-| resnet101 | D910x8-G | 78.24 | 94.09 |44.65 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnet/resnet_101_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnet/resnet101-689c5e77.ckpt) |
-| resnet152 | D910x8-G | 78.72 | 94.45 | 60.34| [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnet/resnet_152_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnet/resnet152-beb689d8.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------:|:---------:|:---------:|:----------:|------------|------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------|
+| resnet50 | 76.76 | 93.31 | 25.61 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnet/resnet_50_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/resnet/resnet50-f369a08d-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------:|:---------:|:---------:|:----------:|------------|------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------|
+| resnet50 | 76.69 | 93.50 | 25.61 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnet/resnet_50_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnet/resnet50-e0733ab8.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
-- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
+- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -59,9 +73,11 @@ mpirun -n 8 python train.py --config configs/resnet/resnet_18_ascend.yaml --data
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -74,7 +90,8 @@ python train.py --config configs/resnet/resnet_18_ascend.yaml --data_dir /path/t
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/resnet/resnet_18_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -82,8 +99,10 @@ python validate.py -c configs/resnet/resnet_18_ascend.yaml --data_dir /path/to/i
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
+[1] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on
+computer vision and pattern recognition. 2016: 770-778.
diff --git a/configs/resnetv2/README.md b/configs/resnetv2/README.md
index ceb4b48ee..42a81dfd2 100644
--- a/configs/resnetv2/README.md
+++ b/configs/resnetv2/README.md
@@ -4,7 +4,8 @@
## Introduction
-Author analyzes the propagation formulations behind the residual building blocks, which suggest that the forward and backward signals can be directly propagated from one block
+Author analyzes the propagation formulations behind the residual building blocks, which suggest that the forward and
+backward signals can be directly propagated from one block
to any other block, when using identity mappings as the skip connections and after-addition activation.
@@ -18,35 +19,49 @@ to any other block, when using identity mappings as the skip connections and aft
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|--------------|-----------|-----------|-----------|-------|-------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------|
-| resnetv2_50 | D910x8-G | 76.90 | 93.37 | 25.60 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnetv2/resnetv2_50_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnetv2/resnetv2_50-3c2f143b.ckpt) |
-| resnetv2_101 | D910x8-G | 78.48 | 94.23 | 44.55 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnetv2/resnetv2_101_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnetv2/resnetv2_101-5d4c49a1.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-----------:|:---------:|:---------:|:----------:|------------|----------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------|
+| resnetv2_50 | 77.03 | 93.29 | 25.60 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnetv2/resnetv2_50_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/resnetv2/resnetv2_50-a0b9f7f8-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-----------:|:---------:|:---------:|:----------:|------------|----------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------|
+| resnetv2_50 | 76.90 | 93.37 | 25.60 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnetv2/resnetv2_50_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnetv2/resnetv2_50-3c2f143b.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
-- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
+- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -57,9 +72,11 @@ mpirun -n 8 python train.py --config configs/resnetv2/resnetv2_50_ascend.yaml --
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -72,7 +89,8 @@ python train.py --config configs/resnetv2/resnetv2_50_ascend.yaml --data_dir /pa
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/resnetv2/resnetv2_50_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -80,8 +98,11 @@ python validate.py -c configs/resnetv2/resnetv2_50_ascend.yaml --data_dir /path/
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1] He K, Zhang X, Ren S, et al. Identity mappings in deep residual networks[C]//Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14. Springer International Publishing, 2016: 630-645.
+[1] He K, Zhang X, Ren S, et al. Identity mappings in deep residual networks[C]//Computer Vision–ECCV 2016: 14th
+European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14. Springer International
+Publishing, 2016: 630-645.
diff --git a/configs/resnext/README.md b/configs/resnext/README.md
index 022a7301f..331023f3a 100644
--- a/configs/resnext/README.md
+++ b/configs/resnext/README.md
@@ -1,4 +1,5 @@
# ResNeXt
+
> [Aggregated Residual Transformations for Deep Neural Networks](https://arxiv.org/abs/1611.05431)
## Introduction
@@ -22,20 +23,28 @@ accuracy.[[1](#references)]
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:---------------:|:---------:|:---------:|:----------:|------------|-------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------|
+| resnext50_32x4d | 78.64 | 94.18 | 25.10 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnext/resnext50_32x4d_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/resnext/resnext50_32x4d-988f75bc-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|------------------|----------|-----------|-----------|------------|--------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
-| resnext50_32x4d | D910x8-G | 78.53 | 94.10 | 25.10 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnext/resnext50_32x4d_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnext/resnext50_32x4d-af8aba16.ckpt) |
-| resnext101_32x4d | D910x8-G | 79.83 | 94.80 | 44.32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnext/resnext101_32x4d_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnext/resnext101_32x4d-3c1e9c51.ckpt) |
-| resnext101_64x4d | D910x8-G | 80.30 | 94.82 | 83.66 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnext/resnext101_64x4d_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnext/resnext101_64x4d-8929255b.ckpt) |
-| resnext152_64x4d | D910x8-G | 80.52 | 95.00 | 115.27 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnext/resnext152_64x4d_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnext/resnext152_64x4d-3aba275c.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:---------------:|:---------:|:---------:|:----------:|------------|-------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------|
+| resnext50_32x4d | 78.53 | 94.10 | 25.10 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/resnext/resnext50_32x4d_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/resnext/resnext50_32x4d-af8aba16.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -43,16 +52,20 @@ Our reproduced model performance on ImageNet-1K is reported as follows.
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-ecosystem/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -63,9 +76,11 @@ mpirun -n 8 python train.py --config configs/resnext/resnext50_32x4d_ascend.yaml
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -78,7 +93,8 @@ python train.py --config configs/resnext/resnext50_32x4d_ascend.yaml --data_dir
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/resnext/resnext50_32x4d_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -90,4 +106,5 @@ Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv
## References
-[1] Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1492-1500.
+[1] Xie S, Girshick R, Dollár P, et al. Aggregated residual transformations for deep neural networks[C]//Proceedings of
+the IEEE conference on computer vision and pattern recognition. 2017: 1492-1500.
diff --git a/configs/rexnet/README.md b/configs/rexnet/README.md
index 74edfb0c6..e8905aa16 100644
--- a/configs/rexnet/README.md
+++ b/configs/rexnet/README.md
@@ -2,46 +2,61 @@
> [ReXNet: Rethinking Channel Dimensions for Efficient Model Design](https://arxiv.org/abs/2007.00992)
-## Introduction
+## Introduction
-ReXNets is a new model achieved based on parameterization. It utilizes a new search method for a channel configuration via piece-wise linear functions of block index. The search space contains the conventions, and an effective channel configuration that can be parameterized by a linear function of the block index is used. ReXNets outperforms the recent lightweight models including NAS-based models and further showed remarkable fine-tuning performances on COCO object detection, instance segmentation, and fine-grained classifications.
+ReXNets is a new model achieved based on parameterization. It utilizes a new search method for a channel configuration
+via piece-wise linear functions of block index. The search space contains the conventions, and an effective channel
+configuration that can be parameterized by a linear function of the block index is used. ReXNets outperforms the recent
+lightweight models including NAS-based models and further showed remarkable fine-tuning performances on COCO object
+detection, instance segmentation, and fine-grained classifications.
## Results
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|-----------------|-----------|-------|-------|------------|-------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------|
-| rexnet_09 | D910x8-G | 77.06 | 93.41 | 4.13 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/rexnet/rexnet_x09_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/rexnet/rexnet_09-da498331.ckpt) |
-| rexnet_10 | D910x8-G | 77.38 | 93.60 | 4.84 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/rexnet/rexnet_x10_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/rexnet/rexnet_10-c5fb2dc7.ckpt) |
-| rexnet_13 | D910x8-G | 79.06 | 94.28 | 7.61 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/rexnet/rexnet_x13_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/rexnet/rexnet_13-a49c41e5.ckpt) |
-| rexnet_15 | D910x8-G | 79.95 | 94.74 | 9.79 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/rexnet/rexnet_x15_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/rexnet/rexnet_15-37a931d3.ckpt) |
-| rexnet_20 | D910x8-G | 80.64 | 94.99 | 16.45 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/rexnet/rexnet_x20_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/rexnet/rexnet_20-c5810914.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:---------:|:---------:|:---------:|:----------:|------------|-------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------|
+| rexnet_09 | 76.14 | 92.96 | 4.13 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/rexnet/rexnet_x09_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/rexnet/rexnet_09-00223eb4-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:---------:|:---------:|:---------:|:----------:|------------|-------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|
+| rexnet_09 | 77.06 | 93.41 | 4.13 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/rexnet/rexnet_x09_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/rexnet/rexnet_09-da498331.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
-- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
+- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -52,9 +67,11 @@ mpirun -n 8 python train.py --config configs/rexnet/rexnet_x09_ascend.yaml --dat
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -67,7 +84,8 @@ python train.py --config configs/rexnet/rexnet_x09_ascend.yaml --data_dir /path/
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/rexnet/rexnet_x09_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -75,8 +93,10 @@ python validate.py -c configs/rexnet/rexnet_x09_ascend.yaml --data_dir /path/to/
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1] Han D, Yun S, Heo B, et al. Rethinking channel dimensions for efficient model design[C]//Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. 2021: 732-741.
+[1] Han D, Yun S, Heo B, et al. Rethinking channel dimensions for efficient model design[C]//Proceedings of the IEEE/CVF
+conference on Computer Vision and Pattern Recognition. 2021: 732-741.
diff --git a/configs/senet/README.md b/configs/senet/README.md
index fe7b5050f..aa03b1217 100644
--- a/configs/senet/README.md
+++ b/configs/senet/README.md
@@ -1,4 +1,5 @@
# SENet
+
> [Squeeze-and-Excitation Networks](https://arxiv.org/abs/1709.01507)
## Introduction
@@ -21,21 +22,28 @@ additional computational cost.[[1](#references)]
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:----------:|:---------:|:---------:|:----------:|------------|------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------|
+| seresnet18 | 72.05 | 90.59 | 11.80 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/senet/seresnet18_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/senet/seresnet18-7b971c78-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|-------------------|----------|-----------|-----------|------------|-------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------|
-| seresnet18 | D910x8-G | 71.81 | 90.49 | 11.80 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/senet/seresnet18_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/senet/seresnet18-7880643b.ckpt) |
-| seresnet34 | D910x8-G | 75.38 | 92.50 | 21.98 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/senet/seresnet34_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/senet/seresnet34-8179d3c9.ckpt) |
-| seresnet50 | D910x8-G | 78.32 | 94.07 | 28.14 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/senet/seresnet50_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/senet/seresnet50-ff9cd214.ckpt) |
-| seresnext26_32x4d | D910x8-G | 77.17 | 93.42 | 16.83 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/senet/seresnext26_32x4d_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/senet/seresnext26_32x4d-5361f5b6.ckpt) |
-| seresnext50_32x4d | D910x8-G | 78.71 | 94.36 | 27.63 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/senet/seresnext50_32x4d_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/senet/seresnext50_32x4d-fdc35aca.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:----------:|:---------:|:---------:|:----------:|------------|------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|
+| seresnet18 | 71.81 | 90.49 | 11.80 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/senet/seresnet18_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/senet/seresnet18-7880643b.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -43,16 +51,20 @@ Our reproduced model performance on ImageNet-1K is reported as follows.
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-ecosystem/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -63,9 +75,11 @@ mpirun -n 8 python train.py --config configs/senet/seresnet50_ascend.yaml --data
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -78,7 +92,8 @@ python train.py --config configs/senet/seresnet50_ascend.yaml --data_dir /path/t
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/senet/seresnet50_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -90,4 +105,5 @@ Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv
## References
-[1] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
+[1] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and
+pattern recognition. 2018: 7132-7141.
diff --git a/configs/shufflenetv1/README.md b/configs/shufflenetv1/README.md
index 794f7ebc4..7af6d1587 100644
--- a/configs/shufflenetv1/README.md
+++ b/configs/shufflenetv1/README.md
@@ -4,7 +4,11 @@
## Introduction
-ShuffleNet is a computationally efficient CNN model proposed by KuangShi Technology in 2017, which, like MobileNet and SqueezeNet, etc., is mainly intended to be applied to mobile. ShuffleNet uses two operations at its core: pointwise group convolution and channel shuffle, which greatly reduces the model computation while maintaining accuracy. ShuffleNet designs more efficient network structures to achieve smaller and faster models, instead of compressing or migrating a large trained model.
+ShuffleNet is a computationally efficient CNN model proposed by KuangShi Technology in 2017, which, like MobileNet and
+SqueezeNet, etc., is mainly intended to be applied to mobile. ShuffleNet uses two operations at its core: pointwise
+group convolution and channel shuffle, which greatly reduces the model computation while maintaining accuracy.
+ShuffleNet designs more efficient network structures to achieve smaller and faster models, instead of compressing or
+migrating a large trained model.
 @@ -13,40 +17,53 @@ ShuffleNet is a computationally efficient CNN model proposed by KuangShi Technol
Figure 1. Architecture of ShuffleNetV1 [1]
@@ -13,40 +17,53 @@ ShuffleNet is a computationally efficient CNN model proposed by KuangShi Technol
Figure 1. Architecture of ShuffleNetV1 [1]
-
## Results
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-------------------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------|
+| shufflenet_v1_g3_05 | 57.08 | 79.89 | 0.73 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv1/shufflenet_v1_0.5_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/shufflenet/shufflenetv1/shufflenet_v1_g3_05-56209ef3-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|---------------------|----------|-----------|-----------|------------|--------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------|
-| shufflenet_v1_g3_05 | D910x8-G | 57.05 | 79.73 | 0.73 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv1/shufflenet_v1_0.5_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/shufflenet/shufflenetv1/shufflenet_v1_g3_05-42cfe109.ckpt) |
-| shufflenet_v1_g3_10 | D910x8-G | 67.77 | 87.73 | 1.89 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv1/shufflenet_v1_1.0_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/shufflenet/shufflenetv1/shufflenet_v1_g3_10-245f0ccf.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-------------------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------|
+| shufflenet_v1_g3_05 | 57.05 | 79.73 | 0.73 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv1/shufflenet_v1_0.5_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/shufflenet/shufflenetv1/shufflenet_v1_g3_05-42cfe109.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
-- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
+- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -57,9 +74,11 @@ mpirun -n 8 python train.py --config configs/shufflenetv1/shufflenet_v1_0.5_asce
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -72,7 +91,8 @@ python train.py --config configs/shufflenetv1/shufflenet_v1_0.5_ascend.yaml --da
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/shufflenetv1/shufflenet_v1_0.5_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -80,8 +100,10 @@ python validate.py -c configs/shufflenetv1/shufflenet_v1_0.5_ascend.yaml --data_
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1] Zhang X, Zhou X, Lin M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6848-6856.
+[1] Zhang X, Zhou X, Lin M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices[C]
+//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6848-6856.
diff --git a/configs/shufflenetv2/README.md b/configs/shufflenetv2/README.md
index 0156b9d32..e5649958c 100644
--- a/configs/shufflenetv2/README.md
+++ b/configs/shufflenetv2/README.md
@@ -1,13 +1,18 @@
# ShuffleNetV2
+
> [ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design](https://arxiv.org/abs/1807.11164)
## Introduction
-A key point was raised in ShuffleNetV2, where previous lightweight networks were guided by computing an indirect measure of network complexity, namely FLOPs. The speed of lightweight networks is described by calculating the amount of floating point operations. But the speed of operation was never considered directly. The running speed in mobile devices needs to consider not only FLOPs, but also other factors such as memory accesscost and platform characterics.
+A key point was raised in ShuffleNetV2, where previous lightweight networks were guided by computing an indirect measure
+of network complexity, namely FLOPs. The speed of lightweight networks is described by calculating the amount of
+floating point operations. But the speed of operation was never considered directly. The running speed in mobile devices
+needs to consider not only FLOPs, but also other factors such as memory accesscost and platform characterics.
Therefore, based on these two principles, ShuffleNetV2 proposes four effective network design principles.
-- MAC is minimized when the input feature matrix of the convolutional layer is equal to the output feature matrixchannel (when FLOPs are kept constant).
+- MAC is minimized when the input feature matrix of the convolutional layer is equal to the output feature
+ matrixchannel (when FLOPs are kept constant).
- MAC increases when the groups of GConv increase (while keeping FLOPs constant).
- the higher the fragmentation of the network design, the slower the speed.
- The impact of Element-wise operation is not negligible.
@@ -19,47 +24,59 @@ Therefore, based on these two principles, ShuffleNetV2 proposes four effective n
Figure 1. Architecture Design in ShuffleNetV2 [1]
-
## Results
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:------------------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------|
+| shufflenet_v2_x0_5 | 60.65 | 82.26 | 1.37 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv2/shufflenet_v2_0.5_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/shufflenet/shufflenetv2/shufflenet_v2_x0_5-39d05bb6-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|------------------|----------|-----------|-----------|------------|--------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------|
-| shufflenet_v2_x0_5 | D910x8-G | 60.53 | 82.11 | 1.37 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv2/shufflenet_v2_0.5_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/shufflenet/shufflenetv2/shufflenet_v2_x0_5-8c841061.ckpt) |
-| shufflenet_v2_x1_0 | D910x8-G | 69.47 | 88.88 | 2.29 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv2/shufflenet_v2_1.0_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/shufflenet/shufflenetv2/shufflenet_v2_x1_0-0da4b7fa.ckpt) |
-| shufflenet_v2_x1_5 | D910x8-G | 72.79 | 90.93 | 3.53 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv2/shufflenet_v2_1.5_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/shufflenet/shufflenetv2/shufflenet_v2_x1_5-00b56131.ckpt) |
-| shufflenet_v2_x2_0 | D910x8-G | 75.07 | 92.08 | 7.44 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv2/shufflenet_v2_2.0_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/shufflenet/shufflenetv2/shufflenet_v2_x2_0-ed8e698d.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:------------------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------|
+| shufflenet_v2_x0_5 | 60.53 | 82.11 | 1.37 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/shufflenetv2/shufflenet_v2_0.5_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/shufflenet/shufflenetv2/shufflenet_v2_x0_5-8c841061.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
+
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
#### Notes
- All models are trained on ImageNet-1K training set and the top-1 accuracy is reported on the validatoin set.
-- Context: GPU_TYPE x pieces - G/F, G - graph mode, F - pynative mode with ms function.
-
## Quick Start
+
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
+
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -68,9 +85,11 @@ mpirun -n 8 python train.py --config configs/shufflenetv2/shufflenet_v2_0.5_asce
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -83,7 +102,8 @@ python train.py --config configs/shufflenetv2/shufflenet_v2_0.5_ascend.yaml --da
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```
python validate.py -c configs/shufflenetv2/shufflenet_v2_0.5_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -91,8 +111,11 @@ python validate.py -c configs/shufflenetv2/shufflenet_v2_0.5_ascend.yaml --data_
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
+
-[1] Ma N, Zhang X, Zheng H T, et al. Shufflenet v2: Practical guidelines for efficient cnn architecture design[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 116-131.
+[1] Ma N, Zhang X, Zheng H T, et al. Shufflenet v2: Practical guidelines for efficient cnn architecture design[C]
+//Proceedings of the European conference on computer vision (ECCV). 2018: 116-131.
diff --git a/configs/sknet/README.md b/configs/sknet/README.md
index 673b93d7f..c06ca81ff 100644
--- a/configs/sknet/README.md
+++ b/configs/sknet/README.md
@@ -4,12 +4,15 @@
## Introduction
-The local receptive fields (RFs) of neurons in the primary visual cortex (V1) of cats [[1](#references)] have inspired the
-construction of Convolutional Neural Networks (CNNs) [[2](#references)] in the last century, and it continues to inspire mordern CNN
+The local receptive fields (RFs) of neurons in the primary visual cortex (V1) of cats [[1](#references)] have inspired
+the
+construction of Convolutional Neural Networks (CNNs) [[2](#references)] in the last century, and it continues to inspire
+mordern CNN
structure construction. For instance, it is well-known that in the visual cortex, the RF sizes of neurons in the
same area (e.g.,V1 region) are different, which enables the neurons to collect multi-scale spatial information in the
same processing stage. This mechanism has been widely adopted in recent Convolutional Neural Networks (CNNs).
-A typical example is InceptionNets [[3](#references), [4](#references), [5](#references), [6](#references)], in which a simple concatenation is designed to aggregate
+A typical example is InceptionNets [[3](#references), [4](#references), [5](#references), [6](#references)], in which a
+simple concatenation is designed to aggregate
multi-scale information from, e.g., 3×3, 5×5, 7×7 convolutional kernels inside the “inception” building block.
@@ -23,36 +26,51 @@ multi-scale information from, e.g., 3×3, 5×5, 7×7 convolutional kernels insid
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:----------:|:---------:|:---------:|:----------:|------------|------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------|
+| skresnet18 | 72.85 | 90.83 | 11.97 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/sknet/skresnet18_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/sknet/skresnet18-9d8b1afc-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|-------------------|---------|-----------|-----------|------------|------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------|
-| skresnet18 | D910x8-G | 73.09 | 91.20 | 11.97 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/sknet/skresnet18_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/sknet/skresnet18-868228e5.ckpt) |
-| skresnet34 | D910x8-G | 76.71 | 93.10 | 22.31 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/sknet/skresnet34_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/sknet/skresnet34-d668b629.ckpt) |
-| skresnext50_32x4d | D910x8-G | 79.08 | 94.60 | 37.31 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/sknet/skresnext50_32x4d_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/sknet/skresnext50_32x4d-395413a2.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:----------:|:---------:|:---------:|:----------:|------------|------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|
+| skresnet18 | 73.09 | 91.20 | 11.97 | 64 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/sknet/skresnet18_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/sknet/skresnet18-868228e5.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
-- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
+- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
+
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
+
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -61,9 +79,11 @@ mpirun -n 8 python train.py --config configs/sknet/skresnext50_32x4d_ascend.yaml
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -76,7 +96,8 @@ python train.py --config configs/sknet/skresnext50_32x4d_ascend.yaml --data_dir
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```
python validate.py -c configs/sknet/skresnext50_32x4d_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -84,24 +105,29 @@ python validate.py -c configs/sknet/skresnext50_32x4d_ascend.yaml --data_dir /pa
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
-
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
+
-[1] D. H. Hubel and T. N. Wiesel. Receptive fields, binocular interaction and functional architecture in the cat’s visual
+[1] D. H. Hubel and T. N. Wiesel. Receptive fields, binocular interaction and functional architecture in the cat’s
+visual
cortex. The Journal of Physiology, 1962.
[2] Y . LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation
applied to handwritten zip code recognition. Neural Computation, 1989.
-[3] C. Szegedy, V . V anhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In
+[3] C. Szegedy, V . V anhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer
+vision. In
CVPR, 2016.
-[4] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift.
+[4] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate
+shift.
arXiv preprint arXiv:1502.03167, 2015.
-[5] C. Szegedy, V . V anhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer vision. In
+[5] C. Szegedy, V . V anhoucke, S. Ioffe, J. Shlens, and Z. Wojna. Rethinking the inception architecture for computer
+vision. In
CVPR, 2016.
[6] C. Szegedy, S. Ioffe, V . V anhoucke, and A. A. Alemi. Inception-v4, inception-resnet and the impact of residual
diff --git a/configs/squeezenet/README.md b/configs/squeezenet/README.md
index 2717f1709..0e9ed2eb1 100644
--- a/configs/squeezenet/README.md
+++ b/configs/squeezenet/README.md
@@ -23,37 +23,51 @@ Middle: SqueezeNet with simple bypass; Right: SqueezeNet with complex bypass.
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-------------:|:---------:|:---------:|:----------:|------------|---------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------|
+| squeezenet1_0 | 58.75 | 80.76 | 1.25 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/squeezenet/squeezenet_1.0_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/squeezenet/squeezenet1_0-24010b28-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|---------------|---------|-----------|-----------|------------|---------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------|
-| squeezenet1_0 | D910x8-G | 58.67 | 80.61 | 1.25 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/squeezenet/squeezenet_1.0_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/squeezenet/squeezenet1_0-eb911778.ckpt) |
-| squeezenet1_0 | GPUx8-G | 58.83 | 81.08 | 1.25 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/squeezenet/squeezenet_1.0_gpu.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/squeezenet/squeezenet1_0_gpu-685f5941.ckpt) |
-| squeezenet1_1 | D910x8-G | 58.44 | 80.84 | 1.24 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/squeezenet/squeezenet_1.1_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/squeezenet/squeezenet1_1-da256d3a.ckpt) |
-| squeezenet1_1 | GPUx8-G | 59.18 | 81.41 | 1.24 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/squeezenet/squeezenet_1.1_gpu.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/squeezenet/squeezenet1_1_gpu-0e33234a.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-------------:|:---------:|:---------:|:----------:|------------|---------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
+| squeezenet1_0 | 58.67 | 80.61 | 1.25 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/squeezenet/squeezenet_1.0_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/squeezenet/squeezenet1_0-eb911778.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
-- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
+- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
+
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
+
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -62,9 +76,11 @@ mpirun -n 8 python train.py --config configs/squeezenet/squeezenet_1.0_ascend.ya
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -77,7 +93,8 @@ python train.py --config configs/squeezenet/squeezenet_1.0_ascend.yaml --data_di
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```
python validate.py -c configs/squeezenet/squeezenet_1.0_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -85,9 +102,11 @@ python validate.py -c configs/squeezenet/squeezenet_1.0_ascend.yaml --data_dir /
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
-
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
+
-[1] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size[J]. arXiv preprint arXiv:1602.07360, 2016.
+[1] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB
+model size[J]. arXiv preprint arXiv:1602.07360, 2016.
diff --git a/configs/swintransformer/README.md b/configs/swintransformer/README.md
index f6544b31e..1e4fecae8 100644
--- a/configs/swintransformer/README.md
+++ b/configs/swintransformer/README.md
@@ -1,15 +1,21 @@
# Swin Transformer
+
> [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
## Introduction
+
-The key idea of Swin transformer is that the features in shifted window go through transformer module rather than the whole feature map.
-Besides that, Swin transformer extracts features of different levels. Additionally, compared with Vision Transformer (ViT), the resolution
-of Swin Transformer in different stages varies so that features with different sizes could be learned. Figure 1 shows the model architecture
-of Swin transformer. Swin transformer could achieve better model performance with smaller model parameters and less computation cost
+The key idea of Swin transformer is that the features in shifted window go through transformer module rather than the
+whole feature map.
+Besides that, Swin transformer extracts features of different levels. Additionally, compared with Vision Transformer (
+ViT), the resolution
+of Swin Transformer in different stages varies so that features with different sizes could be learned. Figure 1 shows
+the model architecture
+of Swin transformer. Swin transformer could achieve better model performance with smaller model parameters and less
+computation cost
on ImageNet-1K dataset compared with ViT and ResNet.[[1](#references)]
@@ -20,6 +26,7 @@ on ImageNet-1K dataset compared with ViT and ResNet.[[1](#references)]
## Results
+
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config configs/swintransformer/swin_tiny_ascend.yaml --data_dir /path/to/imagenet
```
+
> If the script is executed by the root user, the `--allow-run-as-root` parameter must be added to `mpirun`.
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -85,7 +111,8 @@ python train.py --config configs/swintransformer/swin_tiny_ascend.yaml --data_di
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```
python validate.py -c configs/swintransformer/swin_tiny_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -96,6 +123,8 @@ python validate.py -c configs/swintransformer/swin_tiny_ascend.yaml --data_dir /
Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/) in MindCV.
## References
+
-[1] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 10012-10022.
+[1] Liu Z, Lin Y, Cao Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]//Proceedings
+of the IEEE/CVF international conference on computer vision. 2021: 10012-10022.
diff --git a/configs/swintransformerv2/README.md b/configs/swintransformerv2/README.md
index 18bf88cba..63b221a91 100644
--- a/configs/swintransformerv2/README.md
+++ b/configs/swintransformerv2/README.md
@@ -1,4 +1,5 @@
# Swin Transformer V2
+
> [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883)
## Introduction
@@ -23,17 +24,28 @@ semantic segmentation, and Kinetics-400 video action classification.[[1](#refere
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-------------------:|:---------:|:---------:|:----------:|------------|---------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------|
+| swinv2_tiny_window8 | 81.38 | 95.46 | 28.78 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/swintransformerv2/swinv2_tiny_window8_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/swinv2/swinv2_tiny_window8-70c5e903-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|----------------------|----------|-----------|-----------|------------|---------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------|
-| swinv2_tiny_window8 | D910x8-G | 81.42 | 95.43 | 28.78 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/swintransformerv2/swinv2_tiny_window8_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/swinv2/swinv2_tiny_window8-3ef8b787.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-------------------:|:---------:|:---------:|:----------:|------------|---------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------|
+| swinv2_tiny_window8 | 81.42 | 95.43 | 28.78 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/swintransformerv2/swinv2_tiny_window8_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/swinv2/swinv2_tiny_window8-3ef8b787.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -41,16 +53,20 @@ Our reproduced model performance on ImageNet-1K is reported as follows.
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-ecosystem/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -61,9 +77,11 @@ mpirun -n 8 python train.py --config configs/swintransformerv2/swinv2_tiny_windo
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -76,7 +94,8 @@ python train.py --config configs/swintransformerv2/swinv2_tiny_window8_ascend.ya
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/swintransformerv2/swinv2_tiny_window8_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -88,4 +107,5 @@ Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv
## References
-[1] Liu Z, Hu H, Lin Y, et al. Swin transformer v2: Scaling up capacity and resolution[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 12009-12019.
+[1] Liu Z, Hu H, Lin Y, et al. Swin transformer v2: Scaling up capacity and resolution[C]//Proceedings of the IEEE/CVF
+conference on computer vision and pattern recognition. 2022: 12009-12019.
diff --git a/configs/vgg/README.md b/configs/vgg/README.md
index 76f9cca47..a6dd460eb 100644
--- a/configs/vgg/README.md
+++ b/configs/vgg/README.md
@@ -1,13 +1,17 @@
# VGGNet
+
> [Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/abs/1409.1556)
## Introduction
+
-Figure 1 shows the model architecture of VGGNet. VGGNet is a key milestone on image classification task. It expands the model to 16-19 layers for the first time. The key motivation of this model is
-that it shows usage of 3x3 kernels is efficient and by adding 3x3 kernels, it could have the same effect as 5x5 or 7x7 kernels. VGGNet could achieve better model performance compared with previous
+Figure 1 shows the model architecture of VGGNet. VGGNet is a key milestone on image classification task. It expands the
+model to 16-19 layers for the first time. The key motivation of this model is
+that it shows usage of 3x3 kernels is efficient and by adding 3x3 kernels, it could have the same effect as 5x5 or 7x7
+kernels. VGGNet could achieve better model performance compared with previous
methods such as GoogleLeNet and AlexNet on ImageNet-1K dataset.[[1](#references)]
@@ -18,6 +22,7 @@ methods such as GoogleLeNet and AlexNet on ImageNet-1K dataset.[[1](#references)
## Results
+
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distrubted training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config configs/vgg/vgg16_ascend.yaml --data_dir /path/to/imagenet
```
+
> If the script is executed by the root user, the `--allow-run-as-root` parameter must be added to `mpirun`.
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -86,7 +109,8 @@ python train.py --config configs/vgg/vgg16_ascend.yaml --data_dir /path/to/datas
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```
python validate.py -c configs/vgg/vgg16_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -97,6 +121,8 @@ python validate.py -c configs/vgg/vgg16_ascend.yaml --data_dir /path/to/imagenet
Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/) in MindCV.
## References
+
-[1] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv:1409.1556, 2014.
+[1] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint
+arXiv:1409.1556, 2014.
diff --git a/configs/visformer/README.md b/configs/visformer/README.md
index 4d37cd462..1594f342b 100644
--- a/configs/visformer/README.md
+++ b/configs/visformer/README.md
@@ -1,9 +1,15 @@
# Visformer
-> [Visformer: The Vision-friendly Transformer](https://arxiv.org/abs/2104.12533)
+
+> [Visformer: The Vision-friendly Transformer](https://arxiv.org/abs/2104.12533)
## Introduction
-Visformer, or Vision-friendly Transformer, is an architecture that combines Transformer-based architectural features with those from convolutional neural network architectures. Visformer adopts the stage-wise design for higher base performance. But self-attentions are only utilized in the last two stages, considering that self-attention in the high-resolution stage is relatively inefficient even when the FLOPs are balanced. Visformer employs bottleneck blocks in the first stage and utilizes group 3 × 3 convolutions in bottleneck blocks inspired by ResNeXt. It also introduces BatchNorm to patch embedding modules as in CNNs. [[2](#references)]
+Visformer, or Vision-friendly Transformer, is an architecture that combines Transformer-based architectural features
+with those from convolutional neural network architectures. Visformer adopts the stage-wise design for higher base
+performance. But self-attentions are only utilized in the last two stages, considering that self-attention in the
+high-resolution stage is relatively inefficient even when the FLOPs are balanced. Visformer employs bottleneck blocks in
+the first stage and utilizes group 3 × 3 convolutions in bottleneck blocks inspired by ResNeXt. It also introduces
+BatchNorm to patch embedding modules as in CNNs. [[2](#references)]
 @@ -18,35 +24,49 @@ Visformer, or Vision-friendly Transformer, is an architecture that combines Tran
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
@@ -18,35 +24,49 @@ Visformer, or Vision-friendly Transformer, is an architecture that combines Tran
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|--------------------|----------|-----------|-----------|------------|------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------|
-| visformer_tiny | D910x8-G | 78.28 | 94.15 | 10.33 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/visformer/visformer_tiny_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/visformer/visformer_tiny-daee0322.ckpt) |
-| visformer_tiny_v2 | D910x8-G | 78.82 | 94.41 | 9.38 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/visformer/visformer_tiny_v2_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/visformer/visformer_tiny_v2-6711a758.ckpt) |
-| visformer_small | D910x8-G | 81.76 | 95.88 | 40.25 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/visformer/visformer_small_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/visformer/visformer_small-6c83b6db.ckpt) |
-| visformer_small_v2 | D910x8-G | 82.17 | 95.90 | 23.52 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/visformer/visformer_small_v2_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/visformer/visformer_small_v2-63674ade.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------|
+| visformer_tiny | 78.40 | 94.30 | 10.33 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/visformer/visformer_tiny_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/visformer/visformer_tiny-df995ba4-910v2.ckpt) |
+
+
+
+performance tested on ascend 910(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------|
+| visformer_tiny | 78.28 | 94.15 | 10.33 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/visformer/visformer_tiny_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/visformer/visformer_tiny-daee0322.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
+
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
+
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -55,9 +75,11 @@ mpirun -n 8 python train.py --config configs/visformer/visformer_tiny_ascend.yam
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -70,7 +92,8 @@ python train.py --config configs/visformer/visformer_tiny_ascend.yaml --data_dir
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```
python validate.py -c configs/visformer/visformer_tiny_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -78,9 +101,12 @@ python validate.py -c configs/visformer/visformer_tiny_ascend.yaml --data_dir /p
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1] Chen Z, Xie L, Niu J, et al. Visformer: The vision-friendly transformer. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 589-598.
+
+[1] Chen Z, Xie L, Niu J, et al. Visformer: The vision-friendly transformer. Proceedings of the IEEE/CVF International
+Conference on Computer Vision. 2021: 589-598.
[2] Visformer, https://paperswithcode.com/method/visformer
diff --git a/configs/vit/README.md b/configs/vit/README.md
index bdf225d67..562238afe 100644
--- a/configs/vit/README.md
+++ b/configs/vit/README.md
@@ -1,14 +1,23 @@
# ViT
+
> [ An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929)
## Introduction
+
-Vision Transformer (ViT) achieves remarkable results compared to convolutional neural networks (CNN) while obtaining fewer computational resources for pre-training. In comparison to convolutional neural networks (CNN), Vision Transformer (ViT) shows a generally weaker inductive bias resulting in increased reliance on model regularization or data augmentation (AugReg) when training on smaller datasets.
+Vision Transformer (ViT) achieves remarkable results compared to convolutional neural networks (CNN) while obtaining
+fewer computational resources for pre-training. In comparison to convolutional neural networks (CNN), Vision
+Transformer (ViT) shows a generally weaker inductive bias resulting in increased reliance on model regularization or
+data augmentation (AugReg) when training on smaller datasets.
-The ViT is a visual model based on the architecture of a transformer originally designed for text-based tasks, as shown in the below figure. The ViT model represents an input image as a series of image patches, like the series of word embeddings used when using transformers to text, and directly predicts class labels for the image. ViT exhibits an extraordinary performance when trained on enough data, breaking the performance of a similar state-of-art CNN with 4x fewer computational resources. [[2](#references)]
+The ViT is a visual model based on the architecture of a transformer originally designed for text-based tasks, as shown
+in the below figure. The ViT model represents an input image as a series of image patches, like the series of word
+embeddings used when using transformers to text, and directly predicts class labels for the image. ViT exhibits an
+extraordinary performance when trained on enough data, breaking the performance of a similar state-of-art CNN with 4x
+fewer computational resources. [[2](#references)]
@@ -20,6 +29,7 @@ The ViT is a visual model based on the architecture of a transformer originally
## Results
+
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config configs/vit/vit_b32_224_ascend.yaml --data_dir /path/to/imagenet
```
+
> If the script is executed by the root user, the `--allow-run-as-root` parameter must be added to `mpirun`.
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
**Note:**
-1) As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
-2) The current configuration with a batch_size of 512, was initially set for a machine with 64GB of VRAM. To avoid running out of memory (OOM) on machines with smaller VRAM, consider reducing the batch_size to 256 or lower. Simultaneously, to maintain the consistency of training results, please scale the learning rate down proportionally with decreasing batch_size.
+
+1) As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the
+ global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+2) The current configuration with a batch_size of 512, was initially set for a machine with 64GB of VRAM. To avoid
+ running out of memory (OOM) on machines with smaller VRAM, consider reducing the batch_size to 256 or lower.
+ Simultaneously, to maintain the consistency of training results, please scale the learning rate down proportionally
+ with decreasing batch_size.
* Standalone Training
@@ -88,7 +108,8 @@ python train.py --config configs/vit/vit_b32_224_ascend.yaml --data_dir /path/to
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```
python validate.py -c configs/vit/vit_b32_224_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -96,11 +117,14 @@ python validate.py -c configs/vit/vit_b32_224_ascend.yaml --data_dir /path/to/im
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
+
-[1] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
+[1] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at
+scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[2] "Vision Transformers (ViT) in Image Recognition – 2022 Guide", https://viso.ai/deep-learning/vision-transformer-vit/
diff --git a/configs/volo/README.md b/configs/volo/README.md
index 743df4442..9948f4c09 100644
--- a/configs/volo/README.md
+++ b/configs/volo/README.md
@@ -2,9 +2,15 @@
> [VOLO: Vision Outlooker for Visual Recognition ](https://arxiv.org/abs/2106.13112)
-## Introduction
+## Introduction
-Vision Outlooker (VOLO), a novel outlook attention, presents a simple and general architecture. Unlike self-attention that focuses on global dependency modeling at a coarse level, the outlook attention efficiently encodes finer-level features and contexts into tokens, which is shown to be critically beneficial to recognition performance but largely ignored by the self-attention. Five versions different from model scaling are introduced based on the proposed VOLO: VOLO-D1 with 27M parameters to VOLO-D5 with 296M. Experiments show that the best one, VOLO-D5, achieves 87.1% top-1 accuracy on ImageNet-1K classification, which is the first model exceeding 87% accuracy on this competitive benchmark, without using any extra training data.
+Vision Outlooker (VOLO), a novel outlook attention, presents a simple and general architecture. Unlike self-attention
+that focuses on global dependency modeling at a coarse level, the outlook attention efficiently encodes finer-level
+features and contexts into tokens, which is shown to be critically beneficial to recognition performance but largely
+ignored by the self-attention. Five versions different from model scaling are introduced based on the proposed VOLO:
+VOLO-D1 with 27M parameters to VOLO-D5 with 296M. Experiments show that the best one, VOLO-D5, achieves 87.1% top-1
+accuracy on ImageNet-1K classification, which is the first model exceeding 87% accuracy on this competitive benchmark,
+without using any extra training data.
 @@ -17,36 +23,43 @@ Vision Outlooker (VOLO), a novel outlook attention, presents a simple and genera
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+*coming soon*
+
+performance tested on ascend 910(8p) with graph mode
+
@@ -17,36 +23,43 @@ Vision Outlooker (VOLO), a novel outlook attention, presents a simple and genera
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+*coming soon*
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Weight |
-|-----------------|-----------|-------|------------|------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------|----------------------------------------------------------------------------------|
-| volo_d1 | D910x8-G | 82.59 | 95.99 | 27 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/volo/volo_d1_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/volo/volo_d1-c7efada9.ckpt) |
-| volo_d2 | D910x8-G | 82.95 | 96.13 | 59 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/volo/volo_d2_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/volo/volo_d2-0910a460.ckpt) |
-| volo_d3 | D910x8-G | 83.38 | 96.28 | 87 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/volo/volo_d3_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/volo/volo_d3-25916c36.ckpt) |
-| volo_d4 | D910x8-G | 82.5 | 95.86 | 193 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/volo/volo_d4_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/volo/volo_d4-6c88cd33.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:-------:|:---------:|:---------:|:----------:|------------|--------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------|
+| volo_d1 | 82.59 | 95.99 | 27 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/volo/volo_d1_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/volo/volo_d1-c7efada9.ckpt) |
+
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
-- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
+- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-lab/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -57,9 +70,11 @@ mpirun -n 8 python train.py --config configs/volo/volo_d1_ascend.yaml --data_dir
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep
+the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
- Standalone Training
@@ -72,7 +87,8 @@ python train.py --config configs/volo/volo_d1_ascend.yaml --data_dir /path/to/da
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/volo/volo_d1_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -80,8 +96,10 @@ python validate.py -c configs/volo/volo_d1_ascend.yaml --data_dir /path/to/image
### Deployment
-To deploy online inference services with the trained model efficiently, please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
+To deploy online inference services with the trained model efficiently, please refer to
+the [deployment tutorial](https://mindspore-lab.github.io/mindcv/tutorials/deployment/).
## References
-[1] Yuan L , Hou Q , Jiang Z , et al. VOLO: Vision Outlooker for Visual Recognition[J]. . arXiv preprint arXiv:2106.13112, 2021.
+[1] Yuan L , Hou Q , Jiang Z , et al. VOLO: Vision Outlooker for Visual Recognition[J]. . arXiv preprint arXiv:
+2106.13112, 2021.
diff --git a/configs/xception/README.md b/configs/xception/README.md
index 61ff965a5..efba12395 100644
--- a/configs/xception/README.md
+++ b/configs/xception/README.md
@@ -1,4 +1,5 @@
# Xception
+
> [Xception: Deep Learning with Depthwise Separable Convolutions](https://arxiv.org/pdf/1610.02357.pdf)
## Introduction
@@ -9,7 +10,8 @@ interprets the Inception module in convolutional neural networks as an intermedi
depthwise separable convolution operations. From this point of view, the depthwise separable convolution can be
understood as having the largest number of Inception modules, that is, the extreme idea proposed in the paper, combined
with the idea of residual network, Google proposed a new type of deep convolutional neural network inspired by Inception
-Network architecture where the Inception module has been replaced by a depthwise separable convolution module.[[1](#references)]
+Network architecture where the Inception module has been replaced by a depthwise separable convolution
+module.[[1](#references)]
 @@ -22,17 +24,22 @@ Network architecture where the Inception module has been replaced by a depthwise
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+*coming soon*
+
+performance tested on ascend 910(8p) with graph mode
+
@@ -22,17 +24,22 @@ Network architecture where the Inception module has been replaced by a depthwise
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
+*coming soon*
+
+performance tested on ascend 910(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|----------|----------|-----------|-----------|------------|-------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------|
-| xception | D910x8-G | 79.01 | 94.25 | 22.91 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/xception/xception_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/xception/xception-2c1e711df.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------:|:---------:|:---------:|:----------:|------------|-------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|
+| xception | 79.01 | 94.25 | 22.91 | 32 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/xception/xception_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/xception/xception-2c1e711df.ckpt) |
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -40,16 +47,20 @@ Our reproduced model performance on ImageNet-1K is reported as follows.
### Preparation
#### Installation
+
Please refer to the [installation instruction](https://github.com/mindspore-ecosystem/mindcv#installation) in MindCV.
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
@@ -60,9 +71,11 @@ mpirun -n 8 python train.py --config configs/xception/xception_ascend.yaml --dat
Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -75,7 +88,8 @@ python train.py --config configs/xception/xception_ascend.yaml --data_dir /path/
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```shell
python validate.py -c configs/xception/xception_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -87,4 +101,5 @@ Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv
## References
-[1] Chollet F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1251-1258.
+[1] Chollet F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on
+computer vision and pattern recognition. 2017: 1251-1258.
diff --git a/configs/xcit/README.md b/configs/xcit/README.md
index c20fe5c77..1f8b4b306 100644
--- a/configs/xcit/README.md
+++ b/configs/xcit/README.md
@@ -1,9 +1,14 @@
# XCiT: Cross-Covariance Image Transformers
> [XCiT: Cross-Covariance Image Transformers](https://arxiv.org/abs/2106.09681)
+
## Introduction
-XCiT models propose a “transposed” version of self-attention that operates across feature channels rather than tokens, where the interactions are based on the cross-covariance matrix between keys and queries. The resulting cross-covariance attention (XCA) has linear complexity in the number of tokens, and allows efficient processing of high-resolution images. Our cross-covariance image transformer (XCiT) – built upon XCA – combines the accuracy of conventional transformers with the scalability of convolutional architectures.
+XCiT models propose a “transposed” version of self-attention that operates across feature channels rather than tokens,
+where the interactions are based on the cross-covariance matrix between keys and queries. The resulting cross-covariance
+attention (XCA) has linear complexity in the number of tokens, and allows efficient processing of high-resolution
+images. Our cross-covariance image transformer (XCiT) – built upon XCA – combines the accuracy of conventional
+transformers with the scalability of convolutional architectures.
 @@ -16,18 +21,28 @@ XCiT models propose a “transposed” version of self-attention that operates a
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
@@ -16,18 +21,28 @@ XCiT models propose a “transposed” version of self-attention that operates a
Our reproduced model performance on ImageNet-1K is reported as follows.
+performance tested on ascend 910*(8p) with graph mode
+
-| Model | Context | Top-1 (%) | Top-5 (%) | Params (M) | Recipe | Download |
-|--------------|----------|-----------|-----------|------------|-----------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------|
-| xcit_tiny_12_p16_224 | D910x8-G | 77.67 | 93.79 | 7.00 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/xcit/xcit_tiny_12_p16_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/xcit/xcit_tiny_12_p16_224-1b1c9301.ckpt) |
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------------------:|:---------:|:---------:|:----------:|------------|-----------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------|
+| xcit_tiny_12_p16_224 | 77.27 | 93.56 | 7.00 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/xcit/xcit_tiny_12_p16_ascend.yaml) | [weights](https://download-mindspore.osinfra.cn/toolkits/mindcv/xcit/xcit_tiny_12_p16_224-bd90776e-910v2.ckpt) |
+performance tested on ascend 910(8p) with graph mode
+
+
+
+| Model | Top-1 (%) | Top-5 (%) | Params (M) | Batch Size | Recipe | Download |
+|:--------------------:|:---------:|:---------:|:----------:|------------|-----------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------|
+| xcit_tiny_12_p16_224 | 77.67 | 93.79 | 7.00 | 128 | [yaml](https://github.com/mindspore-lab/mindcv/blob/main/configs/xcit/xcit_tiny_12_p16_ascend.yaml) | [weights](https://download.mindspore.cn/toolkits/mindcv/xcit/xcit_tiny_12_p16_224-1b1c9301.ckpt) |
+
+
#### Notes
-- Context: Training context denoted as {device}x{pieces}-{MS mode}, where mindspore mode can be G - graph mode or F - pynative mode with ms function. For example, D910x8-G is for training on 8 pieces of Ascend 910 NPU using graph mode.
- Top-1 and Top-5: Accuracy reported on the validation set of ImageNet-1K.
## Quick Start
@@ -40,24 +55,29 @@ Please refer to the [installation instruction](https://github.com/mindspore-lab/
#### Dataset Preparation
-Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training and validation.
+Please download the [ImageNet-1K](https://www.image-net.org/challenges/LSVRC/2012/index.php) dataset for model training
+and validation.
### Training
* Distributed Training
-It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple Ascend 910 devices, please run
+It is easy to reproduce the reported results with the pre-defined training recipe. For distributed training on multiple
+Ascend 910 devices, please run
```shell
# distributed training on multiple GPU/Ascend devices
mpirun -n 8 python train.py --config configs/xcit/xcit_tiny_12_p16_ascend.yaml --data_dir /path/to/imagenet
```
+
> If the script is executed by the root user, the `--allow-run-as-root` parameter must be added to `mpirun`.
-Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
+> Similarly, you can train the model on multiple GPU devices with the above `mpirun` command.
-For detailed illustration of all hyper-parameters, please refer to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
+For detailed illustration of all hyper-parameters, please refer
+to [config.py](https://github.com/mindspore-lab/mindcv/blob/main/config.py).
-**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
+**Note:** As the global batch size (batch_size x num_devices) is an important hyper-parameter, it is recommended to
+keep the global batch size unchanged for reproduction or adjust the learning rate linearly to a new global batch size.
* Standalone Training
@@ -70,7 +90,8 @@ python train.py --config configs/xcit/xcit_tiny_12_p16_ascend.yaml --data_dir /p
### Validation
-To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path with `--ckpt_path`.
+To validate the accuracy of the trained model, you can use `validate.py` and parse the checkpoint path
+with `--ckpt_path`.
```
python validate.py -c configs/xcit/xcit_tiny_12_p16_224_ascend.yaml --data_dir /path/to/imagenet --ckpt_path /path/to/ckpt
@@ -83,4 +104,5 @@ Please refer to the [deployment tutorial](https://mindspore-lab.github.io/mindcv
## References
-[1] Ali A, Touvron H, Caron M, et al. Xcit: Cross-covariance image transformers[J]. Advances in neural information processing systems, 2021, 34: 20014-20027.
+[1] Ali A, Touvron H, Caron M, et al. Xcit: Cross-covariance image transformers[J]. Advances in neural information
+processing systems, 2021, 34: 20014-20027.