+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+  +
+ 
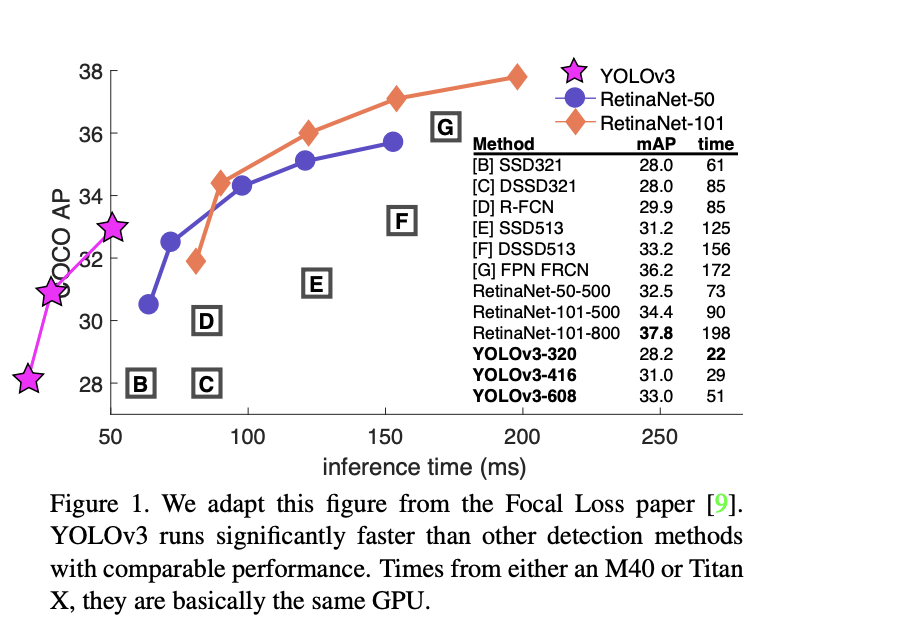 +
+ +
+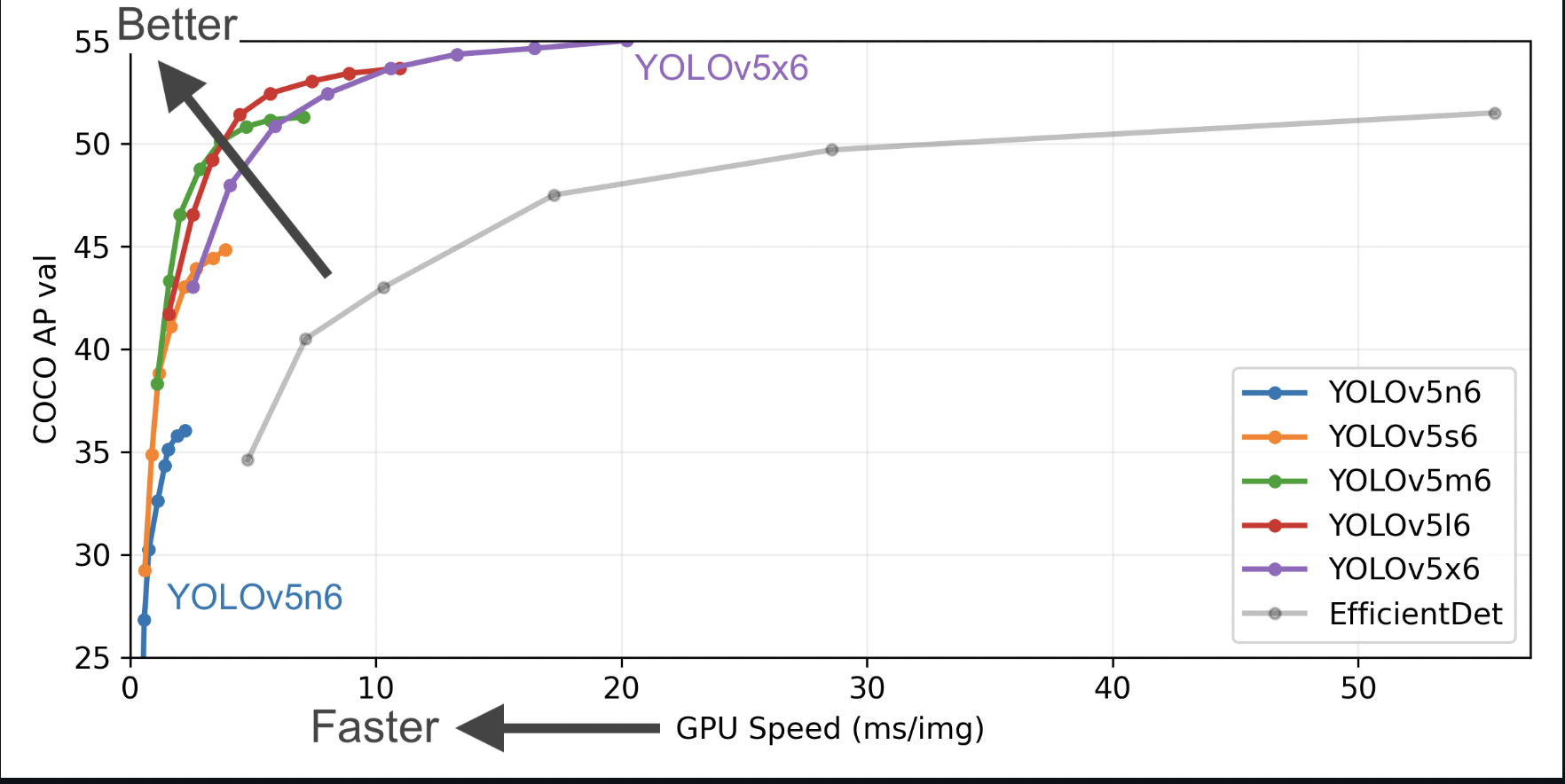 +
+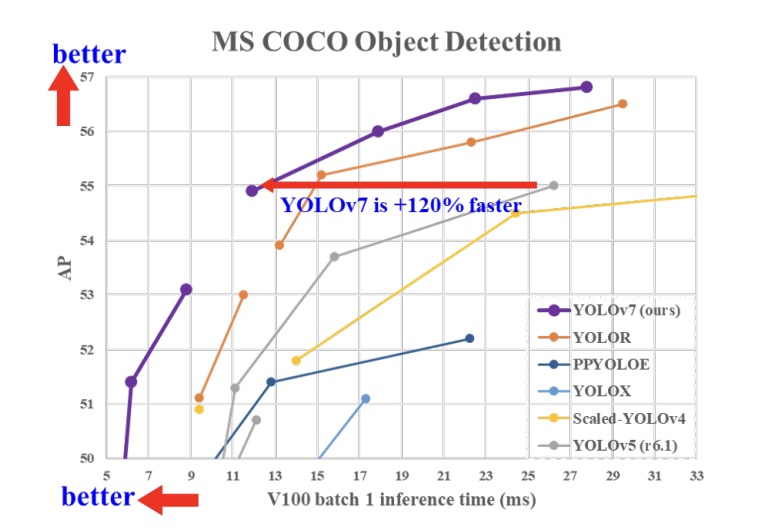 +
+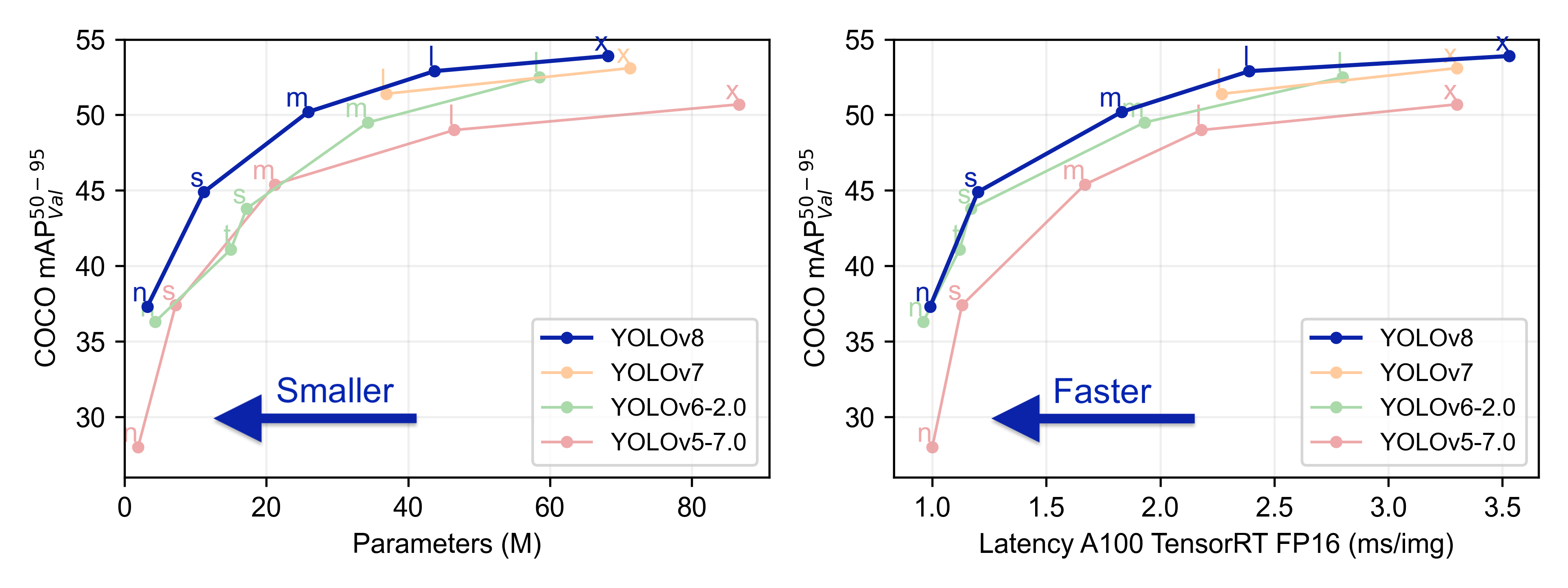 +
+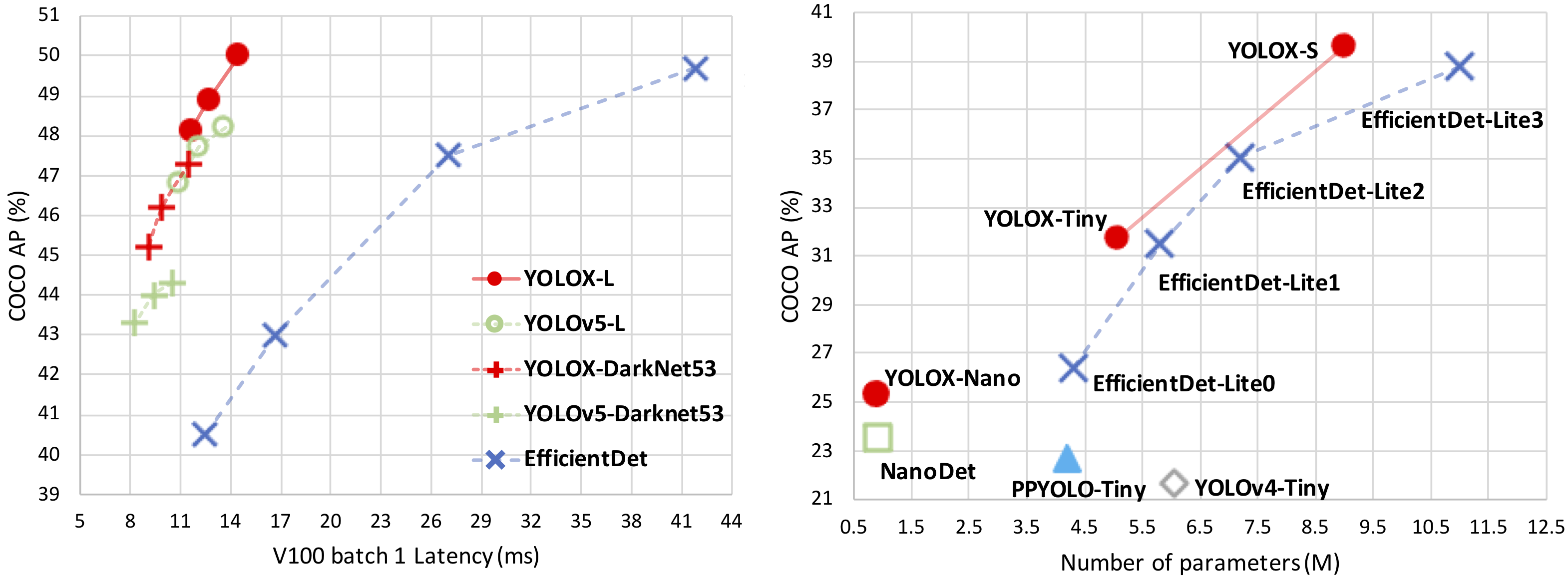 +
+

 +
+


 +
+ 



 +
+ 

 +
+ 

