Submission for McGill CodeJam2019 Hackathon
Machine Learning has recently seen an exponential explosion in new research. Keeping up with the huge volume of new papers can be a real challenge for students, researchers, and professionals in the field. We wanted to build a prototype that helps users efficiently search for papers, get personalized recommendations, and discover new papers.
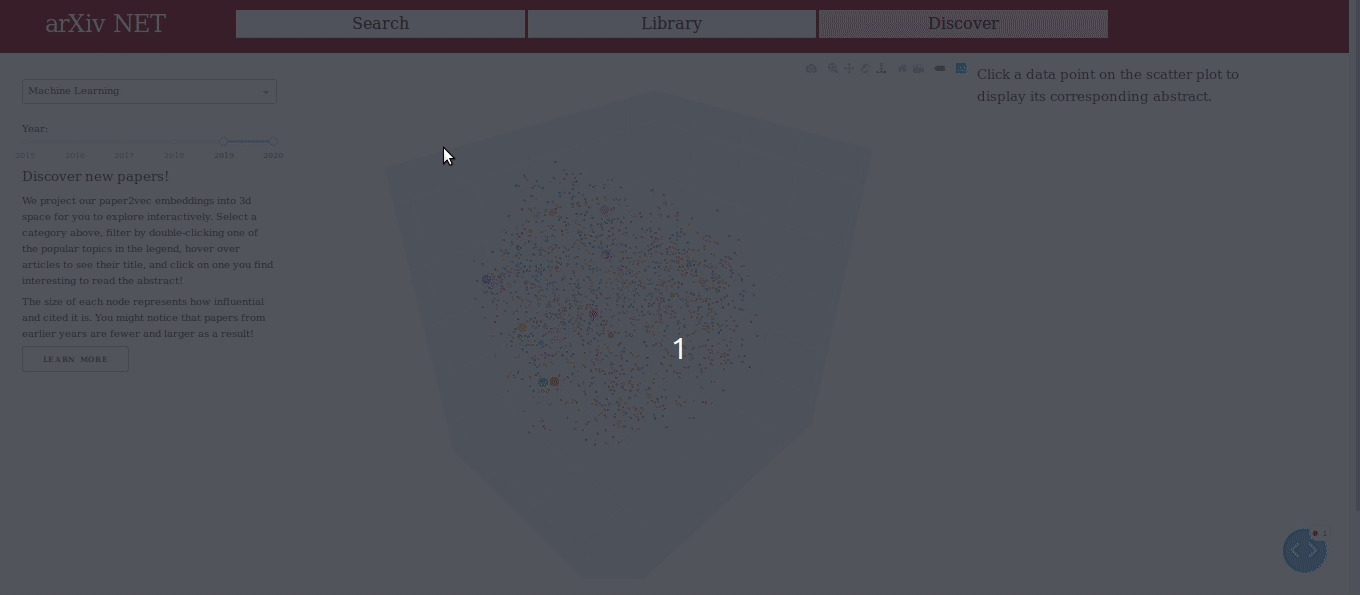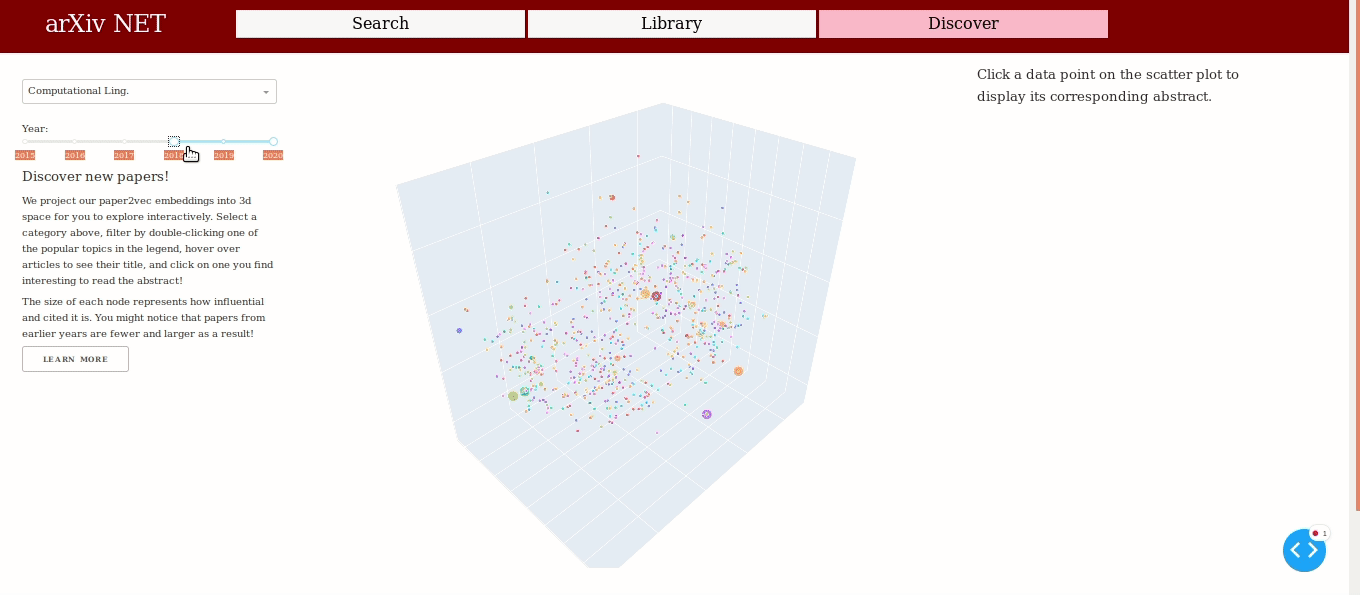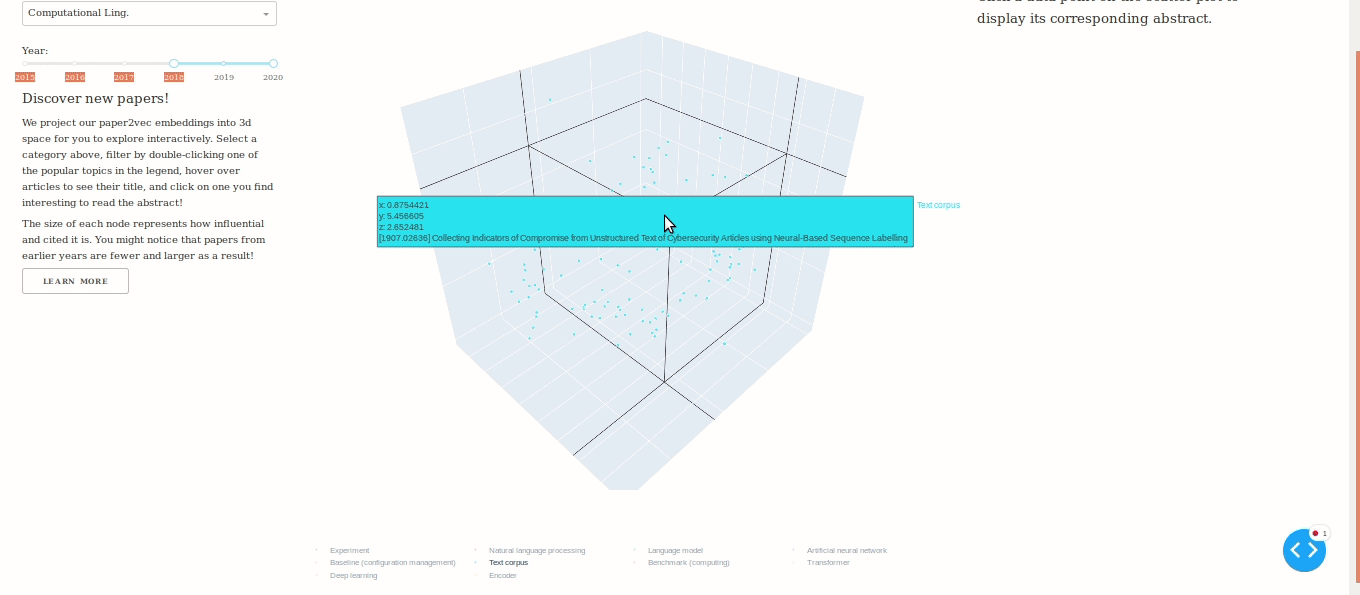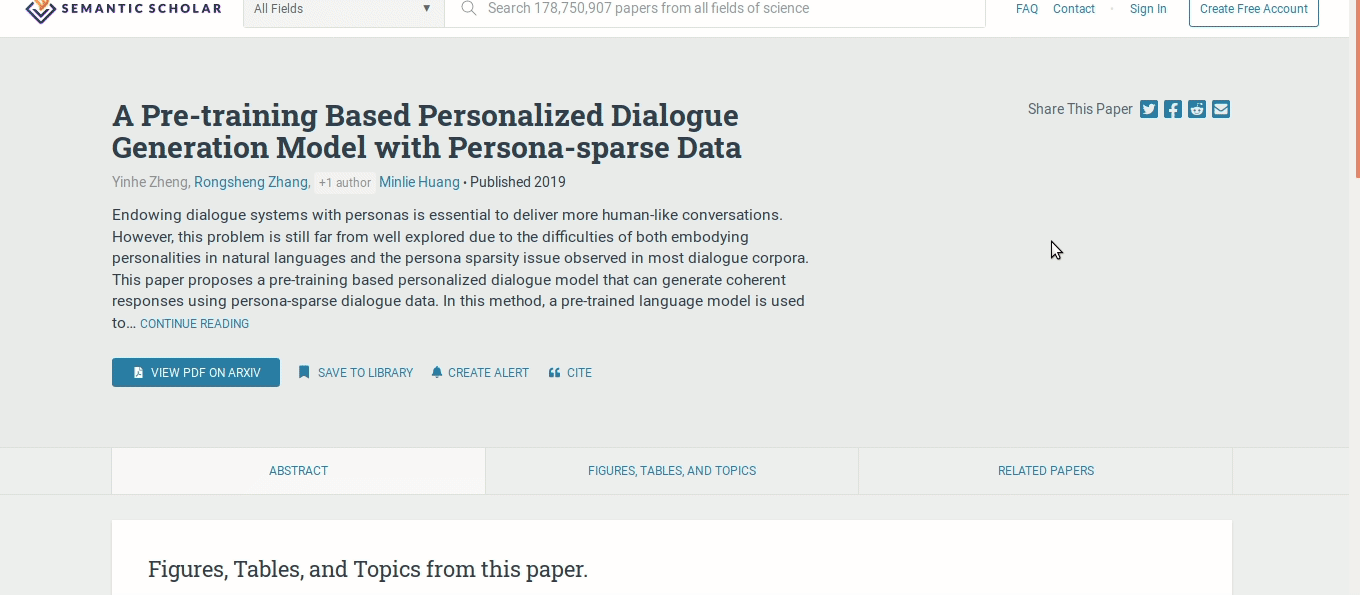
ArXivNet offers an interactive view of the semantic paper embeddings compressed into 3D-space with principal component analysis (PCA) and t-SNE. Using this, the user can see clusters of different papers showing their similarities to discover new papers on a given topic.
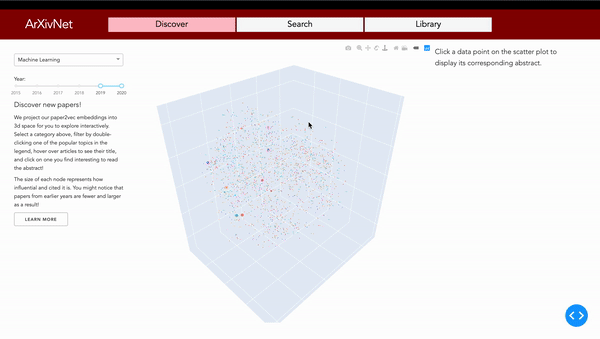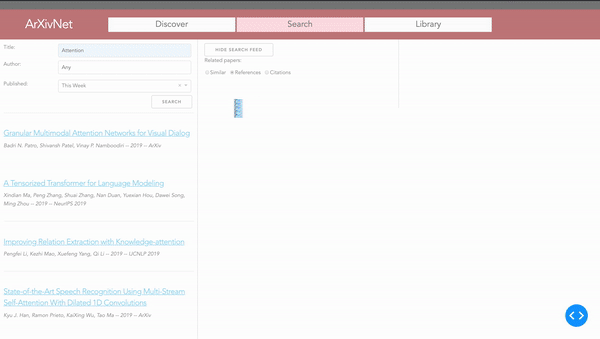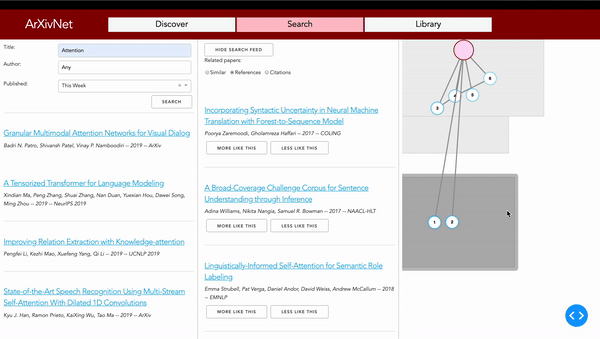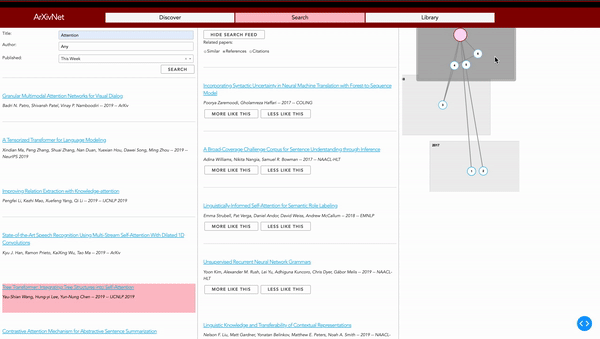
ArXivNet provides a different way to search through arXiv papers. After finding a paper, the user is able to get a list of related papers. These include papers which were referenced by the original, papers which cite the original, or papers which are deemed to be similar by checking cosine similarity of the vector representations of the papers on arXiv. The related papers can be viewed in list-form or in a graph which shows the ordering of the papers through time, and represents citations as arrows between them. This allows the user to see at a glance who has built upon the paper they've searched for, what the paper itself was built upon, and other papers with similar ideas.
ArXivNet also offers a user library where they can save papers they're interested in, as well as a recommendation feed which suggests new papers based off of the users saved papers and previous searches.