A C++ module for Object Detection and tracking (in this case humans are detected, but 80 classes from COCO dataset can be detected). The coordinates of all the objects detected in the camera frame are transformed into robot reference frame for further processing.
- Naitri Rajyaguru, Robotics Graduate Student at University of Maryland, College Park.
- Mayank Joshi, Robotics Graduate Student at University of Maryland, College Park.
Human detection is a part of object detection where primary class “human/person” is detected in images or video frames. In robotics, human detection is very necessary as humans are dynamic obstacles and no one would want a robot colliding with a human. Therefore, for navigation, a robot needs to detect and identify humans in its field of view.
We propose a human detection and tracking module, which uses computer vision algorithms to perceive the environment. The module uses a monocular camera to get frames in which humans are first detected by a deep neural network model and then those are tracked till they are present in the frame. Alot of research has been done in the field of object detection, especially human detection. Although quite a lot algorithms are quite efficient, like HOG (Histogram of Oriented Gradients) but they are not as robust as a deep neural network. Now days we have processing power that could run DNN model in real time and the accuracy of the model can be increased by training it on more data, therefore a scope of improvement is always present. Our module also has the capability to obtain training data and check the performance of DNN model on the test data, which can be provided by the user.
We plan to use YoloV4-tiny, a pre-trained model based on Darknet framework.

Image taken from this article
- Project: Acme Robotics Human(s) obstacle detector and tracker in robot reference frame
- Overview of prosposed work, including risks, mitigation, timeline
- UML and activity diagrams
- Travis code coverage setup with Coveralls
- Developer-level documentation
- The model is trained on MS COCO dataset which contains RGB images therefore would not able to work with infrared cameras or in low light. Training on additional low light and data from infrared camera can make the model more robust
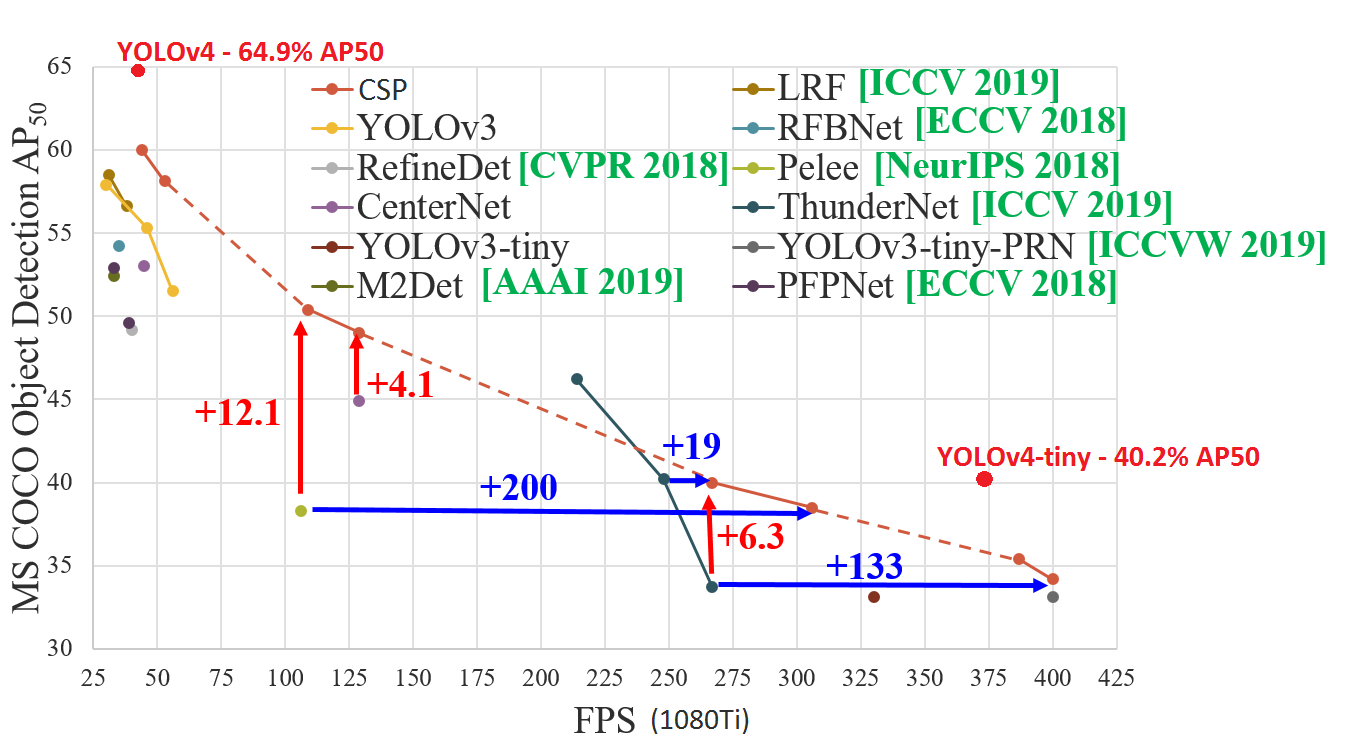
- Since yoloV4-tiny is the compressed version of yoloV4, therefore it lacks in accuracy. YoloV4 achieves an average precision of 64.9% while yoloV4-tiny achieves an average precision of 40.2%. Check full comparison here
- Running the system on the robot can memory expensive due to deep learning model, one possible solution is to quantize the weights of the model so that it takes less memory and is faster
- The class dependency diagram of the proposed design:

-
Activity diagram

-
Quadchart and Proposal of 2 pages can be found here

- OpenCV 4.5.0 (covered under the open-source Apache 2 License)
- Eigen 3.4 the Mozilla Public License 2.0
- GTest BSD 3-Clause "New" or "Revised" License
Install OpenCV 4.5.0 and other dependencies using the following command found in Acme-Robotics-Human-Tracker directory
sh requirements.sh
With the following steps you can clone this repository in you local machine and build it.
git clone --recursive https://github.com/mjoshi07/Acme-Robotics-Human-Tracker
cd Acme-Robotics-Human-Tracker
mkdir build
cd build
cmake ..
make
To run tests of this module, use the following command
./tests/human-tracker-test
To use, webcam uncomment the line in Autobot.cpp #216 and comment line #219
./app/human-tracker
- Detection output of running the detector on some random images with known ground truth
- Green Bounding Box represents the GROUND TRUTH and Red Bounding Box represents the DETECTOR Output

- The results on live webcame

- Human location in ROBOT REFERENCE FRAME




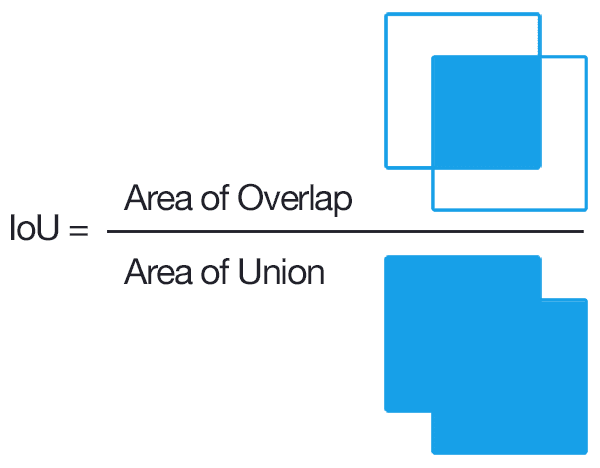
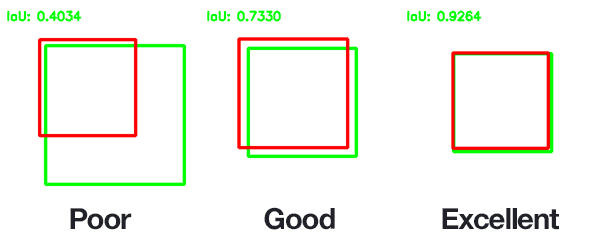
- We used Intersection over Union as a metric for our detector as it is a better metric than measuring error between centroids
- IOU takes into consideration the height and width of the predicted bounding box whereas centroid shift only takes into consideration the location of centroid of the bounding box which is an ambigous metric as displayed below

- Centroid of the predicted bounding box highlighted in Red color is same for both images and also coincides with the centroid of the Ground Truth bounding box highlighted in Green Color but it is quite obvious that both the predicted bounding boxes are quite inaccurate

{kind=link}
- We will be following AIP (Agile Iterative Process) and implement the software using TDD (Test Driven Development)
- Quality shall be ensured by unit testing and cppcheck, adhering to Google C++ style guide
- Operating System (Ubuntu 18.04 LTS)
- Programming Language (Modern C++)
- Build System (CMake >= 3.2.1)
- External Library (Opencv >= 4.5.0)
- Pre-trained model (yoloV4-tiny)
Following the Agile Iterative Process for Development, we switch roles of driver and navigator. Product backlog, iteration backlog and worklog can be found here and Sprint planning with review notes can be found here
To install doxygen run the following command:
sudo apt-get install doxygen
Now from the cloned directory run:
cd docs
doxygen Doxyfile
Generated doxygen files are in html format and you can find them in ./docs folder. With the following command
cd docs
cd html
google-chrome index.html
Run cppcheck: Results are stored in ./results/cppcheck.txt
sh run_cppcheck.sh
Run cpplint: Results are stored in ./results/cpplinttxt
sh run_cpplint.sh