- Provision an Azure OpenAI resource in your Azure subscription.
- Create an Azure OpenAI Service resource in the Azure portal.
- Create an Azure OpenAI Service resource in Azure CLI.
- az cognitiveservices account create -n MyOpenAIResource -g OAIResourceGroup -l eastus --kind OpenAI --sku s0 --subscription subscriptionID
Use Azure AI Studio - https://ai.azure.com/
- Azure AI Studio provides access to model management, deployment, experimentation, customization, and learning resources.
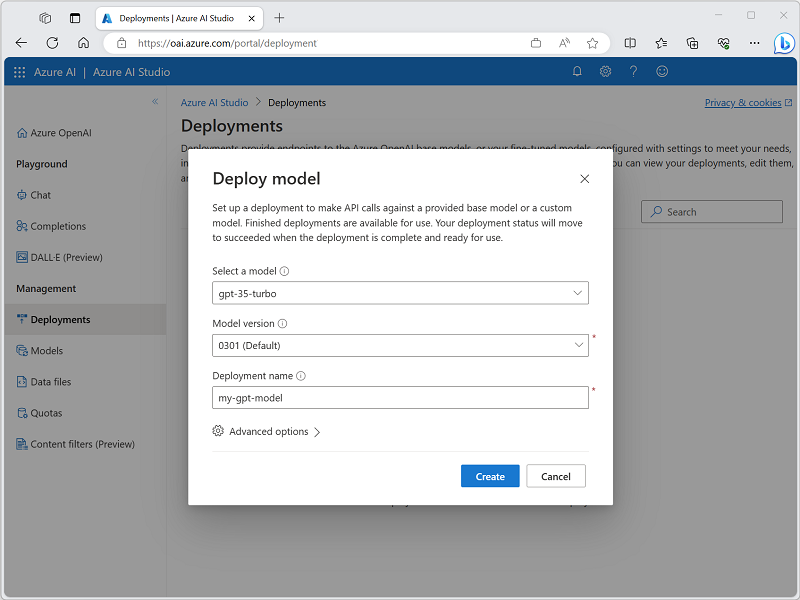
- Select your resource, deploy your first model through the Deployments page
-
* MS provides base models and the option to create customized base models. This module covers the currently available base models.
1. GPT-4 models - Latest generation of generative pretrained (GPT) models that can generate NL and code completions based on NL prompts.
1. GPT 3.5 models - Generate NL and code completions based on NL prompts.
1. GPT-35-turbo models - Optimized for chat-based interactions and work well in most generative AI scenarios.
1. Embeddings models - Convert text into numeric vectors, and are useful in language analytics scenarios such as comparing text sources for similarities.
1. DALL-E models - Used to generate images based on NL prompts.
* Pricing Options - https://azure.microsoft.com/en-us/pricing/details/cognitive-services/openai-service/
* Deploy a model to chat with or make API calls to receive responses to prompts.
* Depoy using Azure AI Studio
* <img src="https://learn.microsoft.com/en-us/training/wwl-data-ai/get-started-openai/media/studio-deploy-model.png" width=500 height=500>
* Deploy using Azure CLI
1. az cognitiveservices account deployment create -g OAIResourceGroup -n MyOpenAIResource --deployment-name MyModel --model-name gpt-35-turbo --model-version "0301" --model-format OpenAI --sku-name "Standard" --sku-capacity 1
* Deploy using the REST API - https://learn.microsoft.com/en-us/azure/ai-services/openai/
- Test, A prompt is the text portion of a request that is sent to the deployed model's completions endpoint.
- Responses are referred to as completions, which can come in form of text, code, or other formats.
- Prompt types, Prompts can be grouped into types of requests based on task.
| Task type | Prompt example | Completion example |
|---|---|---|
| Classifying content | Tweet: I enjoyed the trip. Sentiment: | Positive |
| Generating new content | List ways of traveling | 1. Bike 2. Car ... |
| Holding a conversation | A friendly AI assistant | See examples |
| Transformation (translation and symbol conversion) English: Hello French: | bonjour | |
| Summarizing content | Provide a summary of the content {text} | The content shares methods of machine learning. |
| Picking up where you left off | One way to grow tomatoes | is to plant seeds. |
| Giving factual responses | How many moons does Earth have? | One |
- Playgrounds are useful interfaces in Azure AI Studio that you can use to experiment with your deployed models without needing to develop your own client application.
- Azure AI Studio offers multiple playgrounds with different parameter tuning options.
- Completions playground - Allows you to make calls to your deployed models through a text-in, text-out interface and to adjust parameters. Completions Playground parameters
- Temperature: Controls randomness.
- Lowering the temperature means that the model produces more repetitive and deterministic responses.
- Increasing the temperature results in more unexpected or creative responses. Try adjusting temperature or Top P but not both.
- Max length (tokens): Set a limit on the number of tokens per model response.
- The API supports a maximum of 4000 tokens shared between the prompt (including system message, examples, message history, and user query) and the model's response.
- One token is roughly four characters for typical English text.
- Stop sequences: Make responses stop at a desired point, such as the end of a sentence or list.
- Specify up to four sequences where the model will stop generating further tokens in a response. The returned text won't contain the stop sequence.
- Top probabilities (Top P): Similar to temperature, this controls randomness but uses a different method.
- Lowering Top P narrows the model’s token selection to likelier tokens.
- Increasing Top P lets the model choose from tokens with both high and low likelihood.
- Try adjusting temperature or Top P but not both.
- Frequency penalty: Reduce the chance of repeating a token proportionally based on how often it has appeared in the text so far. This decreases the likelihood of repeating the exact same text in a response.
- Presence penalty: Reduce the chance of repeating any token that has appeared in the text at all so far. This increases the likelihood of introducing new topics in a response.
- Pre-response text: Insert text after the user’s input and before the model’s response. This can help prepare the model for a response.
- Post-response text: Insert text after the model’s generated response to encourage further user input, as when modeling a conversation.
- Temperature: Controls randomness.
- Chat playground - Based on a conversation-in, message-out interface. You can initialize the session with a system message to set up the chat context.
- Add few-shot examples - providing a few of examples to help the model learn what it needs to do.
- Zero-shot - providing no examples.
- In the Assistant setup, you can provide few-shot examples of what the user input may be, and what the assistant response should be. The assistant tries to mimic the responses you include here in tone, rules, and format you've defined in your system message.
-
- Chat playground parameters
- Max response: Set a limit on the number of tokens (max 4000 tokens support) per model response.
- Past messages included: Select the number of past messages to include in each new API request. Including past messages helps give the model context for new user queries. Setting this number to 10 will include five user queries and five system responses.
- Completions playground - Allows you to make calls to your deployed models through a text-in, text-out interface and to adjust parameters. Completions Playground parameters

- What Azure OpenAI base model can you deploy to access the capabilities of ChatGPT?
- text-davinci-003
- gpt-35-turbo - Correct. Only the gpt-3.5-turbo and later models can be used to access the chat capabilities.
- text-embedding-ada-002 (Version 2)
- Which parameter could you adjust to change the randomness or creativeness of the completions returned?
- Temperature - Correct. The temperature parameter can be adjusted to change the randomness or creativeness of the completions returned.
- Frequency penalty
- Stop sequence
- Which Azure AI Studio playground is able to support conversation-in, message-out scenarios?
- Images
- Chat - Correct. The Chat playground is able to support conversation-in, message-out scenarios.
- Bot
Lab - https://microsoftlearning.github.io/mslearn-openai/Instructions/Exercises/01-get-started-azure-openai.html
- Provision an Azure OpenAI resource. Create an Azure OpenAI resource: Pricing tier: Standard S0
- Deploy a model
- Azure portal -> Azure OpenAI resource -> Overview page -> select the button to go to AI Studio. (scroll down)
- Azure AI Studio -> Deployments page and view your existing model deployments -> if not, create a new deployment of the gpt-35-turbo-16k -> Deployment type: Standard
- Use the Chat playground
- Configuration - used to select your deployment, define system message, and set parameters for interacting with your deployment.
- Chat session - used to submit chat messages and view responses.
- Under Deployments, ensure that your gpt-35-turbo-16k model deployment is selected.
- Review the default System message, which should be You are an AI assistant that helps people find information. The system message is included in prompts submitted to the model, and provides context for the model’s responses; setting expectations about how an AI agent based on the model should interact with the user.
- Experiment with system messages, prompts, and few-shot examples
1.select the Prompt samples, and use the Marketing Writing Assistant prompt template.
- Review the new system message, which describes how an AI agent should use the model to respond.
- Experiment with parameters. Configuration (Parameters tab) panel -> set the following parameter values: Max response: 1000, Temperature: 1
- Deploy your model to a web app - Pricing plan: Free (F1) - If this is not available, select Basic (B1). Enable chat history in the web app: Unselected