为何自研路由组件? 随着业务体量的增加,原先的库表存储已经不能支撑海量的并发请求。因此,可能需要考虑分库分表。 无论是业务之初就考虑分库分表,还是项目中期进行分库分表迁移,考虑自研数据库路由组件的出发点都是:** 现有的技术方案无法实现(不适合、不方便)个性化的业务需求,并且自研组件小而精,易于迭代维护,后续也可加入新的功能(例如事务支持)** 分库、分表是两回事,可能只分库不分表,可能分表不分库,也可能分库分表
| 分库分表前 | 分库分表后 | |
|---|---|---|
| 并发支撑情况 | MySQL 单机部署,扛不住高并发 | MySQL 从单机到多机,能承受的并发增加了多倍 |
| 磁盘使用情况 | MySQL 单机磁盘容量几乎撑满 | 拆分为多个库,数据库服务器磁盘使用率大大降低 |
| SQL 执行性能 | 单表数据量太大,SQL 越跑越慢 | 单表数据量减少,SQL 执行效率明显提升 |


现有的分库分表组件主要有如下两种:
在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。 提供类似功能的中间件有 MySQL Router(官方)、Atlas(基于 MySQL Proxy)、MaxScale、MyCat。
基于组件的则直接基于独立的 jar 包就可以进行开发,不用部署,运维成本低,不需要代理层的二次转发请求,性能很高**。**比较经典的就是 Sharding-JDBC

- 实现层面:组件需要知道数据需要从哪个具体的数据库的子表中获取,并且对用户透明
- 数据源切换:如何在组件中实现_动态数据源切换_
- 路由算法:如何实现比较均匀的_路由散列算法_
- SQL 改写:如何拦截并修改 SQL
- 引入数据分片带来的问题:主要考虑跨表连接查询、跨库事务问题
- 跨表连接查询:通常两种方案:(1)解决跨表查询;(2)规避跨表连接,采用第三方中间件汇总查询
- 跨库事务:这块也是痛点,通常有两种做法:(1)分布式事务;(2)规避分布式事务问题,采用最终一致性方案
Tips: 关于以上跨表连接查询、跨库事务具体解决方案,需要根据业务场景、对于数据一致性的要求、综合性能等综合考虑。 例如:
- 秒杀场景下,关于库存的处理,就不太适合使用繁重的分布式事务,采用最终一致性方案(MQ+JOB兜底)比较合适;反之,对于金融等场景,考虑分布式事务比较合适
- 对于 B 端系统的跨表查询场景,业务访问量也不会很大,考虑适配跨表连接方案代价就比较高了,相反采用 ES 汇总查询,相对来说容易接受一点
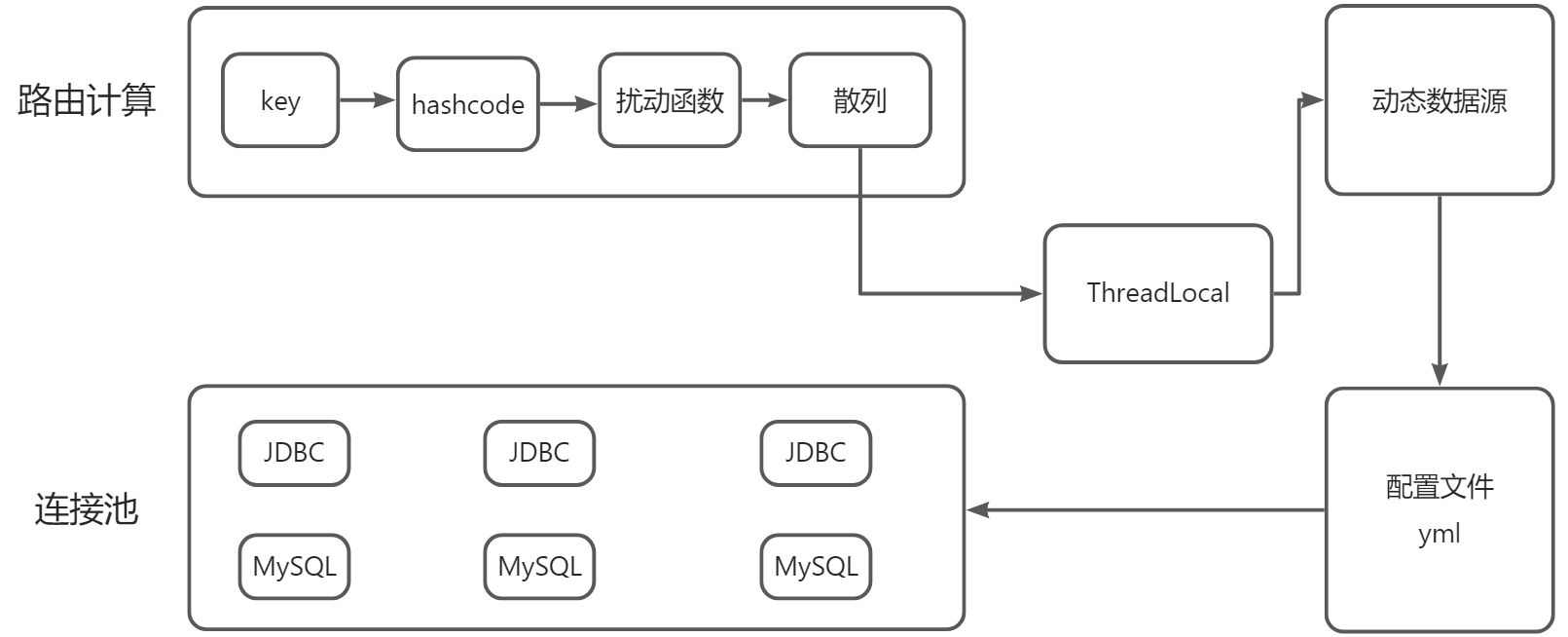
- AOP 切面拦截:拦截需要使用DB 路由的方法,这里采用自定义注解
- 数据库连接池配置:分库分表需要按需配置数据库连接源,在这些连接池的集合中进行动态数据源切换
AbstractRoutingDataSource:是用于动态数据源切换的 Spring 服务类,提供了数据源切换的抽象方法determineCurrentLookupKey- 路由哈希算法设计:在路由设计时,需要根据分库分表字段进行路由计算,让数据均匀地分布至各个库表之中。这里参考 HashMap 的 扰动函数设计
- MyBatis 拦截器:实现 sql 动态拦截和修改

├─src
│ ├─main
│ │ ├─java
│ │ │ └─io
│ │ │ └─github
│ │ │ └─mokeeqian
│ │ │ └─router
│ │ │ ├─annotation
│ │ │ ├─aop
│ │ │ ├─config
│ │ │ ├─context
│ │ │ ├─dynamic
│ │ │ ├─model
│ │ │ ├─strategy
│ │ │ │ └─impl
│ │ │ └─util
│ │ └─resources
│ │ └─META-INF
│ └─test
│ └─java
路由注解 为切面提供切点,同时获取被注解的方法入参属性中的路由字段
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD, ElementType.TYPE})
public @interface DBRouter {
/**
* 路由字段
* @return
*/
String key() default "";
}- @Retention:告诉编译程序如何处理,也可理解为注解类的生命周期。
- @Target:该注解的作用点,主要有:TYPE(类、接口)、METHOD(方法)、PACKAGE、FIELD、PARAMETER等。这里我们选择作用在方法上。
路由策略注解
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE, ElementType.METHOD})
public @interface DBRouterStrategy {
/**
* 是否分表
* @return
*/
boolean splitTable() default false;
}继承抽象类 AbstractRoutingDataSource,实现其 determineCurrentLookupKey 方法,从 DBContextHolder中获取 DB key,用以实现动态切换数据源
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
// db01, db02, ...
return "db" + RouterContext.getDatabaseKey();
}
}AbstractRoutingDataSource的getConnection() ⽅法根据查找 lookup key 键对不同⽬标数据源的调⽤, 通常是通过(但不⼀定)某些线程绑定的事物上下⽂来实现 AbstractRoutingDataSource的多数据源动态 切换的核⼼逻辑是:在程序运⾏时,把数据源数据源通过AbstractRoutingDataSource 动态织⼊到程序 中,灵活的进⾏数据源切换 基于AbstractRoutingDataSource的多数据源动态切换,可以实现读写分离,这么做缺点也很明显,⽆法 动态的增加数据源
对于较复杂的数据源配置,一般使用 org.springframework.context.EnvironmentAware来实现:
EnvironmentAware#setEnvironment:读取 yml 配置文件中的自定义分库分表配置
public void setEnvironment(Environment environment){
String prefix="mini-db-router.jdbc.datasource.";
databaseCount=Integer.parseInt(Objects.requireNonNull(environment.getProperty(prefix+"dbCount")));
tableCount=Integer.parseInt(Objects.requireNonNull(environment.getProperty(prefix+"tbCount")));
routerKey=environment.getProperty(prefix+"routerKey");
// 分库列表 db01,db02
String dataSources=environment.getProperty(prefix+"list");
assert dataSources!=null;
for(String dbInfo:dataSources.split(",")){
Map<String, Object> dataSourceProps=PropertyUtil.handle(environment,prefix+dbInfo,Map.class);
dataSourceMap.put(dbInfo,dataSourceProps);
}
// 默认数据源
String defaultData=environment.getProperty(prefix+"default");
defaultDataSourceConfig=PropertyUtil.handle(environment,prefix+defaultData,Map.class);
}router:
jdbc:
datasource:
# 从这里开始就是数据源的配置了
dbCount: 2
tbCount: 4
default: db00
routerKey: uId # 路由字段
list: db01,db02 # 分库
db00:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/lottery?useUnicode=true
username: root
password: xxx
db01:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/lottery_01?useUnicode=true
username: root
password: xxx
db02:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/lottery_02?useUnicode=true
username: root
password: xxx创建数据源:DynamicDataSource#setTargetDataSources,DynamicDataSource#setDefaultTargetDataSource
@Bean
public DataSource dataSource(){
Map<Object, Object> targetDataSources=new HashMap<>();
for(String dbInfo:dataSourceMap.keySet()){
Map<String, Object> objMap=dataSourceMap.get(dbInfo);
targetDataSources.put(dbInfo,new DriverManagerDataSource(
objMap.get("url").toString(),objMap.get("username").toString(),objMap.get("password").toString())
);
}
// 设置数据源
DynamicDataSource dynamicDataSource=new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(
new DriverManagerDataSource(
defaultDataSourceConfig.get("url").toString(),
defaultDataSourceConfig.get("username").toString(),
defaultDataSourceConfig.get("password").toString()
)
);
return dynamicDataSource;
}使用 ThreadLocal 保存分库、分表的路由结果,借鉴 SecurityContextHolder
public class RouterContext {
private static final ThreadLocal<String> DATABASE_KEY = new ThreadLocal<>();
private static final ThreadLocal<String> TABLE_KEY = new ThreadLocal<>();
public static String getDatabaseKey() {
return DATABASE_KEY.get();
}
public static void setDatabaseKey(String databaseKey) {
DATABASE_KEY.set(databaseKey);
}
public static String getTableKey() {
return TABLE_KEY.get();
}
public static void setTableKey(String tableKey) {
TABLE_KEY.set(tableKey);
}
public static void clearDatabaseKey() {
DATABASE_KEY.remove();
}
public static void clearTableKey() {
TABLE_KEY.remove();
}
}这里采用接口 IDBRouterStrategy ,后续可以实现该接口,进行个性化的路由策略配置

@Override
public void doRouter(String databaseKeyFieldValue){
// 总的库表数目
int size=routerConfig.getDatabaseCount()*routerConfig.getTableCount();
// 扰动函数;在 JDK 的 HashMap 中,对于一个元素的存放,需要进行哈希散列。而为了让散列更加均匀,所以添加了扰动函数。
int idx=(size-1)&(databaseKeyFieldValue.hashCode()^(databaseKeyFieldValue.hashCode()>>>16));
// 库表索引;相当于是把一个长条的桶,切割成段,对应分库分表中的库编号和表编号
int dbIdx=idx/routerConfig.getTableCount()+1;
int tbIdx=idx-routerConfig.getTableCount()*(dbIdx-1);
// 设置路由到 context
RouterContext.setDatabaseKey(String.format("%02d",dbIdx));
RouterContext.setTableKey(String.format("%03d",tbIdx));
}基于以上,分库功能已经实现,但是,如何分表?即将逻辑 SQL 转化为 **物理 SQL,**例如: 逻辑SQL:SELECT * FROM tb_user WHERE id = 123;
物理SQL:SELECT * FROM tb_user_01 WHERE id = 123;
一种思路是:使用 MyBatis 的 Interceptor 进行 SQL 拦截,然后动态修改 SQL
mybatis:自定义实现拦截器插件Interceptor
-
@Intercepts注解:拦截器 可以被拦截的四种类型:
- Executor:拦截执行器的方法
- ParameterHandler:拦截参数的处理
- ResultHandler:拦截结果集的处理
- StatementHandler:拦截Sql语法构建的处理
-
@Signature注解:拦截点,指定拦截哪个对象里面的哪个方法 其参数如下:
- type:要被拦截的类型(上述四种之一)
- method:在类型基础上,指定被拦截的方法
- args:在方法基础上,指定方法入参参数(Java里可能存在重载,故要注意参数顺序和类型)
-
类型&方法一览
拦截类型 拦截方法 Executor update、query、flushStatements、commit、rollback、getTransaction、close、isClosed ParameterHandler getParameterObject、setParameters ResultHandler handleResultSets、handleOutputParameters StatementHandler prepare、parameterize、batch、update、query
StatementHandler 的具体方法:
- prepare: ⽤于创建⼀个具体的 Statement 对象的实现类或者是 Statement 对象
- parametersize: ⽤于初始化 Statement 对象以及对sql的占位符进⾏赋值
- update: ⽤于通知 Statement 对象将 insert、update、delete 操作推送到数据库
- query: ⽤于通知 Statement 对象将 select 操作推送数据库并返回对应的查询结果
我们主要使用 StatementHandler 的 prepare 方法,拦截 sql 语句
@Intercepts(
@Signature(type = StatementHandler.class, method = "prepare", args = {Connection.class, Integer.class})
)这里的 Interceptor#intercept 方法就是我们要实现的方法,其中,invocation 就是被拦截的对象(StatementHandler#prepare方法)
/**
* @author Clinton Begin
*/
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
default Object plugin(Object target) {
return Plugin.wrap(target, this);
}
default void setProperties(Properties properties) {
// NOP
}
}如何获取 MyBatis 中的 SQL 语句?
基于 StatementHandler,然后 获取其 BoundSql
// 获取 StatementHandler
StatementHandler statementHandler=(StatementHandler)invocation.getTarget();
MetaObject metaObject=MetaObject.forObject(statementHandler,SystemMetaObject.DEFAULT_OBJECT_FACTORY,
SystemMetaObject.DEFAULT_OBJECT_WRAPPER_FACTORY,new DefaultReflectorFactory());
MappedStatement mappedStatement=(MappedStatement)metaObject.getValue("delegate.mappedStatement");
// 获取 MyBatis 原始 SQL
BoundSql boundSql=statementHandler.getBoundSql();
String originalSql=boundSql.getSql();如何识别 SQL 中的表名称? 使用正则表达式匹配:from,into,update 这三个关键字,其之后就是表名称
private Pattern pattern=Pattern.compile("(from|into|update)[\\s]{1,}(\\w{1,})",Pattern.CASE_INSENSITIVE);识别之后如何替换?
使用反射,直接修改 BoundSql#sql 字段
// 通过反射修改 sql 语句
// getDeclaredField:可以获取所有已声明字段(无视访问限定符); getField:只能获取public 字段
Field field=boundSql.getClass().getDeclaredField("sql");
field.setAccessible(true);
field.set(boundSql,replacedSql);
field.setAccessible(false);- 使用反射可以访问 Java 类的私有成员、私有方法。在框架开发中,用处十分广泛
目前为止,底层逻辑已经全部实现,现在只需要使用AOP对调用方法进行拦截处理即可 定义切点 这里直接拦截先前定义的自定义注解,也可以是使用表达式匹配
/**
* 切点,拦截 @DBRouter
*/
@Pointcut("@annotation(io.github.mokeeqian.router.annotation.DBRouter)")
public void pointCut(){}定义切面拦截具体逻辑
@Around("pointCut() && @annotation(dbRouter)")
public Object aroundAnnotationDBRouter(ProceedingJoinPoint proceedingJoinPoint,DBRouter dbRouter)throws Throwable{
// 从 @DBRouter 注解中拿到路由 Key
String dbKey=dbRouter.key();
if(StringUtils.isBlank(dbKey)||StringUtils.isBlank(routerConfig.getRouterKey())){
throw new RuntimeException("annotation @DBRouter key is null");
}
// 如果 @DBRouter key 属性未指定,则默认使用 application.yml 中的 routerKey
if(StringUtils.isBlank(dbKey)){
dbKey=routerConfig.getRouterKey();
}
// 获取路由字段的属性值
String dbKeyFieldValue=parseRouterKeyFieldValue(dbKey,proceedingJoinPoint.getArgs());
// 路由下发
routerStrategy.doRouter(dbKeyFieldValue);
// 放行
try{
return proceedingJoinPoint.proceed();
}finally{
// 清空路由
routerStrategy.clear();
}
}- 几种切面环绕逻辑:
- @Before:前置通知,在方法执行之前执行
- @After:后置通知,在方法执行之后执行(即使出现异常,后置通知也会执行)
- @Around:环绕通知,围绕着方法执行(可以实现其他四种通知)
- @AfterReturning:返回通知,在方法返回结果之后执行
- @AfterThrowing:异常通知,在方法抛出异常之后
- AspectJ 注解的执行顺序:
@Around 都会出现两次:@Before、@AfterReturning、@AfterReturning、@After 这四个都会在两次@Around 执行之间被执行
- 无异常时:@Aspect、@Pointcut、@Around、@Before、@AfterReturning、@After、@Around
- 有异常时:@Aspect、@Pointcut、@Around、@Before、@AfterThrowing、@After、@Around
最后的最后,将项目封装成 SpringBoot 起步依赖,编写配置类,然后利用自动装配机制。
package io.github.mokeeqian.router.config;
import io.github.mokeeqian.router.aop.RouterAspect;
import io.github.mokeeqian.router.dynamic.DynamicDataSource;
import io.github.mokeeqian.router.dynamic.DynamicMybatisPlugin;
import io.github.mokeeqian.router.model.RouterConfig;
import io.github.mokeeqian.router.strategy.IRouterStrategy;
import io.github.mokeeqian.router.strategy.impl.RouterStrategyHashCode;
import io.github.mokeeqian.router.util.PropertyUtil;
import org.apache.ibatis.plugin.Interceptor;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.EnvironmentAware;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.env.Environment;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.jdbc.datasource.DriverManagerDataSource;
import org.springframework.transaction.support.TransactionTemplate;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
/**
* @description: 数据源配置
* @author:mokeeqian
* @date: 2023/8/27
* @Copyright: mokeeqian@gmail.com
*/
@Configuration
public class DataSourceAutoConfig implements EnvironmentAware {
/**
* 数据源
* db -> Config
*/
private Map<String, Map<String, Object>> dataSourceMap = new HashMap<>();
/**
* 默认数据源配置
*/
private Map<String, Object> defaultDataSourceConfig;
/**
* database 数目
*/
private int databaseCount;
/**
* table 数目
*/
private int tableCount;
/**
* 路由 key
*/
private String routerKey;
@Bean
public RouterConfig routerConfig() {
return new RouterConfig(this.databaseCount, this.tableCount, this.routerKey);
}
@Bean
public IRouterStrategy routerStrategy(RouterConfig routerConfig) {
return new RouterStrategyHashCode(routerConfig);
}
@Bean
public Interceptor plugin() {
return new DynamicMybatisPlugin();
}
@Bean(name = "routerAspect")
@ConditionalOnMissingBean
public RouterAspect routerAspect(RouterConfig routerConfig, IRouterStrategy routerStrategy) {
return new RouterAspect(routerConfig, routerStrategy);
}
/**
* 这个数据源就会被 MyBatis SpringBoot Starter 中 SqlSessionFactory sqlSessionFactory(DataSource dataSource) 注入使用
*
* @return
*/
@Bean
public DataSource dataSource() {
Map<Object, Object> targetDataSources = new HashMap<>();
for (String dbInfo : dataSourceMap.keySet()) {
Map<String, Object> objMap = dataSourceMap.get(dbInfo);
targetDataSources.put(dbInfo, new DriverManagerDataSource(
objMap.get("url").toString(), objMap.get("username").toString(), objMap.get("password").toString())
);
}
// 设置数据源
DynamicDataSource dynamicDataSource = new DynamicDataSource();
dynamicDataSource.setTargetDataSources(targetDataSources);
dynamicDataSource.setDefaultTargetDataSource(
new DriverManagerDataSource(
defaultDataSourceConfig.get("url").toString(),
defaultDataSourceConfig.get("username").toString(),
defaultDataSourceConfig.get("password").toString()
)
);
return dynamicDataSource;
}
@Bean
public TransactionTemplate transactionTemplate(DataSource dataSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager();
dataSourceTransactionManager.setDataSource(dataSource);
TransactionTemplate transactionTemplate = new TransactionTemplate();
transactionTemplate.setTransactionManager(dataSourceTransactionManager);
transactionTemplate.setPropagationBehaviorName("PROPAGATION_REQUIRED");
return transactionTemplate;
}
/**
* 读取 yml 数据源配置
*
* @param environment
*/
@Override
public void setEnvironment(Environment environment) {
String prefix = "mini-db-router.jdbc.datasource.";
databaseCount = Integer.parseInt(Objects.requireNonNull(environment.getProperty(prefix + "dbCount")));
tableCount = Integer.parseInt(Objects.requireNonNull(environment.getProperty(prefix + "tbCount")));
routerKey = environment.getProperty(prefix + "routerKey");
// 分库列表 db01,db02
String dataSources = environment.getProperty(prefix + "list");
assert dataSources != null;
for (String dbInfo : dataSources.split(",")) {
Map<String, Object> dataSourceProps = PropertyUtil.handle(environment, prefix + dbInfo, Map.class);
dataSourceMap.put(dbInfo, dataSourceProps);
}
// 默认数据源
String defaultData = environment.getProperty(prefix + "default");
defaultDataSourceConfig = PropertyUtil.handle(environment, prefix + defaultData, Map.class);
}
}随后,需要编写 resources/META_INF/spring.factories 文件,配置数据源配置类
org.springframework.boot.autoconfigure.EnableAutoConfiguration=io.github.mokeeqian.router.config.DataSourceAutoConfig最后,将项目打包到 maven 仓库,即可使用啦
基于原先的单库单表,现在如何做迁移?
最简单的就是直接停机迁移,停止一切写入。然后将旧库数据迁移至新库。

如果线上业务不能停机怎么办?
- 我们对老库的更新操作(增删改),同时也要写入新库(双写)。如果操作的数据不存在于新库的话,需要插入到新库中。 这样就能保证,咱们新库里的数据是最新的。
- 在迁移过程,双写只会让被更新操作过的老库中的数据同步到新库,我们_还需要自己写脚本将老库中的数据和新库的数据做比对_。如果新库中没有,那咱们就把数据插入到新库。如果新库有,旧库没有,就把新库对应的数据删除(冗余数据清理)。
- 重复上一步的操作,直到老库和新库的数据一致为止
这块其实可以借助 Canal 等中间件(binlog主从同步原理)来实现
