Home
mTCP is a high-performance user-level TCP stack for multicore systems. Scaling the performance of short TCP connections is fundamentally challenging due to inefficiencies in the kernel. mTCP addresses these inefficiencies from the ground up - from packet I/O and TCP connection management all the way to the application interface.

Besides adopting well-known techniques, our mTCP stack (1) translates expensive system calls to shared memory access between two threads within the same CPU core, (2) allows efficient flow-level event aggregation, and (3) performs batch processing of RX/TX packets for high I/O efficiency. mTCP on an 8-core machine improves the performance of small message transactions by a factor 25 (compared with the latest Linux TCP stack (kernel version 3.10.12)) and 3 (compared with with the best-performing research system). It also improves the performance of various popular applications by 33% (SSLShader) to 320% (lighttpd) compared with those on the Linux stack.
Many high-performance network applications spend a significant portion of CPU cycles for TCP processing in the kernel. (e.g., ~80% inside kernel for lighttpd) Even worse, these CPU cycles are not utilized effectively; according to our measurements, Linux spends more than 4x the cycles than mTCP in handling the same number of TCP transactions.
Then, can we design a user-level TCP stack that incorporates all existing optimizations into a single system? Can we bring the performance of existing packet I/O libraries to the TCP stack? To answer these questions, we build a TCP stack in the user level. User-level TCP is attractive for many reasons.
- Easily depart from the kernel's complexity
- Directly benefit from the optimizations in the high performance packet I/O libraries
- Naturally aggregate flow-level events by packet-level I/O batching
- Easily preserve the existing application programming interface
Several packet I/O systems allow high-speed packet I/O (~100M packets/s) from a user-level application. However, they are not suitable for implementing a transport layer because (i) they waste CPU cycles by polling NICs and (ii) they do not allow multiplexing between RX and TX. To address these challenges, we extend PacketShader I/O engine (PSIO) for efficient event-driven packet I/O. The new event-driven interface, ps_select(), works similarly to select() except that it operates on TX/RX queues of interested NIC ports. For example, mTCP specifies interested NIC interfaces for RX and/or TX events with a timeout in microseconds, and ps_select() returns immediately if any events of interests are available.
The use of PSIO brings the opportunity to amortize the overhead of various system calls and context switches throughout the system, in addition to eliminating the per-packet memory allocation and DMA overhead. For more detail about the PSIO, please refer to the PacketShader project page.
mTCP is implemented as a separate-TCP-thread-per-application-thread model.Since coupling TCP jobs with the application thread could break time-based operations such as handling TCP retransmission timeouts, we choose to create a separate TCP thread for each application thread affinitized to the same CPU core. Figure 2 shows how mTCP interacts with the application thread. Applications can communicate with the mTCP threads via library functions that grant safe sharing of the internal TCP data.

While designing the TCP stack, we consider following primitives for performance scalability and efficient event delivery.
- Thread mapping and flow-level core affinity
- Multicore and cache-friendly data structures
- Batched event handling
- Optimizations for short-lived connections
Our TCP implementation follows the original TCP specification, RFC793. It supports basic TCP features such as connection management, reliable data transfer, flow control, and congestion control. mTCP also implements popular options such as timestamp, MSS, and window scaling. For congestion control, mTCP implements NewReno.
Our programming interface preserves as much as possible the most commonly-used semantics for easy migration of applications. We introduce our user-level socket API and an event system as below.
User-level socket API
mTCP provides a BSD-like socket interface; for each BSD socket function, we have a corresponding function call (e.g., accept() -> mtcp_accept()). In addition, we provide some of the fcntl() or ioctl() functionalities that are frequently used with sockets (e.g., setting socket as nonblocking, getting/setting the socket buffer size) and event systems as below.
User-level event system
As shown in Figure 3, we provide an epoll-like event system. Applications can fetch the events through mtcp_epoll_wait() and register events through mtcp_epoll_ctl(), which correspond to epoll_wait() and epoll_ctl() in Linux.
mctx_t mctx = mtcp_create_context();
int ep_id = mtcp_epoll_create(mctx, N);
mtcp_listen(mctx, listen_id, 4096);
while (1) {
n = mtcp_epoll_wait(mctx, ep_id, events, N, -1);
for (i = 0; i < n; i++) {
sockid = events[i].data.sockid;
if (sockid == listen_id) {
c = mtcp_accept(mctx, listen_id, NULL);
mtcp_setsock_nonblock(mctx, c);
ev.events = EPOLLIN | EPOLLOUT);
ev.data.sockid = c;
mtcp_epoll_ctl(mctx, ep_id, EPOLL_CTL_ADD, c, &ev);
} else if (events[i].events == EPOLLIN) {
r = mtcp_read(mctx, sockid, buf, LEN);
if (r == 0)
mtcp_close(mctx, sockid);
} else if (events[i].events == EPOLLOUT) {
mtcp_write(mctx, sockid, buf, len);
}
}
}
As in Figure 2, you can program with mTCP just as you do with Linux epoll and sockets. One difference is that the mTCP functions require mctx (mTCP thread context) for all functions, managing resources independently among different threads for core-scalability.
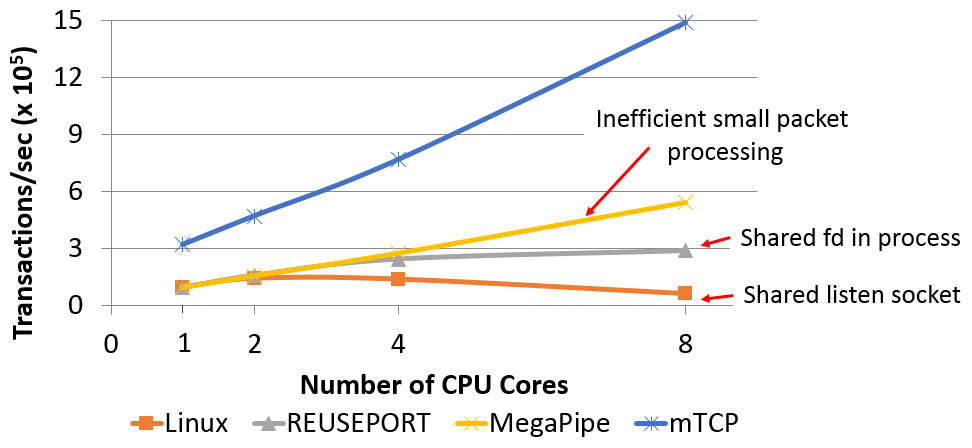
We first show mTCP's scalability with a benchmark for a server sending a short (64B) message. All servers are multi-threaded with a single listening port. Figure 3 shows the performance as a function of the number of CPU cores. While Linux shows poor scaling due to a shared accept queue, and Linux with SO_REUSEPORT scales but not linearly, mTCP scales almost linearly with the number of CPU cores. On 8 cores, mTCP shows 25x, 5x, 3x higher performance over Linux, Linux+SO_REUSEPORT, and MegaPipe, respectively.
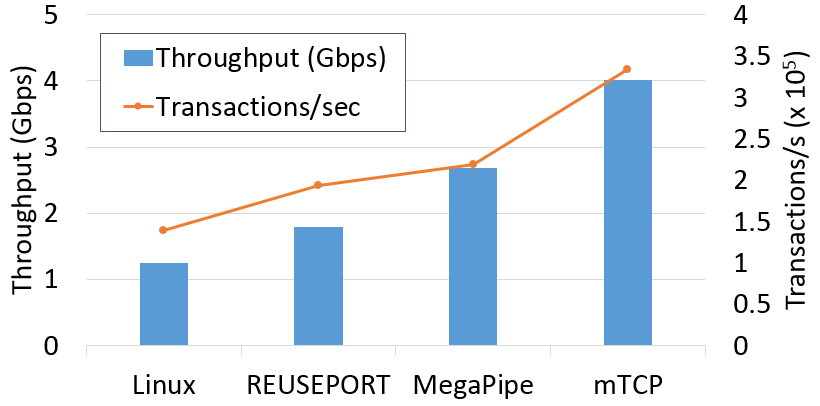
To gauge the performance of lighttpd in a realistic setting, we run a test by extracting the static file workload from SpecWeb2009 as Affinity-Accept and MegaPipe did. Figure 4 shows that mTCP improves the throughput by 3.2x, 2.2x, 1.5x over Linux, REUSEPORT, and MegaPipe, respectively.
For lighttpd, we changed only ~65 LoC to use mTCP-specific event and socket function calls. For multi-threading, a total of ~800 lines were modified out of lighttpd's ~40,000 LoC.
Experiment setup:
1 Intel Xeon E5-2690 @ 2.90 GHz (octacore)
32 GB RAM (4 memory channels)
1~2 Intel dual port 82599 10 GbE NIC
Linux 2.6.32 (for mTCP), Linux 3.1.3 (for MegaPipe), Linux 3.10.12
ixgbe-3.17.3
mTCP: A Highly Scalable User-level TCP Stack for Multicore Systems
EunYoung Jeong, Shinae Woo, Muhammad Jamshed, Haewon Jeong, Sunghwan Ihm, Dongsu Han, and KyoungSoo Park
In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI'14)
Seattle, WA, April 2014