
ExcelUtil is a Java wrapper using Apache POI to read and write Excel file in declarative fashion.
This library is also introduced as "Related Project" on Apache POI's official website.
ExcelUtil is using Apache POI version 5.2.5
<dependency>
<groupId>io.github.nambach</groupId>
<artifactId>ExcelUtil</artifactId>
<version>2.5.1</version>
</dependency>For full detail guides & example, see the Wiki page.
Here we have a simple class Book:
class Book {
private String isbn;
private String title;
private double rating;
private String author;
private String subCategory;
private Category category;
static class Category {
private long id;
private String name;
}
}The core building block to write data is DataTemplate<T>. It holds mapping rules of the DTO class you need to export Excel.
public class Main {
static final DataTemplate<Book> BOOK_TEMPLATE = DataTemplate
.fromClass(Book.class)
.includeAllFields();
public static void main(String[] args) {
InputStream stream = BOOK_TEMPLATE.writeData(books);
FileUtil.writeToDisk(".../books.xlsx", stream, true);
}
}Your DTO class should follow camelCase convention, so that the generated titles would be correct.
The next building block is Style, which is pretty much the same as what you can configure with normal Excel.
static final Style BASED_STYLE = Style
.builder()
.fontName("Calibri")
.fontSize((short) 12)
.build();
static final Style HEADER_STYLE = Style
.builder(BASED_STYLE) // it is able to accumulate previous style
.fontColorInHex("#ffffff")
.backgroundColorInHex("#191970")
.border(BorderSide.FULL)
.horizontalAlignment(HorizontalAlignment.LEFT)
.build();Since Apache POI has some limitations regarding to stylings, it is recommended to pre-define your styles as static constant for optimization and further reuse.
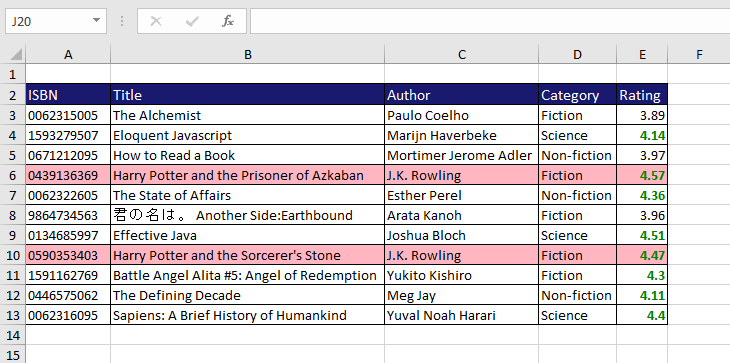
Below is an example to apply styles conditionally.
public class Main {
static final Style DATA_STYLE = ...
static final Style HIGH_RATE = ...
static final Style FAVORITE_ONE = ...
static final DataTemplate<Book> BOOK_TEMPLATE = DataTemplate
.fromClass(Book.class)
.column(c -> c.field("isbn").title("ISBN")) // customize column title
.includeFields("title", "author")
.column(c -> c.title("Category")
.transform(book -> book.getCategory().getName())) // derive new column
.column(c -> c.field("rating")
.conditionalStyle(book -> book.getRating() > 4 ? // styles with conditions
HIGH_RATE : null))
.config(cf -> cf.startAtCell("A2")
.autoSizeColumns(true)
.headerStyle(HEADER_STYLE)
.dataStyle(DATA_STYLE)
.conditionalRowStyle(book -> book.getTitle() // selective styling
.contains("Harry Potter") ? FAVORITE_ONE : null));
public static void main(String[] args) {
InputStream stream = BOOK_TEMPLATE.writeData(books);
FileUtil.writeToDisk(".../books.xlsx", stream, true);
}
}
You can merge your data rows, either based on same cell values or a particular value that you specify.
Before doing so, you might want to sort your data so that the merging process can perform correctly.
books.sort(Comparator
.comparing((Book book) -> book.getCategory().getId())
.thenComparing(comparing(Book::getSubCategory).reversed())
.thenComparing(Book::getTitle));Here is example of how to configure merge rows.
static final Style VCENTER = Style.builder().verticalAlignment(VerticalAlignment.CENTER).build();
static final DataTemplate<Book> BOOK_TEMPLATE = DataTemplate
.fromClass(Book.class)
.includeFields("title")
.column(c -> c.field("subCategory")
.style(VCENTER)
.mergeOnValue(true)) // merge cells with the same value consecutively
.column(c -> c.title("Category")
.style(VCENTER)
.transform(book -> book.getCategory().getName())
.mergeOnId(book -> book.getCategory().getId())) // merge on derived value
.config(cf -> cf.startAtCell("A2")
.autoSizeColumns(true));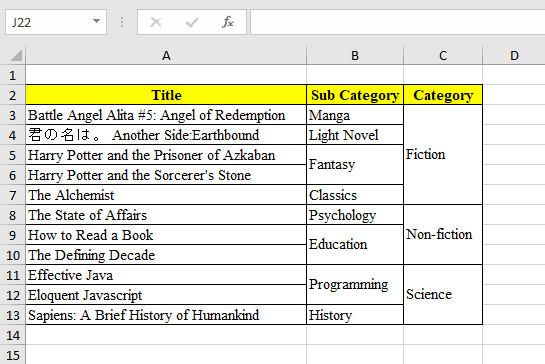
The building block to read data is ReaderConfig<T>.
ReaderConfig<Book> BOOK_READER = ReaderConfig
.fromClass(Book.class)
.titleAtRow(0)
.dataFromRow(1)
.column(0, "ibsn")
.column(1, "title")
.column(2, "author")
.column(3, "category");You can directly retrieve the config from your already defined DataTemplate<T>.
ReaderConfig<Book> BOOK_READER = BOOK_TEMPLATE.getReaderConfig();
InputStream stream = FileUtil.readFromDisk(".../book.xlsx");
List<Book> books = BOOK_READER.readSheet(stream);For more flexible process while reading data, use built-in callback handler as below.
ReaderConfig<Book> READER_CONFIG = ReaderConfig
.fromClass(Book.class)
.titleAtRow(0)
.dataFromRow(1)
.column(0, "ibsn")
.column(1, "title")
.handler(set -> set.atColumn(2)
.handle((book, cell) -> {
String value = cell.readString();
book.getCategory().setName(value);
}))
.handler(set -> set.fromColumn(3)
.handle((book, cell) -> {
String title = cell.getColumnTitle();
if (title.contains("Rating in")) {
String year = title.substring(10);
Double rating = cell.readDouble();
book.getRatingMap().put(year, rating);
}
}));Documentation can be found here.
- Minimum JDK version: 1.8
- Support Excel version:
- 97-2003 (.xls)
- 2007+ (.xlsx)
Released under Apache-2.0 License.