




Proxy List Scrapper from various websites. They gives the free proxies for temporary use.
A proxy is server that acts like a gateway or intermediary between any device and the rest of the internet. A proxy accepts and forwards connection requests, then returns data for those requests. This is the basic definition, which is quite limited, because there are dozens of unique proxy types with their own distinct configurations.
Residential proxies, Datacenter proxies, Anonymous proxies, Transparent proxies
Avoid Geo-restrictions, Protect Privacy and Increase Security, Avoid Firewalls and Bans, Automate Online Processes, Use Multiple Accounts and Gather Data
you can download the chrome extension "Free Proxy List Scrapper Chrome Extension" folder and load in the extension.
Goto Chrome Extension click here.
Web_Scrapper Module here
Web Scrapper is proxy web scraper using proxy rotating api https://scrape.do
you can check official documentation from here
## How to use Proxy List Scrapper You can clone this project from github. or use
pip install Proxy-List-Scrapper
Make sure you have installed the requests and urllib3 in python
in import add
from Proxy_List_Scrapper import Scrapper, Proxy, ScrapperException
After that simply create an object of Scrapper class as "scrapper"
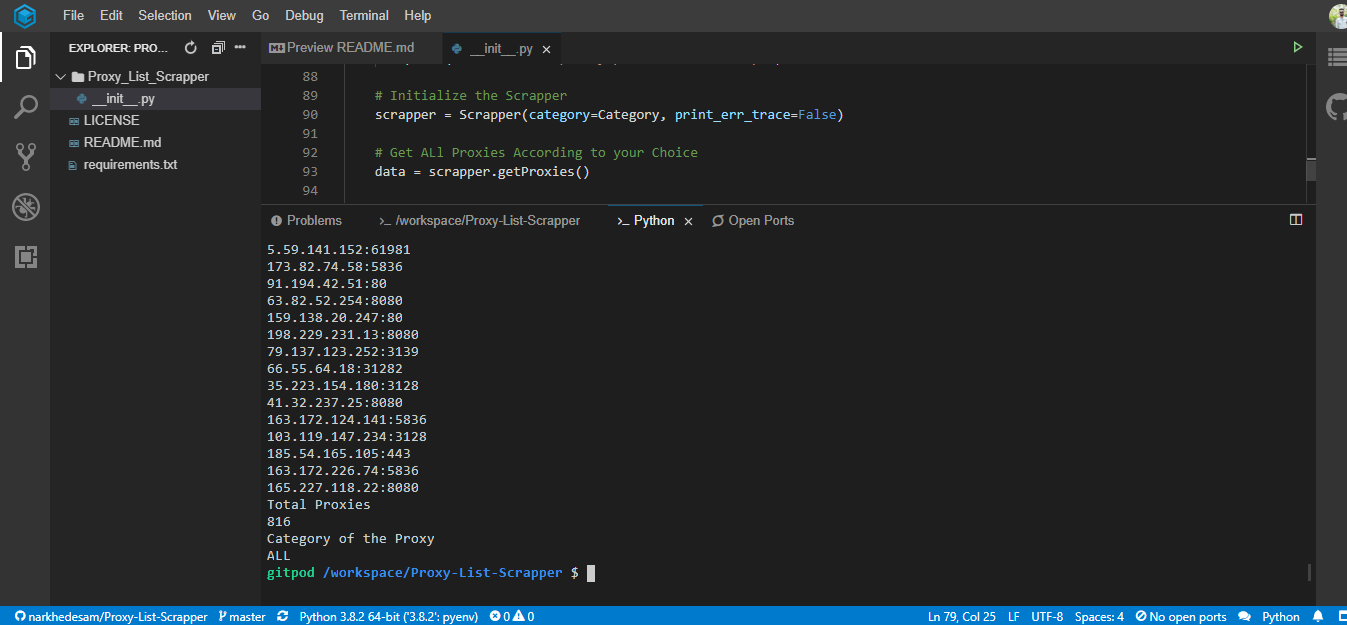
scrapper = Scrapper(category=Category, print_err_trace=False)
Here Your need to specify category defined as below:
SSL = 'https://www.sslproxies.org/',
GOOGLE = 'https://www.google-proxy.net/',
ANANY = 'https://free-proxy-list.net/anonymous-proxy.html',
UK = 'https://free-proxy-list.net/uk-proxy.html',
US = 'https://www.us-proxy.org/',
NEW = 'https://free-proxy-list.net/',
SPYS_ME = 'http://spys.me/proxy.txt',
PROXYSCRAPE = 'https://api.proxyscrape.com/?request=getproxies&proxytype=all&country=all&ssl=all&anonymity=all',
PROXYNOVA = 'https://www.proxynova.com/proxy-server-list/'
PROXYLIST_DOWNLOAD_HTTP = 'https://www.proxy-list.download/HTTP'
PROXYLIST_DOWNLOAD_HTTPS = 'https://www.proxy-list.download/HTTPS'
PROXYLIST_DOWNLOAD_SOCKS4 = 'https://www.proxy-list.download/SOCKS4'
PROXYLIST_DOWNLOAD_SOCKS5 = 'https://www.proxy-list.download/SOCKS5'
ALL = 'ALL'
These are all categories.
After you have to call a function named "getProxies"
# Get ALL Proxies According to your Choice
data = scrapper.getProxies()
the data will be returned by the above function the data is having the response data of function.
in data having proxies,len,category
- @proxies is the list of Proxy Class which has actual proxy.
- @len is the count of total proxies in @proxies.
- @category is the category of proxies defined above.
# Print These Scrapped Proxies
print("Scrapped Proxies:")
for item in data.proxies:
print('{}:{}'.format(item.ip, item.port))
# Print the size of proxies scrapped
print("Total Proxies")
print(data.len)
# Print the Category of proxy from which you scrapped
print("Category of the Proxy")
print(data.category)
Sameer Narkhede
- https://www.sslproxies.org/
- https://www.google-proxy.net/
- https://free-proxy-list.net/anonymous-proxy.html
- https://free-proxy-list.net/uk-proxy.html
- https://www.us-proxy.org/
- https://free-proxy-list.net/
- http://spys.me/proxy.txt
- https://proxyscrape.com/
- https://www.proxynova.com/proxy-server-list/
- https://www.proxy-list.download/
If this project help you reduce time to develop, you can give me a cup of coffee
