介绍如何使用CPM(Convolutional Pose Machines)实现服饰关键点定位,是对阿里云天池“FashionAI全球挑战赛——服饰关键点定位”竞赛的一次尝试。
输入是一张图片,输出是每个关键点的x、y坐标,一般会归一化到0~1区间中,所以可以理解为回归问题,但是直接对坐标值进行回归会导致较大误差,更好的做法是输出一个低分辨率的热图,使得关键点所在位置输出较高响应,而其他位置则输出较低响应。

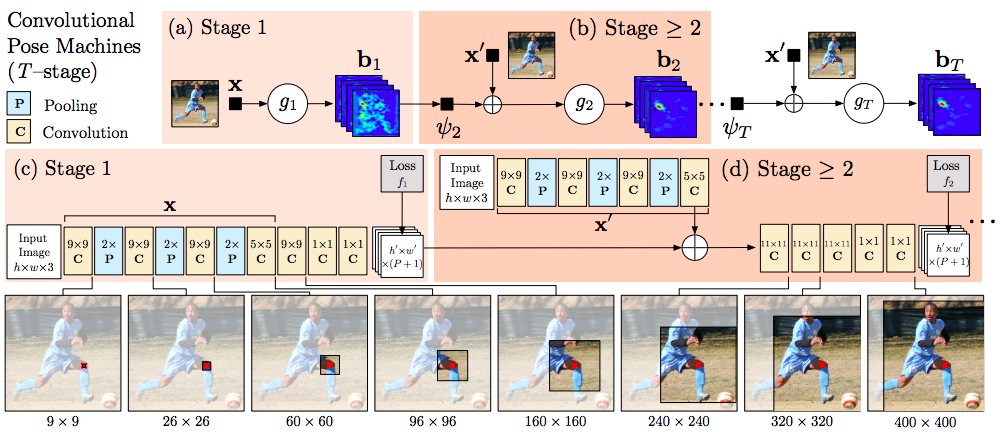
因此使用CPM(2016年的CVPR)的模型,其基本思想是使用多个级联的stage,每个stage包含多个CNN并且都输出热图,通过最小化每个stage的热图和ground truth之间的差距,从而得到越来越准确的关键点定位结果。
Github上有CPM的一个开源实现(https://github.com/timctho/convolutional-pose-machines-tensorflow)。
使用天池FashionAI全球挑战赛提供的数据,FashionAI—服饰关键点定位数据集_数据集-阿里云天池 (aliyun.com)
其中服饰关键点定位赛题提供的训练集包括7W多张图片,测试集包括5W多张图片。
每张图片都指定了对应的服饰类别,共5类:上衣(blouse)、外套(outwear)、连身裙(dress)、半身裙(skirt)、裤子(trousers)。

训练集还提供了每张图片对应的24个关键点的标注,包括x坐标、y坐标、是否可见三项信息,但并不是每类服饰都有24个关键点,数据详细信息可查看FashionAI—服饰关键点定位数据集_数据集-阿里云天池 (aliyun.com)。
| Ubuntu | 22.04 |
|---|---|
| GPU | 2080 Ti-11G |
| cuda | 10.0.130 |
| cudnn | 7.6.5.32-1+cuda10.0 |
| python | 3.7.10 |
| tensorflow-gpu | 1.15.5 |
| numpy | 1.18.5 |
| pandas | 1.2.4 |
| scikit-learn | 0.24.2 |
| opencv-contrib-python | 4.5.1.48 |
| matplotlib | 3.4.1 |
| imageio | 2.15.0 |
| tqdm | 4.64.1 |
由于tensorflow-gpu的1.x版不支持RTX 30系列显卡,故在30系列显卡上训练时,训练和测试损失会出现nan,即使使用已经训练好的模型测试也会出现关键点捕捉不准确,代码中已经默认使用CPU测试,若想使用GPU,则建议在20系列上进行实验(亲测可行)。
如果事先未了解过tensorflow-gpu和Cuda、cudnn的相关知识,可以参考Tensorflow、CUDA、cuDNN详细的下载安装过程_cudnn下载-CSDN博客进行安装。
我已经提供了预训练模型,在2080Ti的GPU上训练共历时两天,如果想要自己尝试训练进行优化,在代码目录下执行:
python train.py
对不同的服饰种类进行训练时,要在train.py中修改以下部分(此时为训练skirt服饰集):
#train = train[train.image_category == 'dress']#以dress为例,测试代码运行效果
#train = train[train.image_category == 'blouse']
#train = train[train.image_category == 'outwear']
#train = train[train.image_category == 'trousers']
train = train[train.image_category == 'skirt']修改上述代码,从训练集中选择所要训练的服饰类型。
#dress
'''features = [
'neckline_left', 'neckline_right', 'center_front', 'shoulder_left', 'shoulder_right',
'armpit_left', 'armpit_right', 'waistline_left', 'waistline_right',
'cuff_left_in', 'cuff_left_out', 'cuff_right_in', 'cuff_right_out', 'hemline_left', 'hemline_right']#15'''
#blouse
'''features = [
'neckline_left', 'neckline_right', 'center_front', 'shoulder_left', 'shoulder_right',
'armpit_left', 'armpit_right', 'cuff_left_in', 'cuff_left_out', 'cuff_right_in',
'cuff_right_out','top_hem_left','top_hem_right']#13'''
#outwear
'''features = [
'neckline_left', 'neckline_right', 'shoulder_left', 'shoulder_right','armpit_left',
'armpit_right', 'waistline_left', 'waistline_right','cuff_left_in','cuff_left_out',
'cuff_right_in', 'cuff_right_out','top_hem_left','top_hem_right']#14'''
#trousers
'''features = [
'waistband_left','waistband_right','crotch','bottom_left_in','bottom_left_out',
'bottom_right_in','bottom_right_out']#7'''
#skirt
features = [
'waistband_left','waistband_right','hemline_left', 'hemline_right']#4修改上述代码,对不同服饰选择其所对应的特征集,集合后的数字为该服饰所拥有的特征数量。
OUTPUT_DIR ='skirt'选择训练后模型与训练中示例图片的保存路径。

上图为一张skirt训练结果,第一行的三张依次是第1个、第2个、第3个Stage的响应图合成结果,第二行的三张分别对应第6个Stage的响应图合成结果、正确答案、正确答案和原图的合成,证明关键点捕捉准确。


为更好地完成关键点检测任务,我对于特征提取过程做了些许修改,这是我们改进后地模型训练具体流程。
我已经使用上述数据集生成了预训练模型和示例图片,并将其保存在blouse、skirt、trousers、outwear和dress五个文件夹内,可根据需要自行选择使用的模型。
如果想要查看关键点捕捉效果,在代码目录下执行:
python test.py
会生成测试集中随机16张图片的关键点捕捉结果,保存在你所测试的服饰类型所对应的文件夹下,并输出前5张图片的关键点位置坐标。
若想修改所测试的服装类型,请修改以下test.py中的以下代码(以测试dress数据为例):
test = test[test.image_category == 'dress']
#test = test[test.image_category == 'blouse']
#test = test[test.image_category == 'outwear']
#test = test[test.image_category == 'trousers']
#test = test[test.image_category == 'skirt']上述代码用于选择所要测试的服装数据。
OUTPUT_DIR = 'dress'修改OUTPUT_DIR,从该目录下使用训练好的模型,并将测试结果也保存在该目录下。
y_dim = 15#根据训练的数据进行调整将y_dim的的值修改为该类服饰的特征数量,与train.py中特征集合后的数字相同。
注:为方便使用,已将测试代码封装为函数保存在test_def.py中。
-
data文件夹下存放训练和测试集数据;
-
blouse、skirt、trousers、outwear和dress五个文件夹分别存放对应的预训练模型和训练过程示例图片;
-
cuda_test.py 用于测试tensorflow是否可使用GPU;
-
data_augmentation.py用于数据增强,对训练集图片进行随机旋转、随机平移、随机水平翻转,增强模型鲁棒性;
-
data_preprocess.py用于对天池赛上下载的数据集进行预处理;
-
test.py是测试文件;
-
test_def.py是封装好的测试文件;
-
train.py用于对数据集进行训练,得到训练好的模型;
-
utils_key.py是所有代码运行时所需要用的的外部依赖。
-
由于Linux与Windows路径符不同( / 和 \ )故在不同的操作系统中,建议先运行data_preprocess.py,得到适应操作系统的train_changed.csv文件,上传文件中为在Linux系统中生成的预处理后表格。
-
在对关键点数据进行训练时,起初试图将其一起训练,但是显存空间不足,故针对每种服装对其分别进行训练,训练时要自己根据服装种类,在train_changed.csv进行初步筛选,再在train.py中选择对应的特征集,并创建对应输出目录。
-
测试时,同样要根据服装种类,在test.csv进行初步筛选,然后由其拥有的特征集大小确定关键点数组的维度(即y_dim),选择对应的模型导入目录和输出目录。
- Convolutional Pose Machines:https://arxiv.org/abs/1602.00134
- Code repository for Convolutional Pose Machines:https://github.com/shihenw/convolutional-pose-machines-release
- 天池FashionAI全球挑战赛小小尝试:https://zhuanlan.zhihu.com/p/34
- 服饰关键点定位:27 服饰关键点定位 - 知乎 (zhihu.com)
- FashionAI—服饰关键点定位数据集_数据集:https://tianchi.aliyun.com/dataset/136923
- Tensorflow、Cuda、cudnn安装:Tensorflow、CUDA、cuDNN详细的下载安装过程_cudnn下载-CSDN博客