Puppeteer(中文翻译"木偶") 是 Google Chrome 团队官方的无界面(Headless)Chrome 工具,它是一个 Node 库,提供了一个高级的 API 来控制 DevTools协议上的无头版 Chrome 。也可以配置为使用完整(非无头)的 Chrome。Chrome 素来在浏览器界稳执牛耳,因此,Chrome Headless 必将成为 web 应用自动化测试的行业标杆。使用 Puppeteer,相当于同时具有 Linux 和 Chrome 双端的操作能力,应用场景可谓非常之多。此仓库的建立,即是尝试各种折腾使用 GoogleChrome Puppeteer;以期在好玩的同时,学到更多有意思的操作。
你可以在浏览器中手动完成的大部分事情都可以使用 Puppeteer 完成!你可以从以下几个示例开始:
- 生成页面的截图和PDF。
- 抓取SPA并生成预先呈现的内容(即“SSR”)。
- 从网站抓取你需要的内容。
- 自动表单提交,UI测试,键盘输入等
- 创建一个最新的自动化测试环境。使用最新的JavaScript和浏览器功能,直接在最新版本的Chrome中运行测试。
- 捕获您的网站的时间线跟踪,以帮助诊断性能问题。
微注: 鉴于个人信息不便于提交,已设置 git 提交忽视私密配置文件;如要运行如下几个 Demo,需要手动在
src/config目录下,创建 secret.js,格式如 secretSample.js 所示(🍀️)。
备注: 鉴于
Puppeteer需要Chromium,但,即便处于 Science 上网的姿态, 也会遇到 Chromium 无法成功下载的问题;所以在最新的修改中,已经其替换为 puppeteer-core (默认情况下不下载 Chromium,使用时需要确保您安装的puppeteer-core版本与您要连接的浏览器兼容)。在实际使用时候,即便已然按照说明操作,但依旧会报如下错误:Error: Chromium revision is not downloaded. Run "npm install" or "yarn install"
因此只好采取手动下载
Chromium的方式解决;因此在运行此仓库时候,您需要在 Puppeteer API Tip-Of-Tree 根据指定 Puppeteer 下载对应 Chromium,然后放置到项根目录即可(项目中已对各不同系统做了适配,国内用户可以在 Taobao Mirrors 根据系统按需下载)。
这番折腾,是基于 Puppeteer 抓取某网页链接( 具体是在 https://jefwww.fjade.com/categories/Front-End/ 中随机出一篇),将其推送到技术头条;其目的在于:练习初步运用 Puppeteer。
git clone https://github.com/nicejade/toss-puppeteer
npm i (更推荐 yarn)
npm run shareBlogToBlogread
- 打开技术头条-提交页面,同时到 晚晴幽草轩-Front-End 随机抓取一篇文章,获取到标题、地址、描述。
- 模拟人为操作,点开“用微博登录”按钮(会跳转至微博登录页面);
- 模拟人为操作,填充用户名和密码并“点击”登录按钮,完成登录(会重新跳转至技术头条-提交页面);
- 模拟人为操作,填充之前获取到的标题、地址、描述,并“点击”提交,打完收工。
- 将其部署于服务器,并设置任务,定时间隔性执行,完成自动按时分享。
处于某些分享需要,偶尔会涉及到这样的需求即:分享指定链接(Url)到指定网站;这个相比于如上功能,要省却些步骤。如果愿意折腾的话,还可以提交至多个不同的目标网站,只需增加设定目标地址,登录方式,以及提交表单的信息即可。当然,对于涉及到登录需要复杂的验证网站,额外需要多做些处理。这里只对技术头条做了配置,运行如下命令即可:(Update@17-12-17)
Url=https://jeffjade.com/2017/09/28/127-nice-front-end-tutorial/ yarn shareUrlToTheSite
url=https://jeffjade.com/2017/09/28/127-nice-front-end-tutorial/ yarn shareUrlToTheSite
此番折腾,是基于 Puppeteer 抓取指定网站页面(示例是 https://jeffjade.com/ 所有文章),并将其打印成 PDF;其目的在于:进一步熟悉运用 Puppeteer。
git clone https://github.com/nicejade/toss-puppeteer
npm i (更推荐 yarn)
npm run printWebsiteToPDF
- 打开 https://jeffjade.com/archives 页面,从而得到博客文章总分页总数;
- 运用
axios&cheerio抓取分页并分析,从而得到网站所有文章链接,并存储在数据中; - 遍历所有链接(借助
async控制并发),在页面渲染完成之后,将其打印成 PDF 并保存。
早前在 About Me有如此感叹道:
嗟夫,真真是:独立的才是自己的。博客从最开始用多说,17年6月1日关闭服务后,转战网易云跟帖;未曾想它8月1日也跟着关闭了。索性转投靠至国外Disqus,奈何这堵墙厉害之极,家里虽也翻了墙,却仍不能很好访问;这才又转战至 Gitment;😂言多皆泪,感慨颇多啊——独立的才是自己的,之后得空时候,还是自己搞一套😪,Fighting。
这提及的 Gitment 是基于 GitHub Issues 的评论系统;它本身的一些特征,使得它存在很多优势,对于维护“程序”相关话题博客。所以,个人博客晚晴幽草轩就采用此评论系统;但,它也会存在一些问题,譬如需要主动初始化评论,initialize-your-comments,当然也可以运用些工具协助完成✅。对于已经写了 140+ 篇博文的晚晴幽草轩,这实在很有必要;所以,这里谈及即,使用 Puppeteer 一键来初始化 Gitment 评论系统(需要注明的是,每个系统结构有所区别,这里只具有些参考性,却不能直接加以使用)。
git clone https://github.com/nicejade/toss-puppeteer
npm i (更推荐 yarn)
npm run initializeGitment- 打开 https://jeffjade.com/archives 页面,从而得到博客文章总分页总数;
- 运用
axios&cheerio抓取分页并分析,从而得到网站所有文章链接,并存储在数据中; - 打开 Github 登录地址: https://github.com/login ,填充用户名、密码,从而完成登录;
- 遍历所存储链接,并在不同窗口打开(借助
async控制并发); - 等待,直到初始化按钮显示后并点击(实际上需要先触发博客页面的 Github login 链接);
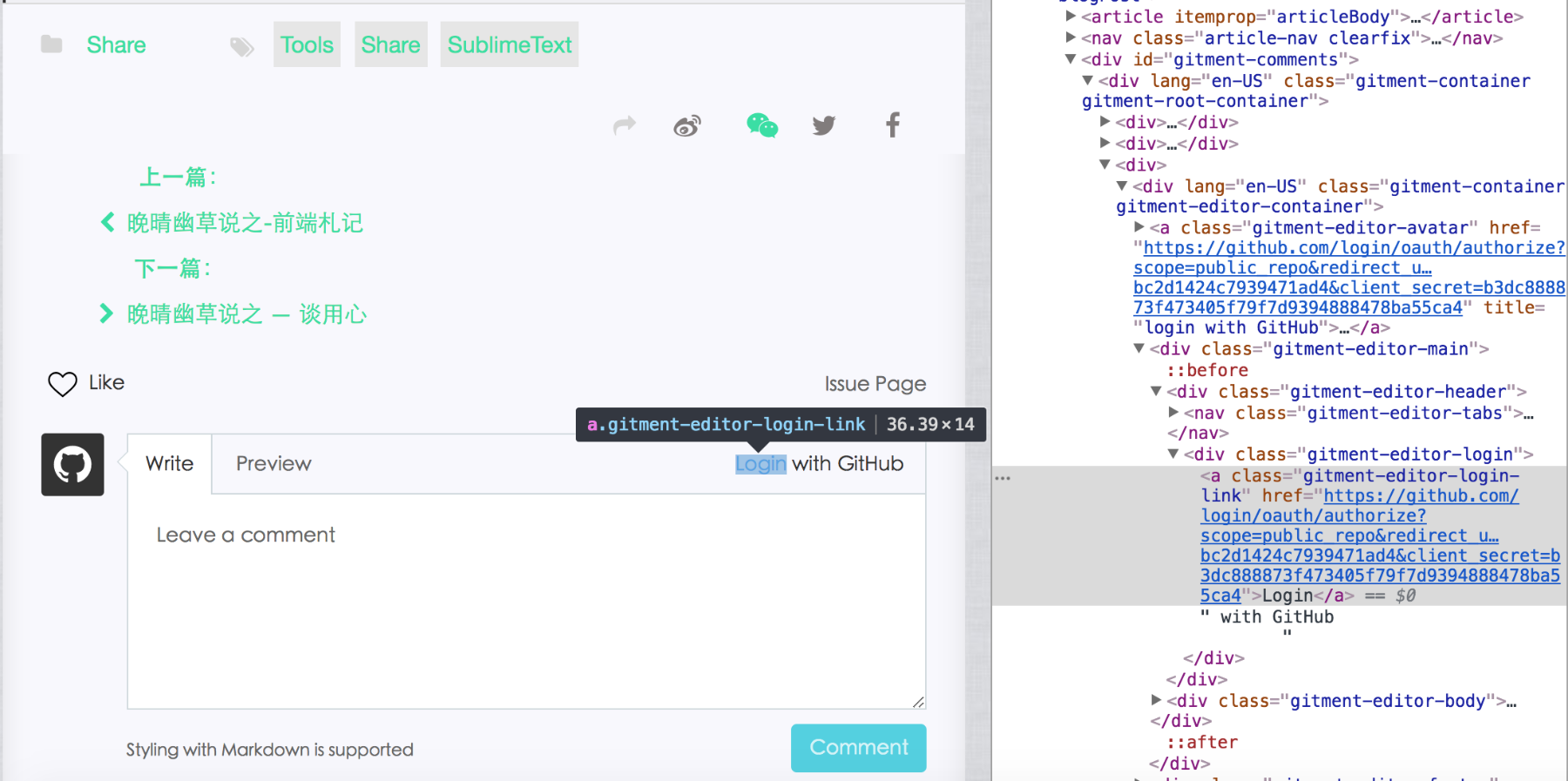
寄存的博客评论,可在 jadeblog-backups#issues 查看;(实际上,在使用 Gitment 之时,触发初始化按钮,并未能真正完成初始化,猜测这可能是插件本身的问题,或者别的,需要进一步探究)(Update@17-11-23)。
可以使用 tracing.start 和 tracing.stop 创建一个可以在 Chrome 开发工具或时间线查看器中打开的跟踪文件(每个浏览器一次只能激活一个跟踪),具体参见 Puppeteer Trace Api。
await page.tracing.start({path: 'trace.json'})
await page.goto('https://www.google.com')
await page.tracing.stop()git clone https://github.com/nicejade/toss-puppeteer
npm i (更推荐 yarn)
npm run performanceAnalysis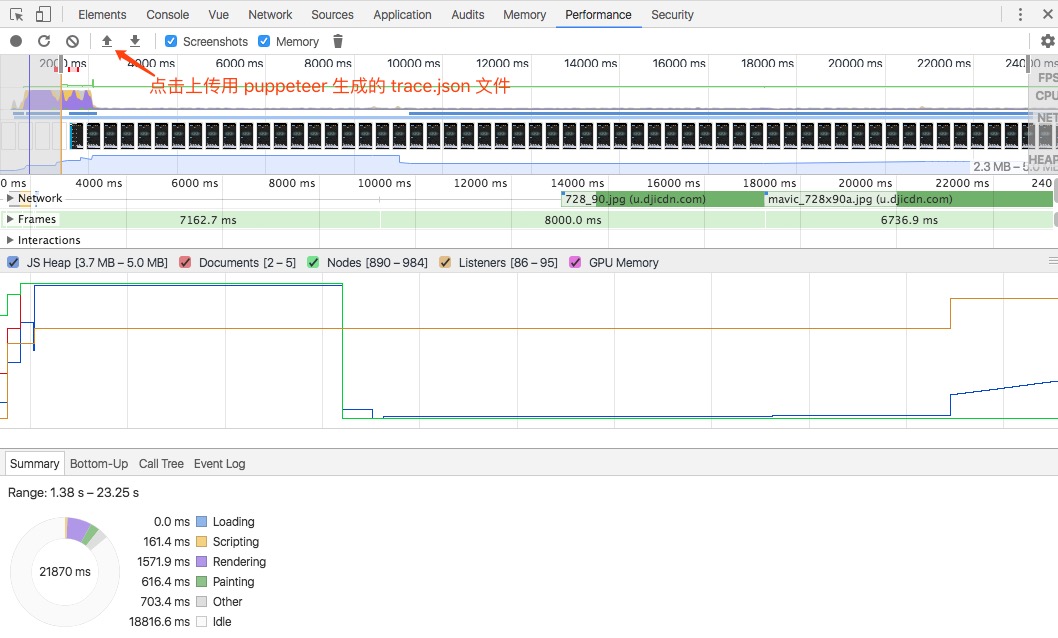
对于 Chrome Performance/Timeline,如何使用,可以参见 Chrome 开发者工具,或者移步至 Chrome Tutorial,这里有比较详尽的,不断补充修缮的参考资料。