{kind=link}
Keywords network builder based on TF-IDF with the use of Hadoop platform.
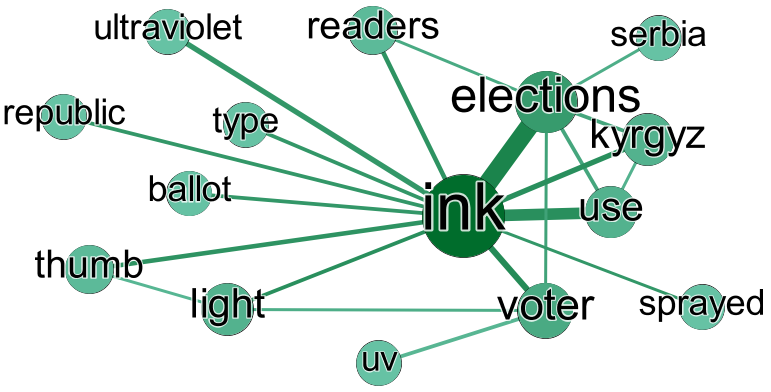
A keywords graph built from this article.
This repository is intended to work with Cloudera Hadoop technology stack, but can be easily ported to any other Hadoop stacks.
- Download this VM used by Cloudera.
- Log in to VM using
training/traininglogin/password. - Clone this repository using Git with its submodules:
git clone --recursive https://github.com/ZitRos/hadoop-network-of-keywords. cd hadoop-network-of-keywordsand run the shell scriptrun_mapreduce.sh.- To generate the graph to
result.csv, runnetwork_builder.pyafter running 4. - Build a visual graph from
result.csvfile, for example, using Gephi.
TF-IDF metrics are computed using Hadoop. Further processing and graph building are done after TF-IDF values are computed.
By running the run_mapreduce.sh script, you should get similar output to the
following. Note that you can pass a particular file name to analyze to the shell
script, located at texts directory: run_mapreduce.sh animals/dogs.txt.
Sample output:
[training@localhost hadoop-network-of-keywords]$ ./run_mapreduce.sh
Calculating TF-IDF for tech/ink-helps-drive-democracy-in-asia.txt
Running TF mapreduce...
Removing old results...
Deleted /temp
Putting files to HDFS...
Counting files...
Running TF mapreduce on Hadoop...
packageJobJar: [tf_mapper.py, tf_reducer.py, utils.py, /tmp/hadoop-training/hadoop-unjar7892492009998614173/] [] /tmp/streamjob4399530855769057884.jar tmpDir=null
17/12/16 21:15:56 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
17/12/16 21:15:56 WARN snappy.LoadSnappy: Snappy native library is available
17/12/16 21:15:56 INFO snappy.LoadSnappy: Snappy native library loaded
17/12/16 21:15:56 INFO mapred.FileInputFormat: Total input paths to process : 2095
17/12/16 21:15:58 INFO streaming.StreamJob: getLocalDirs(): [/var/lib/hadoop-hdfs/cache/training/mapred/local]
17/12/16 21:15:58 INFO streaming.StreamJob: Running job: job_201712162108_0001
17/12/16 21:15:58 INFO streaming.StreamJob: To kill this job, run:
17/12/16 21:15:58 INFO streaming.StreamJob: UNDEF/bin/hadoop job -Dmapred.job.tracker=0.0.0.0:8021 -kill job_201712162108_0001
17/12/16 21:15:58 INFO streaming.StreamJob: Tracking URL: http://0.0.0.0:50030/jobdetails.jsp?jobid=job_201712162108_0001
17/12/16 21:15:59 INFO streaming.StreamJob: map 0% reduce 0%
17/12/16 21:16:23 INFO streaming.StreamJob: map 1% reduce 0%
...
17/12/16 21:18:45 INFO streaming.StreamJob: map 5% reduce 0%
17/12/16 21:19:12 INFO streaming.StreamJob: map 5% reduce 2%
17/12/16 21:19:22 INFO streaming.StreamJob: map 6% reduce 2%
...
17/12/16 22:14:49 INFO streaming.StreamJob: map 99% reduce 33%
17/12/16 22:15:23 INFO streaming.StreamJob: map 100% reduce 33%
17/12/16 22:15:44 INFO streaming.StreamJob: map 100% reduce 74%
17/12/16 22:15:47 INFO streaming.StreamJob: map 100% reduce 83%
17/12/16 22:15:50 INFO streaming.StreamJob: map 100% reduce 92%
17/12/16 22:15:54 INFO streaming.StreamJob: map 100% reduce 100%
17/12/16 22:15:55 INFO streaming.StreamJob: Job complete: job_201712162108_0001
17/12/16 22:15:55 INFO streaming.StreamJob: Output: /temp/output
Running DF mapreduce on Hadoop...
packageJobJar: [df_mapper.py, df_reducer.py, utils.py, /tmp/hadoop-training/hadoop-unjar8254911625928607214/] [] /tmp/streamjob64323986015252274.jar tmpDir=null
17/12/16 22:15:57 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
17/12/16 22:15:57 WARN snappy.LoadSnappy: Snappy native library is available
17/12/16 22:15:57 INFO snappy.LoadSnappy: Snappy native library loaded
17/12/16 22:15:57 INFO mapred.FileInputFormat: Total input paths to process : 1
17/12/16 22:15:57 INFO streaming.StreamJob: getLocalDirs(): [/var/lib/hadoop-hdfs/cache/training/mapred/local]
17/12/16 22:15:57 INFO streaming.StreamJob: Running job: job_201712162108_0002
17/12/16 22:15:57 INFO streaming.StreamJob: To kill this job, run:
17/12/16 22:15:57 INFO streaming.StreamJob: UNDEF/bin/hadoop job -Dmapred.job.tracker=0.0.0.0:8021 -kill job_201712162108_0002
17/12/16 22:15:57 INFO streaming.StreamJob: Tracking URL: http://0.0.0.0:50030/jobdetails.jsp?jobid=job_201712162108_0002
17/12/16 22:15:58 INFO streaming.StreamJob: map 0% reduce 0%
17/12/16 22:16:03 INFO streaming.StreamJob: map 100% reduce 0%
17/12/16 22:16:11 INFO streaming.StreamJob: map 100% reduce 95%
17/12/16 22:16:13 INFO streaming.StreamJob: map 100% reduce 100%
17/12/16 22:16:14 INFO streaming.StreamJob: Job complete: job_201712162108_0002
17/12/16 22:16:14 INFO streaming.StreamJob: Output: /temp/dfoutput
Getting results into tf_df_output.txt...The result will go to tf_df_output.txt file. Each row in this file is a tuple of
three values (term frequency, document frequency, word), separated by tabs. To
calculate TF-IDF, the number of documents is saved to files_count.txt file as a
plain number.
Example of tf_df_output.txt:
3 5 a
1 3 and
1 5 are
1 1 awesome
1 1 best
1 1 can
1 1 dog
5 1 dogs
1 1 everybody
1 1 friend
1 1 high
1 3 is
1 1 jump
2 3 love
1 1 man
1 3 of
1 2 otherAfter generating tf_df_output.txt file with some other helper files, run the network_builder.py
script to produce result.csv file. Example of result is generated from
Ink helps drive democrasy in Asia article in result.csv file:
;use;voter;thumb;readers;type;uv;serbia;elections;light;sprayed;ultraviolet;ink;republic;kyrgyz;ballot
use;0;0;0;0;0;0;0;2;0;0;0;12;0;1;0
voter;0;0;0;0;0;2;0;1;1;0;0;5;0;0;0
thumb;0;0;0;0;0;0;0;0;1;0;0;3;0;0;0
readers;0;0;0;0;0;0;0;1;0;0;0;3;0;0;0
type;0;0;0;0;0;0;0;0;0;0;0;2;0;0;0
uv;0;2;0;0;0;0;0;0;0;0;0;0;0;0;0
serbia;0;0;0;0;0;0;0;1;0;0;0;0;0;0;0
elections;2;1;0;1;0;0;1;0;0;0;0;21;0;2;0
light;0;1;1;0;0;0;0;0;0;0;0;2;0;0;0
sprayed;0;0;0;0;0;0;0;0;0;0;0;1;0;0;0
ultraviolet;0;0;0;0;0;0;0;0;0;0;0;4;0;0;0
ink;12;5;3;3;2;0;0;21;2;1;4;0;2;4;2
republic;0;0;0;0;0;0;0;0;0;0;0;2;0;0;0
kyrgyz;1;0;0;0;0;0;0;2;0;0;0;4;0;0;0
ballot;0;0;0;0;0;0;0;0;0;0;0;2;0;0;0
MIT © Nikita Savchenko