diff --git a/.ci/spellcheck/.pyspelling.wordlist.txt b/.ci/spellcheck/.pyspelling.wordlist.txt
index 93693522d4d..feb81243299 100644
--- a/.ci/spellcheck/.pyspelling.wordlist.txt
+++ b/.ci/spellcheck/.pyspelling.wordlist.txt
@@ -47,6 +47,7 @@ autoregressive
autoregressively
AutoTokenizer
AWQ
+awq
backend
backends
Baevski
@@ -391,6 +392,7 @@ KServe
Kubernetes
Kupyn
KV
+KVCache
Labelling
labour
labse
@@ -617,6 +619,7 @@ Prateek
pre
Precisions
precomputed
+preconverted
prefetching
preformatted
PrePostProcessing
diff --git a/notebooks/llm-chatbot/genai_gradio_helper.py b/notebooks/llm-chatbot/genai_gradio_helper.py
index 6b73c800c9d..95b23932c23 100644
--- a/notebooks/llm-chatbot/genai_gradio_helper.py
+++ b/notebooks/llm-chatbot/genai_gradio_helper.py
@@ -9,33 +9,33 @@
core = ov.Core()
chinese_examples = [
- ["你好!"],
- ["你是谁?"],
- ["请介绍一下上海"],
- ["请介绍一下英特尔公司"],
- ["晚上睡不着怎么办?"],
- ["给我讲一个年轻人奋斗创业最终取得成功的故事。"],
- ["给这个故事起一个标题。"],
+ ["你好!"],
+ ["你是谁?"],
+ ["请介绍一下上海"],
+ ["请介绍一下英特尔公司"],
+ ["晚上睡不着怎么办?"],
+ ["给我讲一个年轻人奋斗创业最终取得成功的故事。"],
+ ["给这个故事起一个标题。"],
]
english_examples = [
- ["Hello there! How are you doing?"],
- ["What is OpenVINO?"],
- ["Who are you?"],
- ["Can you explain to me briefly what is Python programming language?"],
- ["Explain the plot of Cinderella in a sentence."],
- ["What are some common mistakes to avoid when writing code?"],
- ["Write a 100-word blog post on “Benefits of Artificial Intelligence and OpenVINO“"],
+ ["Hello there! How are you doing?"],
+ ["What is OpenVINO?"],
+ ["Who are you?"],
+ ["Can you explain to me briefly what is Python programming language?"],
+ ["Explain the plot of Cinderella in a sentence."],
+ ["What are some common mistakes to avoid when writing code?"],
+ ["Write a 100-word blog post on “Benefits of Artificial Intelligence and OpenVINO“"],
]
japanese_examples = [
- ["こんにちは!調子はどうですか?"],
- ["OpenVINOとは何ですか?"],
- ["あなたは誰ですか?"],
- ["Pythonプログラミング言語とは何か簡単に説明してもらえますか?"],
- ["シンデレラのあらすじを一文で説明してください。"],
- ["コードを書くときに避けるべきよくある間違いは何ですか?"],
- ["人工知能と「OpenVINOの利点」について100語程度のブログ記事を書いてください。"],
+ ["こんにちは!調子はどうですか?"],
+ ["OpenVINOとは何ですか?"],
+ ["あなたは誰ですか?"],
+ ["Pythonプログラミング言語とは何か簡単に説明してもらえますか?"],
+ ["シンデレラのあらすじを一文で説明してください。"],
+ ["コードを書くときに避けるべきよくある間違いは何ですか?"],
+ ["人工知能と「OpenVINOの利点」について100語程度のブログ記事を書いてください。"],
]
DEFAULT_SYSTEM_PROMPT = """\
@@ -55,7 +55,11 @@
def get_system_prompt(model_language):
- return DEFAULT_SYSTEM_PROMPT_CHINESE if (model_language == "Chinese") else DEFAULT_SYSTEM_PROMPT_JAPANESE if (model_language == "Japanese") else DEFAULT_SYSTEM_PROMPT
+ return (
+ DEFAULT_SYSTEM_PROMPT_CHINESE
+ if (model_language == "Chinese")
+ else DEFAULT_SYSTEM_PROMPT_JAPANESE if (model_language == "Japanese") else DEFAULT_SYSTEM_PROMPT
+ )
class TextQueue:
@@ -111,10 +115,8 @@ def default_partial_text_processor(partial_text: str, new_text: str):
partial_text += new_text
return partial_text
-
text_processor = model_configuration.get("partial_text_processor", default_partial_text_processor)
-
def bot(message, history, temperature, top_p, top_k, repetition_penalty):
"""
callback function for running chatbot on submit button click
@@ -168,13 +170,11 @@ def generate_and_signal_complete():
history[-1][1] = partial_text
yield "", history, streamer
-
def stop_chat(streamer):
if streamer is not None:
streamer.end()
return None
-
def stop_chat_and_clear_history(streamer):
if streamer is not None:
streamer.end()
@@ -183,7 +183,6 @@ def stop_chat_and_clear_history(streamer):
examples = chinese_examples if (model_language == "Chinese") else japanese_examples if (model_language == "Japanese") else english_examples
-
with gr.Blocks(
theme=gr.themes.Soft(),
css=".disclaimer {font-variant-caps: all-small-caps;}",
@@ -272,4 +271,4 @@ def stop_chat_and_clear_history(streamer):
stop.click(fn=stop_chat, inputs=streamer, outputs=[streamer], queue=False)
clear.click(fn=stop_chat_and_clear_history, inputs=streamer, outputs=[chatbot, streamer], queue=False)
- return demo
\ No newline at end of file
+ return demo
diff --git a/notebooks/llm-chatbot/llm-chatbot-generate-api.ipynb b/notebooks/llm-chatbot/llm-chatbot-generate-api.ipynb
index 1c6853141dd..0a953b5ba9f 100644
--- a/notebooks/llm-chatbot/llm-chatbot-generate-api.ipynb
+++ b/notebooks/llm-chatbot/llm-chatbot-generate-api.ipynb
@@ -1,6 +1,7 @@
{
"cells": [
{
+ "attachments": {},
"cell_type": "markdown",
"id": "50e1d1d5-3bdd-4224-9f93-bf5d9a83f424",
"metadata": {},
@@ -11,8 +12,8 @@
"Large Language Models (LLMs) are artificial intelligence systems that can understand and generate human language. They use deep learning algorithms and massive amounts of data to learn the nuances of language and produce coherent and relevant responses.\n",
"While a decent intent-based chatbot can answer basic, one-touch inquiries like order management, FAQs, and policy questions, LLM chatbots can tackle more complex, multi-touch questions. LLM enables chatbots to provide support in a conversational manner, similar to how humans do, through contextual memory. Leveraging the capabilities of Language Models, chatbots are becoming increasingly intelligent, capable of understanding and responding to human language with remarkable accuracy.\n",
"\n",
- "Previously, we already discussed how to build an instruction-following pipeline using OpenVINO and Optimum Intel, please check out [Dolly example](../dolly-2-instruction-following) for reference.\n",
- "In this tutorial, we consider how to use the power of OpenVINO for running Large Language Models for chat. We will use a pre-trained model from the [Hugging Face Transformers](https://huggingface.co/docs/transformers/index) library. The [Hugging Face Optimum Intel](https://huggingface.co/docs/optimum/intel/index) library converts the models to OpenVINO™ IR format. To simplify the user experience, we will use [OpenVINO Generate API](https://github.com/openvinotoolkit/openvino.genai) for generation of instruction-following inference pipeline.\n",
+ "Previously, we already discussed how to build an instruction-following pipeline using OpenVINO, please check out [this tutorial](../llm-question-answering/llm-question-answering.ipynb) for reference.\n",
+ "In this tutorial, we consider how to use the power of OpenVINO for running Large Language Models for chat. We will use a pre-trained model from the [Hugging Face Transformers](https://huggingface.co/docs/transformers/index) library. The [Hugging Face Optimum Intel](https://huggingface.co/docs/optimum/intel/index) library converts the models to OpenVINO™ IR format. To simplify the user experience, we will use [OpenVINO Generate API](https://github.com/openvinotoolkit/openvino.genai) for generation pipeline.\n",
"\n",
"\n",
"The tutorial consists of the following steps:\n",
@@ -21,39 +22,36 @@
"- Download and convert the model from a public source using the [OpenVINO integration with Hugging Face Optimum](https://huggingface.co/blog/openvino).\n",
"- Compress model weights to 4-bit or 8-bit data types using [NNCF](https://github.com/openvinotoolkit/nncf)\n",
"- Create a chat inference pipeline with [OpenVINO Generate API](https://github.com/openvinotoolkit/openvino.genai/blob/master/src/README.md).\n",
- "- Run chat pipeline\n",
+ "- Run chat pipeline with [Gradio](https://www.gradio.app/).\n",
"\n",
"\n",
"\n",
"\n",
"\n",
+ "### Installation Instructions\n",
+ "\n",
+ "This is a self-contained example that relies solely on its own code.\n",
+ "\n",
+ "We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.\n",
+ "For details, please refer to [Installation Guide](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/README.md#-installation-guide).\n",
+ "\n",
+ " \n",
+ "\n",
"#### Table of contents:\n",
"\n",
"- [Prerequisites](#Prerequisites)\n",
"- [Select model for inference](#Select-model-for-inference)\n",
"- [Convert model using Optimum-CLI tool](#Convert-model-using-Optimum-CLI-tool)\n",
- "- [Compress model weights](#Compress-model-weights)\n",
" - [Weights Compression using Optimum-CLI](#Weights-Compression-using-Optimum-CLI)\n",
- " - [Weight compression with AWQ](#Weight-compression-with-AWQ)\n",
- " - [Select device for inference and model variant](#Select-device-for-inference-and-model-variant)\n",
+ "- [Select device for inference](#Select-device-for-inference)\n",
"- [Instantiate pipeline with OpenVINO Generate API](#Instantiate-pipeline-with-OpenVINO-Generate-API)\n",
"- [Run Chatbot](#Run-Chatbot)\n",
- " - [Prepare text streamer to get results runtime](#Prepare-text-streamer-to-get-results-runtime)\n",
- " - [Setup of the chatbot life process function](#Setup-of-the-chatbot-life-process-function)\n",
- " - [Next Step](#Next-Step)\n",
- "\n",
- "\n",
- "### Installation Instructions\n",
- "\n",
- "This is a self-contained example that relies solely on its own code.\n",
- "\n",
- "We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.\n",
- "For details, please refer to [Installation Guide](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/README.md#-installation-guide).\n",
- "\n",
- "\n"
+ " - [Advanced generation options](#Advanced-generation-options)\n",
+ "\n"
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "5df233b0-0369-4fff-9952-7957a90394a5",
"metadata": {},
@@ -66,7 +64,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 1,
"id": "563ecf9f-346b-4f14-85ef-c66ff0c95f65",
"metadata": {
"tags": []
@@ -134,13 +132,12 @@
" open(\"gradio_helper.py\", \"w\").write(r.text)\n",
"\n",
"if not Path(\"notebook_utils.py\").exists():\n",
- " r = requests.get(\n",
- " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\"\n",
- " )\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\")\n",
" open(\"notebook_utils.py\", \"w\").write(r.text)"
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "81983176-e571-4652-ba21-4bd608c35146",
"metadata": {},
@@ -149,8 +146,17 @@
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"The tutorial supports different models, you can select one from the provided options to compare the quality of open source LLM solutions.\n",
+ "Model conversion and optimization is time- and memory-consuming process. For your convenience, we provide a [collection](https://huggingface.co/collections/OpenVINO/llm-6687aaa2abca3bbcec71a9bd) of optimized models on HuggingFace hub. You can skip the model conversion step by selecting one of the available on HuggingFace hub model. If you want to reproduce optimization process locally, please unset **Use preconverted models** checkbox.\n",
+ "\n",
">**Note**: conversion of some models can require additional actions from user side and at least 64GB RAM for conversion.\n",
"\n",
+ "[Weight compression](https://docs.openvino.ai/2024/openvino-workflow/model-optimization-guide/weight-compression.html) is a technique for enhancing the efficiency of models, especially those with large memory requirements. This method reduces the model’s memory footprint, a crucial factor for Large Language Models (LLMs). We provide several options for model weight compression:\n",
+ "\n",
+ "* **FP16** reducing model binary size on disk using `save_model` with enabled compression weights to FP16 precision. This approach is available in OpenVINO from scratch and is the default behavior.\n",
+ "* **INT8** is an 8-bit weight-only quantization provided by [NNCF](https://github.com/openvinotoolkit/nncf): This method compresses weights to an 8-bit integer data type, which balances model size reduction and accuracy, making it a versatile option for a broad range of applications.\n",
+ "* **INT4** is an 4-bit weight-only quantization provided by [NNCF](https://github.com/openvinotoolkit/nncf). involves quantizing weights to an unsigned 4-bit integer symmetrically around a fixed zero point of eight (i.e., the midpoint between zero and 15). in case of **symmetric quantization** or asymmetrically with a non-fixed zero point, in case of **asymmetric quantization** respectively. Compared to INT8 compression, INT4 compression improves performance even more, but introduces a minor drop in prediction quality. INT4 it ideal for situations where speed is prioritized over an acceptable trade-off against accuracy.\n",
+ "* **INT4 AWQ** is an 4-bit activation-aware weight quantization. [Activation-aware Weight Quantization](https://arxiv.org/abs/2306.00978) (AWQ) is an algorithm that tunes model weights for more accurate INT4 compression. It slightly improves generation quality of compressed LLMs, but requires significant additional time for tuning weights on a calibration dataset. We will use `wikitext-2-raw-v1/train` subset of the [Wikitext](https://huggingface.co/datasets/Salesforce/wikitext) dataset for calibration.\n",
+ "\n",
"
\n",
+ "\n",
"#### Table of contents:\n",
"\n",
"- [Prerequisites](#Prerequisites)\n",
"- [Select model for inference](#Select-model-for-inference)\n",
"- [Convert model using Optimum-CLI tool](#Convert-model-using-Optimum-CLI-tool)\n",
- "- [Compress model weights](#Compress-model-weights)\n",
" - [Weights Compression using Optimum-CLI](#Weights-Compression-using-Optimum-CLI)\n",
- " - [Weight compression with AWQ](#Weight-compression-with-AWQ)\n",
- " - [Select device for inference and model variant](#Select-device-for-inference-and-model-variant)\n",
+ "- [Select device for inference](#Select-device-for-inference)\n",
"- [Instantiate pipeline with OpenVINO Generate API](#Instantiate-pipeline-with-OpenVINO-Generate-API)\n",
"- [Run Chatbot](#Run-Chatbot)\n",
- " - [Prepare text streamer to get results runtime](#Prepare-text-streamer-to-get-results-runtime)\n",
- " - [Setup of the chatbot life process function](#Setup-of-the-chatbot-life-process-function)\n",
- " - [Next Step](#Next-Step)\n",
- "\n",
- "\n",
- "### Installation Instructions\n",
- "\n",
- "This is a self-contained example that relies solely on its own code.\n",
- "\n",
- "We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.\n",
- "For details, please refer to [Installation Guide](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/README.md#-installation-guide).\n",
- "\n",
- "\n"
+ " - [Advanced generation options](#Advanced-generation-options)\n",
+ "\n"
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "5df233b0-0369-4fff-9952-7957a90394a5",
"metadata": {},
@@ -66,7 +64,7 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 1,
"id": "563ecf9f-346b-4f14-85ef-c66ff0c95f65",
"metadata": {
"tags": []
@@ -134,13 +132,12 @@
" open(\"gradio_helper.py\", \"w\").write(r.text)\n",
"\n",
"if not Path(\"notebook_utils.py\").exists():\n",
- " r = requests.get(\n",
- " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\"\n",
- " )\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\")\n",
" open(\"notebook_utils.py\", \"w\").write(r.text)"
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "81983176-e571-4652-ba21-4bd608c35146",
"metadata": {},
@@ -149,8 +146,17 @@
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"The tutorial supports different models, you can select one from the provided options to compare the quality of open source LLM solutions.\n",
+ "Model conversion and optimization is time- and memory-consuming process. For your convenience, we provide a [collection](https://huggingface.co/collections/OpenVINO/llm-6687aaa2abca3bbcec71a9bd) of optimized models on HuggingFace hub. You can skip the model conversion step by selecting one of the available on HuggingFace hub model. If you want to reproduce optimization process locally, please unset **Use preconverted models** checkbox.\n",
+ "\n",
">**Note**: conversion of some models can require additional actions from user side and at least 64GB RAM for conversion.\n",
"\n",
+ "[Weight compression](https://docs.openvino.ai/2024/openvino-workflow/model-optimization-guide/weight-compression.html) is a technique for enhancing the efficiency of models, especially those with large memory requirements. This method reduces the model’s memory footprint, a crucial factor for Large Language Models (LLMs). We provide several options for model weight compression:\n",
+ "\n",
+ "* **FP16** reducing model binary size on disk using `save_model` with enabled compression weights to FP16 precision. This approach is available in OpenVINO from scratch and is the default behavior.\n",
+ "* **INT8** is an 8-bit weight-only quantization provided by [NNCF](https://github.com/openvinotoolkit/nncf): This method compresses weights to an 8-bit integer data type, which balances model size reduction and accuracy, making it a versatile option for a broad range of applications.\n",
+ "* **INT4** is an 4-bit weight-only quantization provided by [NNCF](https://github.com/openvinotoolkit/nncf). involves quantizing weights to an unsigned 4-bit integer symmetrically around a fixed zero point of eight (i.e., the midpoint between zero and 15). in case of **symmetric quantization** or asymmetrically with a non-fixed zero point, in case of **asymmetric quantization** respectively. Compared to INT8 compression, INT4 compression improves performance even more, but introduces a minor drop in prediction quality. INT4 it ideal for situations where speed is prioritized over an acceptable trade-off against accuracy.\n",
+ "* **INT4 AWQ** is an 4-bit activation-aware weight quantization. [Activation-aware Weight Quantization](https://arxiv.org/abs/2306.00978) (AWQ) is an algorithm that tunes model weights for more accurate INT4 compression. It slightly improves generation quality of compressed LLMs, but requires significant additional time for tuning weights on a calibration dataset. We will use `wikitext-2-raw-v1/train` subset of the [Wikitext](https://huggingface.co/datasets/Salesforce/wikitext) dataset for calibration.\n",
+ "\n",
"\n",
" Click here to see available models options
\n",
"\n",
@@ -162,9 +168,7 @@
">You can login on Hugging Face Hub in notebook environment, using following code:\n",
" \n",
"```python\n",
- " ## login to huggingfacehub to get access to pretrained model \n",
- "[back to top ⬆️](#Table-of-contents:)\n",
- "\n",
+ " # login to huggingfacehub to get access to pretrained model \n",
"\n",
"\n",
" from huggingface_hub import notebook_login, whoami\n",
@@ -183,7 +187,7 @@
">You can login on Hugging Face Hub in notebook environment, using following code:\n",
" \n",
"```python\n",
- " ## login to huggingfacehub to get access to pretrained model \n",
+ " # login to huggingfacehub to get access to pretrained model \n",
"\n",
" from huggingface_hub import notebook_login, whoami\n",
"\n",
@@ -200,7 +204,7 @@
">You can login on Hugging Face Hub in notebook environment, using following code:\n",
" \n",
"```python\n",
- " ## login to huggingfacehub to get access to pretrained model \n",
+ " # login to huggingfacehub to get access to pretrained model \n",
"\n",
" from huggingface_hub import notebook_login, whoami\n",
"\n",
@@ -216,7 +220,7 @@
">You can login on Hugging Face Hub in notebook environment, using following code:\n",
" \n",
"```python\n",
- " ## login to huggingfacehub to get access to pretrained model \n",
+ " # login to huggingfacehub to get access to pretrained model \n",
"\n",
" from huggingface_hub import notebook_login, whoami\n",
"\n",
@@ -232,7 +236,7 @@
">You can login on Hugging Face Hub in notebook environment, using following code:\n",
" \n",
"```python\n",
- " ## login to huggingfacehub to get access to pretrained model \n",
+ " # login to huggingfacehub to get access to pretrained model \n",
"\n",
" from huggingface_hub import notebook_login, whoami\n",
"\n",
@@ -269,7 +273,7 @@
{
"data": {
"application/vnd.jupyter.widget-view+json": {
- "model_id": "4d7d47d24c4a42f699f0a32e81c14fe4",
+ "model_id": "eb4a943c89d34c98885e861c2edeedb2",
"version_major": 2,
"version_minor": 0
},
@@ -284,6 +288,7 @@
],
"source": [
"from llm_config import get_llm_selection_widget\n",
+ "\n",
"form, lang, model_id_widget, compression_variant, use_preconverted = get_llm_selection_widget()\n",
"\n",
"form"
@@ -291,7 +296,7 @@
},
{
"cell_type": "code",
- "execution_count": 17,
+ "execution_count": 4,
"id": "906022ec-96bf-41a9-9447-789d2e875250",
"metadata": {
"tags": []
@@ -301,7 +306,7 @@
"name": "stdout",
"output_type": "stream",
"text": [
- "Selected model mistral-7b with INT4 compression\n"
+ "Selected model qwen2-0.5b-instruct with INT4 compression\n"
]
}
],
@@ -312,6 +317,7 @@
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "62af3e8a-915a-49b4-8007-803777ba9eaf",
"metadata": {},
@@ -321,32 +327,26 @@
"\n",
"🤗 [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) is the interface between the 🤗 [Transformers](https://huggingface.co/docs/transformers/index) and [Diffusers](https://huggingface.co/docs/diffusers/index) libraries and OpenVINO to accelerate end-to-end pipelines on Intel architectures. It provides ease-to-use cli interface for exporting models to [OpenVINO Intermediate Representation (IR)](https://docs.openvino.ai/2024/documentation/openvino-ir-format.html) format.\n",
"\n",
+ "\n",
+ " Click here to read more about Optimum CLI usage
\n",
+ "\n",
"The command bellow demonstrates basic command for model export with `optimum-cli`\n",
"\n",
"```\n",
"optimum-cli export openvino --model --task \n",
"```\n",
"\n",
- "where `--model` argument is model id from HuggingFace Hub or local directory with model (saved using `.save_pretrained` method), `--task ` is one of [supported task](https://huggingface.co/docs/optimum/exporters/task_manager) that exported model should solve. For LLMs it will be `text-generation-with-past`. If model initialization requires to use remote code, `--trust-remote-code` flag additionally should be passed."
- ]
- },
- {
- "cell_type": "markdown",
- "id": "13694bf8-ee7b-4186-a3e0-a8705be9733c",
- "metadata": {},
- "source": [
- "## Compress model weights\n",
- "[back to top ⬆️](#Table-of-contents:)\n",
- "\n",
- "\n",
- "\n",
- "The [Weights Compression](https://docs.openvino.ai/2024/openvino-workflow/model-optimization-guide/weight-compression.html) algorithm is aimed at compressing the weights of the models and can be used to optimize the model footprint and performance of large models where the size of weights is relatively larger than the size of activations, for example, Large Language Models (LLM). Compared to INT8 compression, INT4 compression improves performance even more, but introduces a minor drop in prediction quality.\n",
- "\n",
+ "where `--model` argument is model id from HuggingFace Hub or local directory with model (saved using `.save_pretrained` method), `--task ` is one of [supported task](https://huggingface.co/docs/optimum/exporters/task_manager) that exported model should solve. For LLMs it is recommended to use `text-generation-with-past`. If model initialization requires to use remote code, `--trust-remote-code` flag additionally should be passed.\n",
+ " \n",
"\n",
"### Weights Compression using Optimum-CLI\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
- "You can also apply fp16, 8-bit or 4-bit weight compression on the Linear, Convolutional and Embedding layers when exporting your model with the CLI by setting `--weight-format` to respectively fp16, int8 or int4. This type of optimization allows to reduce the memory footprint and inference latency.\n",
+ "You can also apply fp16, 8-bit or 4-bit weight compression on the Linear, Convolutional and Embedding layers when exporting your model with the CLI. \n",
+ "\n",
+ " Click here to read more about weights compression with Optimum CLI
\n",
+ "\n",
+ "Setting `--weight-format` to respectively fp16, int8 or int4. This type of optimization allows to reduce the memory footprint and inference latency.\n",
"By default the quantization scheme for int8/int4 will be [asymmetric](https://github.com/openvinotoolkit/nncf/blob/develop/docs/compression_algorithms/Quantization.md#asymmetric-quantization), to make it [symmetric](https://github.com/openvinotoolkit/nncf/blob/develop/docs/compression_algorithms/Quantization.md#symmetric-quantization) you can add `--sym`.\n",
"\n",
"For INT4 quantization you can also specify the following arguments :\n",
@@ -354,38 +354,17 @@
"- The `--ratio` parameter controls the ratio between 4-bit and 8-bit quantization. If set to 0.9, it means that 90% of the layers will be quantized to int4 while 10% will be quantized to int8.\n",
"\n",
"Smaller group_size and ratio values usually improve accuracy at the sacrifice of the model size and inference latency.\n",
- "\n",
- ">**Note**: There may be no speedup for INT4/INT8 compressed models on dGPU."
- ]
- },
- {
- "cell_type": "markdown",
- "id": "f2f46ffd",
- "metadata": {},
- "source": [
- "### Weight compression with AWQ\n",
- "[back to top ⬆️](#Table-of-contents:)\n",
- "\n",
- "[Activation-aware Weight Quantization](https://arxiv.org/abs/2306.00978) (AWQ) is an algorithm that tunes model weights for more accurate INT4 compression. It slightly improves generation quality of compressed LLMs, but requires significant additional time for tuning weights on a calibration dataset. We use `wikitext-2-raw-v1/train` subset of the [Wikitext](https://huggingface.co/datasets/Salesforce/wikitext) dataset for calibration.\n",
- "\n",
- "Below you can enable AWQ to be additionally applied during model export with INT4 precision.\n",
+ "You can enable AWQ to be additionally applied during model export with INT4 precision using `--awq` flag and providing dataset name with `--dataset`parameter (e.g. `--dataset wikitext2`)\n",
"\n",
">**Note**: Applying AWQ requires significant memory and time.\n",
"\n",
- ">**Note**: It is possible that there will be no matching patterns in the model to apply AWQ, in such case it will be skipped."
- ]
- },
- {
- "cell_type": "markdown",
- "id": "130a037a-7d98-4152-81ea-92ffb01da5a2",
- "metadata": {},
- "source": [
- "We can now save floating point and compressed model variants"
+ ">**Note**: It is possible that there will be no matching patterns in the model to apply AWQ, in such case it will be skipped.\n",
+ " "
]
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 5,
"id": "c4ef9112",
"metadata": {
"collapsed": false,
@@ -394,7 +373,15 @@
},
"tags": []
},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "✅ INT4 qwen2-0.5b-instruct model already converted and can be found in qwen2/INT4_compressed_weights\n"
+ ]
+ }
+ ],
"source": [
"from llm_config import convert_and_compress_model\n",
"\n",
@@ -402,6 +389,7 @@
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "671a17d4",
"metadata": {
@@ -415,12 +403,20 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 6,
"id": "281f1d07-998e-4e13-ba95-0264564ede82",
"metadata": {
"tags": []
},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Size of model with INT4 compressed weights is 358.86 MB\n"
+ ]
+ }
+ ],
"source": [
"from llm_config import compare_model_size\n",
"\n",
@@ -428,24 +424,39 @@
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "6d62f9f4-5434-4550-b372-c86b5a5089d5",
"metadata": {},
"source": [
- "##### Select device for inference and model variant\n",
- "[back to top ⬆️](#Table-of-contents:)\n",
- "\n",
- ">**Note**: There may be no speedup for INT4/INT8 compressed models on dGPU."
+ "## Select device for inference\n",
+ "[back to top ⬆️](#Table-of-contents:)"
]
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 7,
"id": "837b4a3b-ccc3-4004-9577-2b2c7b802dea",
"metadata": {
"tags": []
},
- "outputs": [],
+ "outputs": [
+ {
+ "data": {
+ "application/vnd.jupyter.widget-view+json": {
+ "model_id": "bd7063e94441430e800e31760658c553",
+ "version_major": 2,
+ "version_minor": 0
+ },
+ "text/plain": [
+ "Dropdown(description='Device:', options=('CPU', 'AUTO'), value='CPU')"
+ ]
+ },
+ "execution_count": 7,
+ "metadata": {},
+ "output_type": "execute_result"
+ }
+ ],
"source": [
"from notebook_utils import device_widget\n",
"\n",
@@ -455,6 +466,7 @@
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "c53001e7-615f-4eb5-b831-4e2b2ff32826",
"metadata": {
@@ -465,6 +477,7 @@
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "f7f63327-f0f5-4e2d-bfc2-0f764f8c19a8",
"metadata": {},
@@ -474,29 +487,46 @@
"\n",
"[OpenVINO Generate API](https://github.com/openvinotoolkit/openvino.genai/blob/master/src/README.md) can be used to create pipelines to run an inference with OpenVINO Runtime. \n",
"\n",
- "Firstly we need to create pipeline with `LLMPipeline`. `LLMPipeline` is the main object used for decoding. You can construct it straight away from the folder with the converted model. It will automatically load the `main model`, `tokenizer`, `detokenizer` and default `generation configuration`. We will provide directory with model and device for `LLMPipeline`.\n",
- "After that we will configure parameters for decoding. We can get default config with `get_generation_config()`, setup parameters and apply the updated version with `set_generation_config(config)` or put config directly to `generate()`. It's also possible to specify the needed options just as inputs in the `generate()` method, as shown below.\n",
- "Then we just run `generate` method and get the output in text format. We do not need to encode input prompt according to model expected template or write post-processing code for logits decoder, it will be done easily with LLMPipeline."
+ "Firstly we need to create a pipeline with `LLMPipeline`. `LLMPipeline` is the main object used for text generation using LLM in OpenVINO GenAI API. You can construct it straight away from the folder with the converted model. We will provide directory with model and device for `LLMPipeline`. Then we run `generate` method and get the output in text format.\n",
+ "Additionally, we can configure parameters for decoding. We can get the default config with `get_generation_config()`, setup parameters, and apply the updated version with `set_generation_config(config)` or put config directly to `generate()`. It's also possible to specify the needed options just as inputs in the `generate()` method, as shown below, e.g. we can add `max_new_tokens` to stop generation if a specified number of tokens is generated and the end of generation is not reached. We will discuss some of the available generation parameters more deeply later."
]
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 8,
"id": "7a041101-7336-40fd-96c9-cd298015a0f3",
"metadata": {
"tags": []
},
- "outputs": [],
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "Loading model from qwen2/INT4_compressed_weights\n",
+ "\n",
+ "Input text: The Sun is yellow bacause\n",
+ " it is made of hydrogen and oxygen atoms. The\n"
+ ]
+ }
+ ],
"source": [
"from openvino_genai import LLMPipeline\n",
+ "\n",
"print(f\"Loading model from {model_dir}\\n\")\n",
"\n",
"\n",
"pipe = LLMPipeline(str(model_dir), device.value)\n",
- "print(pipe.generate(\"The Sun is yellow bacause\", temperature=1.2, top_k=4, do_sample=True, max_new_tokens=10))"
+ "\n",
+ "generation_config = pipe.get_generation_config()\n",
+ "\n",
+ "input_prompt = \"The Sun is yellow bacause\"\n",
+ "print(f\"Input text: {input_prompt}\")\n",
+ "print(pipe.generate(input_prompt, max_new_tokens=10))"
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "24d622d0-be46-47c0-a762-88cb50ab15a9",
"metadata": {},
@@ -505,21 +535,35 @@
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"Now, when model created, we can setup Chatbot interface using [Gradio](https://www.gradio.app/).\n",
+ "\n",
+ "\n",
+ " Click here to see how pipeline works
\n",
+ "\n",
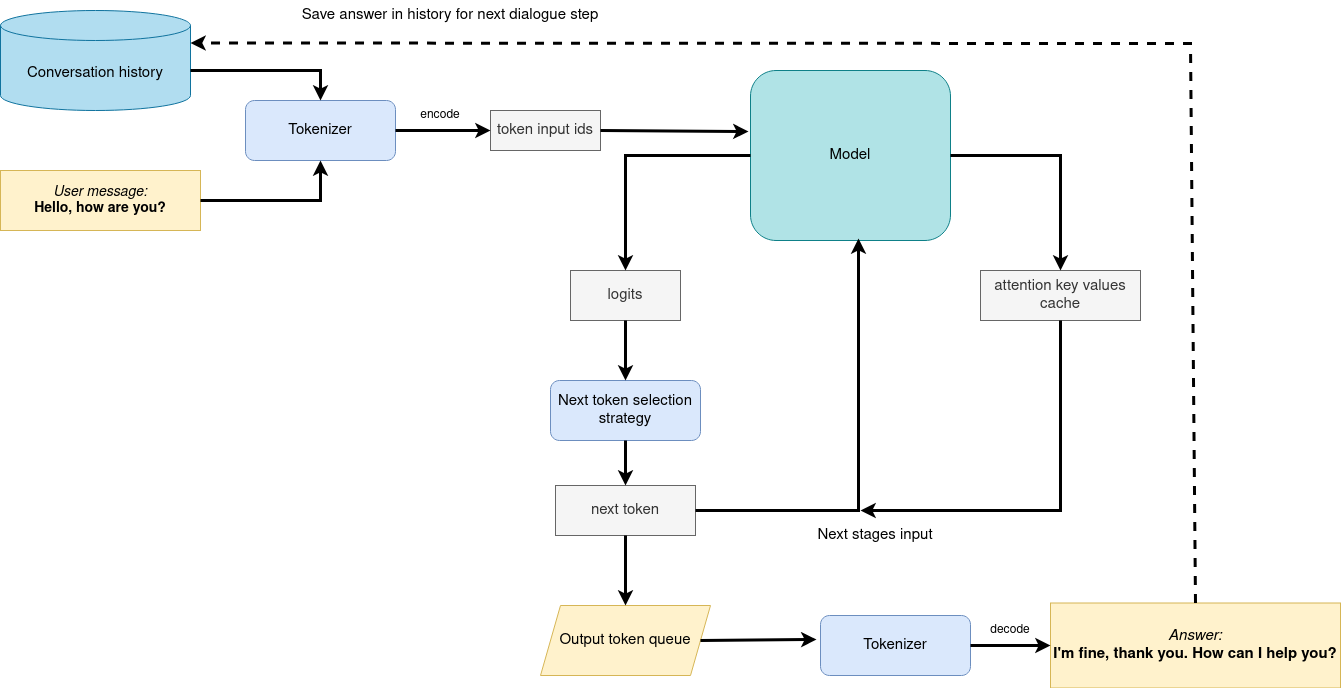
"The diagram below illustrates how the chatbot pipeline works\n",
"\n",
- "\n",
+ "\n",
+ "\n",
+ "As you can see, user input question passed via tokenizer to apply chat-specific formatting (chat template) and turn the provided string into the numeric format. [OpenVINO Tokenizers](https://github.com/openvinotoolkit/openvino_tokenizers) are used for these purposes inside `LLMPipeline`. You can find more detailed info about tokenization theory and OpenVINO Tokenizers in this [tutorial](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/openvino-tokenizers/openvino-tokenizers.ipynb). Then tokenized input passed to LLM for making prediction of next token probability. The way the next token will be selected over predicted probabilities is driven by the selected decoding methodology. You can find more information about the most popular decoding methods in this [blog](https://huggingface.co/blog/how-to-generate). The sampler's goal is to select the next token id is driven by generation configuration. Next, we apply stop generation condition to check the generation is finished or not (e.g. if we reached the maximum new generated tokens or the next token id equals to end of the generation). If the end of the generation is not reached, then new generated token id is used as the next iteration input, and the generation cycle repeats until the condition is not met. When stop generation criteria are met, then OpenVINO Detokenizer decodes generated token ids to text answer. \n",
"\n",
- "As can be seen, the pipeline very similar to instruction-following with only changes that previous conversation history additionally passed as input with next user question for getting wider input context. On the first iteration, it is provided instructions joined to conversation history (if exists) converted to token ids using a tokenizer, then prepared input provided to the model. The model generates probabilities for all tokens in logits format. The way the next token will be selected over predicted probabilities is driven by the selected decoding methodology. You can find more information about the most popular decoding methods in this [blog](https://huggingface.co/blog/how-to-generate). The result generation updates conversation history for next conversation step. It makes stronger connection of next question with previously provided and allows user to make clarifications regarding previously provided answers. [More about that, please, see here.](https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide.html)\n",
+ "The difference between chatbot and instruction-following pipelines is that the model should have \"memory\" to find correct answers on the chain of connected questions. OpenVINO GenAI uses `KVCache` representation for maintain a history of conversation. By default, `LLMPipeline` resets `KVCache` after each `generate` call. To keep conversational history, we should move LLMPipeline to chat mode using `start_chat()` method.\n",
"\n",
- "To make experience easier, we will use [OpenVINO Generate API](https://github.com/openvinotoolkit/openvino.genai/blob/master/src/README). Firstly we will create pipeline with `LLMPipeline`. `LLMPipeline` is the main object used for decoding. You can construct it straight away from the folder with the converted model. It will automatically load the main model, tokenizer, detokenizer and default generation configuration. After that we will configure parameters for decoding. We can get default config with `get_generation_config()`, setup parameters and apply the updated version with `set_generation_config(config)` or put config directly to `generate()`. It's also possible to specify the needed options just as inputs in the `generate()` method, as shown below. Then we just run `generate` method and get the output in text format. We do not need to encode input prompt according to model expected template or write post-processing code for logits decoder, it will be done easily with `LLMPipeline`.\n"
+ "More info about OpenVINO LLM inference can be found in [LLM Inference Guide](https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide.html)\n",
+ " "
]
},
{
+ "attachments": {},
"cell_type": "markdown",
"id": "725544ea-05ec-40d7-bbbc-1dc87cf57d04",
"metadata": {},
"source": [
- "There are several parameters that can control text generation quality: \n",
+ "### Advanced generation options\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "\n",
+ " Click here to see detailed description of advanced options
\n",
+ "\n",
+ "There are several parameters that can control text generation quality, \n",
" * `Temperature` is a parameter used to control the level of creativity in AI-generated text. By adjusting the `temperature`, you can influence the AI model's probability distribution, making the text more focused or diverse. \n",
" Consider the following example: The AI model has to complete the sentence \"The cat is ____.\" with the following token probabilities: \n",
"\n",
@@ -538,29 +582,8 @@
" - **Medium top_p** (e.g., 0.8): The AI model considers tokens with a higher cumulative probability, such as \"playing,\" \"sleeping,\" and \"eating.\" \n",
" - **High top_p** (e.g., 1.0): The AI model considers all tokens, including those with lower probabilities, such as \"driving\" and \"flying.\" \n",
" * `Top-k` is an another popular sampling strategy. In comparison with Top-P, which chooses from the smallest possible set of words whose cumulative probability exceeds the probability P, in Top-K sampling K most likely next words are filtered and the probability mass is redistributed among only those K next words. In our example with cat, if k=3, then only \"playing\", \"sleeping\" and \"eating\" will be taken into account as possible next word.\n",
- " * `Repetition Penalty` This parameter can help penalize tokens based on how frequently they occur in the text, including the input prompt. A token that has already appeared five times is penalized more heavily than a token that has appeared only one time. A value of 1 means that there is no penalty and values larger than 1 discourage repeated tokens.https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide.html"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "02a5f000",
- "metadata": {},
- "source": [
- "### Prepare text streamer to get results runtime\n",
- "[back to top ⬆️](#Table-of-contents:)\n",
- "\n",
- "Load the `detokenizer`, use it to convert token_id to string output format. We will collect print-ready text in a queue and give the text when it is needed. It will help estimate performance."
- ]
- },
- {
- "cell_type": "markdown",
- "id": "68f076b8",
- "metadata": {},
- "source": [
- "### Setup of the chatbot life process function\n",
- "[back to top ⬆️](#Table-of-contents:)\n",
- "\n",
- "`bot` function is the entry point for starting chat. We setup config here, collect history to string and put it to `generate()` method. After that it's generate new chatbot message and we add it to history."
+ " * `Repetition Penalty` This parameter can help penalize tokens based on how frequently they occur in the text, including the input prompt. A token that has already appeared five times is penalized more heavily than a token that has appeared only one time. A value of 1 means that there is no penalty and values larger than 1 discourage repeated tokens.\n",
+ " "
]
},
{
@@ -574,34 +597,15 @@
"source": [
"from genai_gradio_helper import get_gradio_helper\n",
"\n",
- "demo = get_gradio_helper(pipe, model_configuration, model_id, lang.value)\n",
+ "demo = get_gradio_helper(pipe, model_configuration, model_id, lang.value)\n",
"\n",
- "demo.launch()"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 10,
- "id": "7b837f9e-4152-4a5c-880a-ed874aa64a74",
- "metadata": {
- "tags": []
- },
- "outputs": [],
- "source": [
- "# please uncomment and run this cell for stopping gradio interface\n",
- "# demo.close()"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "d69ca0a2",
- "metadata": {},
- "source": [
- "### Next Step\n",
- "[back to top ⬆️](#Table-of-contents:)\n",
- "\n",
- "\n",
- "Besides chatbot, we can use LangChain to augmenting LLM knowledge with additional data, which allow you to build AI applications that can reason about private data or data introduced after a model’s cutoff date. You can find this solution in [Retrieval-augmented generation (RAG) example](../llm-rag-langchain/)."
+ "try:\n",
+ " demo.launch(debug=True)\n",
+ "except Exception:\n",
+ " demo.launch(debug=True, share=True)\n",
+ "# if you are launching remotely, specify server_name and server_port\n",
+ "# demo.launch(server_name='your server name', server_port='server port in int')\n",
+ "# Read more in the docs: https://gradio.app/docs/"
]
}
],
@@ -642,412 +646,7 @@
},
"widgets": {
"application/vnd.jupyter.widget-state+json": {
- "state": {
- "067a100f2bd4465f81da4fd9ab3f5adc": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DropdownModel",
- "state": {
- "_options_labels": [
- "CPU",
- "AUTO"
- ],
- "description": "Device:",
- "index": 0,
- "layout": "IPY_MODEL_53027f0d6b374cb5841140902de60009",
- "style": "IPY_MODEL_5db48946f9be480eacb6a06a4c4aec21"
- }
- },
- "0e2af61bbb5b4996822fa9ef3ff61982": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DropdownModel",
- "state": {
- "_options_labels": [
- "English",
- "Chinese",
- "Japanese"
- ],
- "index": 1,
- "layout": "IPY_MODEL_77a5f36926204d569500ff759046d572",
- "style": "IPY_MODEL_ed7fe4055ab24bf7a0c17df02f4f9b82"
- }
- },
- "1064af17a7104e6a998e65e864b14510": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DropdownModel",
- "state": {
- "_options_labels": [
- "CPU",
- "AUTO"
- ],
- "description": "Device:",
- "index": 0,
- "layout": "IPY_MODEL_7b12e62dd6904bbe85813f22eaff95f4",
- "style": "IPY_MODEL_4fa495c0d02d45a88f1b978a6fb97672"
- }
- },
- "24220aea0f034c0f8b5922eb246c6176": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "323f65aa9e7a455db32de98a018c5eba": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "LabelStyleModel",
- "state": {
- "description_width": "",
- "font_family": null,
- "font_size": null,
- "font_style": null,
- "font_variant": null,
- "font_weight": null,
- "text_color": null,
- "text_decoration": null
- }
- },
- "3560954cbdb1401eb374b120d04eb3ef": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "4384efc9d084421988415647aa5e2ffb": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DropdownModel",
- "state": {
- "_options_labels": [
- "INT4",
- "INT4-AWQ",
- "INT8",
- "FP16"
- ],
- "index": 0,
- "layout": "IPY_MODEL_9475b177a77843818dc6e133263ff44b",
- "style": "IPY_MODEL_6a5821b013fb4cdb912ec1bce8fec625"
- }
- },
- "44dcc989843e4185b6f21934d54318e7": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "LabelModel",
- "state": {
- "layout": "IPY_MODEL_24220aea0f034c0f8b5922eb246c6176",
- "style": "IPY_MODEL_ef174221ce394b4d9536044121a2014e",
- "value": "Language:"
- }
- },
- "464ac433f7bb48bf8badf59b5402cd9d": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DropdownModel",
- "state": {
- "_options_labels": [
- "qwen1.5-0.5b-chat",
- "qwen2-1.5b-instruct",
- "qwen2-7b-instruct",
- "qwen1.5-7b-chat",
- "qwen-7b-chat",
- "chatglm3-6b",
- "glm-4-9b-chat",
- "baichuan2-7b-chat",
- "minicpm-2b-dpo",
- "internlm2-chat-1.8b",
- "qwen1.5-1.8b-chat"
- ],
- "index": 0,
- "layout": "IPY_MODEL_d70ae93f79de4b8c91efe096c7f0a1b3",
- "style": "IPY_MODEL_bb5331008108429da33c572e220e9cfd"
- }
- },
- "4d7d47d24c4a42f699f0a32e81c14fe4": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "BoxModel",
- "state": {
- "children": [
- "IPY_MODEL_f6ac7672e6844a61b2a6310765a1b743",
- "IPY_MODEL_bc50a1e98bce46b79c3ecb299e91bb34",
- "IPY_MODEL_5cdc0a289da0418e855f9067d52455f9",
- "IPY_MODEL_76dbadf630504ecfb60d6549ab9a8471"
- ],
- "layout": "IPY_MODEL_b599bb1053bb405bb0ee9ae49e1019f0"
- }
- },
- "4fa495c0d02d45a88f1b978a6fb97672": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "description_width": ""
- }
- },
- "53027f0d6b374cb5841140902de60009": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "545d4571c96740249e0fe869e9c2f145": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "5cdc0a289da0418e855f9067d52455f9": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "BoxModel",
- "state": {
- "children": [
- "IPY_MODEL_e33379d2d81046408230524a621a5188",
- "IPY_MODEL_4384efc9d084421988415647aa5e2ffb"
- ],
- "layout": "IPY_MODEL_bd0fe269b29a40e8b6413da6fcfdca88"
- }
- },
- "5db48946f9be480eacb6a06a4c4aec21": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "description_width": ""
- }
- },
- "6a5821b013fb4cdb912ec1bce8fec625": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "description_width": ""
- }
- },
- "6a8574b1acb347ff85cec4a5761ec9e1": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "76dbadf630504ecfb60d6549ab9a8471": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "BoxModel",
- "state": {
- "children": [
- "IPY_MODEL_b3e0b54f26474fcbb6e31ca69c034484",
- "IPY_MODEL_c56a20c7dd594d2283b5e8f4a7a73401"
- ],
- "layout": "IPY_MODEL_dca19a43a4c145b8a51302d86dd932aa"
- }
- },
- "77a5f36926204d569500ff759046d572": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "7b12e62dd6904bbe85813f22eaff95f4": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "89ce417807834a43b44e79296b75ebd3": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "9475b177a77843818dc6e133263ff44b": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "9cc5b7cf46634de9b888c9976968f0e6": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "CheckboxStyleModel",
- "state": {
- "description_width": ""
- }
- },
- "b3e0b54f26474fcbb6e31ca69c034484": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "LabelModel",
- "state": {
- "layout": "IPY_MODEL_6a8574b1acb347ff85cec4a5761ec9e1",
- "style": "IPY_MODEL_d9b3c38a73374fa1a9f16f2eb7858aee",
- "value": "Use preconverted models:"
- }
- },
- "b599bb1053bb405bb0ee9ae49e1019f0": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {
- "border_bottom": "solid 1px",
- "border_left": "solid 1px",
- "border_right": "solid 1px",
- "border_top": "solid 1px",
- "display": "flex",
- "flex_flow": "column",
- "padding": "1%",
- "width": "30%"
- }
- },
- "bb5331008108429da33c572e220e9cfd": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "description_width": ""
- }
- },
- "bc50a1e98bce46b79c3ecb299e91bb34": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "BoxModel",
- "state": {
- "children": [
- "IPY_MODEL_bdcf34e32aff4678827bdc44b9b1e045",
- "IPY_MODEL_464ac433f7bb48bf8badf59b5402cd9d"
- ],
- "layout": "IPY_MODEL_89ce417807834a43b44e79296b75ebd3"
- }
- },
- "bd0fe269b29a40e8b6413da6fcfdca88": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "bdcf34e32aff4678827bdc44b9b1e045": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "LabelModel",
- "state": {
- "layout": "IPY_MODEL_545d4571c96740249e0fe869e9c2f145",
- "style": "IPY_MODEL_323f65aa9e7a455db32de98a018c5eba",
- "value": "Model:"
- }
- },
- "c246af659ef84e0d84b817b490086474": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "c56a20c7dd594d2283b5e8f4a7a73401": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "CheckboxModel",
- "state": {
- "disabled": false,
- "layout": "IPY_MODEL_c246af659ef84e0d84b817b490086474",
- "style": "IPY_MODEL_9cc5b7cf46634de9b888c9976968f0e6",
- "value": true
- }
- },
- "cdee6dee6030420687eac2043dd99b8a": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "d70ae93f79de4b8c91efe096c7f0a1b3": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "d9b3c38a73374fa1a9f16f2eb7858aee": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "LabelStyleModel",
- "state": {
- "description_width": "",
- "font_family": null,
- "font_size": null,
- "font_style": null,
- "font_variant": null,
- "font_weight": null,
- "text_color": null,
- "text_decoration": null
- }
- },
- "dca19a43a4c145b8a51302d86dd932aa": {
- "model_module": "@jupyter-widgets/base",
- "model_module_version": "2.0.0",
- "model_name": "LayoutModel",
- "state": {}
- },
- "e33379d2d81046408230524a621a5188": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "LabelModel",
- "state": {
- "layout": "IPY_MODEL_cdee6dee6030420687eac2043dd99b8a",
- "style": "IPY_MODEL_ea95d4829c434113ae1a79a54568f984",
- "value": "Compression:"
- }
- },
- "ea95d4829c434113ae1a79a54568f984": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "LabelStyleModel",
- "state": {
- "description_width": "",
- "font_family": null,
- "font_size": null,
- "font_style": null,
- "font_variant": null,
- "font_weight": null,
- "text_color": null,
- "text_decoration": null
- }
- },
- "ed7fe4055ab24bf7a0c17df02f4f9b82": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "DescriptionStyleModel",
- "state": {
- "description_width": ""
- }
- },
- "ef174221ce394b4d9536044121a2014e": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "LabelStyleModel",
- "state": {
- "description_width": "",
- "font_family": null,
- "font_size": null,
- "font_style": null,
- "font_variant": null,
- "font_weight": null,
- "text_color": null,
- "text_decoration": null
- }
- },
- "f6ac7672e6844a61b2a6310765a1b743": {
- "model_module": "@jupyter-widgets/controls",
- "model_module_version": "2.0.0",
- "model_name": "BoxModel",
- "state": {
- "children": [
- "IPY_MODEL_44dcc989843e4185b6f21934d54318e7",
- "IPY_MODEL_0e2af61bbb5b4996822fa9ef3ff61982"
- ],
- "layout": "IPY_MODEL_3560954cbdb1401eb374b120d04eb3ef"
- }
- }
- },
+ "state": {},
"version_major": 2,
"version_minor": 0
}
diff --git a/utils/llm_config.py b/utils/llm_config.py
index 986a8e6250d..99bd6d273bf 100644
--- a/utils/llm_config.py
+++ b/utils/llm_config.py
@@ -537,12 +537,15 @@ def get_optimum_cli_command(model_id, weight_format, output_dir, compression_opt
command += " {}".format(output_dir)
return command
-default_language = 'English'
+
+default_language = "English"
SUPPORTED_OPTIMIZATIONS = ["INT4", "INT4-AWQ", "INT8", "FP16"]
+
def get_llm_selection_widget():
import ipywidgets as widgets
+
lang_drop_down = widgets.Dropdown(options=list(SUPPORTED_LLM_MODELS))
# Define dependent drop down
@@ -553,27 +556,33 @@ def dropdown_handler(change):
global default_language
default_language = change.new
# If statement checking on dropdown value and changing options of the dependent dropdown accordingly
- model_drop_down.options=SUPPORTED_LLM_MODELS[change.new]
- lang_drop_down.observe(dropdown_handler, names='value')
+ model_drop_down.options = SUPPORTED_LLM_MODELS[change.new]
+
+ lang_drop_down.observe(dropdown_handler, names="value")
compression_drop_down = widgets.Dropdown(options=SUPPORTED_OPTIMIZATIONS)
preconverted = widgets.Checkbox(value=True)
- form_items = [
- widgets.Box([widgets.Label(value='Language:'), lang_drop_down]),
- widgets.Box([widgets.Label(value='Model:'), model_drop_down]),
- widgets.Box([widgets.Label(value='Compression:'), compression_drop_down]),
- widgets.Box([widgets.Label(value="Use preconverted models:"), preconverted])
+ form_items = [
+ widgets.Box([widgets.Label(value="Language:"), lang_drop_down]),
+ widgets.Box([widgets.Label(value="Model:"), model_drop_down]),
+ widgets.Box([widgets.Label(value="Compression:"), compression_drop_down]),
+ widgets.Box([widgets.Label(value="Use preconverted models:"), preconverted]),
]
-
- form = widgets.Box(form_items, layout=widgets.Layout(
- display='flex',
- flex_flow='column',
- border='solid 1px',
- #align_items='stretch',
- width='30%',
- padding = '1%'))
+
+ form = widgets.Box(
+ form_items,
+ layout=widgets.Layout(
+ display="flex",
+ flex_flow="column",
+ border="solid 1px",
+ # align_items='stretch',
+ width="30%",
+ padding="1%",
+ ),
+ )
return form, lang_drop_down, model_drop_down, compression_drop_down, preconverted
+
def convert_tokenizer(model_id, remote_code, model_dir):
import openvino as ov
from transformers import AutoTokenizer
@@ -628,9 +637,8 @@ def convert_and_compress_model(model_id, model_config, precision, use_preconvert
print(f"✅ {precision} {model_id} model converted and can be found in {model_dir}")
return model_dir
-
+
def compare_model_size(model_dir):
-
fp16_weights = model_dir.parent / "FP16" / "openvino_model.bin"
int8_weights = model_dir.parent / "INT8_compressed_weights" / "openvino_model.bin"
int4_weights = model_dir.parent / "INT4_compressed_weights" / "openvino_model.bin"
@@ -642,4 +650,4 @@ def compare_model_size(model_dir):
if compressed_weights.exists():
print(f"Size of model with {precision} compressed weights is {compressed_weights.stat().st_size / 1024 / 1024:.2f} MB")
if compressed_weights.exists() and fp16_weights.exists():
- print(f"Compression rate for {precision} model: {fp16_weights.stat().st_size / compressed_weights.stat().st_size:.3f}")
\ No newline at end of file
+ print(f"Compression rate for {precision} model: {fp16_weights.stat().st_size / compressed_weights.stat().st_size:.3f}")