


- Getting Started
- Cleanup and processing of HTML table data
- Invalid and imperfect HTML
- Extracting HTML tables from files
- Extracting HTML tables from URLs
- Analyzing and visualizing scraped data
Pandas is one of the most popular Python libraries for data analysis. This library has many useful functions. One of such functions is pandas read_html. It can convert HTML tables into pandas DataFrame efficiently.
This tutorial will show you how useful pandas read_html can be, especially when combined with other helpful functions.
For a detailed explanation, see our blog post.
Pandas can be installed using the pip command or conda command if you’re using Anaconda.
pip3 install pandas
conda install pandasYou must also install lxml, html5lib, BeautifulSoup4, and Matplotlib libraries to facilitate reading & parsing the HTML and plotting the information.
Here are the pip commands to install:
pip3 install lxml
pip3 install html5lib
pip3 install BeautifulSoup4
pip3 install matplotlibIf you are using the conda prompt, use the following commands:
conda install lxml
conda install html5lib
conda install BeautifulSoup4
conda install matplotlibIn the following line of the code, a variable contains HTML. You should note that we’re using Python’s triple quote conventions to store multiline strings in a variable easily.
html = '''
<table>
<thead>
<tr>
<th>Sequence</th>
<th>Country</th>
<th>Population</th>
<th>Updated</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>China</td>
<td>1,439,323,776</td>
<td>1-Dec-2020</td>
</tr>
<tr>
<td>2</td>
<td>India</td>
<td>1,380,004,385</td>
<td>1-Dec-2020</td>
</tr>
<tr>
<td>3</td>
<td>United States</td>
<td>331,002,651</td>
<td>1-Dec-2020</td>
</tr>
</tbody>
</table>'''The next step is to import pandas and call the pandas read_html function:
import pandas as pd
df_list = pd.read_html(html) Note that the pandas read_html function returns a list of Pandas DataFrame objects. This can be verified by checking the length of the df_list variable:
print(len(df_list))
# OUTPUT: 1Let’s check the content of the DataFrame by printing it.
print(df_list[0])
When you run from the terminal, the data from HTML tables will be extracted and displayed as follows:
$ python3 read_html.py
Sequence Country Population Updated
0 1 China 1439323776 1-Dec-2020
1 2 India 1380004385 1-Dec-2020
2 3 United States 331002651 1-Dec-2020If you’re using Jupyter Notebook, the output of the same command will have a better appearance.
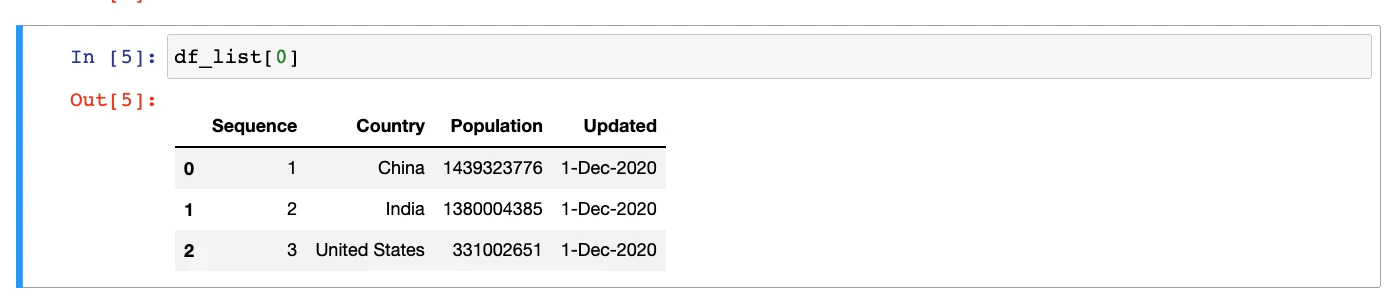
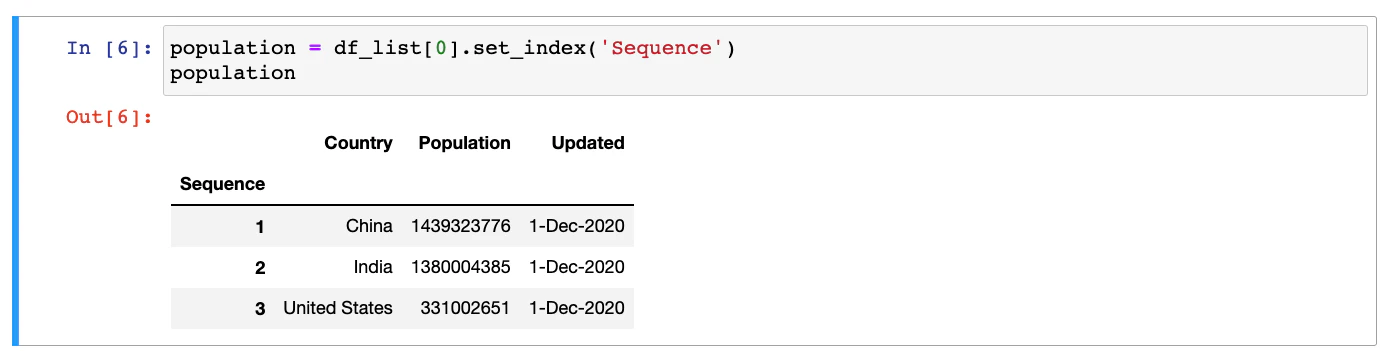
The index column can be easily updated by calling the set_index() function of the DataFrame:
population = df_list[0].set_index('Sequence')
Once again, let’s take a look at the output from the Jupyter Notebook of this new DataFrame.
The data types can be checked by calling info() function of the DataFrame as follows:
population.info()The output will be as follows:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 3 entries, 1 to 3
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Country 3 non-null object
1 Population 3 non-null int64
2 Updated 3 non-null object
dtypes: int64(1), object(2)Note the Dtype for the column Updated is object. It means that pandas read_html function didn’t understand that this column is date.
There are multiple ways to do this. The easiest of these methods is to use one more parameter of the pandas read_html function. This parameter is parse_dates:
pd.read_html(html, parse_dates=[3])
# OR
pd.read_html(html, parse_dates=['Updated'])This time, if the .info() function is called, the DataFrame will have correct data types:
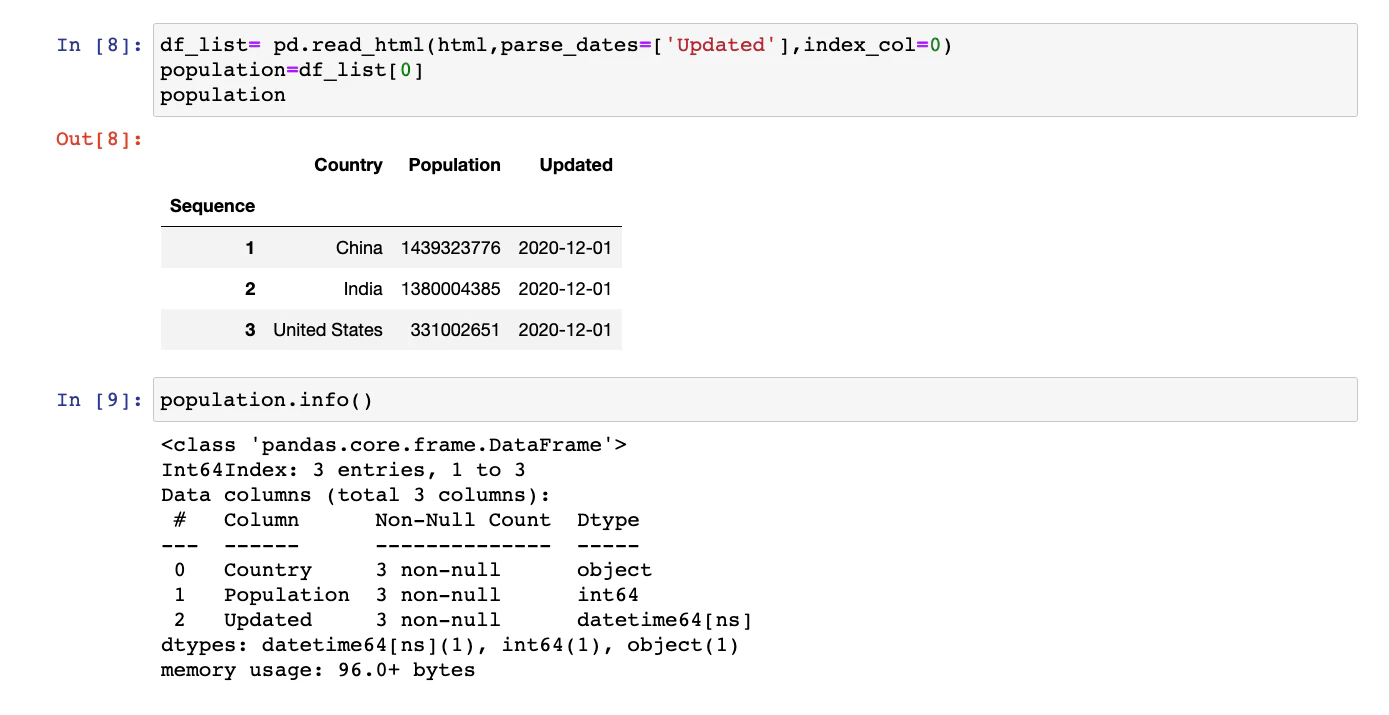
The HTML that we used in the previous example is valid. If the heading in the HTML table is embedded in regular <tr> and <td> tags, the DataFrame will be created with default numeric columns.
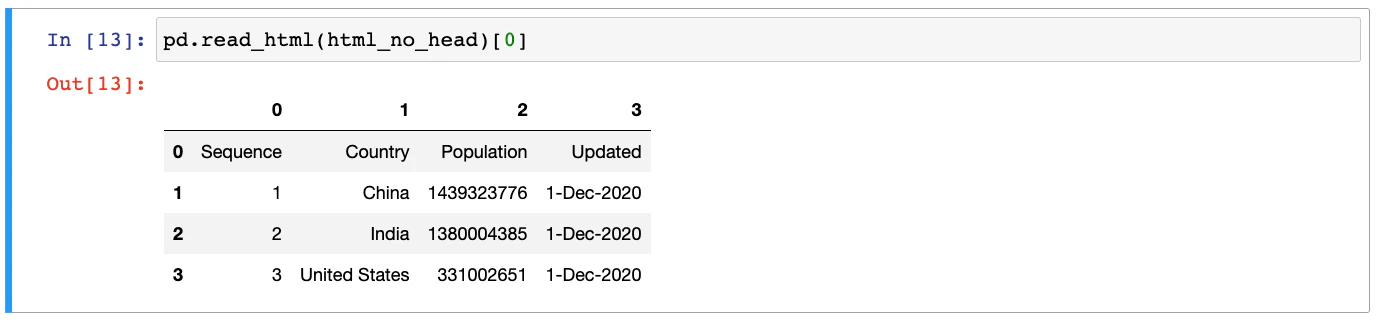
In such cases, you can use another optional parameter of pandas read_html method as follows:
pd.read_html(html_no_head,header=0)Extracting data from HTML tables that are in HTML files is almost the same as reading from strings.
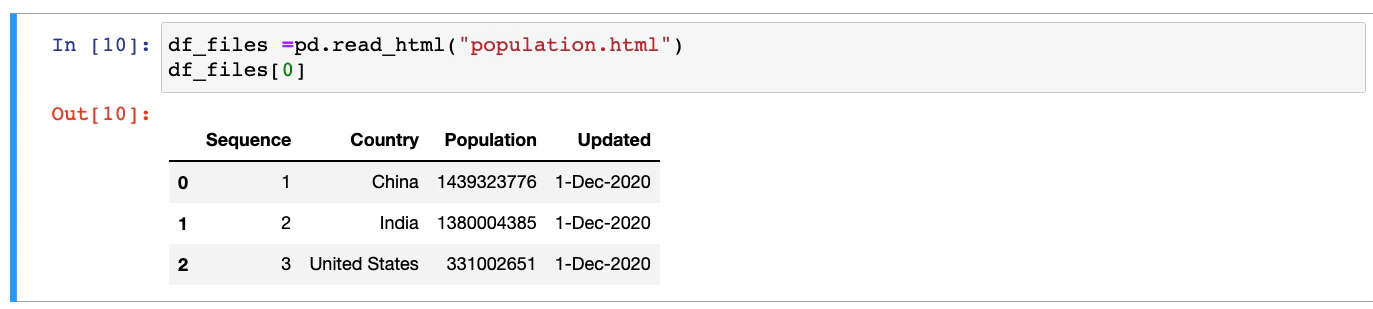
Instead of the HTML string, the pandas read_html needs the file path, relative or absolute. Assuming that the population.html file contains the HTML table with population information which is currently located in the tmp folder, we can read the HTML table as follows:
population_file= pd.read_html("/tmp/population.html",parse_dates=['Updated'],index_col=0)
population_file[0]
Pandas can directly connect to web URLs and read HTML tables. This functionality can be used for further Python web scraping.
The first step is to extract the list of tables using the Pandas read_html function. Next, we’ll check the length of the tables returned.
import pandas as pd
list_of_df = pd.read_html("https://en.wikipedia.org/w/index.php?title=Science_Fiction:_The_100_Best_Novels&oldid=1091082777")
len(list_of_df)
# OUTPUT: 7To get to the exact table, there are multiple approaches possible.
To use regular expressions, first, we need to identify any pattern inside the <table> that we want to scrape. Open the URL in a browser, right-click the table, and click inspect.
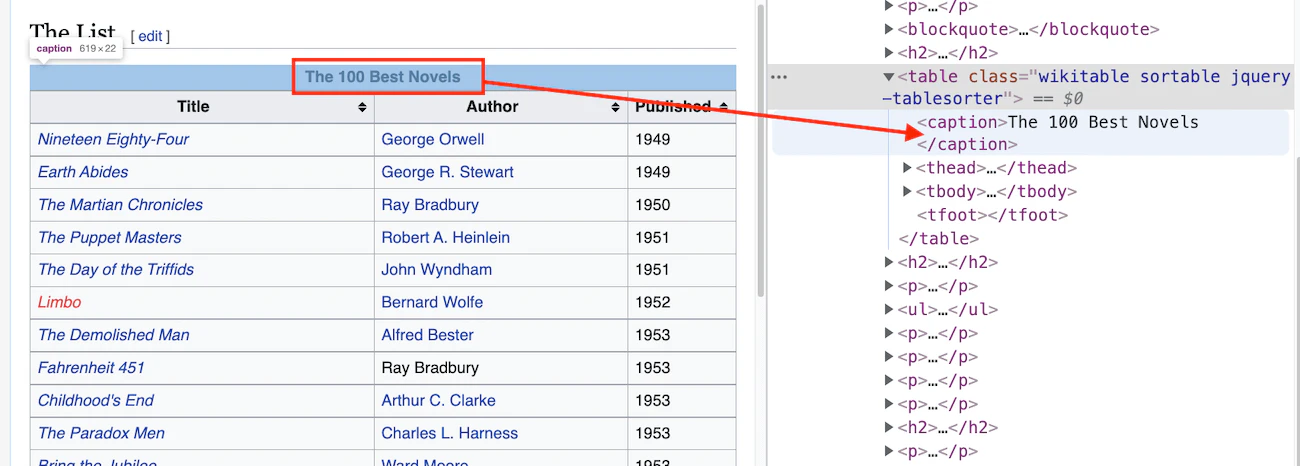
This regular expression can now be supplied to the optional parameter match of the pandas read_html function.
import pandas as pd
list_of_df = pd.read_html("https://en.wikipedia.org/w/index.php?title=Science_Fiction:_The_100_Best_Novels&oldid=1091082777", match='The 100 Best Novels')
len(list_of_df)
# OUTPUT: 1One more way to extract the required table is by using the specific attributes:
pd.read_html("https://en.wikipedia.org/w/index.php?title=Science_Fiction:_The_100_Best_Novels&oldid=1091082777", attrs={'class':"wikitable"})Let’s find the author who has written most of the books in this Top 100 list:
df=list_of_df[0]
df.value_counts(subset=['Author'])This will print the following pandas series:
Author
Philip K. Dick 6
J. G. Ballard 4
Robert A. Heinlein 3
Brian Aldiss 3
Thomas M. Disch 3
..It gives us the information that Philip K. Dick has written 6 books out of these 100 best books. If needed, you can also plot charts to represent the same information.
df = df.value_counts(subset=['Author']).reset_index(name='BookCount')The next step is to make a subset of this DataFrame, where authors have published 3 or more books out of these Top 100:
top_df = df[df['BookCount'] >= 3]
print(top_df)The output will be the following DataFrame:
Author BookCount
0 Philip K. Dick 6
1 J. G. Ballard 4
2 Robert A. Heinlein 3
3 Brian Aldiss 3
4 Thomas M. Disch 3And finally, this data can be plotted as a horizontal bar chart:
top_df.plot.barh(x='Author',y='BookCount',figsize=(12,5))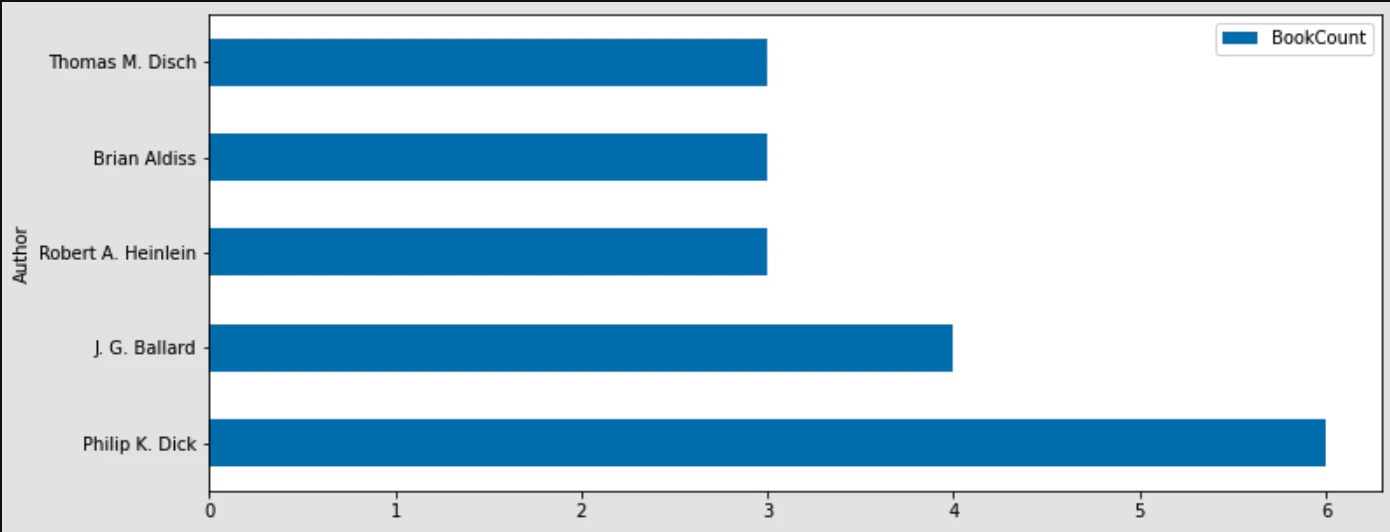
If you wish to find out more about How to Read HTML Tables with Pandas, see our blog post.