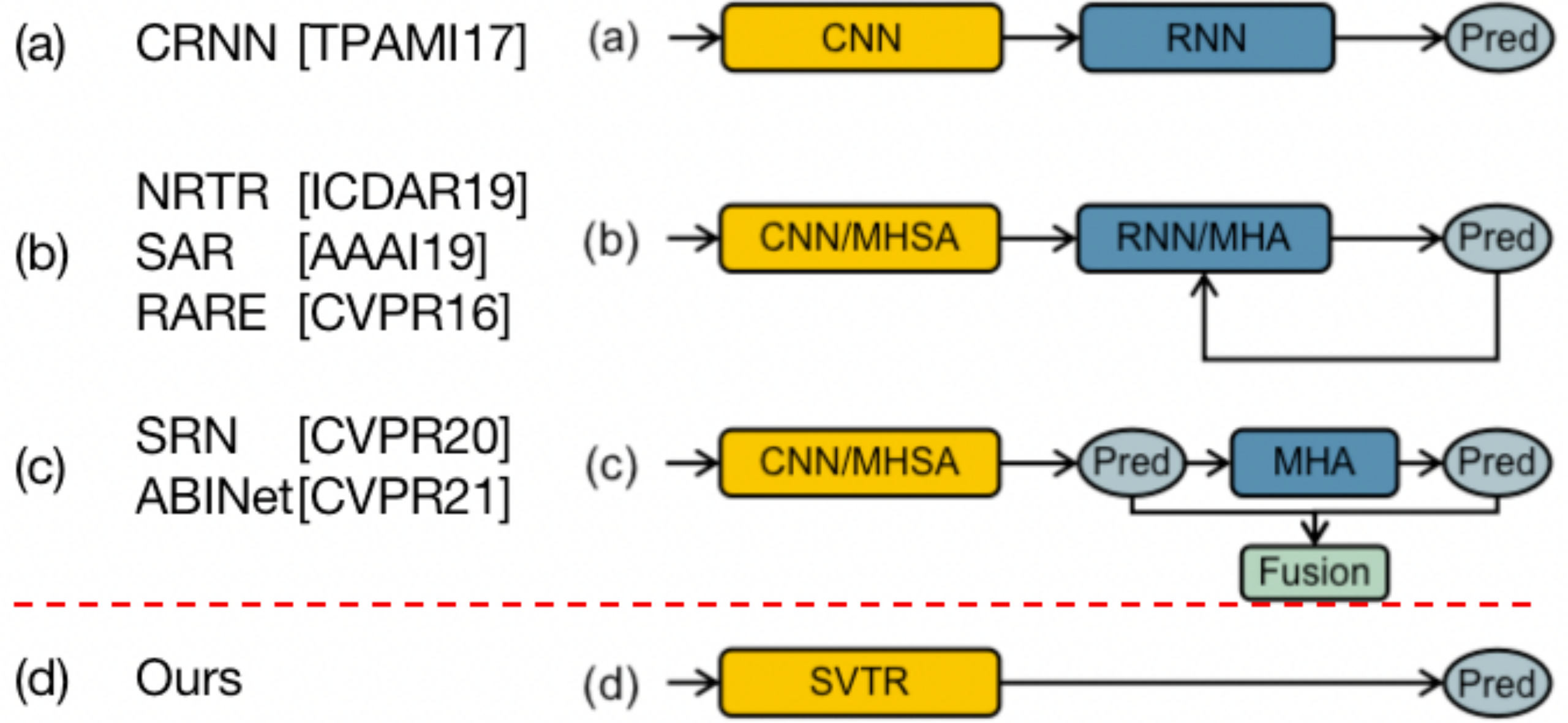
SVTR
不使用类语言解码器,仅使用单视觉模型,在中英文场景文字识别上都取得了较好效果,并且推理速度较快。单视觉模型需要做到以下几点,才有可能得到场景文本识别的关键特征,应对复杂的文本识别场景,提升识别精度:
1、单视觉模型应具备关注笔画特征的能力:文本字符是由若干个笔画组成,而对于一些相似的字符,如‘B’和‘8’、‘z’和‘2’、‘大’和‘太’等等,它们在形状上相似,但是在笔画上具有细微的差异,因此模型应具备关注字符笔画细节特征的能力,以更加准确的区分相似字符。
2、单视觉模型需捕捉到单个字符内局部特征和字符之间的长距离全局依赖:单个字符存在与整个文本图像中的局部位置,这需要单视觉模型具备提取局部特征的能力,同时在笔画特征的基础上建立单个字符内笔画的相关性;对于文本图像中的所有字符,它们不是相互孤立的,存在内在的联系,因此要求单视觉模型可以建立多个字符的长距离全局依赖;进一步的,图像文本包含了文本区域和非文本区域,因此在建立文本(多个字符)的全局特征基础上,需区分文本区域和非文本区域。

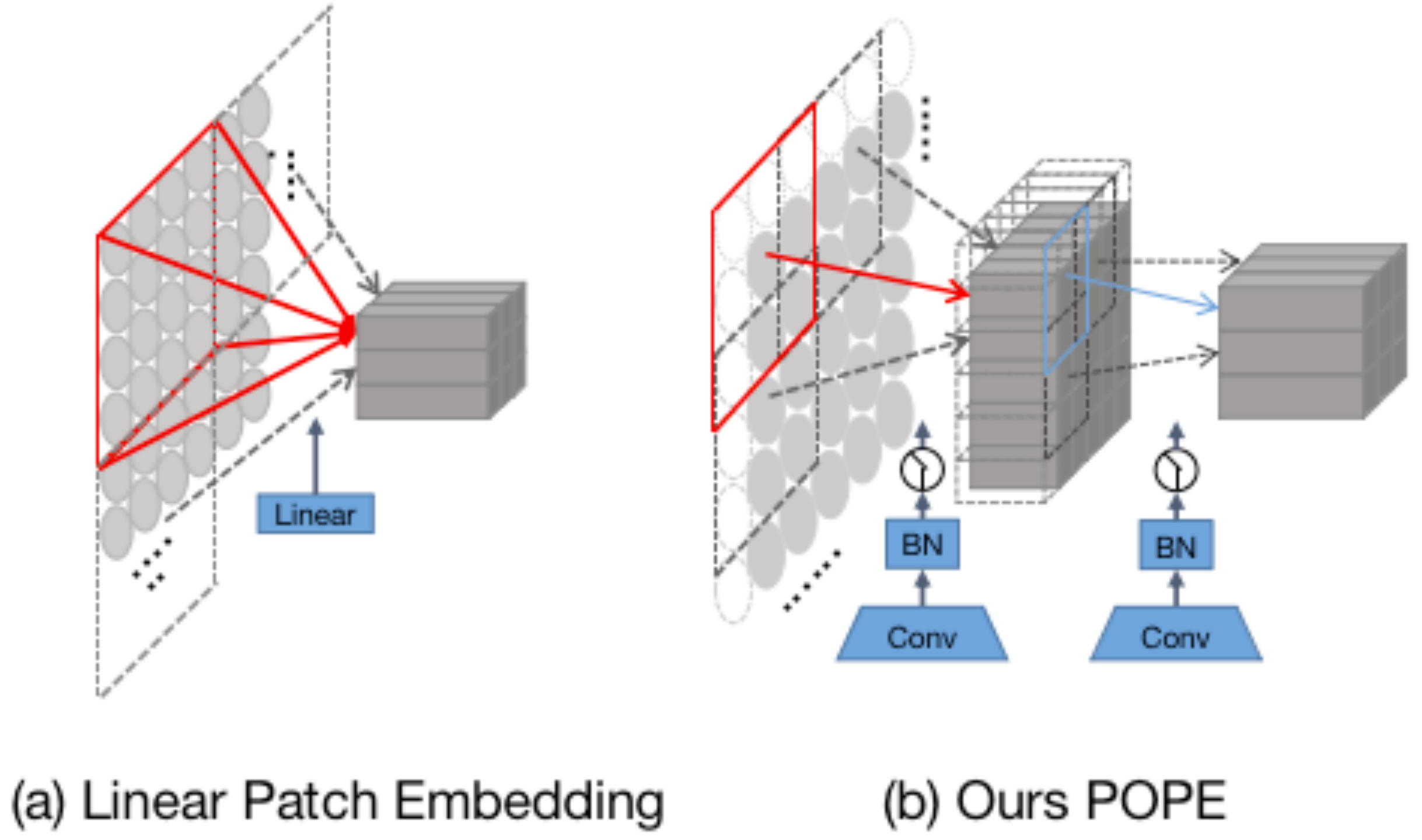
将文本图像拆分为若干个patches,每个patches表示了字符的一部分,被称为字符组件(character components),用于表示字符的笔画特征。我们通过两个级联的卷积模块实现Progressive Overlapping Patch Embedding(POPE)如图3(b),将输入 HW3的图像嵌入到 H/4 * W/4 *D0 字符组件中。
前面提到单视觉模型实现高精度文本识别需要两种特征:
- 局部细粒度特征:笔画特征、局部的字符形态特征、单个字符中笔画的相关性;
- 全局粗粒度特征:多个字符之间的相关性和文本区域与非文本区域之间的相关性。
因此,我们设计了具有不同感受野的两个混合块(Mixing Block)来完成这两种粒度特征的感知和提取。
- Global Mixing:如图4(a) 所示,Global Mixing感知所有字符组件之间的依赖关系,提取全局特征。此外它还能够削弱非文本区域中组件的影响,进一步提高文本区域中字符组件的重要性。具体地,我们使用 MHSA 和 MLP实现Mixing,整体结构借鉴Vision Transformer Unit。 Global Mixing层本质上就是一个Transformer block,由一个多头自注意层,一个Layer Norm 层,以及一个MLP层构成。通过自注意力机制的全局建模特性来进行全局字符建模。
- Local Mixing:如图4(b) 所示,Local Mixing感知预定义感受野领域(7*11)内组件之间的相关性,提取局部特征。其目标是对字符形态特征进行编码并建立字符内组件之间的关联,从而模拟对字符识别至关重要的笔画特征。Global Mixing层本质上就是一个Transformer block,由一个多头自注意层,一个Layer Norm 层,以及一个MLP层构成。通过自注意力机制的全局建模特性来进行全局字符建模。

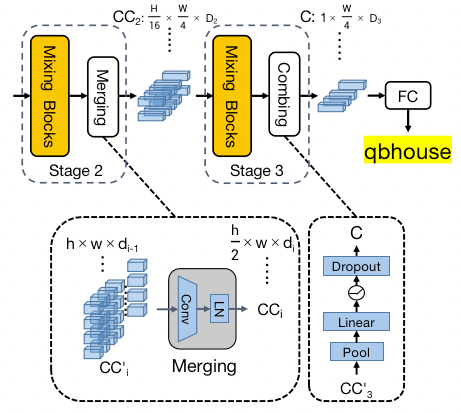
Merging:如果三个阶段保持恒定空间分辨率(H/4 * W/4),会带来很高的计算成本,这也会导致特征表示的冗余。它由对高度下采样的卷积实现,不仅降低了计算成本,而且还构建了适配文本图像的层次结构。我们增加了通道数(di=2*di-1)以补偿高度下采样带来的信息损失。
Combing & Predicting:在第三阶段,将高度池化(Pool)为 1,然后是全连接层、非线性激活和 dropout。通过这样做,字符组件被进一步压缩为特征序列,序列元素由维度为D3的特征所表示。使用合并后特征序列,我们通过简单的并行线性分类器来实现识别。对于英文识别,字符类别数N设置为37(数字+字母+空白字符),对于中文识别,N被设置为6625(数字+字母+简体字+繁体字+特殊符号+空白字符)。
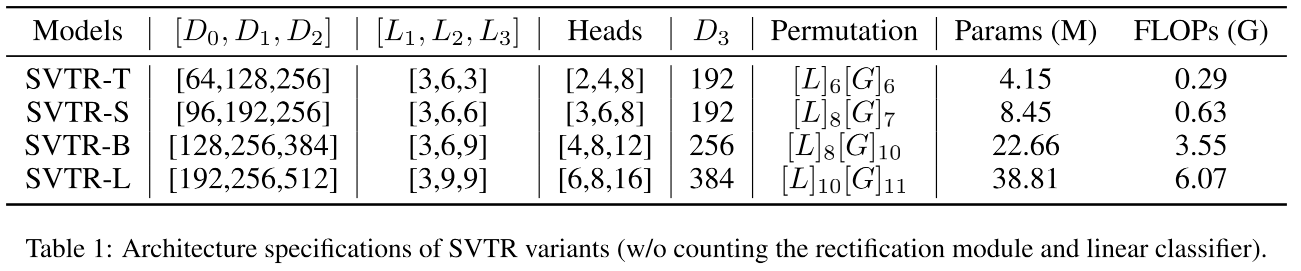
我们基于三个阶段的通道数和多头自注意力的head数、mixing block的个数的变换,得到了四种不同体积的网络(详细见表1):SVTR-T(Tiny)、SVTR-S(Small)、SVTR-B(Base)、SVTR-L(Large)。