mpify is a thin library to run function on multiple processes, and to help training model in PyTorch's Distributed Data Parallel mode within a Jupyter notebook running on a multi-GPU host.
The main features are:
- Parallel but blocking execution, call returns after all processes finish.
- Results from any or all of the workers can be gathered.
- No persistent worker pool to maintain. Each subprocess spawns-executes-terminates.
- Each spawned subprocess can create its own GPU context, suitable for multi-GPU host.
- Functions and objects created in the Jupyter notebook, can be passed to the worker subprocesses by name.
importstatements can be run in each subprocess before function execution.- Also works outside Jupyter, in batch Python app.
mpify is mainly for interactive multiprocessing where parameters and results can be passed between the Jupyter cell and worker subprocesses via simple function call semantics.
For asynchronous and/or remote workloads (on cluster), dask, ray, or ipyparallel
are better choices, as they can manage persistent process pool, job scheduling, fault-tolerance etc..
- Porting a training loop in Fastai2's notebook train in distributed data parallel mode:
Original:

mpify-ed:
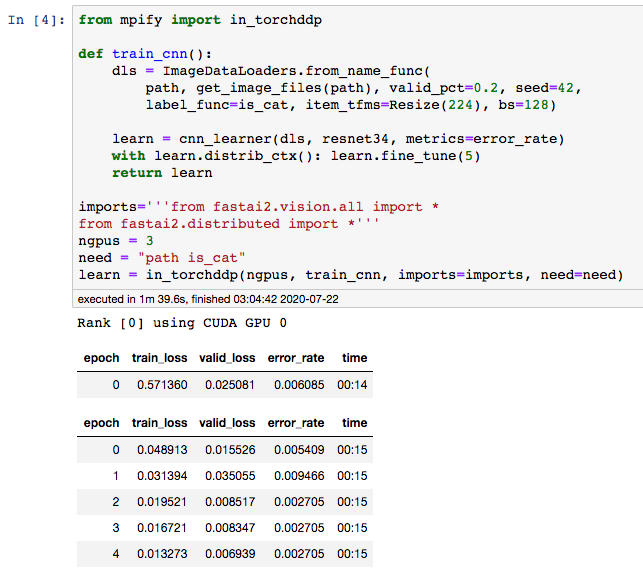
More notebook examples can be found in the [examples/](/examples) directory.
python3 -m pip install git+https://github.com/philtrade/mpify
The complete API documentation.
mpify was conceived to coordinate Python multiprocessing, Jupyter, and multiple CUDA GPUs on a single host.
- Why use multiprocess instead of multiprocessing and torch.multiprocessing: <https://hpc-carpentry.github.io/hpc-python/06-parallel/>
- On from module import * within a function: https://stackoverflow.com/questions/41990900/what-is-the-function-form-of-star-import-in-python-3