Démarrage rapide
Ce chapitre traite du démarrage rapide avec Git. Nous commencerons par expliquer les bases de la gestion de version, puis nous parlerons de l'installation de Git sur votre système et finalement comment le paramétrer pour commencer à l'utiliser. À la fin de ce chapitre vous devriez en savoir assez pour comprendre pourquoi on parle beaucoup de Git, pourquoi vous devriez l'utiliser et vous devriez en avoir une installation prête à l'emploi.
Qu'est-ce que la gestion de version et pourquoi devriez-vous vous en soucier ? Un gestionnaire de version est un système qui enregistre l'évolution d'un fichier ou d'un ensemble de fichiers au cours du temps de manière à ce qu'on puisse rappeler une version antérieure d'un fichier à tout moment. Dans les exemples de ce livre, nous utiliserons des fichiers sources de logiciel comme fichiers sous gestion de version, bien qu'en réalité on puisse l'utiliser avec pratiquement tous les types de fichiers d'un ordinateur.
Si vous êtes un dessinateur ou un développeur web, et que vous voulez conserver toutes les versions d'une image ou d'une mise en page (ce que vous souhaiteriez assurément), un système de gestion de version (VCS en anglais pour Version Control System) est un outil qu'il est très sage d'utiliser. Il vous permet de ramener un fichier à un état précédent, ramener le projet complet à un état précédent, comparer les changements au cours du temps, voir qui a modifié quelque chose qui pourrait causer un problème, qui a introduit un problème et quand, et plus encore. Utiliser un VCS signifie aussi généralement que si vous vous trompez ou que vous perdez des fichiers, vous pouvez facilement revenir à un état stable. De plus, vous obtenez tous ces avantages avec une faible surcharge de travail.
La méthode commune pour la gestion de version est généralement de recopier les fichiers dans un autre répertoire (peut-être avec un nom incluant la date dans le meilleur des cas). Cette méthode est la plus commune parce que c'est la plus simple, mais c'est aussi la moins fiable. Il est facile d'oublier le répertoire dans lequel vous êtes et d'écrire accidentellement dans le mauvais fichier ou d'écraser des fichiers que vous vouliez conserver.
Pour traiter ce problème, les programmeurs ont développé il y a longtemps des VCSs locaux qui utilisaient une base de données simple pour conserver les modifications d'un fichier (voir figure 1-1).
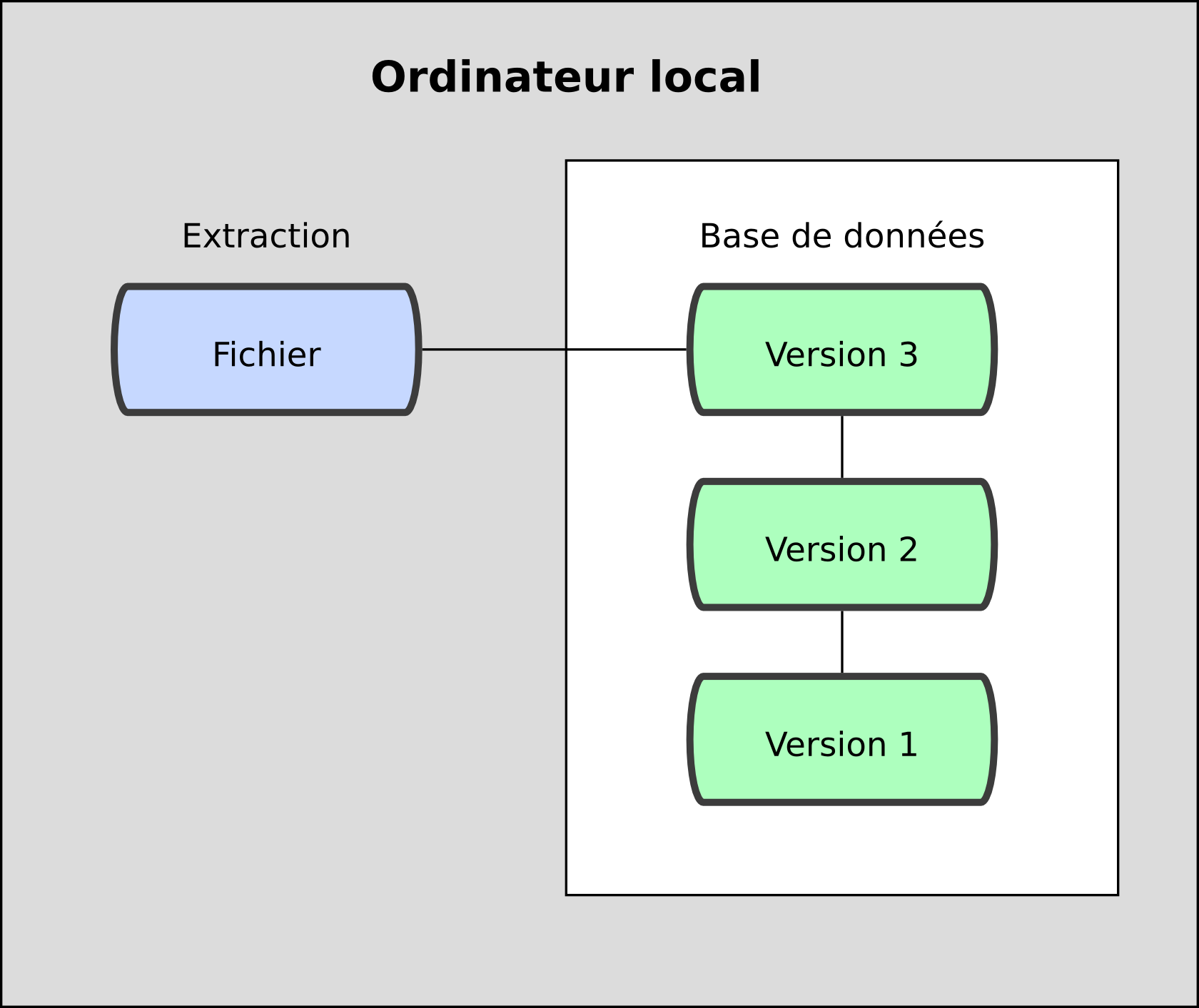 Figure 1-1. Diagramme des systèmes de gestion de version locaux.
Figure 1-1. Diagramme des systèmes de gestion de version locaux.
Un des systèmes les plus populaires était RCS, qui est encore distribué avec de nombreux systèmes d'exploitation aujourd'hui.
Même le système d'exploitation populaire Mac OS X inclut le programme rcs lorsqu'on installe les outils de développement logiciel.
Cet outil fonctionne en conservant des ensembles de patch (c'est-à-dire la différence entre les fichiers) d'une version à l'autre dans un format spécial sur disque ;
il peut alors restituer l'état de n'importe quel fichier à n'importe quel instant en ajoutant toutes les différences.
Le problème majeur que les gens rencontrent est qu'ils ont besoin de collaborer avec des développeurs sur d'autres ordinateurs. Pour traiter ce problème, les systèmes de gestion de version centralisés (CVCS en anglais pour Centralized Version Control Systems) furent développés. Ces systèmes tels que CVS, Subversion, et Perforce, mettent en place un serveur central qui contient tous les fichiers sous gestion de version, et des clients qui peuvent extraire les fichiers de ce dépôt central. Pendant de nombreuses années, cela a été le standard pour la gestion de version (voir figure 1-2).
 Figure 1-2. Diagramme de la gestion de version centralisée.
Figure 1-2. Diagramme de la gestion de version centralisée.
Ce schéma offre de nombreux avantages par rapport à la gestion de version locale. Par exemple, chacun sait jusqu'à un certain point ce que tous les autres sont en train de faire sur le projet. Les administrateurs ont un contrôle fin des permissions et il est beaucoup plus facile d'administrer un CVCS que de gérer des bases de données locales.
Cependant ce système a aussi de nombreux défauts. Le plus visible est le point unique de panne que le serveur centralisé représente. Si ce serveur est en panne pendant une heure, alors durant cette heure, aucun client ne peut collaborer ou enregistrer les modifications issues de son travail. Si le disque dur du serveur central se corrompt, et s'il n'y a pas eu de sauvegarde, vous perdez absolument tout de l'historique d'un projet en dehors des sauvegardes locales que les gens auraient pu réaliser sur leur machines locales. Les systèmes de gestion de version locaux souffrent du même problème - dès qu'on a tout l'historique d'un projet sauvegardé à un endroit unique, on prend le risque de tout perdre.
C'est à ce moment que les systèmes de gestion de version distribués entrent en jeu (DVCSs en anglais pour Distributed Version Control Systems). Dans un DVCS (tel que Git, Mercurial, Bazaar or Darcs), les clients n'extraient plus seulement la dernière version d'un fichier, mais ils dupliquent complètement le dépôt. Ainsi, si le serveur disparaît et si les systèmes collaboraient via ce serveur, n'importe quel dépôt d'un des clients peut être copié sur le serveur pour le restaurer. Chaque extraction devient une sauvegarde complète de toutes les données (voir figure 1-3).
 Figure 1-3. Diagramme de gestion de version de contrôle centralisée.
Figure 1-3. Diagramme de gestion de version de contrôle centralisée.
De plus, un grand nombre de ces systèmes gère particulièrement bien le fait d'avoir plusieurs dépôts avec lesquels travailler, vous permettant de collaborer avec différents groupes de personnes de manières différentes simultanément dans le même projet. Cela permet la mise en place de différentes chaînes de traitement qui ne sont pas réalisables avec les systèmes centralisés, tels que les modèles hiérarchiques.
Comme de nombreuses choses extraordinaires de la vie, Git est né avec une dose de destruction créative et de controverse houleuse. Le noyau Linux est un projet libre de grande envergure. Pour la plus grande partie de sa vie (1991–2002), les modifications étaient transmises sous forme de patchs et d'archives de fichiers. En 2002, le projet du noyau Linux commença à utiliser un DVCS propriétaire appelé BitKeeper.
En 2005, les relations entre la communauté développant le noyau linux et la société en charge du développement de BitKeeper furent rompues, et le statut de gratuité de l'outil fut révoqué. Cela poussa la communauté du développement de Linux (et plus particulièrement Linus Torvalds, le créateur de Linux) à développer leur propre outil en se basant sur les leçons apprises lors de l'utilisation de BitKeeper. Certains des objectifs du nouveau système étaient les suivants :
- Vitesse
- Conception simple
- Support pour les développements non linéaires (milliers de branches parallèles)
- Complètement distribué
- Capacité à gérer efficacement des projets d'envergure tels que le noyau Linux (vitesse et compacité des données)
Depuis sa naissance en 2005, Git a évolué et mûri pour être facile à utiliser tout en conservant ses qualités initiales. Il est incroyablement rapide, il est très efficace pour de grands projets et il a un incroyable système de branches pour des développements non linéaires (voir chapitre 3).
Donc, qu'est-ce que Git en quelques mots ? Il est important de bien comprendre cette section, parce que si on comprend la nature de Git et les principes sur lesquels il repose, alors utiliser efficacement Git devient simple. Au cours de l'apprentissage de Git, essayez de libérer votre esprit de ce que vous pourriez connaître d'autres VCS, tels que Subversion et Perforce ; ce faisant, vous vous éviterez de petites confusions à l'utilisation de cet outil. Git enregistre et gère l'information très différemment des autres systèmes, même si l'interface utilisateur paraît similaire ; comprendre ces différences vous évitera des confusions à l'utilisation.
La différence majeure entre Git et les autres VCS (Subversion et autres) réside dans la manière dont Git considère les données. Au niveau conceptuel, la plupart des autres VCS gèrent l'information comme une liste de modifications de fichiers. Ces systèmes (CVS, Subversion, Perforce, Bazaar et autres) considèrent l'information qu'il gèrent comme une liste de fichiers et les modifications effectuées sur chaque fichier dans le temps, comme illustré en figure 1-4.
 Figure 1-4. D'autres systèmes sauvent l'information comme des modifications sur des fichiers.
Figure 1-4. D'autres systèmes sauvent l'information comme des modifications sur des fichiers.
Git ne gère pas et ne stocke pas les informations de cette manière. À la place, Git pense ses données plus comme un instantané d'un mini système de fichiers. À chaque fois que vous validez ou enregistrez l'état du projet dans Git, il prend effectivement un instantané du contenu de votre espace de travail à ce moment et enregistre une référence à cet instantané. Pour être efficace, si les fichiers n'ont pas changé, Git ne stocke pas le fichier à nouveau, juste une référence vers le fichier original qui n'a pas été modifié. Git pense ses données plus à la manière de la figure 1-5.
 Figure 1-5. Git stocke les données comme des instantanés du projet au cours du temps
Figure 1-5. Git stocke les données comme des instantanés du projet au cours du temps
C'est une distinction importante entre Git et quasiment tous les autres VCSs. Git a reconsidéré quasiment tous les aspects de la gestion de version que la plupart des autres systèmes ont copiés des générations précédentes. Cela fait quasiment de Git un mini système de fichiers avec des outils incroyablement puissants construits dessus, plutôt qu'un simple VCS. Nous explorerons les bénéfices qu'il y a à penser les données de cette manière quand nous aborderons la gestion de branches au chapitre 3.
La plupart des opérations de Git ne nécessite que des fichiers et ressources locales - généralement aucune information venant d'un autre ordinateur du réseau n'est nécessaire. Si vous êtes habitué à un CVCS où toutes les opérations sont ralenties par la latence des échanges réseau, cet aspect de Git vous fera penser que les dieux de la vitesse ont octroyé leurs pouvoirs à Git. Comme vous disposez de l'historique complet du projet localement sur votre disque dur, la plupart des opérations semblent instantanées.
Par exemple, pour parcourir l'historique d'un projet, Git n'a pas besoin d'aller le chercher sur un serveur pour vous l'afficher ; il n'a qu'à simplement le lire directement dans votre base de donnée locale. Cela signifie que vous avez quasi-instantanément accès à l'historique du projet. Si vous souhaitez connaître les modifications introduites entre la version actuelle d'un fichier et son état un mois auparavant, Git peut rechercher l'état du fichier un mois auparavant et réaliser le calcul de différence, au lieu d'avoir à demander cette différence à un serveur ou à devoir récupérer l'ancienne version sur le serveur pour calculer la différence localement.
Cela signifie aussi qu'il y a très peu de choses que vous ne puissiez réaliser si vous n'êtes pas connecté ou hors VPN. Si vous voyagez en train ou en avion et voulez avancer votre travail, vous pouvez continuer à gérer vos versions sans soucis en attendant de pouvoir de nouveau vous connecter pour partager votre travail. Si vous êtes chez vous et ne pouvez avoir une liaison VPN avec votre entreprise, vous pouvez tout de même travailler. Pour de nombreux autres systèmes, faire de même est impossible ou au mieux très contraignant. Avec Perforce par exemple, vous ne pouvez pas faire grand'chose tant que vous n'êtes pas connecté au serveur. Avec Subversion ou CVS, vous pouvez éditer les fichiers, mais vous ne pourrez pas soumettre des modifications à votre base de données (car celle-ci est sur le serveur non accessible). Cela peut sembler peu important à priori, mais vous seriez étonné de découvrir quelle grande différence cela peut constituer à l'usage.
Dans Git, tout est vérifié par une somme de contrôle avant d'être stocké et par la suite cette somme de contrôle, signature unique, sert de référence. Cela signifie qu'il est impossible de modifier le contenu d'un fichier ou d'un répertoire sans que Git ne s'en aperçoive. Cette fonctionnalité est ancrée dans les fondations de Git et fait partie intégrante de sa philosophie. Vous ne pouvez pas perdre des données en cours de transfert ou corrompre un fichier sans que Git ne puisse le détecter.
Le mécanisme que Git utilise pour réaliser les sommes de contrôle est appelé une empreinte SHA-1. C'est une chaîne de caractères composée de 40 caractères hexadécimaux (de '0' à '9' et de 'a' à 'f') calculée en fonction du contenu du fichier ou de la structure du répertoire considéré. Une empreinte SHA-1 ressemble à ceci :
24b9da6552252987aa493b52f8696cd6d3b00373
Vous trouverez ces valeurs à peu près partout dans Git car il les utilise pour tout. En fait, Git stocke tout non pas avec des noms de fichier, mais dans la base de données Git indexée par ces valeurs.
Quand vous réalisez des actions dans Git, la quasi-totalité d'entre elles ne font qu'ajouter des données dans la base de données de Git. Il est très difficile de faire réaliser au système des actions qui ne soient pas réversibles ou de lui faire effacer des données d'une quelconque manière. Par contre, comme dans la plupart des systèmes de gestion de version, vous pouvez perdre ou corrompre des modifications qui n'ont pas encore été entrées en base ; mais dès que vous avez validé un instantané dans Git, il est très difficile de le perdre, spécialement si en plus vous synchronisez votre base de données locale avec un dépôt distant.
Cela fait de l'usage de Git un vrai plaisir, car on peut expérimenter sans danger de casser définitivement son projet. Pour une information plus approfondie sur la manière dont Git stocke ses données et comment récupérer des données qui pourraient sembler perdues, référez-vous au chapitre 9 "Les tripes de Git".
Ici, il faut être attentif. Il est primordial de se souvenir de ce qui suit si vous souhaitez que le reste de votre apprentissage s'effectue sans difficulté. Git gère trois états dans lesquel les fichiers peuvent résider : validé, modifié et indexé. Validé signifie que les données sont stockées en sécurité dans votre base de données locale. Modifié signifie que vous avez modifié le fichier mais qu'il n'a pas encore été validé en base. Indexé signifie que vous avez marqué un fichier modifié dans sa version actuelle pour qu'il fasse partie du prochain instantané du projet.
Ceci nous mène aux trois sections principales d'un projet Git : le répertoire Git, le répertoire de travail et la zone d'index.
 Figure 1-6. Répertoire de travail, zone d'index et répertoire Git.
Figure 1-6. Répertoire de travail, zone d'index et répertoire Git.
Le répertoire Git est l'endroit où Git stocke les méta-données et la base de données des objets de votre projet. C'est la partie la plus importante de Git, et c'est ce qui est copié lorsque vous clonez un dépôt depuis un autre ordinateur.
Le répertoire de travail est une extraction unique d'une version du projet. Ces fichiers sont extraits depuis la base de données compressée dans le répertoire Git et placés sur le disque pour pouvoir être utilisés ou modifiés.
La zone d'index est un simple fichier, généralement situé dans le répertoire Git, qui stocke les informations concernant ce qui fera partie du prochain instantané.
L'utilisation standard de Git se passe comme suit :
- Vous modifiez des fichiers dans votre répertoire de travail
- Vous indexez les fichiers modifiés, ce qui ajoute des instantanés de ces fichiers dans la zone d'index
- Vous validez, ce qui a pour effet de basculer les instantanés des fichiers de l'index dans la base de donnée du répertoire Git.
Si une version particulière d'un fichier est dans le répertoire Git, il est considéré comme validé. S'il est modifié mais a été ajouté dans la zone d'index, il est indexé. S'il a été modifié depuis le dernier instantané mais n'a pas été indexé, il est modifié. Dans le chapitre 2, vous en apprendrez plus sur ces états et comment vous pouvez en tirer parti ou complètement les occulter.
Commençons donc à utiliser Git. La première chose à faire est de l'installer. Vous pouvez l'obtenir par de nombreuses manières ; les deux principales sont de l'installer à partir des sources ou d'installer un paquet existant sur votre plate-forme.
Si vous le pouvez, il est généralement conseillé d'installer Git à partir des sources, car vous obtiendrez la version la plus récente. Chaque nouvelle version de Git tend à inclure des améliorations utiles de l'interface utilisateur, donc récupérer la toute dernière version est souvent la meilleure option si vous savez compiler des logiciels à partir des sources. Comme la plupart du temps les distributions contiennent des version très anciennes de logiciels, à moins que vous ne travailliez sur une distribution très récente ou que vous n'utilisiez des backports, une installation à partir des sources peut être le meilleur choix.
Pour installer Git, vous avez besoin des bibliothèques suivantes : curl, zlib, openssl, expat, libiconv. Par exemple, si vous avez un système d'exploitation qui utilise yum (tel que Fedora) ou apt-get (tel qu'un système basé sur Debian), vous pouvez utiliser l'une des commandes suivantes pour installer les dépendances :
$ yum install curl-devel expat-devel gettext-devel \
openssl-devel zlib-devel
$ apt-get install libcurl4-gnutls-dev libexpat1-dev gettext \
libz-dev libssl-dev
Quand vous avez toutes les dépendances nécessaires, vous pouvez poursuivre et télécharger la dernière version de Git depuis le site :
http://git-scm.com/download
Puis, compiler et installer :
$ tar -zxf git-1.7.2.2.tar.gz
$ cd git-1.7.2.2
$ make prefix=/usr/local all
$ sudo make prefix=/usr/local install
Après ceci, vous pouvez obtenir Git par Git lui-même pour les mises à jour :
$ git clone git://git.kernel.org/pub/scm/git/git.git
Si vous souhaitez installer Git sur Linux via un installateur d'application, vous pouvez généralement le faire via le système de gestion de paquet de base fourni avec votre distribution. Si vous êtes sur Fedora, vous pouvez utiliser yum :
$ yum install git-core
Si vous êtes sur un système basé sur Debian, tel qu'Ubuntu, essayez apt-get :
$ apt-get install git-core
Il y a deux moyens simples d'installer Git sur Mac. Le plus simple et d'utiliser l'installateur graphique de Git que vous pouvez télécharger depuis les pages Google Code (voir figure 1-7) :
http://code.google.com/p/git-osx-installer
 Figure 1-7. Installateur OS X de Git.
Figure 1-7. Installateur OS X de Git.
L'autre méthode consiste à installer Git par les MacPorts (http://www.macports.org).
Si vous avez installé MacPorts, installez Git par :
$ sudo port install git-core +svn +doc +bash_completion +gitweb
Vous n'avez pas à ajouter tous les extras, mais vous souhaiterez sûrement inclure +svn si vous êtes amené à utiliser Git avec des dépôts Subversion (voir chapitre 8).
Installer Git sur Windows est très facile. Le projet msysGit fournit une des procédures d'installation les plus simples. Téléchargez simplement le fichier exe d'installateur depuis la page Google Code, et lancez-le :
http://code.google.com/p/msysgit
Après son installation, vous avez à la fois la version en ligne de commande (avec un client SSH utile pour la suite) ou l'interface graphique standard.
Maintenant que vous avez installé Git sur votre système, vous voudrez personnaliser votre environnement Git. Vous ne devriez avoir à réaliser ces réglages qu'une seule fois ; ils persisteront lors des mises à jour. Vous pouvez aussi les changer à tout instant en relançant les mêmes commandes.
Git contient un outil appelé git config pour vous permettre de voir et modifier les variables de configuration qui contrôlent tous les aspects de l'apparence et du comportement de Git.
Ces variables peuvent être stockées dans trois endroits différents :
- Fichier
/etc/gitconfig: Contient les valeurs pour tous les utilisateurs et tous les dépôts du système. Si vous passez l'option--systemàgit config, il lit et écrit ce fichier spécifiquement. - Fichier
~/.gitconfig: Spécifique à votre utilisateur. Vous pouvez forcer Git à lire et écrire ce fichier en passant l'option--global. - Fichier
configdans le répertoire Git (c'est à dire.git/config) du dépôt en cours d'utilisation : spécifique au seul dépôt en cours. Chaque niveau surcharge le niveau précédent, donc les valeurs dans.git/configsurchargent celles de/etc/gitconfig.
Sur les systèmes Windows, Git recherche le fichier .gitconfig dans le répertoire $HOME (C:\Documents and Settings\$USER la plupart du temps).
Il recherche tout de même /etc/gitconfig, bien qu'il soit relatif à la racine MSys, qui se trouve où vous aurez décidé d'installer Git sur votre système Windows.
La première chose à faire après l'installation de Git est de renseigner votre nom et votre adresse e-mail. C'est une information importante car toutes les validations dans Git utilisent cette information et elle est indélébile dans toutes les validations que vous pourrez réaliser :
$ git config --global user.name "John Doe"
$ git config --global user.email johndoe@example.com
Encore une fois, cette étape n'est nécessaire qu'une fois si vous passez l'option --global, parce que Git utilisera toujours cette information pour tout ce que votre utilisateur fera sur ce système.
Si vous souhaitez surcharger ces valeurs avec un nom ou une adresse e-mail différents pour un projet spécifique, vous pouvez lancer ces commandes sans option --global lorsque vous êtes dans ce projet.
À présent que votre identité est renseignée, vous pouvez configurer l'éditeur de texte qui sera utilisé quand Git vous demande de saisir un message. Par défaut, Git utilise l'éditeur configuré au niveau système, qui est généralement Vi ou Vim. Si vous souhaitez utiliser un éditeur de texte différent, comme Emacs, vous pouvez entrer ce qui suit :
$ git config --global core.editor emacs
Une autre option utile est le paramétrage de l'outil de différences à utiliser pour la résolution des conflits de fusion. Supposons que vous souhaitiez utiliser vimdiff :
$ git config --global merge.tool vimdiff
Git accepte kdiff3, tkdiff, meld, xxdiff, emerge, vimdiff, gvimdiff, ecmerge, et opendiff comme outils valides de fusion. Vous pouvez aussi paramétrer un outil personnalisé ; référez-vous au chapitre 7 pour plus d'information sur cette procédure.
Si vous souhaitez vérifier vos réglages, vous pouvez utiliser la commande git config --list pour lister tous les réglages que Git a pu trouver jusqu'ici :
$ git config --list
user.name=Scott Chacon
user.email=schacon@gmail.com
color.status=auto
color.branch=auto
color.interactive=auto
color.diff=auto
...
Vous pourrez voir certains paramètres apparaître plusieurs fois car Git lit les mêmes paramètres depuis plusieurs fichiers (/etc/gitconfig et ~/.gitconfig, par exemple).
Git utilise la dernière valeur pour chaque paramètre.
Vous pouvez aussi vérifier la valeur effective d'un paramètre particulier en tapant git config <paramètre> :
$ git config user.name
Scott Chacon
Si vous avez besoin d'aide pour utiliser Git, il y a trois moyens d'obtenir les pages de manuel pour toutes les commandes de Git :
$ git help <verbe>
$ git <verbe> --help
$ man git-<verbe>
Par exemple, vous pouvez obtenir la page de manuel pour la commande config en lançant :
$ git help config
Ces commandes sont vraiment sympathiques car vous pouvez y accéder depuis partout, y compris hors connexion.
Si les pages de manuel et ce livre ne sont pas suffisants, vous pouvez essayer les canaux #git ou #github sur le serveur IRC Freenode (irc.freenode.net).
Ces canaux sont régulièrement peuplés de centaines de personnes qui ont une bonne connaissance de Git et sont souvent prêtes à aider.
Vous devriez avoir à présent une compréhension initiale de ce que Git est et en quoi il est différent des CVCS que vous pourriez déjà avoir utilisés. Vous devriez aussi avoir une version de Git en état de fonctionnement sur votre système, paramétrée avec votre identité. Il est temps d'apprendre les bases d'utilisation de Git.
Suivant : 02