Git distribué
Avec un dépôt distant Git mis en place pour permettre à tous les développeurs de partager leur code, et la connaissance des commandes de base de Git pour une gestion locale, abordons les méthodes de gestion distribuée que Git nous offre.
Dans ce chapitre, vous découvrirez comment travailler dans un environnement distribué avec Git en tant que contributeur ou comme intégrateur. Cela recouvre la manière de contribuer efficacement à un projet et de rendre la vie plus facile au mainteneur du projet ainsi qu'à vous-même, mais aussi en tant que mainteneur, de gérer un projet avec de nombreux contributeurs.
À la différence des systèmes de gestion de version centralisés (CVCS), la nature distribuée de Git permet une bien plus grande flexibilité dans la manière dont les développeurs collaborent sur un projet. Dans les systèmes centralisés, tout développeur est un nœud travaillant de manière plus ou moins égale sur un concentrateur central. Dans Git par contre, tout développeur est potentiellement un nœud et un concentrateur, c'est-à-dire que chaque développeur peut à la fois contribuer du code vers les autres dépôts et maintenir un dépôt public sur lequel d'autres vont baser leur travail et auquel ils vont contribuer. Cette capacité ouvre une perspective de modes de développement pour votre projet ou votre équipe dont certains archétypes tirant parti de cette flexibilité seront traités dans les sections qui suivent. Les avantages et inconvénients éventuels de chaque mode seront traités. Vous pouvez choisir d'en utiliser un seul ou de mélanger les fonctions de chacun.
Dans les systèmes centralisés, il n'y a généralement qu'un seul modèle de collaboration, la gestion centralisée. Un concentrateur ou dépôt central accepte le code et tout le monde doit synchroniser son travail avec. Les développeurs sont des nœuds, des consommateurs du concentrateur, seul endroit où ils se synchronisent (voir figure 5-1).
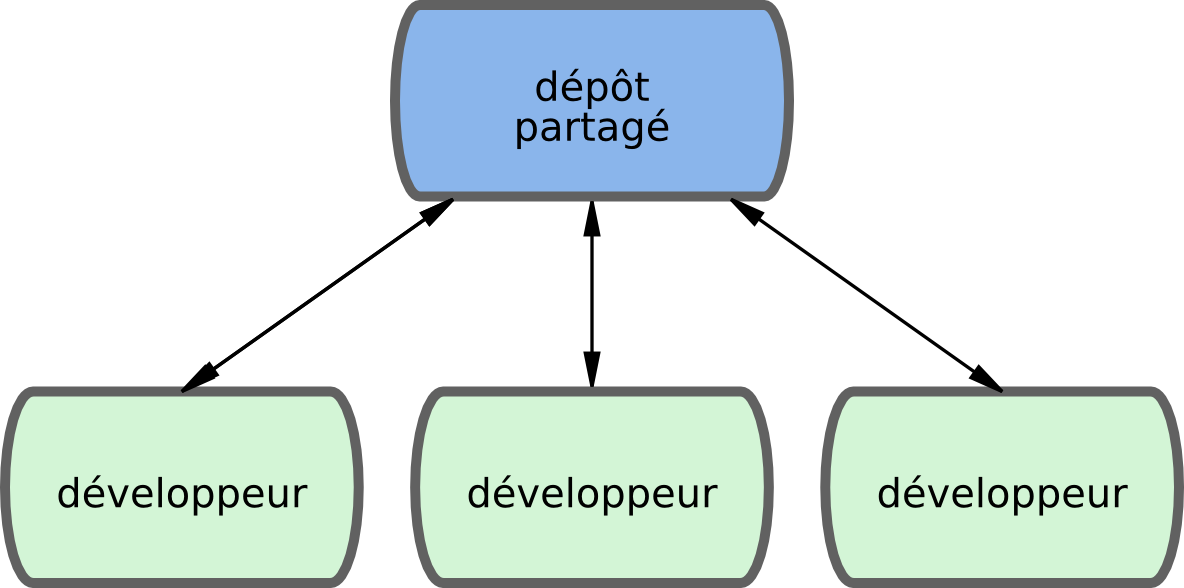 Figure 5-1. La gestion centralisée.
Figure 5-1. La gestion centralisée.
Cela signifie que si deux développeurs clonent depuis le concentrateur et qu'ils introduisent tous les deux des modifications, le premier à pousser ses modifications le fera sans encombre. Le second développeur doit fusionner les modifications du premier dans son dépôt local avant de pousser ses modifications pour ne pas écraser les modifications du premier. Ce concept reste aussi vrai avec Git qu'il l'est avec Subversion (ou tout autre CVCS) et le modèle fonctionne parfaitement dans Git.
Si votre équipe est petite et que vous êtes déjà habitués à une gestion centralisée dans votre société ou votre équipe, vous pouvez simplement continuer à utiliser cette méthode avec Git. Mettez en place un dépôt unique et donnez à tous l'accès en poussée. Git empêchera les utilisateurs d'écraser le travail des autres. Si un développeur clone le dépôt central, fait des modifications et essaie de les pousser alors qu'un autre développeur à poussé ses modifications dans le même temps, le serveur rejettera les modifications du premier. Il lui sera indiqué qu'il cherche à pousser des modifications sans mode avance rapide et qu'il ne pourra pas le faire tant qu'il n'aura pas récupéré et fusionné les nouvelles modifications depuis le serveur. Cette méthode est très intéressante pour de nombreuses personnes car c'est un paradigme avec lequel beaucoup sont familiers et à l'aise.
Comme Git permet une multiplicité de dépôt distants, il est possible d'envisager un mode de fonctionnement où chaque développeur a un accès en écriture à son propre dépôt public et en lecture à tous ceux des autres. Ce scénario inclut souvent un dépôt canonique qui représente le projet « officiel ». Pour commencer à contribuer au projet, vous créez votre propre clone public du projet et poussez vos modifications dessus. Après, il suffit d'envoyer une demande au mainteneur de projet pour qu'il tire vos modifications dans le dépôt canonique. Il peut ajouter votre dépôt comme dépôt distant, tester vos modifications localement, les fusionner dans sa branche et les pousser vers le dépôt public. Le processus se passe comme ceci (voir figure 5-2) :
-
Le mainteneur du projet pousse vers son dépôt public. -
Un contributeur clone ce dépôt et introduit des modifications. -
Le contributeur pousse son travail sur son dépôt public. -
Le contributeur envoie au mainteneur un e-mail de demande pour tirer depuis son dépôt. -
Le mainteneur ajoute le dépôt du contributeur comme dépôt distant et fusionne localement. -
Le mainteneur pousse les modifications fusionnées sur le dépôt principal.
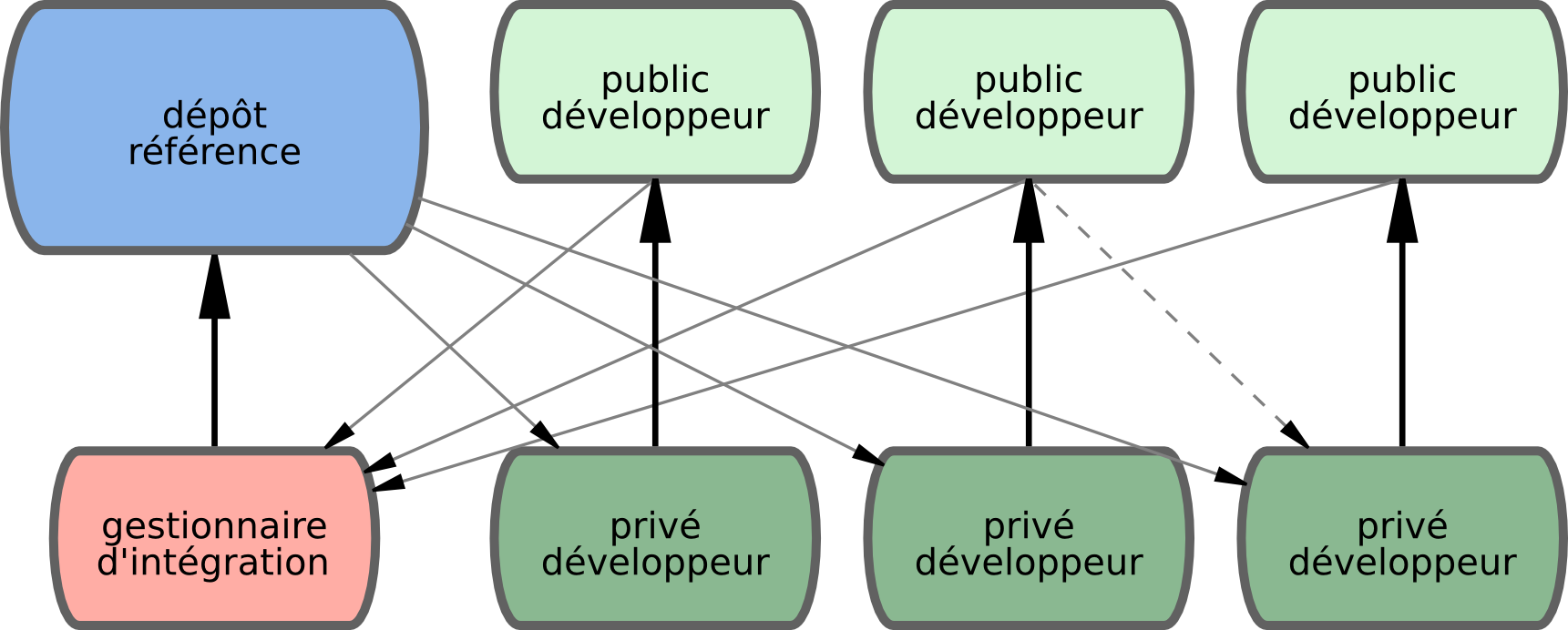 Figure 5-2. Le mode du gestionnaire d'intégration
Figure 5-2. Le mode du gestionnaire d'intégration
C'est une gestion très commune sur des sites tels que GitHub où il est aisé de dupliquer un projet et de pousser ses modifications pour les rendre publiques. Un avantage distinctif de cette approche est qu'il devient possible de continuer à travailler et que le mainteneur du dépôt principal peut tirer les modifications à tout moment. Les contributeurs n'ont pas à attendre le bon-vouloir du mainteneur pour incorporer leurs modifications. Chaque acteur peut travailler à son rythme.
C'est une variante de la gestion multi-dépôt. En général, ce mode est utilisé sur des projets immenses comprenant des centaines de collaborateurs. Un exemple connu en est le noyau Linux. Des gestionnaires d'intégration gèrent certaines parties du projet. Ce sont les lieutenants. Tous les lieutenants ont un unique gestionnaire d'intégration, le dictateur bénévole. Le dépôt du dictateur sert de dépôt de référence à partir duquel tous les collaborateurs doivent tirer. Le processus se déroule comme suit (voir figure 5-3) :
-
Les développeurs de base travaillent sur la branche thématique et rebasent leur travail sur master. La branche `master` est celle du dictateur. -
Les lieutenants fusionnent les branches thématiques des développeurs dans leur propre branche `master`. -
Le dictateur fusionne les branches master de ses lieutenants dans sa propre branche `master`. -
Le dictateur pousse sa branche `master` sur le dépôt de référence pour que les développeurs se rebasent dessus.
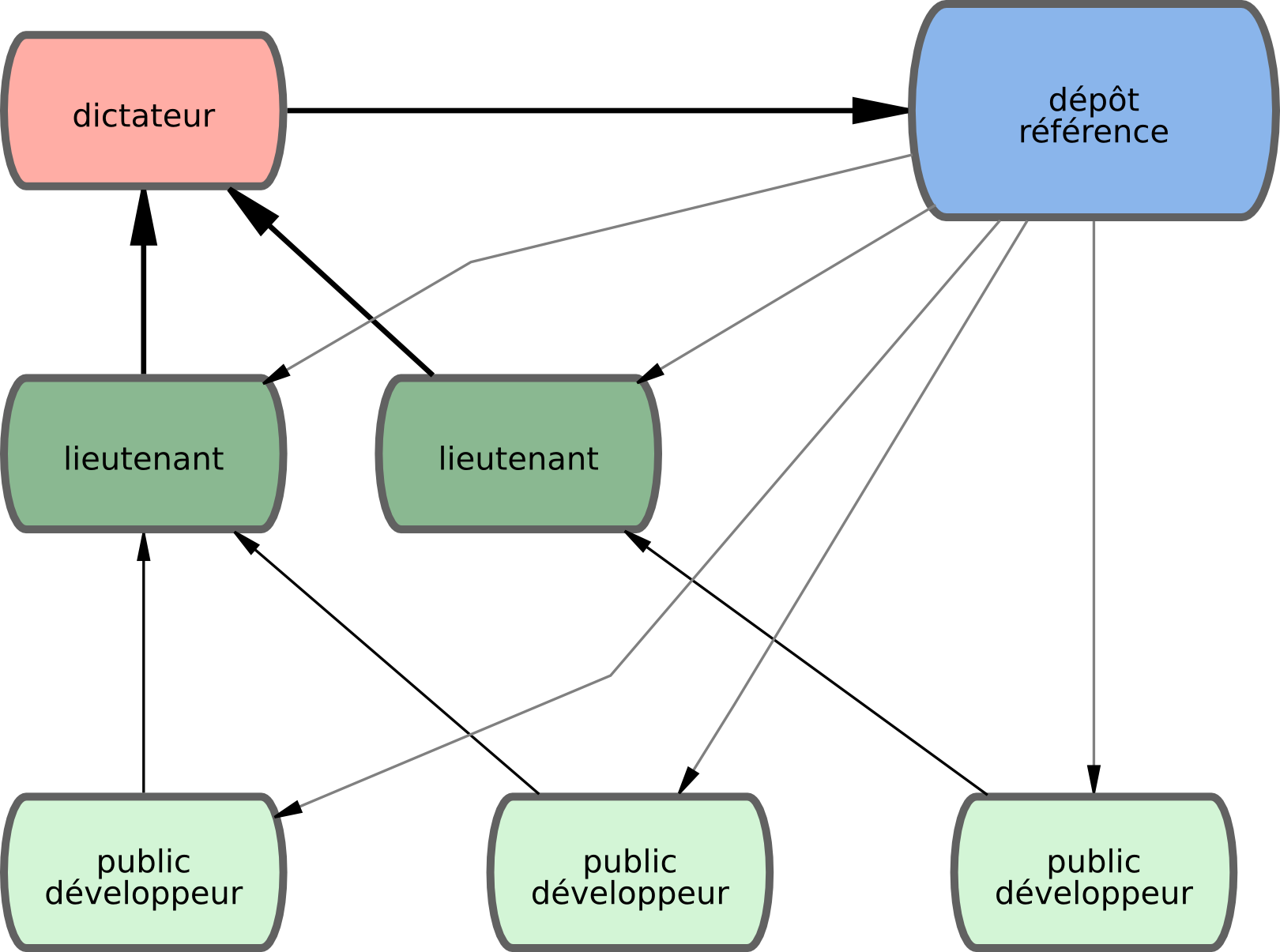 Figure 5-3. Le processus du dictateur bénévole.
Figure 5-3. Le processus du dictateur bénévole.
Ce schéma de processus n'est pas très utilisé mais s'avère utile dans des projets très gros ou pour lesquels un ordre hiérarchique existe, car il permet au chef de projet (le dictateur) de déléguer une grande partie du travail et de collecter de grands sous-ensembles de codes à différents points avant de les intégrer.
Ce sont des schémas de processus rendu possibles et généralement utilisés avec des systèmes distribués tels que Git, mais de nombreuses variations restent possibles pour coller à un flux de modifications donné. En espérant vous avoir aidé à choisir le meilleur mode de gestion pour votre cas, je vais traiter des exemples plus spécifiques de méthode de réalisation des rôles principaux constituant les différents flux.
Vous savez ce que sont les différents modes de gestion et vous devriez connaître suffisamment l'utilisation de Git. Dans cette section, vous apprendrez les moyens les plus utilisés pour contribuer à un projet.
La principale difficulté à décrire ce processus réside dans l'extraordinaire quantité de variations dans sa réalisation. Comme Git est très flexible, les gens peuvent collaborer de différentes façons et ils le font, et il devient problématique de décrire de manière unique comment devrait se réaliser la contribution à un projet. Chaque projet est légèrement différent. Les variables incluent la taille du corps des contributeurs, le choix du flux de gestion, les accès en validation et la méthode de contribution externe.
La première variable est la taille du corps de contributeurs. Combien de personnes contribuent activement du code sur ce projet et à quelle vitesse ? Dans de nombreux cas, vous aurez deux à trois développeurs avec quelques validations par jour, voire moins pour des projets endormis. Pour des sociétés ou des projets particulièrement grands, le nombre de développeurs peut chiffrer à des milliers, avec des dizaines, voire des centaines de patchs ajoutés chaque jour. Ce cas est important car avec de plus en plus de développeurs, les problèmes de fusion et d'application de patch deviennent de plus en plus courants. Les modifications soumises par un développeur peuvent être obsolètes ou impossibles à appliquer à cause de changements qui ont eu lieu dans l'intervalle de leur développement, de leur approbation ou de leur application. Comment dans ces conditions conserver son code en permanence synchronisé et ses patchs valides ?
La variable suivante est le mode de gestion utilisé pour le projet. Est-il centralisé avec chaque développeur ayant un accès égal en écriture sur la ligne de développement principale ? Le projet présente-t-il un mainteneur ou un gestionnaire d'intégration qui vérifie tous les patchs ? Tous les patchs doivent-ils subir une revue de pair et une approbation ? Faîtes-vous partie du processus ? Un système à lieutenant est-il en place et doit-on leur soumettre les modifications en premier ?
La variable suivante est la gestion des accès en écriture. Le mode de gestion nécessaire à la contribution au projet est très différent selon que vous avez ou non accès au dépôt en écriture. Si vous n'avez pas accès en écriture, quelle est la méthode préférée pour la soumission de modifications ? Y a-t-il seulement une politique en place ? Quelle est la quantité de modifications fournie à chaque fois ? Quelle est la périodicité de contribution ?
Toutes ces questions affectent la manière de contribuer efficacement à un projet et les modes de gestion disponibles ou préférables. Je vais traiter ces sujets dans une série de cas d'utilisation allant des plus simples aux plus complexes. Vous devriez pouvoir construire vos propres modes de gestion à partir de ces exemples.
Avant de passer en revue les cas d'utilisation spécifiques, voici un point rapide sur les messages de validation.
La définition et l'utilisation d'une bonne ligne de conduite sur les messages de validation facilitent grandement l'utilisation de Git et la collaboration entre développeurs.
Le projet Git fournit un document qui décrit un certain nombre de bonnes pratiques pour créer des commits qui serviront à fournir des patchs — le document est accessibles dans les sources de Git, dans le fichier Documentation/SubmittingPatches.
Premièrement, il ne faut pas soumettre de patchs comportant des erreurs d'espace (caractères espace inutiles en fin de ligne).
Git fournit un moyen simple de le vérifier — avant de valider, lancez la commande git diff --check qui identifiera et listera les erreurs d'espace.
Voici un exemple dans lequel les caractères en couleur rouge ont été remplacés par des X :
$ git diff --check
lib/simplegit.rb:5: trailing whitespace.
+ @git_dir = File.expand_path(git_dir)XX
lib/simplegit.rb:7: trailing whitespace.
+ XXXXXXXXXXX
lib/simplegit.rb:26: trailing whitespace.
+ def command(git_cmd)XXXX
En lançant cette commande avant chaque validation, vous pouvez vérifier que vous ne commettez pas d'erreurs d'espace qui pourraient ennuyer les autres développeurs.
Ensuite, assurez-vous de faire de chaque validation une modification logiquement atomique. Si possible, rendez chaque modification digeste — ne codez pas pendant un week-end entier sur cinq sujets différents pour enfin les soumettre tous dans une énorme validation le lundi suivant.
Même si vous ne validez pas du week-end, utilisez la zone d'index le lundi pour découper votre travail en au moins une validation par problème, avec un message utile par validation.
Si certaines modifications touchent au même fichier, essayez d'utiliser git add --patch pour indexer partiellement des fichiers (cette fonctionnalité est traitée au chapitre 6).
L'instantané final sera identique, que vous utilisiez une validation unique ou cinq petites validations, à condition que toutes les modifications soient intégrées à un moment, donc n'hésitez pas à rendre la vie plus simple à vos compagnons développeurs lorsqu'ils auront à vérifier vos modifications.
Cette approche simplifie aussi le retrait ou l'inversion ultérieurs d'une modification en cas de besoin.
Le chapitre 6 décrit justement quelques trucs et astuces de Git pour réécrire l'historique et indexer interactivement les fichiers — utilisez ces outils pour fabriquer un historique propre et compréhensible.
Le dernier point à soigner est le message de validation. S'habituer à écrire des messages de validation de qualité facilite grandement l'emploi et la collaboration avec Git. En règle générale, les messages doivent débuter par une ligne unique d'au plus 50 caractères décrivant concisément la modification, suivie d'une ligne vide, suivie d'une explication plus détaillée. Le projet Git exige que l'explication détaillée inclut la motivation de la modification en contrastant le nouveau comportement par rapport à l'ancien — c'est une bonne règle de rédaction. Un bonne règle consiste aussi à utiliser le présent de l'impératif ou des verbes substantivés dans le message. En d'autres termes, utilisez des ordres. Au lieu d'écrire « J'ai ajouté des tests pour » ou « En train d'ajouter des tests pour », utilisez juste « Ajoute des tests pour » ou « Ajout de tests pour ».
Voici ci-dessous un modèle tiré de celui écrit par Tim Pope at tpope.net :
Court résumé des modifications( 50 caractères ou moins)
Explication plus détaillée si nécessaire. Retour à la ligne vers 72
caractères. Dans certains contextes, la première ligne est traitée
comme le sujet d'un e-mail et le reste comme le corps. La ligne
vide qui sépare le titre du corps est importante (à moins d'omettre
totalement le corps). Des outils tels que rebase peuvent être gênés
si vous les laissez collés.
Paragraphes supplémentaires après des lignes vides.
- les listes à puce sont aussi acceptées
- Typiquement, un tiret ou un astérisk précédés d'un espace unique
séparés par des lignes vides mais les conventions peuvent varier
Si tous vos messages de validation ressemblent à ceci, les choses seront beaucoup plus simples pour vous et les développeurs avec qui vous travaillez.
Le projet Git montre des messages de commit bien formatés — je vous encourage à y lancer un git log --no-merges pour pouvoir voir comment rend un historique de messages bien formatés.
Dans les exemples suivants et à travers tout ce livre, par soucis de simplification, je ne formaterai pas les messages aussi proprement.
J'utiliserai plutôt l'option -m de git commit.
Faites ce que je dis, pas ce que je fais.
Le cas le plus probable que vous rencontrerez est celui du projet privé avec un ou deux autres développeurs. Par privé, j'entends code source fermé non accessible au public en lecture. Vous et les autres développeurs aurez accès en poussée au dépôt.
Dans cet environnement, vous pouvez suivre une méthode similaire à ce que vous feriez en utilisant Subversion ou tout autre système centralisé.
Vous bénéficiez toujours d'avantages tels que la validation hors-ligne et la gestion de branche et de fusion grandement simplifiée mais les étapes restent similaires.
La différence principale reste que les fusions ont lieu du côté client plutôt que sur le serveur au moment de valider.
Voyons à quoi pourrait ressembler la collaboration de deux développeurs sur un dépôt partagé.
Le premier développeur, John, clone le dépôt, fait une modification et valide localement.
Dans les exemples qui suivent, les messages de protocole sont remplacés par ... pour les raccourcir .
# Ordinateur de John
$ git clone john@githost:simplegit.git
Initialized empty Git repository in /home/john/simplegit/.git/
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'Eliminer une valeur par defaut invalide'
[master 738ee87] Eliminer une valeur par defaut invalide
1 files changed, 1 insertions(+), 1 deletions(-)
La deuxième développeuse, Jessica, fait la même chose. Elle clone le dépôt et valide une modification :
# Ordinateur de Jessica
$ git clone jessica@githost:simplegit.git
Initialized empty Git repository in /home/jessica/simplegit/.git/
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'Ajouter une tache reset'
[master fbff5bc] Ajouter une tache reset
1 files changed, 1 insertions(+), 0 deletions(-)
À présent, Jessica pousse son travail sur le serveur :
# Ordinateur de Jessica
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> master
John tente aussi de pousser ses modifications :
# Ordinateur de John
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'
John n'a pas le droit de pousser parce que Jessica a déjà poussé dans l'intervalle. Il est très important de comprendre ceci si vous avez déjà utilisé Subversion, parce qu'il faut remarquer que les deux développeurs n'ont pas modifié le même fichier. Quand des fichiers différents ont été modifiés, Subversion réalise cette fusion automatiquement sur le serveur alors que Git nécessite une fusion des modifications locale. John doit récupérer les modifications de Jessica et les fusionner avant d'être autorisé à pousser :
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/master
À présent, le dépôt local de John ressemble à la figure 5-4.
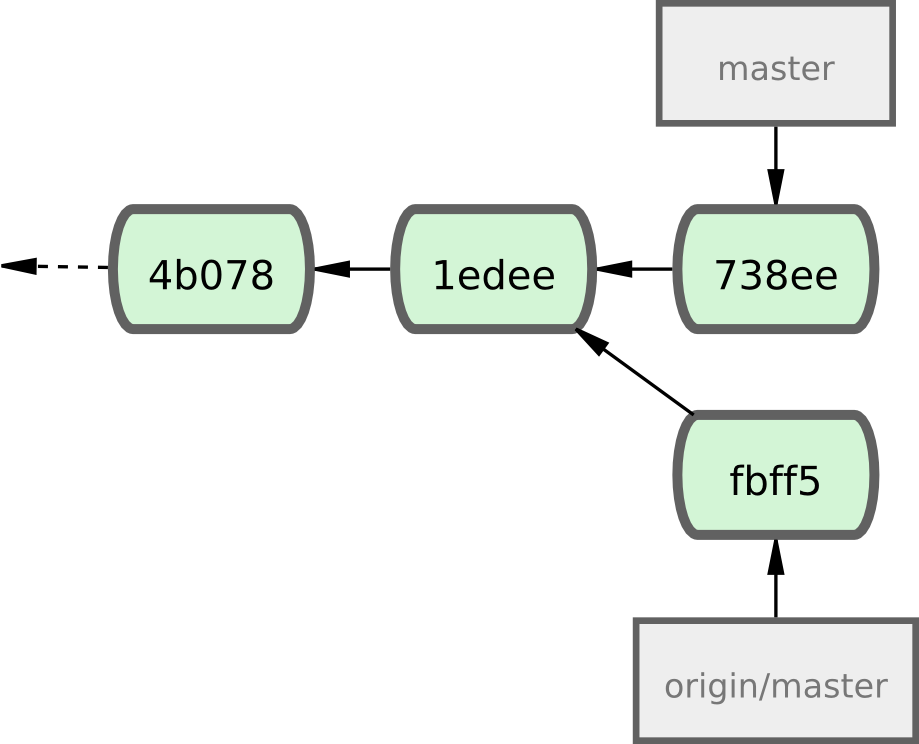 Figure 5-4. État initial du dépôt de John.
Figure 5-4. État initial du dépôt de John.
John a une référence aux modifications que Jessica a poussées, mais il doit les fusionner dans sa propre branche avant de pouvoir pousser :
$ git merge origin/master
Merge made by recursive.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
Cette fusion se passe sans problème — l'historique de commits de John ressemble à présent à la figure 5-5.
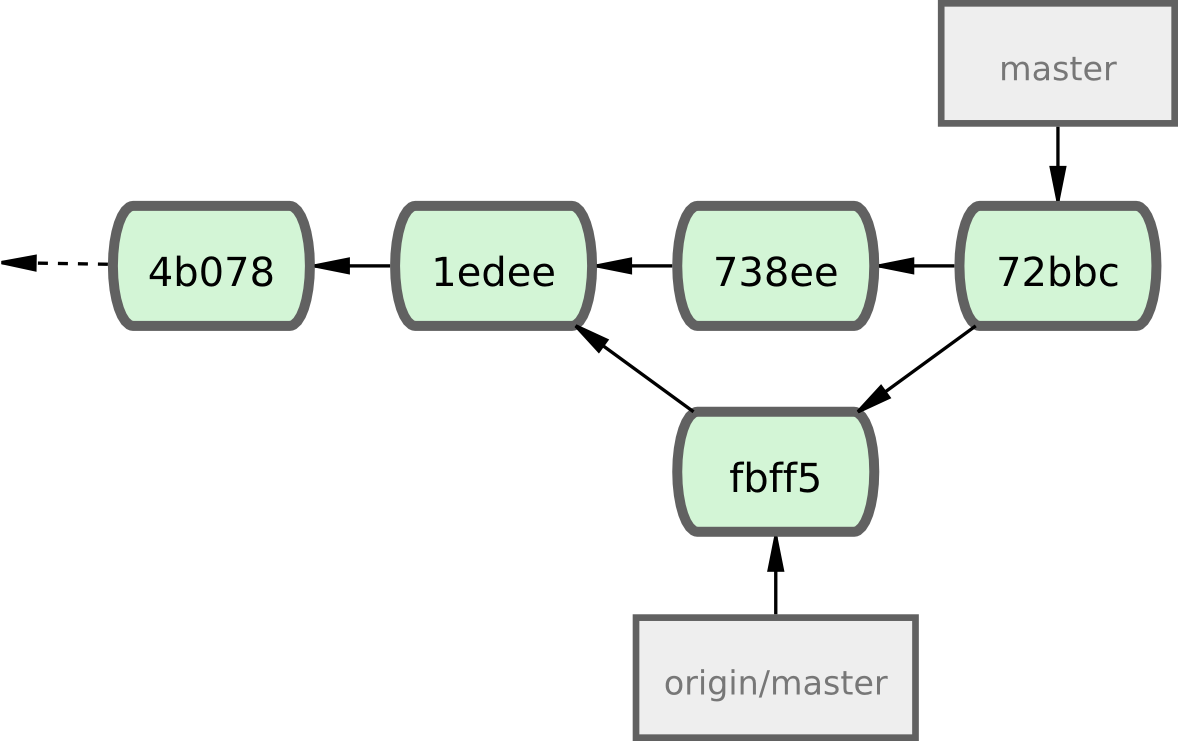 Figure 5-5. Le dépôt local de John après la fusion d'origin/master.
Figure 5-5. Le dépôt local de John après la fusion d'origin/master.
Maintenant, John peut tester son code pour s'assurer qu'il fonctionne encore correctement et peut pousser son travail nouvellement fusionné sur le serveur :
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> master
À la fin, l'historique des commits de John ressemble à la figure 5-6.
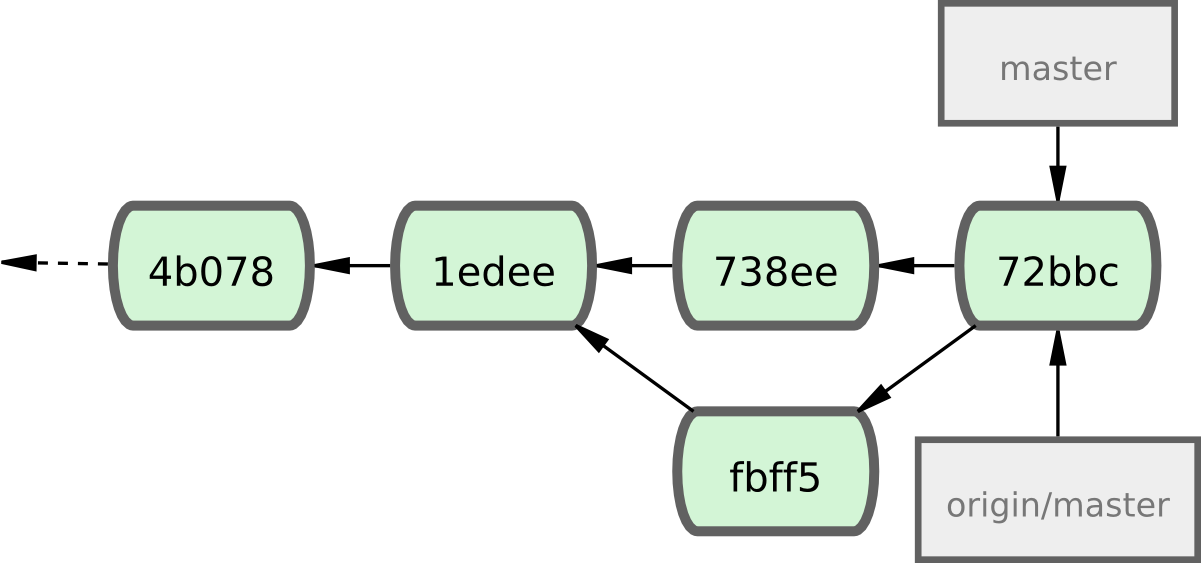 Figure 5-6. L'historique de John après avoir poussé sur le serveur origin.
Figure 5-6. L'historique de John après avoir poussé sur le serveur origin.
Dans l'intervalle, Jessica a travaillé sur une branche thématique.
Elle a créé une branche thématique nommée prob54 et réalisé trois validations sur cette branche.
Elle n'a pas encore récupéré les modifications de John, ce qui donne un historique semblable à la figure 5-7.
[[figures/5.7.png|align=center|frame|width=500px|alt=Figure 5-7. L'historique initial des commits de Jessica.]]
Jessica souhaite se synchroniser sur le travail de John. Elle récupère donc ses modifications :
# Ordinateur de Jessica
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/master
Cette commande tire le travail que John avait poussé dans l'intervalle. L'historique de Jessica ressemble maintenant à la figure 5-8.
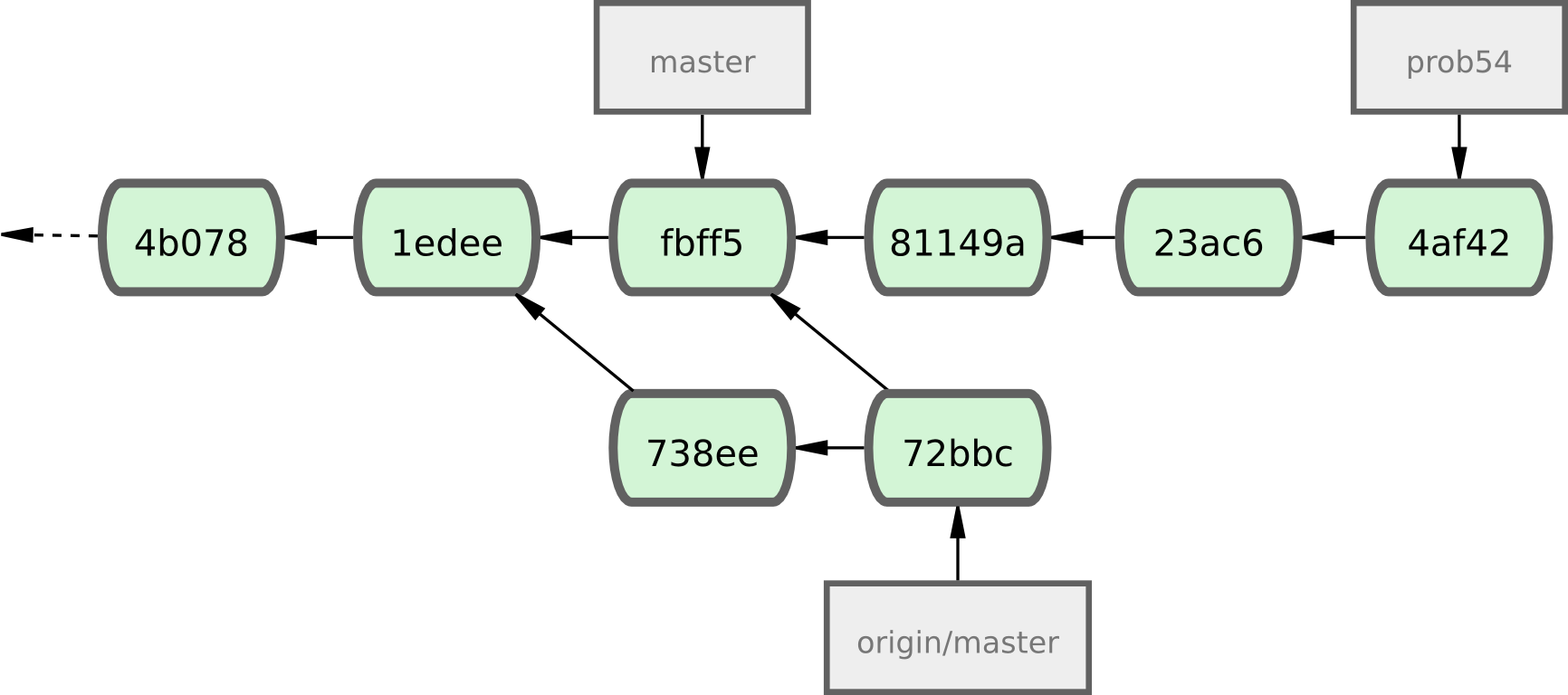 Figure 5-8. L'historique de Jessica après avoir récupéré les modifications de John.
Figure 5-8. L'historique de Jessica après avoir récupéré les modifications de John.
Jessica pense que sa branche thématique et prête mais elle souhaite savoir si elle doit fusionner son travail avant de pouvoir pousser.
Elle lance git log pour s'en assurer :
$ git log --no-merges origin/master ^issue54
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
Eliminer une valeur par defaut invalide
Maintenant, Jessica peut fusionner sa branche thématique dans sa branche master, fusionner le travail de John (origin/master)dans sa branche master, puis pousser le résultat sur le serveur.
Premièrement, elle rebascule sur sa branche master pour intégrer son travail :
$ git checkout master
Switched to branch "master"
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.
Elle peut fusionner soit origin/master soit prob54 en premier — les deux sont en avance, mais l'ordre n'importe pas.
L'instantané final devrait être identique quelque soit l'ordre de fusion qu'elle choisit.
Seul l'historique sera légèrement différent.
Elle choisit de fusionner en premier prob54 :
$ git merge prob54
Updating fbff5bc..4af4298
Fast forward
LISEZMOI | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)
Aucun problème n'apparaît.
Comme vous pouvez le voir, c'est une simple avance rapide.
Maintenant, Jessica fusionne le travail de John (origin/master) :
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
Tout a fusionné proprement et l'historique de Jessica ressemble à la figure 5-9.
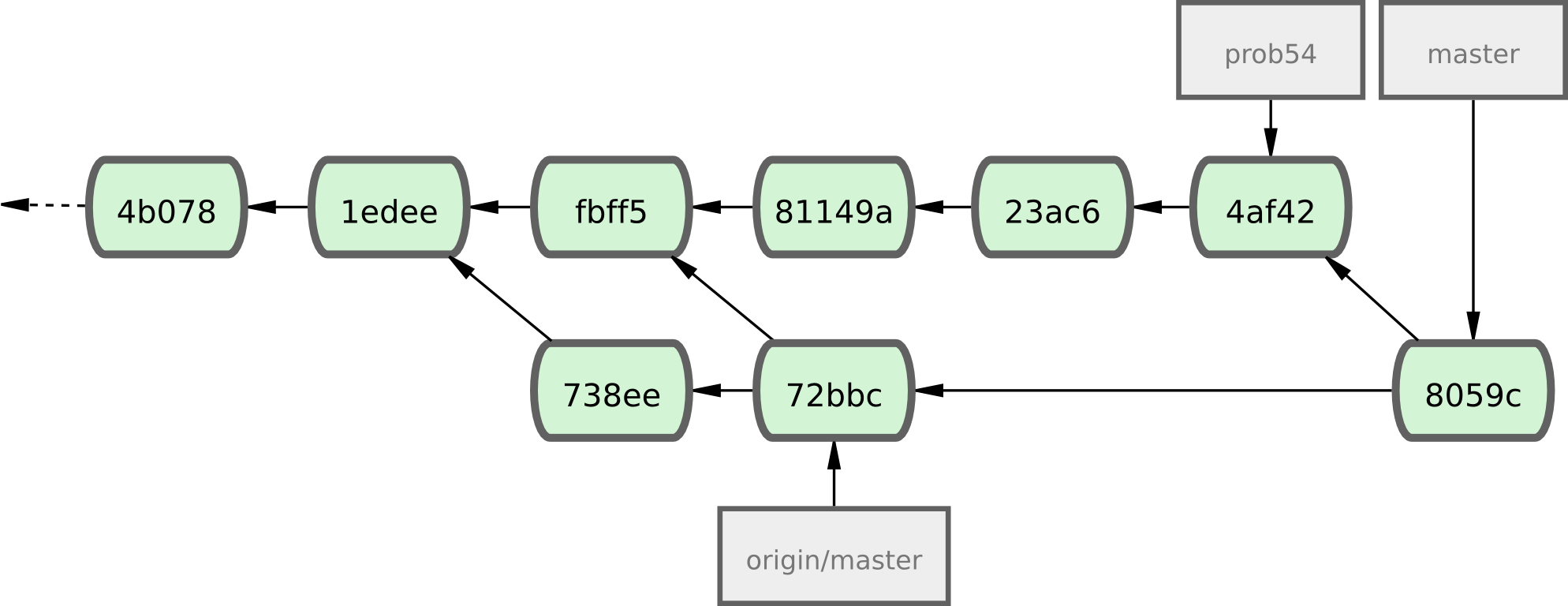 Figure 5-9. L'historique de Jessica après avoir fusionné les modifications de John.
Figure 5-9. L'historique de Jessica après avoir fusionné les modifications de John.
Maintenant origin/master est accessible depuis la branche master de Jessica, donc elle devrait être capable de pousser (en considérant que John n'a pas encore poussé dans l'intervalle) :
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> master
Chaque développeur a validé quelques fois et fusionné les travaux de l'autre avec succès (voir figure 5-10).
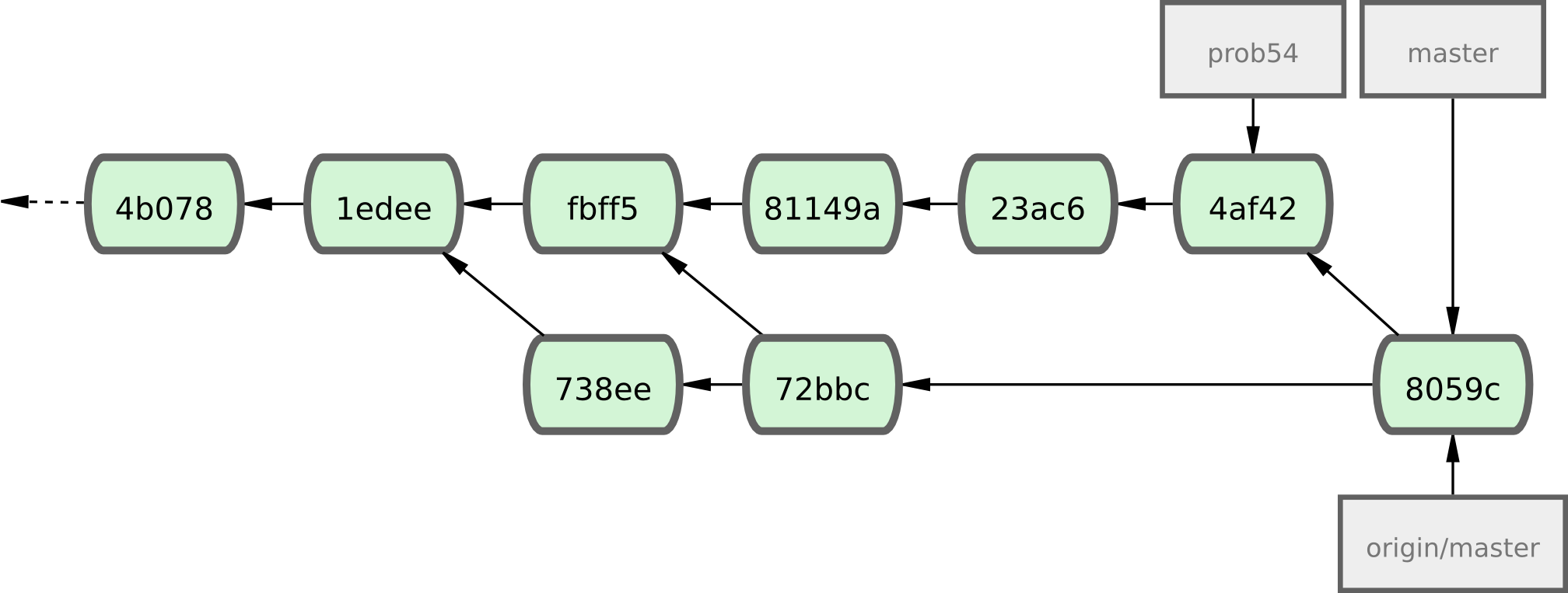 Figure 5-10. L'historique de Jessica après avoir poussé toutes ses modifications sur le serveur.
Figure 5-10. L'historique de Jessica après avoir poussé toutes ses modifications sur le serveur.
C'est un des schéma les plus simples.
Vous travaillez pendant quelques temps, généralement sur une branche thématique, et fusionnez dans votre branche master quand elle est prête à être intégrée.
Quand vous souhaitez partager votre travail, vous récupérez origin/master et la fusionnez si elle a changé, puis finalement vous poussez le résultat sur la branche master du serveur.
La séquence est illustrée par la figure 5-11.
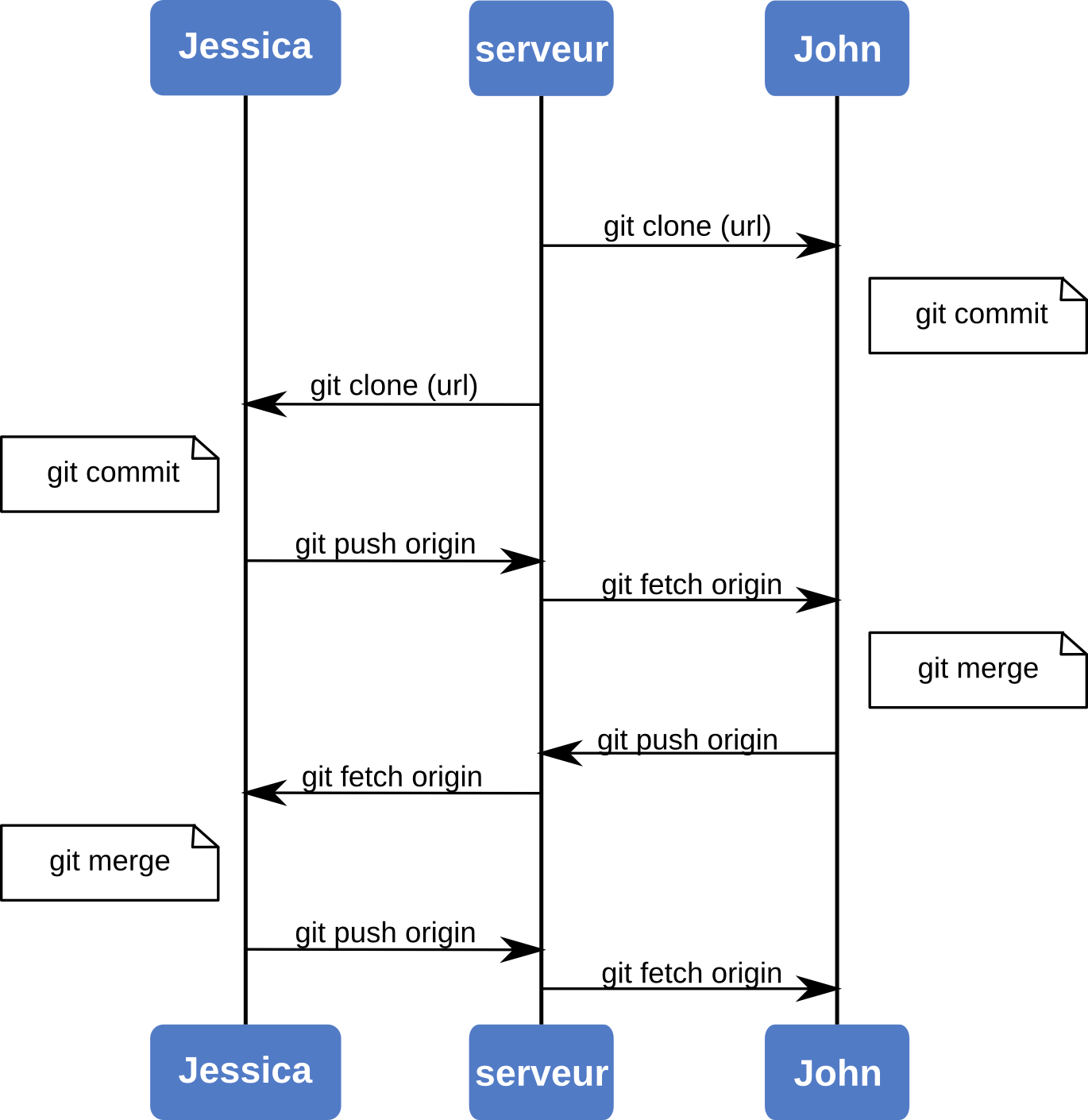 Figure 5-11. Séquence générale des évènements pour une utilisation simple multi-développeur de Git.
Figure 5-11. Séquence générale des évènements pour une utilisation simple multi-développeur de Git.
Dans le scénario suivant, nous aborderons les rôles de contributeur dans un groupe privé plus grand. Vous apprendrez comment travailler dans un environnement où des petits groupes collaborent sur des fonctionnalités, puis les contributions de chaque équipe sont intégrées par une autre entité.
Supposons que John et Jessica travaillent ensemble sur une première fonctionnalité, tandis que Jessica et Josie travaillent sur une autre.
Dans ce cas, l'entreprise utilise un mode d'opération de type « gestionnaire d'intégration » où le travail des groupes est intégré par certains ingénieurs, et la branche master du dépôt principal ne peut être mise à jour que par ces ingénieurs.
Dans ce scénario, tout le travail est validé dans des branches orientées équipe, et tiré plus tard par les intégrateurs.
Suivons le cheminement de Jessica tandis qu'elle travaille sur les deux nouvelles fonctionnalités, collaborant en parallèle avec deux développeurs différents dans cet environnement.
En supposant qu'elle a cloné son dépôt, elle décide de travailler sur la fonctionA en premier.
Elle crée une nouvelle branche pour cette fonction et travaille un peu dessus :
# Ordinateur de Jessica
$ git checkout -b fonctionA
Switched to a new branch "fonctionA"
$ vim lib/simplegit.rb
$ git commit -am 'Ajouter une limite à la fonction de log'
[fonctionA 3300904] Ajouter une limite à la fonction de log
1 files changed, 1 insertions(+), 1 deletions(-)
À ce moment, elle a besoin de partager son travail avec John, donc elle pousse les commits de sa branche fonctionA sur le serveur.
Jessica n'a pas le droit de pousser sur la branche master — seuls les intégrateurs l'ont — et elle doit donc pousser sur une autre branche pour collaborer avec John :
$ git push origin fonctionA
...
To jessica@githost:simplegit.git
* [new branch] fonctionA -> fonctionA
Jessica envoie un e-mail à John pour lui indiquer qu'elle a poussé son travail dans la branche appelée fonctionA et qu'il peut l'inspecter.
Pendant qu'elle attend le retour de John, Jessica décide de commencer à travailler sur la fonctionB avec Josie.
Pour commencer, elle crée une nouvelle branche thématique, à partir de la base master du serveur :
# Ordinateur de Jessica
$ git fetch origin
$ git checkout -b fonctionB origin/master
Switched to a new branch "fonctionB"
À présent, Jessica réalise quelques validations sur la branche fonctionB :
$ vim lib/simplegit.rb
$ git commit -am 'Rendre la fonction ls-tree recursive'
[fonctionB e5b0fdc] Rendre la fonction ls-tree recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'Ajout de ls-files'
[fonctionB 8512791] Ajout ls-files
1 files changed, 5 insertions(+), 0 deletions(-)
Le dépôt de Jessica ressemble à la figure 5-12.
 Figure 5-12. L'historique initial de Jessica.
Figure 5-12. L'historique initial de Jessica.
Elle est prête à pousser son travail, mais elle reçoit un mail de Josie indiquant qu'une branche avec un premier travail a déjà été poussé sur le serveur en tant que fonctionBee.
Jessica doit d'abord fusionner ces modifications avec les siennes avant de pouvoir pousser sur le serveur.
Elle peut récupérer les modifications de Josie avec git fetch :
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] fonctionBee -> origin/fonctionBee
Jessica peut à présent fusionner ceci dans le travail qu'elle a réalisé grâce à git merge :
$ git merge origin/fonctionBee
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)
Mais il y a un petit problème — elle doit pousser son travail fusionné dans sa branche fonctionB sur la branche fonctionBee du serveur.
Elle peut le faire en spécifiant la branche locale suivie de deux points (:) suivi de la branche distante à la commande git push :
$ git push origin fonctionB:fonctionBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 fonctionB -> fonctionBee
Cela s'appelle une refspec. Référez-vous au chapitre 9 pour une explication plus détaillée des refspecs Git et des possibilités qu'elles offrent.
Ensuite, John envoie un e-mail à Jessica pour lui indiquer qu'il a poussé des modifications sur la branche fonctionA et lui demander de les vérifier.
Elle lance git fetch pour tirer toutes ces modifications :
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d fonctionA -> origin/fonctionA
Elle peut alors voir ce qui a été modifié avec git log :
$ git log origin/fonctionA ^fonctionA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
largeur du log passee de 25 a 30
Finalement, elle fusionne le travail de John dans sa propre branche fonctionA :
$ git checkout fonctionA
Switched to branch "fonctionA"
$ git merge origin/fonctionA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Jessica veut régler quelques détails. Elle valide donc encore et pousse ses changements sur le serveur :
$ git commit -am 'details regles'
[fonctionA ed774b3] details regles
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push origin fonctionA
...
To jessica@githost:simplegit.git
3300904..ed774b3 fonctionA -> fonctionA
L'historique des commits de Jessica ressemble à présent à la figure 5-13.
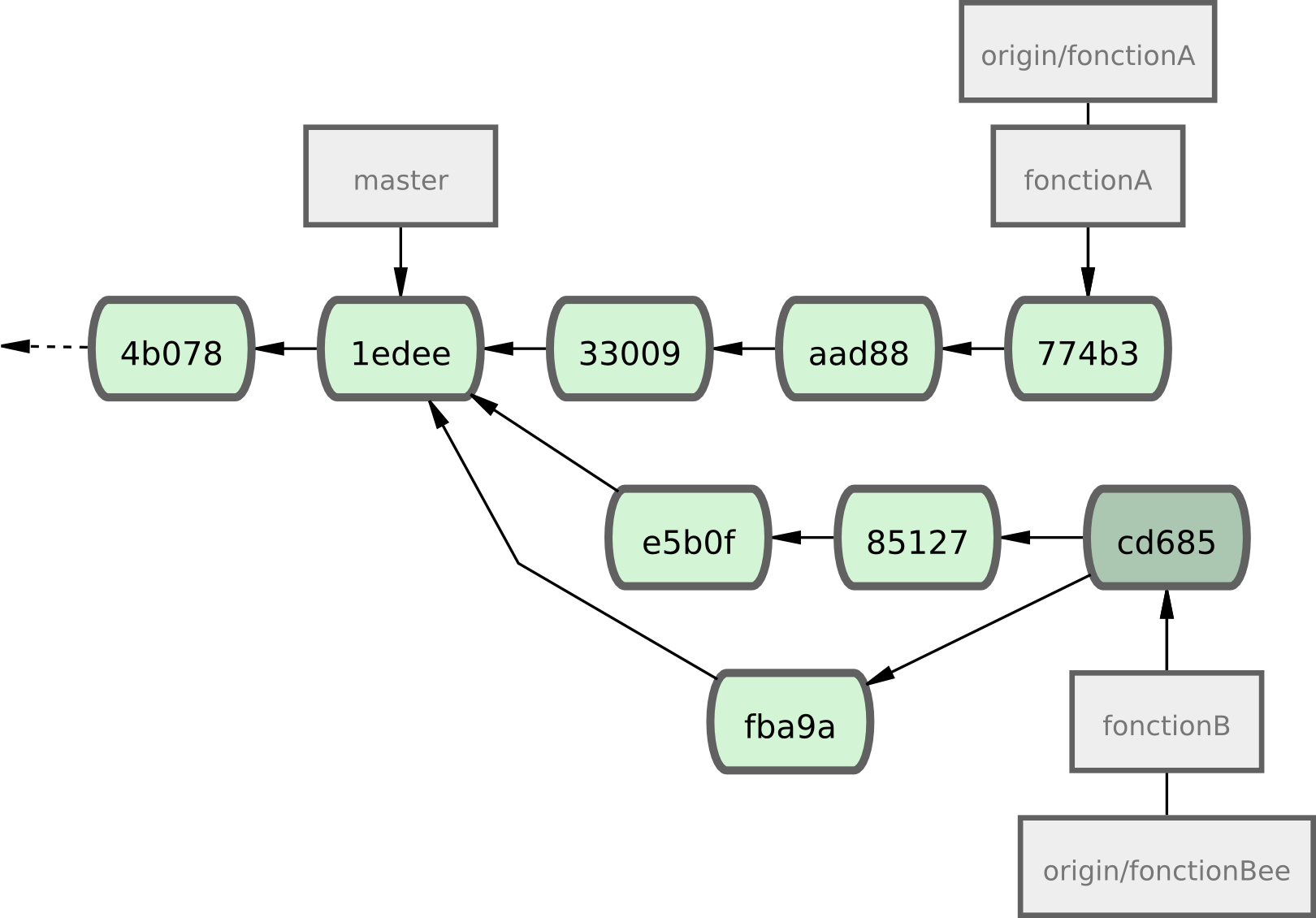 Figure 5-13. L'historique de Jessica après la validation dans la branche thématique.
Figure 5-13. L'historique de Jessica après la validation dans la branche thématique.
Jessica, Josie et John informent les intégrateurs que les branches fonctionA et fonctionB du serveur sont prêtes pour une intégration dans la branche principale.
Après cette intégration, une synchronisation apportera les commits de fusion, ce qui donnera un historique comme celui de la figure 5-14.
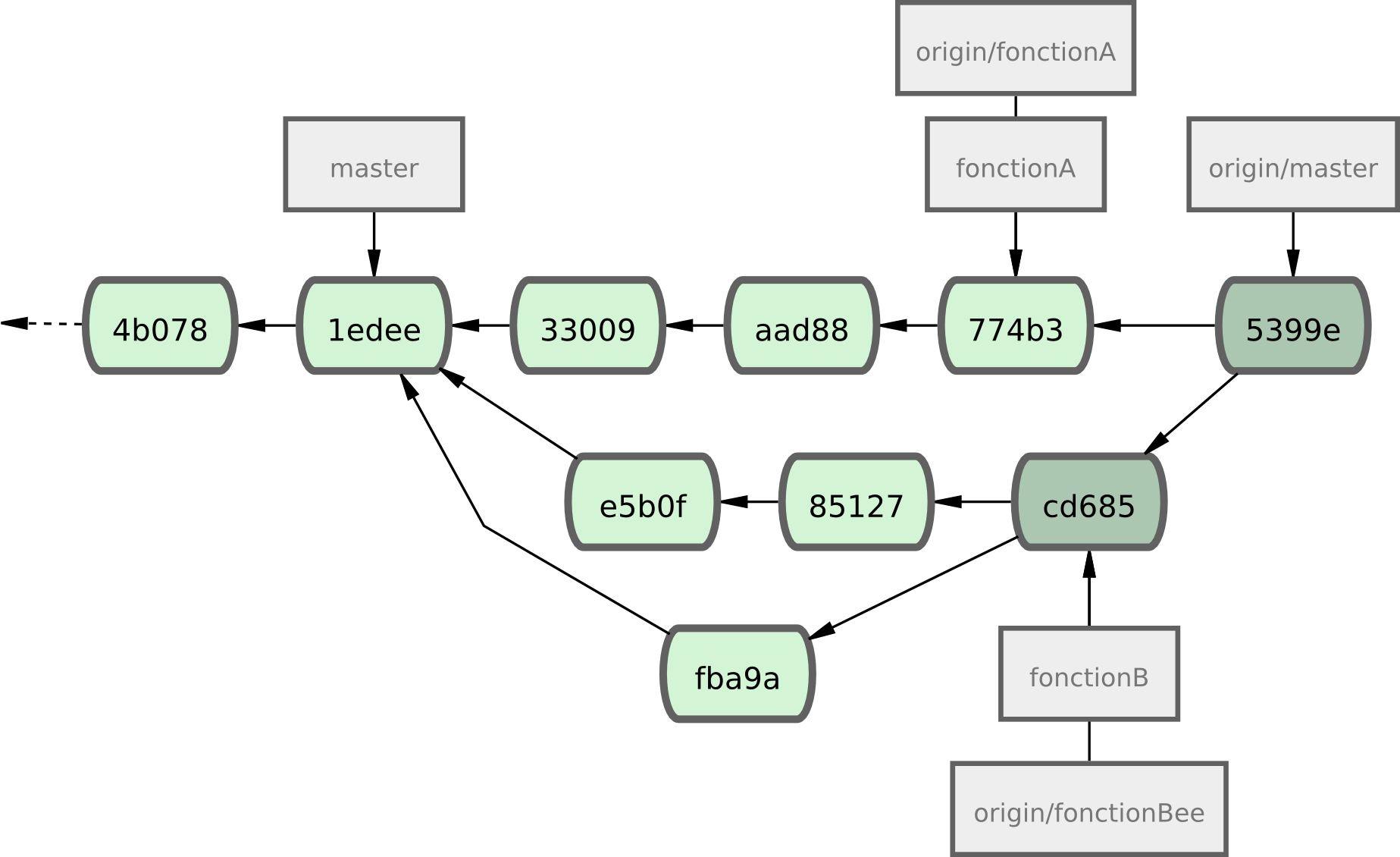 Figure 5-14. L'historique de Jessica après la fusion de ses deux branches thématiques.
Figure 5-14. L'historique de Jessica après la fusion de ses deux branches thématiques.
De nombreuses équipes basculent vers Git du fait de cette capacité à gérer plusieurs équipes travaillant en parallèle, fusionnant plusieurs lignes de développement très tard dans le processus de livraison. La capacité donnée à plusieurs sous-groupes d'équipes à collaborer au moyen de branches distantes sans nécessairement impacter le reste de l'équipe est un grand bénéfice apporté par Git. La séquence de travail qui vous a été décrite ressemble à la figure 5-15.
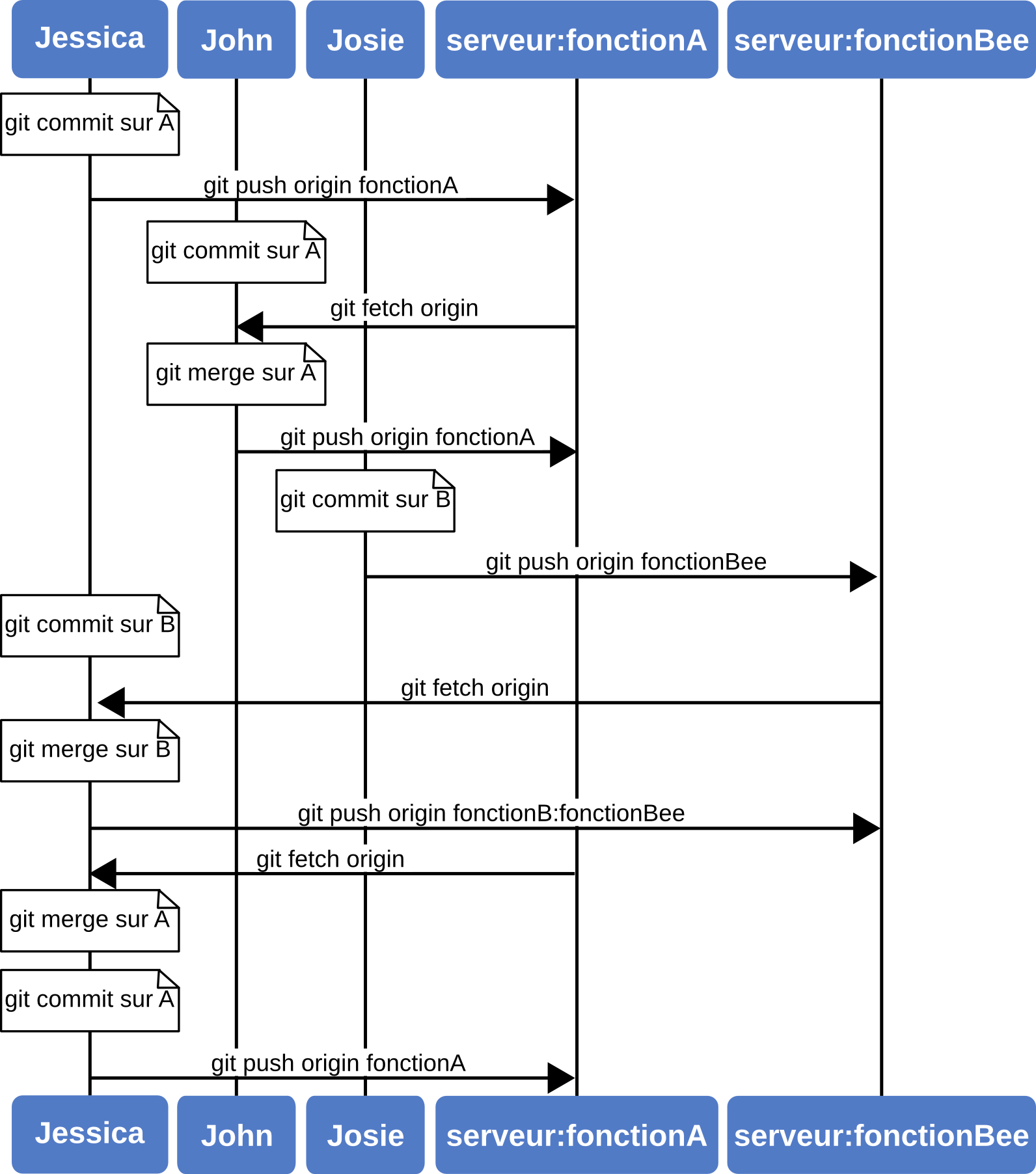 Figure 5-15. Une séquence simple de gestion orientée équipe.
Figure 5-15. Une séquence simple de gestion orientée équipe.
Contribuer à un projet public est assez différent. Il faut présenter le travail au mainteneur d'une autre manière parce que vous n'avez pas possibilité de mettre à jour directement des branches du projet. Ce premier exemple décrit un mode de contribution via des serveurs Git qui proposent facilement la duplication de dépôt. Les sites repo.or.cz ou GitHub proposent cette méthode, et de nombreux mainteneurs s'attendent à ce style de contribution. Le chapitre suivant traite des projets qui préfèrent accepter les contributions sous forme de patch via e-mail.
Premièrement, vous souhaiterez probablement cloner le dépôt principal, créer une nouvelle branche thématique pour le patch ou la série de patchs que seront votre contribution et commencer à travailler. La séquence ressemble globalement à ceci :
$ git clone (url)
$ cd projet
$ git checkout -b fonctionA
$ (travail)
$ git commit
$ (travail)
$ git commit
Vous pouvez utiliser rebase -i pour réduire votre travail à une seule validation ou pour réarranger les modifications dans des commits qui rendront les patchs plus faciles à relire pour le mainteneur — référez-vous au chapitre 6 pour plus d'information sur comment rebaser de manière interactive.
Lorsque votre branche de travail est prête et que vous êtes prêt à la fournir au mainteneur, rendez-vous sur la page du projet et cliquez sur le bouton "Fork" pour créer votre propre projet dupliqué sur lequel vous aurez les droits en écriture.
Vous devez alors ajouter l'URL de ce nouveau dépôt en tant que second dépôt distant, dans notre cas nommé macopie :
$ git remote add macopie (url)
Vous devez pousser votre travail sur cette branche distante.
C'est beaucoup plus facile de pousser la branche sur laquelle vous travaillez sur une branche distante que de fusionner et de pousser le résultat sur le serveur.
La raison principale en est que si le travail n'est pas accepté ou s'il est picoré, vous n'aurez pas à faire marche arrière sur votre branche master.
Si le mainteneur fusionne, rebase ou picore votre travail, vous le saurez en tirant depuis son dépôt :
$ git push macopie fonctionA
Une fois votre travail poussé sur votre copie du dépôt, vous devez notifier le mainteneur.
Ce processus est souvent appelé une demande de tirage (pull request) et vous pouvez la générer soit via le site web — GitHub propose un bouton « pull request » qui envoie automatiquement un message au mainteneur — soit lancer la commande git request-pull et envoyer manuellement par e-mail le résultat au mainteneur de projet.
La commande request-pull prend en paramètres la branche de base dans laquelle vous souhaitez que votre branche thématique soit fusionnée et l'URL du dépôt Git depuis lequel vous souhaitez qu'elle soit tirée, et génère un résumé des modifications que vous demandez à faire tirer.
Par exemple, si Jessica envoie à John une demande de tirage et qu'elle a fait deux validations dans la branche thématique qu'elle vient de pousser, elle peut lancer ceci :
$ git request-pull origin/master macopie
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
John Smith (1):
ajout d'une nouvelle fonction
are available in the git repository at:
git://githost/simplegit.git fonctionA
Jessica Smith (2):
Ajout d'une limite à la fonction de log
change la largeur du log de 25 a 30
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Le résultat peut être envoyé au mainteneur — cela lui indique d'où la modification a été branchée, le résumé des validations et d'où tirer ce travail.
Pour un projet dont vous n'êtes pas le mainteneur, il est généralement plus aisé de toujours laisser la branche master suivre origin\master et de réaliser vos travaux sur des branches thématiques que vous pourrez facilement effacer si elles sont rejetées.
Garder les thèmes de travaux isolés sur des branches thématiques facilite aussi leur rebasage si le sommet du dépôt principal a avancé dans l'intervalle et que vos modifications ne s'appliquent plus proprement.
Par exemple, si vous souhaitez soumettre un second sujet de travail au projet, ne continuez pas à travailler sur la branche thématique que vous venez de pousser mais démarrez en plutôt une depuis la branche master du dépôt principal :
$ git checkout -b fonctionB origin/master
$ (travail)
$ git commit
$ git push macopie fonctionB
$ (email au mainteneur)
$ git fetch origin
À présent, chaque sujet est contenu dans son propre silo — similaire à une file de patchs — que vous pouvez réécrire, rebaser et modifier sans que les sujets n'interfèrent ou ne dépendent entre eux, comme sur la figure 5-16.
[[figures/5.16.png|align=center|frame|width=500px|alt=Figure 5-16. Historique initial des commits avec les modification de fonctionB.]]
Supposons que le mainteneur du projet a tiré une poignée d'autres patchs et essayé par la suite votre première branche, mais celle-ci ne s'applique plus proprement.
Dans ce cas, vous pouvez rebaser cette branche au sommet de origin/master, résoudre les conflits pour le mainteneur et soumettre de nouveau vos modifications :
$ git checkout fonctionA
$ git rebase origin/master
$ git push –f macopie fonctionA
Cette action réécrit votre historique pour qu'il ressemble à la figure 5-17.
 Figure 5-17. Historique des validations après le travail sur fonctionA.
Figure 5-17. Historique des validations après le travail sur fonctionA.
Comme vous avez rebasé votre branche, vous devez spécifier l'option -f à votre commande pour pousser, pour forcer le remplacement de la branche fonctionA sur le serveur par la suite de commits qui n'en est pas descendante.
Une solution alternative serait de pousser ce nouveau travail dans une branche différente du serveur (appelée par exemple fonctionAv2).
Examinons un autre scénario possible : le mainteneur a revu les modifications dans votre seconde branche et apprécie le concept, mais il souhaiterait que vous changiez des détails d'implémentation.
Vous en profiterez pour rebaser ce travail sur le sommet actuel de la branche master du projet.
Vous démarrez une nouvelle branche à partir de la branche origin/master courante, y collez les modifications de fonctionB en résolvant les conflits, changez l'implémentation et poussez le tout en tant que nouvelle branche :
$ git checkout -b fonctionBv2 origin/master
$ git merge --no-commit --squash fonctionB
$ (changement d'implémentation)
$ git commit
$ git push macopie fonctionBv2
L'option --squash prend tout le travail de la branche à fusionner et le colle dans un commit sans fusion au sommet de la branche extraite.
L'option --no-commit indique à Git de ne pas enregistrer automatiquement une validation.
Cela permet de reporter toutes les modifications d'une autre branche, puis de réaliser d'autres modifications avant de réaliser une nouvelle validation.
À présent, vous pouvez envoyer au mainteneur un message indiquant que vous avez réalisé les modifications demandées et qu'il peut trouver cette nouvelle mouture sur votre branche fonctionBv2 (voir figure 5-18).
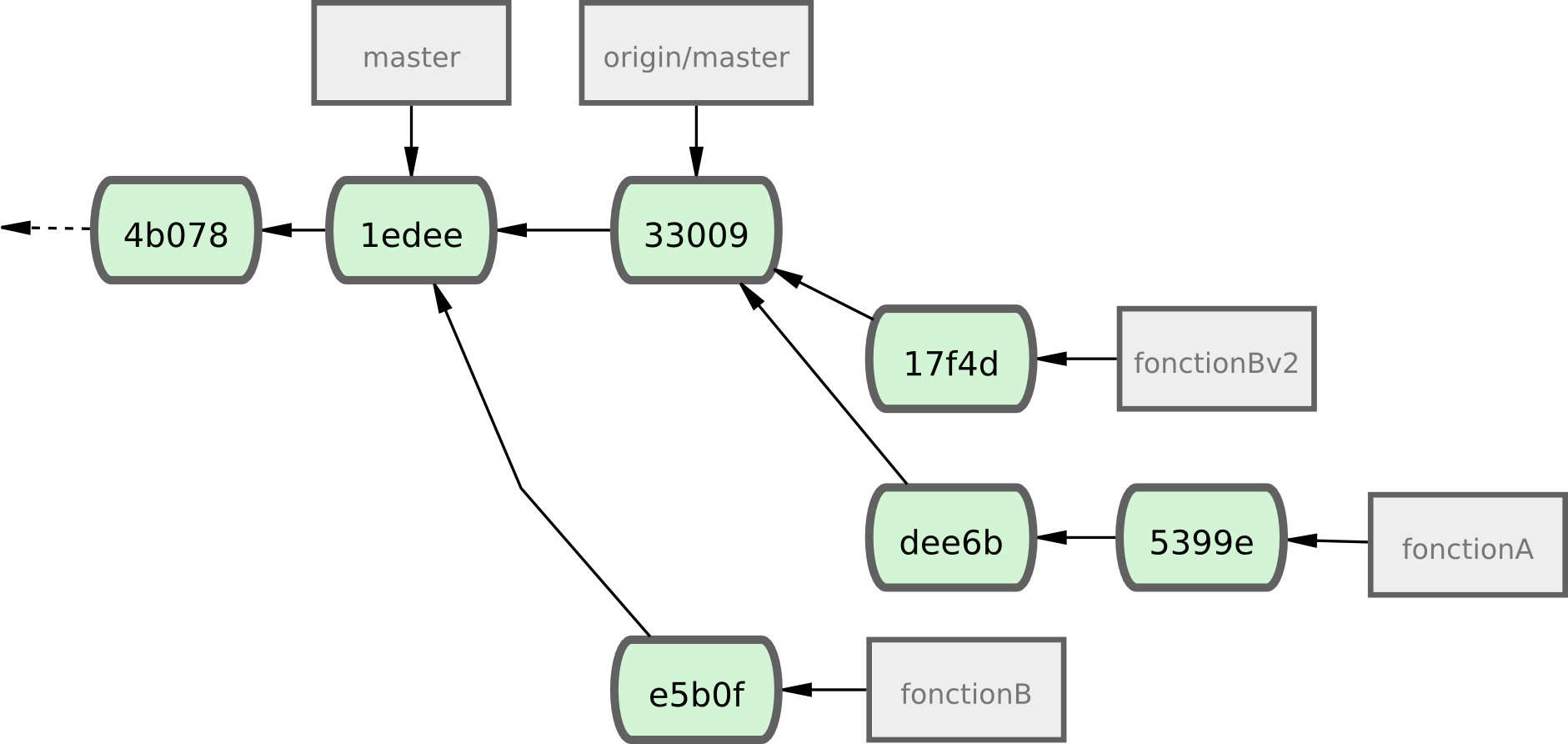 Figure 5-18. Historique des validations après le travail sur fonctionBv2.
Figure 5-18. Historique des validations après le travail sur fonctionBv2.
De nombreux grands projets ont des procédures établies pour accepter des patchs — il faut vérifier les règles spécifiques à chaque projet qui peuvent varier. Néanmoins, ils sont nombreux à accepter les patchs via une liste de diffusion de développement, ce que nous allons éclairer d'un exemple.
La méthode est similaire au cas précédent — vous créez une branche thématique par série de patchs sur laquelle vous travaillez. La différence réside dans la manière de les soumettre au projet. Au lieu de dupliquer le projet et de pousser vos soumissions sur votre dépôt, il faut générer des versions e-mail de chaque série de commits et les envoyer à la liste de diffusion de développement.
$ git checkout -b sujetA
$ (travail)
$ git commit
$ (travail)
$ git commit
Vous avez à présent deux commits que vous souhaitez envoyer à la liste de diffusion.
Vous utilisez git format-patch pour générer des fichiers au format mbox que vous pourrez envoyer à la liste.
Cette commande transforme chaque commit en un message e-mail dont le sujet est la première ligne du message de validation et le corps contient le reste du message plus le patch correspondant.
Un point intéressant de cette commande est qu'appliquer le patch à partir d'un e-mail formaté avec format-patch préserve toute l'information de validation comme nous le verrons dans le chapitre suivant lorsqu'il s'agira de l'appliquer.
$ git format-patch -M origin/master
0001-Ajout-d-une-limite-la-fonction-de-log.patch
0002-change-la-largeur-du-log-de-25-a-30.patch
La commande format-patch affiche les noms de fichiers de patch créés.
L'option -M indique à Git de suivre les renommages.
Le contenu des fichiers ressemble à ceci :
$ cat 0001-Ajout-d-une-limite-la-fonction-de-log.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] Ajout d'une limite à la fonction de log
Limite la fonctionnalité de log aux 20 premières lignes
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
1.6.2.rc1.20.g8c5b.dirty
Vous pouvez maintenant éditer ces fichiers de patch pour ajouter plus d'information à destination de la liste de diffusion mais que vous ne souhaitez par voir apparaître dans le message de validation.
Si vous ajoutez du texte entre la ligne -- et le début du patch (la ligne lib/simplegit.rb), les développeurs peuvent le lire mais l'application du patch ne le prend pas en compte.
Pour envoyer par e-mail ces fichiers, vous pouvez soit copier leur contenu dans votre application d'e-mail ou l'envoyer via une ligne de commande.
Le copier-coller cause souvent des problèmes de formatage, spécialement avec les applications « intelligentes » qui ne préservent pas les retours à la ligne et les types d'espace.
Heureusement, Git fournit un outil pour envoyer correctement les patchs formatés via IMAP, la méthode la plus facile.
Je démontrerai comment envoyer un patch via Gmail qui s'avère être la boite mail que j'utilise ; vous pourrez trouver des instructions détaillées pour de nombreuses applications de mail à la fin du fichier susmentionné Documentation/SubmittingPatches du code source de Git.
Premièrement, il est nécessaire de paramétrer la section imap de votre fichier ~/.gitconfig.
Vous pouvez positionner ces valeurs séparément avec une série de commandes git config, ou vous pouvez les ajouter manuellement.
À la fin, le fichier de configuration doit ressembler à ceci :
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = p4ssw0rd
port = 993
sslverify = false
Si votre serveur IMAP n'utilise pas SSL, les deux dernières lignes ne sont probablement pas nécessaires et le paramètre host commencera par imap:// au lieu de imaps://.
Quand c'est fait, vous pouvez utiliser la commande git send-email pour placer la série de patchs dans le répertoire Drafts du serveur IMAP spécifié :
$ git send-email *.patch
0001-Ajout-d-une-limite-la-fonction-de-log.patch
0002-change-la-largeur-du-log-de-25-a-30.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? y
La première question demande l'adresse mail d'origine (avec par défaut celle saisie en config), tandis que la seconde demande les destinataires. Enfin la dernière question sert à indiquer que l'on souhaite poster la série de patchs comme une réponse au premier patch de la série, créant ainsi un fil de discussion unique pour cette série. Ensuite, Git crache un certain nombre d'informations qui ressemblent à ceci pour chaque patch à envoyer :
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] Ajout d'une limite à la-fonction de log
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OK
À présent, vous devriez pouvoir vous rendre dans le répertoire Drafts, changer le champ destinataire pour celui de la liste de diffusion, y ajouter optionnellement en copie le mainteneur du projet ou le responsable et l'envoyer.
Ce chapitre a traité quelques unes des méthodes communes de gestion de types différents de projets Git que vous pourrez rencontrer et a introduit un certain nombre de nouveaux outils pour vous aider à gérer ces processus. Dans la section suivante, nous allons voir comment travailler de l'autre côté de la barrière : en tant que mainteneur de projet Git. Vous apprendrez comment travailler comme dictateur bénévole ou gestionnaire d'intégration.
En plus de savoir comment contribuer efficacement à un projet, vous aurez probablement besoin de savoir comment en maintenir un.
Cela peut consister à accepter et appliquer les patchs générés via format-patch et envoyés par e-mail, ou à intégrer des modifications dans des branches distantes de dépôts distants.
Que vous mainteniez le dépôt de référence ou que vous souhaitiez aider en vérifiant et approuvant les patchs, vous devez savoir comment accepter les contributions d'une manière limpide pour vos contributeurs et soutenable à long terme pour vous.
Quand vous vous apprêtez à intégrer des contributions, un bonne idée consiste à les essayer d'abord dans une branche thématique, une branche temporaire spécifiquement créée pour essayer cette nouveauté.
De cette manière, il est plus facile de rectifier un patch à part et de le laisser s'il ne fonctionne pas jusqu'à ce que vous disposiez de temps pour y travailler.
Si vous créez une simple branche nommée d'après le thème de la modification que vous allez essayer, telle que ruby_client ou quelque chose d'aussi descriptif, vous pouvez vous en souvenir simplement plus tard.
Le mainteneur du projet Git a l'habitude d'utiliser des espaces de nommage pour ses branches, tels que sc/ruby_client, où sc représente les initiales de la personne qui a contribué les modifications.
Comme vous devez vous en souvenir, on crée une branche à part du master de la manière suivante :
$ git branch sc/ruby_client master
Ou bien, si vous voulez aussi basculer immédiatement dessus, vous pouvez utiliser l'option checkout -b :
$ git checkout -b sc/ruby_client master
Vous voilà maintenant prêt à ajouter les modifications sur cette branche thématique et à déterminer si c'est prêt à être fusionné dans les branches au long cours.
Si vous recevez par e-mail un patch que vous devez intégrer à votre projet, vous avez besoin d'appliquer le patch dans une branche thématique pour l'évaluer.
Il existe deux méthodes pour appliquer un patch envoyé par e-mail : git apply et git am.
Si vous avez reçu le patch de quelqu'un qui l'a généré avec la commande git diff ou diff Unix, vous pouvez l'appliquer avec la commande git apply.
Si le patch a été sauvé comme fichier /tmp/patch-ruby-client.patch, vous pouvez l'appliquer comme ceci :
$ git apply /tmp/patch-ruby-client.patch
Les fichiers dans votre copie de travail sont modifiés.
C'est quasiment identique à la commande patch -p1 qui applique directement les patchs mais en plus paranoïaque et moins tolérant sur les concordances approximatives.
Les ajouts, effacements et renommages de fichiers sont aussi gérés s'ils sont décrits dans le format git diff, ce que patch ne supporte pas.
Enfin, git apply fonctionne en mode « applique tout ou refuse tout » dans lequel toutes les modifications proposées sont appliquées si elles le peuvent, sinon rien n'est modifié là où patch peut n'appliquer que partiellement les patchs, laissant le répertoire de travail dans un état intermédiaire.
git apply est par dessus tout plus paranoïaque que patch.
Il ne créera pas une validation à votre place : après l'avoir lancé, vous devrez indexer et valider les modifications manuellement.
Vous pouvez aussi utiliser git apply pour voir si un patch s'applique proprement avant de réellement l'appliquer — vous pouvez lancer git apply --check avec le patch :
$ git apply --check 0001-seeing-if-this-helps-the-gem.patch
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
S'il n'y pas de message, le patch devrait s'appliquer proprement. Cette commande se termine avec un statut non-nul si la vérification échoue et vous pouvez donc l'utiliser dans des scripts.
Si le contributeur est un utilisateur de Git qui a été assez gentil d'utiliser la commande format-patch pour générer ses patchs, votre travail sera facilité car le patch contient alors déjà l'information d'auteur et le message de validation.
Si possible, encouragez vos contributeurs à utiliser format-patch au lieu de patch pour générer les patchs qu'ils vous adressent.
Vous ne devriez avoir à n'utiliser git apply que pour les vrais patchs.
Pour appliquer un patch généré par format-patch, vous utilisez git am.
Techniquement, git am s'attend à lire un fichier au format mbox, qui est un format texte simple permettant de stocker un ou plusieurs messages e-mail dans un unique fichier texte.
Un fichier ressemble à ceci :
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] Ajout d'une limite à la fonction de log
Limite la fonctionnalité de log aux 20 premières lignes
C'est le début de ce que la commande format-patch affiche, comme vous avez vu dans la section précédente.
C'est aussi un format e-mail mbox parfaitement valide.
Si quelqu'un vous a envoyé par e-mail un patch correctement formaté en utilisant git send-mail et que vous le téléchargez en format mbox, vous pouvez pointer git am sur ce fichier mbox et il commencera à appliquer tous les patchs contenus.
Si vous utilisez un client e-mail qui sait sauver plusieurs messages au format mbox, vous pouvez sauver la totalité de la série de patchs dans un fichier et utiliser git am pour les appliquer tous en une fois.
Néanmoins, si quelqu'un a déposé un fichier de patch généré via format-patch sur un système de suivi de faits techniques ou quelque chose similaire, vous pouvez toujours sauvegarder le fichier localement et le passer à git am pour l'appliquer :
$ git am 0001-limite-la-fonction-de-log.patch
Applying: Ajout d'une limite à la fonction de log
Vous remarquez qu'il s'est appliqué proprement et a créé une nouvelle validation pour vous.
L'information d'auteur est extraite des entêtes From et Date tandis que le message de validation est repris du champ Subject et du corps (avant le patch) du message.
Par exemple, si le patch est appliqué depuis le fichier mbox ci-dessus, la validation générée ressemblerait à ceci :
$ git log --pretty=fuller -1
commit 6c5e70b984a60b3cecd395edd5b48a7575bf58e0
Author: Jessica Smith <jessica@example.com>
AuthorDate: Sun Apr 6 10:17:23 2008 -0700
Commit: Scott Chacon <schacon@gmail.com>
CommitDate: Thu Apr 9 09:19:06 2009 -0700
Ajout d'une limite à la fonction de log
Limite la fonctionnalité de log aux 20 premières lignes
L'information Commit indique la personne qui a appliqué le patch et la date d'application.
L'information Author indique la personne qui a créé le patch et la date de création.
Il reste la possibilité que le patch ne s'applique pas proprement.
Peut-être votre branche principale a déjà trop divergé de la branche sur laquelle le patch a été construit, ou le patch dépend d'un autre patch qui n'a pas encore été appliqué.
Dans ce cas, le processus de git am échouera et vous demandera ce que vous souhaitez faire :
$ git am 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Patch failed at 0001.
When you have resolved this problem run "git am --resolved".
If you would prefer to skip this patch, instead run "git am --skip".
To restore the original branch and stop patching run "git am --abort".
Cette commande introduit des marqueurs de conflit dans tous les fichiers qui ont généré un problème, de la même manière qu'un conflit de fusion ou de rebasage.
Vous pouvez résoudre les problèmes de manière identique — éditez le fichier pour résoudre les conflits, indexez le nouveau fichier, puis lancez git am --resolved pour continuer avec le patch suivant :
$ (correction du fichier)
$ git add ticgit.gemspec
$ git am --resolved
Applying: seeing if this helps the gem
Si vous souhaitez que Git essaie de résoudre les conflits avec plus d'intelligence, vous pouvez passer l'option -3 qui demande à Git de tenter une fusion à trois sources.
Cette option n'est pas active par défaut parce qu'elle ne fonctionne pas si le commit sur lequel le patch indique être basé n'existe pas dans votre dépôt.
Si par contre, le patch est basé sur un commit public, l'option -3 est généralement beaucoup plus fine pour appliquer des patchs conflictuels :
$ git am -3 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Using index info to reconstruct a base tree...
Falling back to patching base and 3-way merge...
No changes -- Patch already applied.
Dans ce cas, je cherchais à appliquer un patch qui avait déjà été intégré.
Sans l'option -3, cela aurait ressemblé à un conflit.
Si vous appliquez des patchs à partir d'un fichier mbox, vous pouvez aussi lancer la commande am en mode interactif qui s'arrête à chaque patch trouvé et vous demande si vous souhaitez l'appliquer :
$ git am -3 -i mbox
Commit Body is:
--------------------------
seeing if this helps the gem
--------------------------
Apply? [y]es/[n]o/[e]dit/[v]iew patch/[a]ccept all
C'est agréable si vous avez un certain nombre de patchs sauvegardés parce que vous pouvez voir les patchs pour vous rafraîchir la mémoire et ne pas les appliquer s'ils ont déjà été intégrés.
Quand tous les patchs pour votre sujet ont été appliqués et validés dans votre branche, vous pouvez choisir si et comment vous souhaitez les intégrer dans une branche au long cours.
Si votre contribution a été fournie par un utilisateur de Git qui a mis en place son propre dépôt public sur lequel il a poussé ses modifications et vous a envoyé l'URL du dépôt et le nom de la branche distante, vous pouvez les ajouter en tant que dépôt distant et réaliser les fusions localement.
Par exemple, si Jessica vous envoie un e-mail indiquant qu'elle a une nouvelle fonctionnalité géniale dans la branche ruby-client de son dépôt, vous pouvez la tester en ajoutant le dépôt distant et en tirant la branche localement :
$ git remote add jessica git://github.com/jessica/monprojet.git
$ git fetch jessica
$ git checkout -b rubyclient jessica/ruby-client
Si elle vous envoie un autre mail indiquant une autre branche contenant une autre fonctionnalité géniale, vous pouvez la récupérer et la tester simplement à partir de votre référence distante.
C'est d'autant plus utile si vous travaillez en continu avec une personne. Si quelqu'un n'a qu'un seul patch à contribuer de temps en temps, l'accepter via e-mail peut s'avérer moins consommateur en temps de préparation du serveur public, d'ajout et retrait de branches distantes juste pour tirer quelques patchs. Vous ne souhaiteriez sûrement pas devoir gérer des centaines de dépôts distants pour intégrer à chaque fois un ou deux patchs. Néanmoins, des scripts et des services hébergés peuvent rendre cette tâche moins ardue. Cela dépend largement de votre manière de développer et de celle de vos contributeurs.
Cette approche a aussi l'avantage de vous fournir l'historique des validations.
Même si vous pouvez rencontrer des problèmes de fusion légitimes, vous avez l'information dans votre historique de la base ayant servi pour les modifications contribuées.
La fusion à trois sources est choisie par défaut plutôt que d'avoir à spécifier l'option -3 en espérant que le patch a été généré à partir d'un instantané public auquel vous auriez accès.
Si vous ne travaillez pas en continu avec une personne mais souhaitez tout de même tirer les modifications de cette manière, vous pouvez fournir l'URL du dépôt distant à la commande git pull.
Cela permet de réaliser un tirage unique sans sauver l'URL comme référence distante :
$ git pull git://github.com/typeunique/projet.git
From git://github.com/typeunique/projet
* branch HEAD -> FETCH_HEAD
Merge made by recursive.
Vous avez maintenant une branche thématique qui contient les contributions. De ce point, vous pouvez déterminer ce que vous souhaitez en faire. Cette section revisite quelques commandes qui vont vous permettre de faire une revue de ce que vous allez exactement introduire si vous fusionnez dans la branche principale.
Faire une revue de tous les commits dans cette branche s'avère souvent d'une grande aide.
Vous pouvez exclure les commits de la branche master en ajoutant l'option --not devant le nom de la branche.
Par exemple, si votre contributeur vous envoie deux patchs et que vous créez une branche appelée contrib et y appliquez ces patchs, vous pouvez lancer ceci :
$ git log contrib --not master
commit 5b6235bd297351589efc4d73316f0a68d484f118
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Oct 24 09:53:59 2008 -0700
seeing if this helps the gem
commit 7482e0d16d04bea79d0dba8988cc78df655f16a0
Author: Scott Chacon <schacon@gmail.com>
Date: Mon Oct 22 19:38:36 2008 -0700
updated the gemspec to hopefully work better
Pour visualiser les modifications que chaque commit introduit, souvenez-vous que vous pouvez passer l'option -p à git log et elle ajoutera le diff introduit à chaque commit.
Pour visualiser un diff complet de ce qui arriverait si vous fusionniez cette branche thématique avec une autre branche, vous pouvez utiliser un truc bizarre pour obtenir les résultats corrects. Vous pourriez penser à lancer ceci :
$ git diff master
Cette commande affiche un diff mais elle peut être trompeuse.
Si votre branche master a avancé depuis que vous en avez créé la branche thématique, vous obtiendrez des résultats apparemment étranges.
Cela arrive parce que Git compare directement l'instantané de la dernière validation sur la branche thématique et celui de la dernière validation sur la branche master.
Par exemple, si vous avez ajouté une ligne dans un fichier sur la branche master, une comparaison directe donnera l'impression que la branche thématique va retirer cette ligne.
Si master est un ancêtre directe de la branche thématique, ce n'est pas un problème.
Si les deux historiques ont divergé, le diff donnera l'impression que vous ajoutez toutes les nouveautés de la branche thématique et retirez tout ce qui a été fait depuis dans la branche master.
Ce que vous souhaitez voir en fait, ce sont les modifications ajoutées sur la branche thématique — le travail que vous introduirez si vous fusionnez cette branche dans master.
Vous obtenez ce résultat en demandant à Git de comparer le dernier instantané de la branche thématique avec son ancêtre commun à la branche master le plus récent.
Techniquement, c'est réalisable en déterminant exactement l'ancêtre commun et en lançant la commande diff dessus :
$ git merge-base contrib master
36c7dba2c95e6bbb78dfa822519ecfec6e1ca649
$ git diff 36c7db
Néanmoins, comme ce n'est pas très commode, Git fournit un raccourci pour réaliser la même chose : la syntaxe à trois points.
Dans le contexte de la commande diff, vous pouvez placer trois points après une autre branche pour réaliser un diff entre le dernier instantané de la branche sur laquelle vous vous trouvez et son ancêtre commun avec une autre branche :
$ git diff master...contrib
Cette commande ne vous montre que les modifications que votre branche thématique a introduites depuis son ancêtre commun avec master. C'est une syntaxe très simple à retenir.
Lorsque tout le travail de votre branche thématique est prêt à être intégré dans la branche principale, il reste à savoir comment le faire. De plus, il faut connaître le mode de gestion que vous souhaitez pour votre projet. Vous avez de nombreux choix et je vais en traiter quelques uns.
Un mode simple fusionne votre travail dans la branche master.
Dans ce scénario, vous avez une branche master qui contient le code stable.
Quand vous avez des modifications prêtes dans une branche thématique, vous la fusionnez dans votre branche master puis effacez la branche thématique, et ainsi de suite.
Si vous avez un dépôt contenant deux branches nommées ruby_client et php_client qui ressemble à la figure 5-19 et que vous fusionnez ruby_client en premier, suivi de php_client, alors votre historique ressemblera à la fin à la figure 5-20.
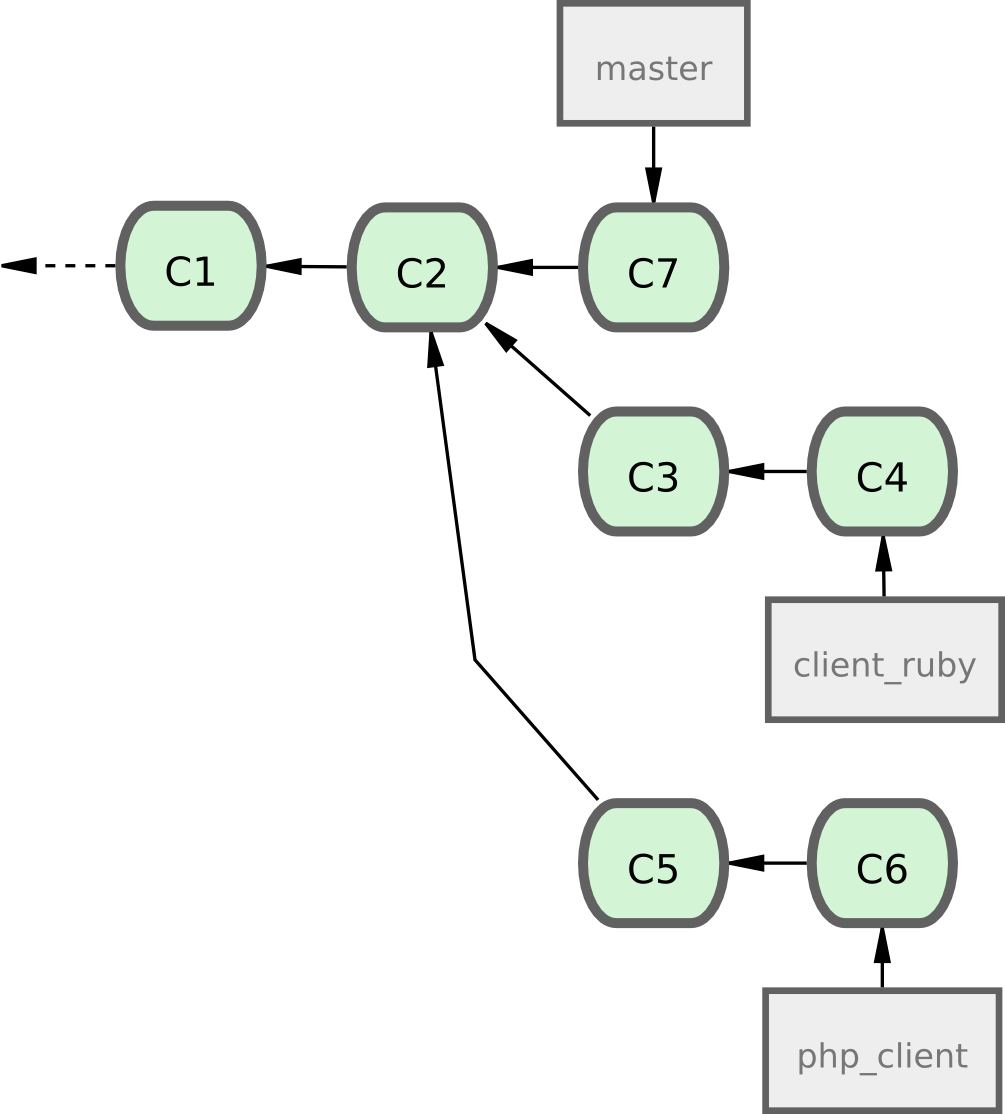 Figure 5-19. Historique avec quelques branches thématiques.
Figure 5-19. Historique avec quelques branches thématiques.
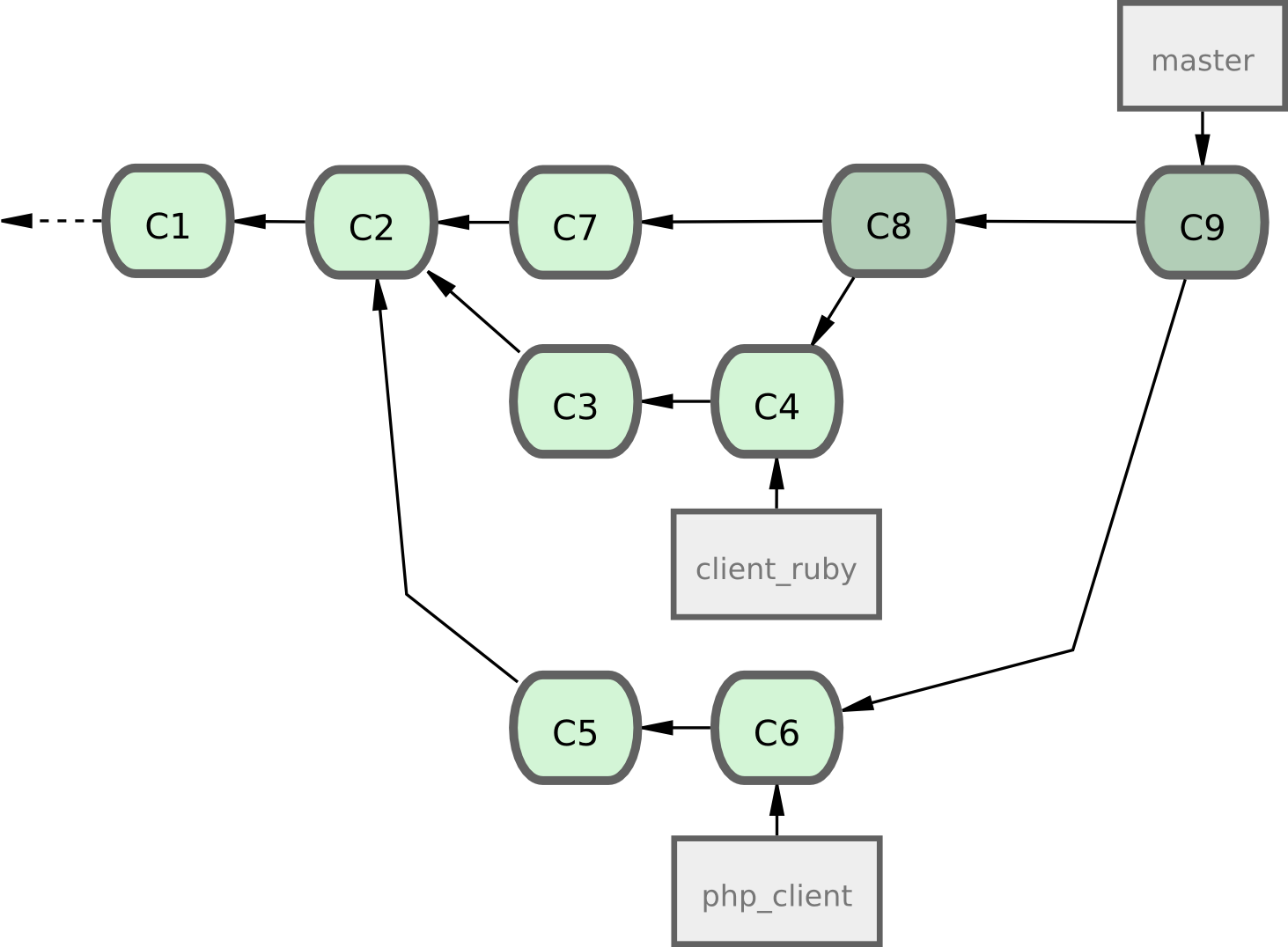 Figure 5-20. Après fusion d'une branche thématique.
Figure 5-20. Après fusion d'une branche thématique.
C'est probablement le mode le plus simple mais cela peut s'avérer problématique si vous avez à gérer des dépôts ou des projets plus gros.
Si vous avez plus de développeurs ou un projet plus important, vous souhaiterez probablement utiliser un cycle à fusion à au moins deux étapes.
Dans ce scénario, vous avez deux branches au long cours, master et develop, dans lequel vous déterminez que master est mis à jour seulement lors d'une version vraiment stable et tout le nouveau code est intégré dans la branche develop.
Vous poussez régulièrement ces deux branches sur le dépôt public.
Chaque fois que vous avez une nouvelle branche thématique à fusionner (figure 5-21), vous la fusionnez dans develop (figure 5-22).
Puis, lorsque vous étiquetez une version majeure, vous mettez master à niveau avec l'état stable de develop en avance rapide (figure 5-23).
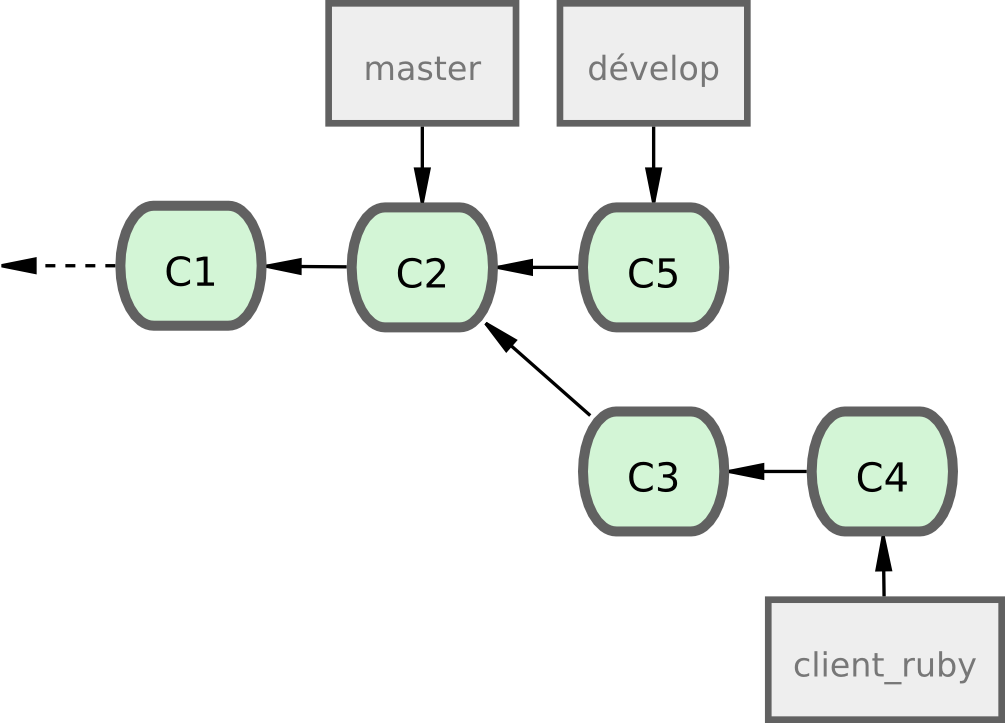 Figure 5-21. Avant la fusion d'une branche thématique.
Figure 5-21. Avant la fusion d'une branche thématique.
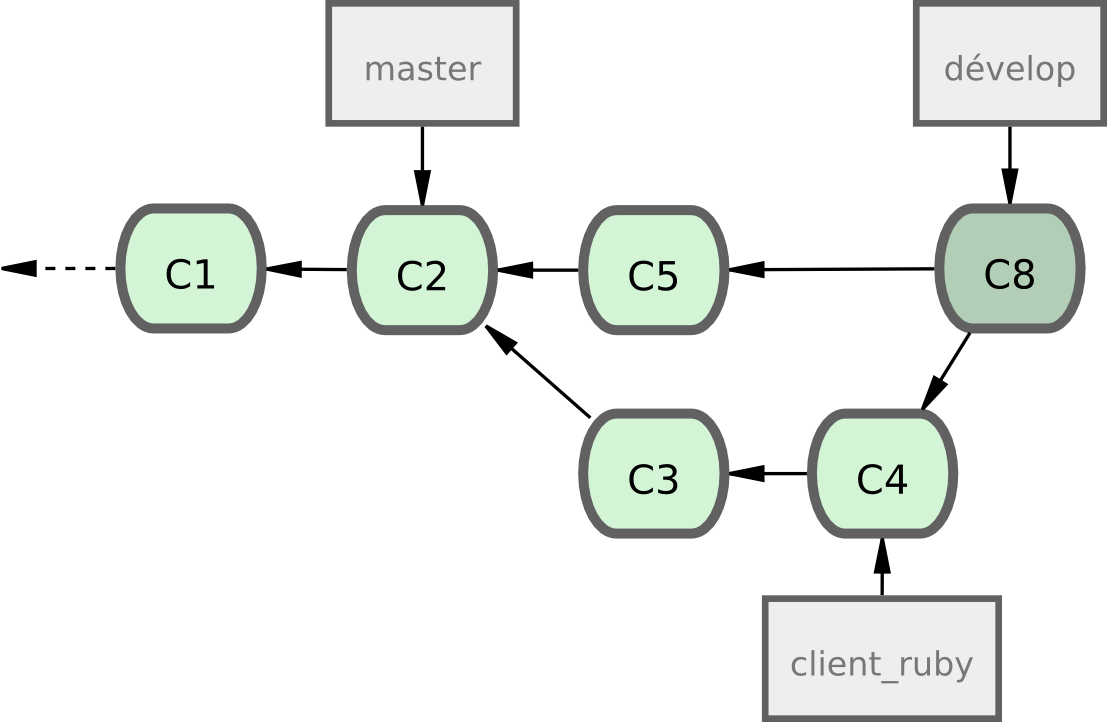 Figure 5-22. Après la fusion d'une branche thématique.
Figure 5-22. Après la fusion d'une branche thématique.
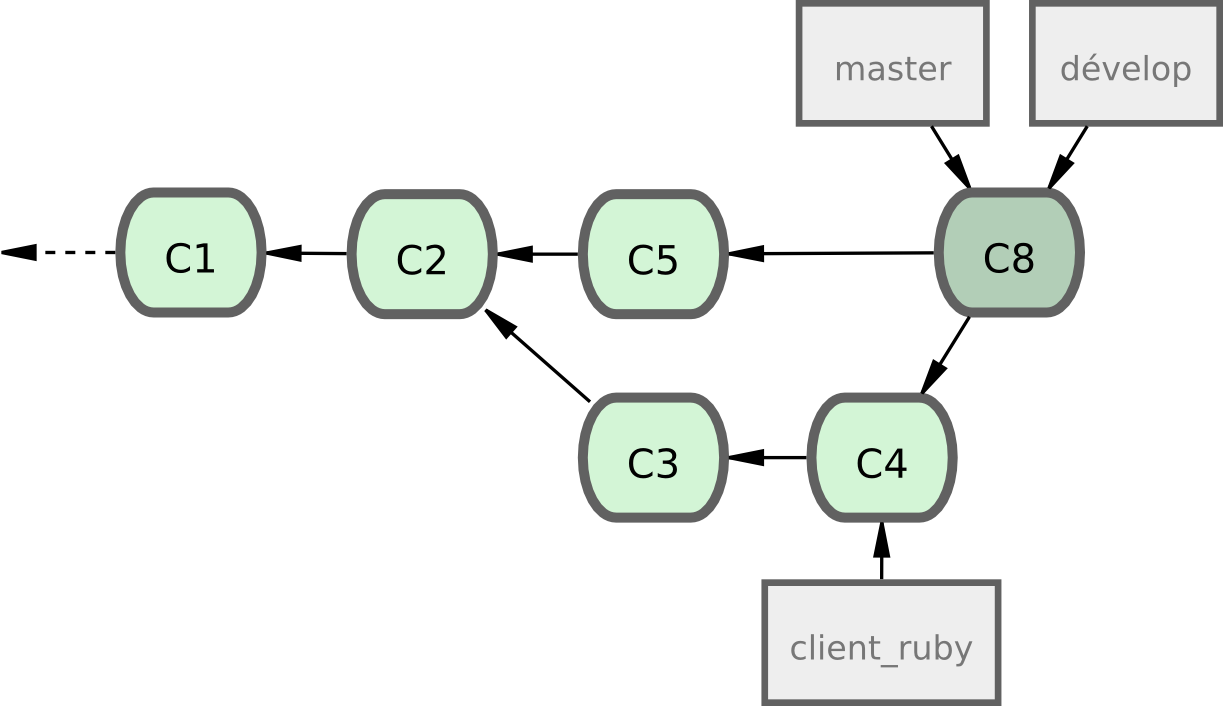 Figure 5-23. Après une publication d'une branche thématique.
Figure 5-23. Après une publication d'une branche thématique.
Ainsi, lorsque l'on clone le dépôt de votre projet, on peut soit extraire la branche master pour construire la dernière version stable et mettre à jour facilement ou on peut extraire le branche develop qui représente le nec plus ultra du développement.
Vous pouvez aussi continuer ce concept avec une branche d'intégration où tout le travail est fusionné.
Alors, quand la base de code sur cette branche est stable et que les tests passent, vous la fusionnez dans la branche develop.
Quand cela s'est avéré stable pendant un certain temps, vous mettez à jour la branche master en avance rapide.
Le projet Git dispose de quatre branches au long cours : master, next, pu (proposed updates : propositions) pour les nouveaux travaux et maint pour les backports de maintenance.
Quand une nouvelle contribution est proposée, elle est collectée dans des branches thématiques dans le dépôt du mainteneur d'une manière similaire à ce que j'ai décrit (voir figure 5-24).
A ce point, les fonctionnalités sont évaluées pour déterminer si elles sont stables et prêtes à être consommées ou si elles nécessitent un peaufinage.
Si elles sont stables, elles sont fusionnées dans next et cette branche est poussée sur le serveur public pour que tout le monde puisse essayer les fonctionnalités intégrées ensemble.
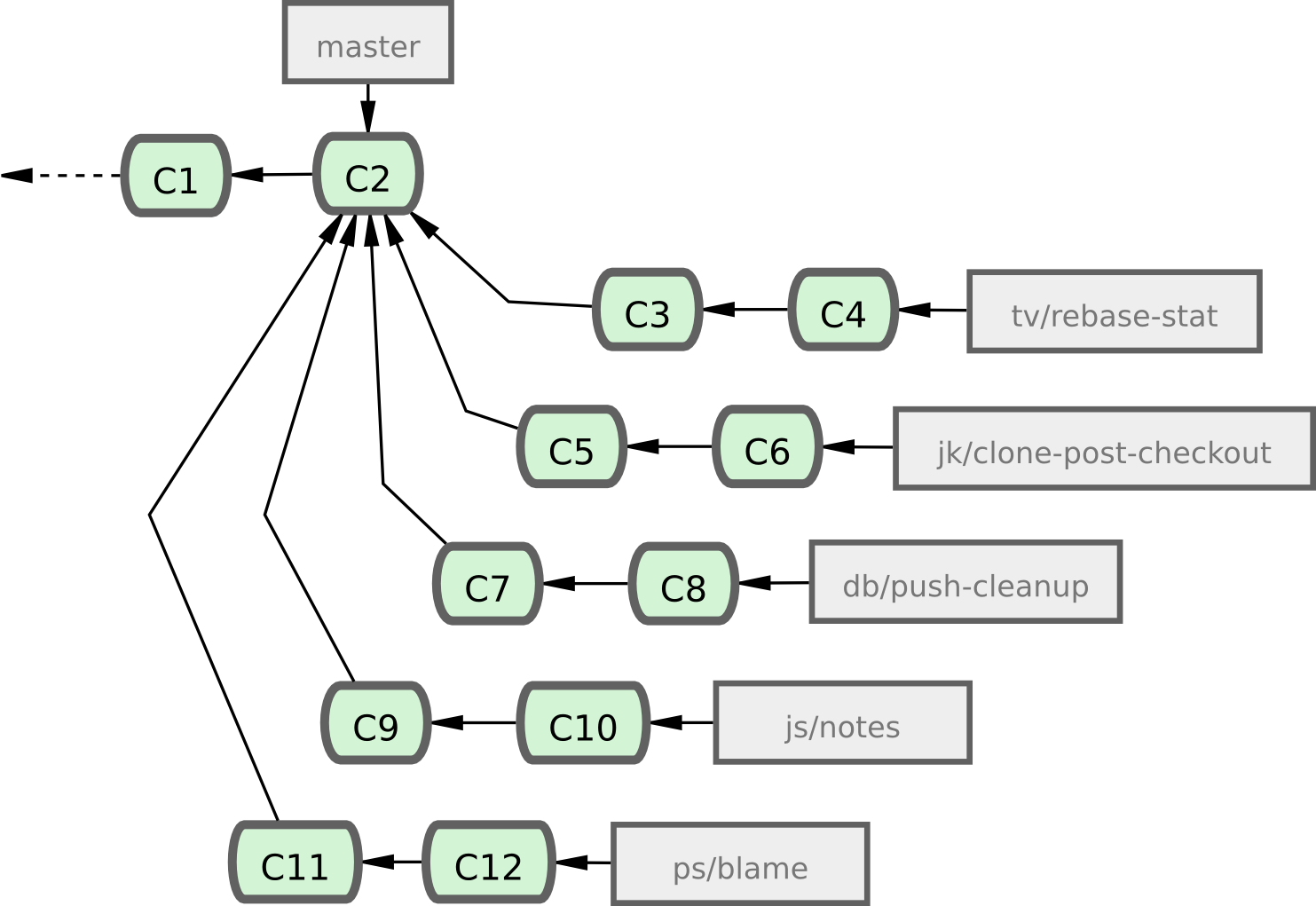 Figure 5-24. Série complexe de branches thématiques contribuées en parallèle.
Figure 5-24. Série complexe de branches thématiques contribuées en parallèle.
Si les fonctionnalités nécessitent encore du travail, elles sont fusionnées plutôt dans pu.
Quand elles sont considérées comme totalement stables, elles sont re-fusionnées dans master et sont alors reconstruites à partir fonctionnalités qui résidaient dans next mais n'ont pu intégrer master.
Cela signifie que master évolue quasiment toujours en mode avance rapide, tandis que next est rebasé assez souvent et pu est rebasé encore plus souvent (voir figure 5-25).
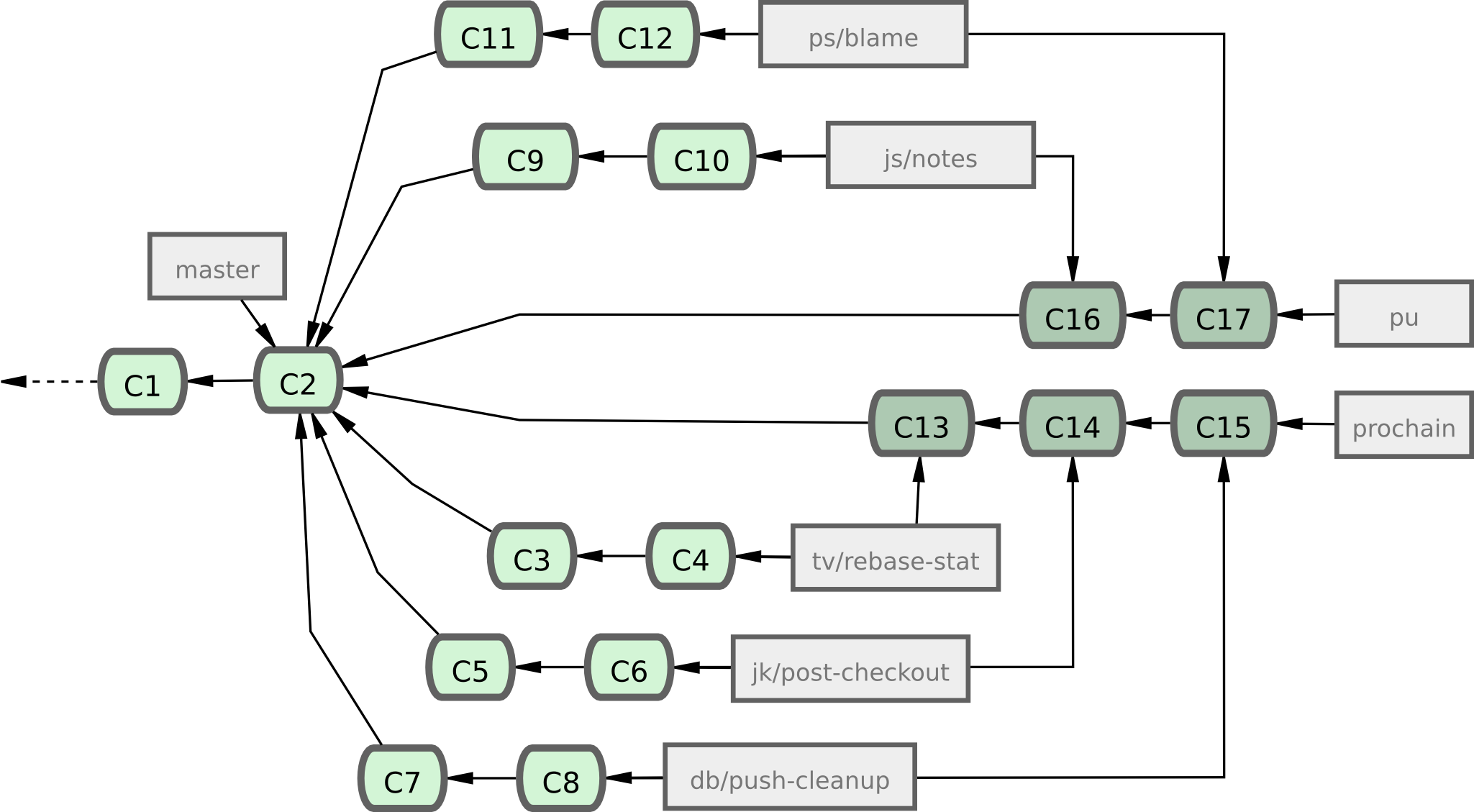 Figure 5-25. Fusion des branches thématiques dans les branches à long terme.
Figure 5-25. Fusion des branches thématiques dans les branches à long terme.
Quand une branche thématique a finalement été fusionnée dans master, elle est effacée du dépôt.
Le projet Git a aussi une branche maint qui est créée à partir de la dernière version pour fournir des patchs correctifs en cas de besoin de version de maintenance.
Ainsi, quand vous clonez le dépôt de Git, vous avez quatre branches disponibles pour évaluer le projet à différentes étapes de développement, selon le niveau développement que vous souhaitez utiliser ou pour lequel vous souhaitez contribuer.
Le mainteneur a une gestion structurée qui lui permet d'évaluer et sélectionner les nouvelles contributions.
D'autres mainteneurs préfèrent rebaser ou sélectionner les contributions sur le sommet de la branche master, plutôt de les fusionner, de manière à conserver un historique à peu près linéaire.
Lorsque plusieurs modifications sont présentes dans une branche thématique et que vous souhaitez les intégrer, vous vous placez sur cette branche et vous lancer la commande rebase pour reconstruire les modifications à partir du sommet courant de la branche master (ou develop, ou autre).
Si cela fonctionne correctement, vous pouvez faire une avance rapide sur votre branche master et vous obtenez au final un historique de projet linéaire.
L'autre moyen de déplacer des modifications introduites dans une branche vers une autre consiste à les sélectionner (cherry-pick).
Une sélection dans Git ressemble à un rebasage appliqué à un commit unique.
Cela consiste à prendre le patch qui a été introduit lors d'une validation et à essayer de l'appliquer sur la branche sur laquelle on se trouve.
C'est très utile si on a un certain nombre de commits sur une branche thématique et que l'on veut n'en intégrer qu'un seul, ou si on n'a qu'un commit sur une branche thématique et qu'on préfère le sélectionner plutôt que de lancer rebase.
Par exemple, supposons que vous ayez un projet ressemblant à la figure 5-26.
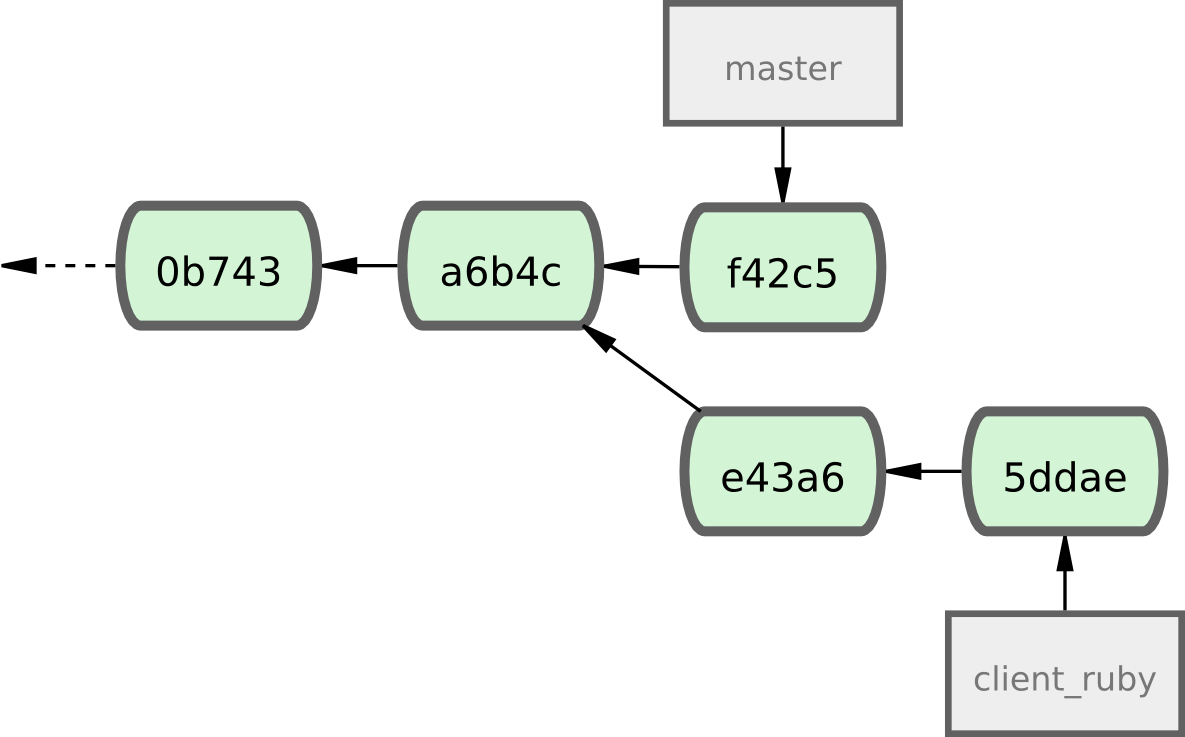 Figure 5-26. Historique d'exemple avant une sélection.
Figure 5-26. Historique d'exemple avant une sélection.
Si vous souhaitez tirer le commit e43a6 dans votre branche master, vous pouvez lancer
$ git cherry-pick e43a6fd3e94888d76779ad79fb568ed180e5fcdf
Finished one cherry-pick.
[master]: created a0a41a9: "More friendly message when locking the index fails."
3 files changed, 17 insertions(+), 3 deletions(-)
La même modification que celle introduite en e43a6 est tirée mais vous obtenez une nouvelle valeur de SHA-1 car les dates d'application sont différentes.
À présent, votre historique ressemble à la figure 5-27.
[[figures/5.27.png|align=center|frame|width=500px|alt=Figure 5-27. Historique après sélection d'un commit dans une branche thématique.]]
Maintenant, vous pouvez effacer votre branche thématique et abandonner les commits que vous n'avez pas tirés dans master.
Quand vous décidez d'arrêter une publication de votre projet, vous souhaiterez probablement étiqueter le projet pour pouvoir recréer cette version dans le futur. Vous pouvez créer une nouvelle étiquette telle que décrite au chapitre 2. Si vous décidez de signer l'étiquette en tant que mainteneur, la commande ressemblera à ceci :
$ git tag -s v1.5 -m 'my signed 1.5 tag'
You need a passphrase to unlock the secret key for
user: "Scott Chacon <schacon@gmail.com>"
1024-bit DSA key, ID F721C45A, created 2009-02-09
Si vous signez vos étiquettes, vous rencontrerez le problème de la distribution de votre clé publique PGP permettant de vérifier la signature.
Le mainteneur du projet Git a résolu le problème en incluant la clé publique comme blob dans le dépôt et en ajoutant une étiquette qui pointe directement sur ce contenu.
Pour faire de même, vous déterminez la clé de votre trousseau que vous voulez publier en lançant gpg --list-keys :
$ gpg --list-keys
/Users/schacon/.gnupg/pubring.gpg
---------------------------------
pub 1024D/F721C45A 2009-02-09 [expires: 2010-02-09]
uid Scott Chacon <schacon@gmail.com>
sub 2048g/45D02282 2009-02-09 [expires: 2010-02-09]
Ensuite, vous pouvez importer la clé directement dans la base de donnée Git en l'exportant de votre trousseau et en la redirigeant dans git hash-object qui écrit une nouveau blob avec son contenu dans Git et vous donne en sortie le SHA-1 du blob :
$ gpg -a --export F721C45A | git hash-object -w --stdin
659ef797d181633c87ec71ac3f9ba29fe5775b92
À présent, vous avez le contenu de votre clé dans Git et vous pouvez créer une étiquette qui pointe directement dessus en spécifiant la valeur SHA-1 que la commande hash-object vous a fournie :
$ git tag -a maintainer-pgp-pub 659ef797d181633c87ec71ac3f9ba29fe5775b92
Si vous lancez git push --tags, l'étiquette mainteneur-pgp-pub sera partagée publiquement.
Un tiers pourra vérifier une étiquette après import direct de votre clé publique PGP, en extrayant le blob de la base de donnée et en l'important dans GPG :
$ git show maintainer-pgp-pub | gpg --import
Il pourra alors utiliser cette clé pour vérifier vos étiquettes signées.
Si de plus, vous incluez des instructions d'utilisation pour la vérification de signature dans le message de étiquetage, l'utilisateur aura accès à ces informations en lançant la commande git show <étiquette>.
Comme Git ne fournit pas par nature de nombres croissants tels que « r123 » à chaque validation, la commande git describe permet de générer un nom humainement lisible pour chaque commit.
Git concatène la nom de l'étiquette la plus proche, le nombre de validations depuis cette étiquette et un code SHA-1 partiel du commit que l'on cherche à définir :
$ git describe master
v1.6.2-rc1-20-g8c5b85c
De cette manière, vous pouvez exporter un instantané ou le construire et le nommer de manière intelligible.
En fait, si Git est construit à partir du source cloné depuis le dépôt Git, git --version vous donne exactement cette valeur.
Si vous demandez la description d'un instantané qui a été étiqueté, le nom de l'étiquette est retourné.
La commande git describe repose sur les étiquettes annotées (étiquettes créées avec les options -a ou -s).
Les étiquettes de publication doivent donc être créées de cette manière si vous souhaitez utiliser git describe pour garantir que les commits seront décrits correctement.
vous pouvez aussi utiliser ces noms comme cible lors d'une extraction ou d'une commande show, bien qu'ils reposent sur le SHA-1 abrégé et pourraient ne pas rester valide indéfiniment.
Par exemple, le noyau Linux a sauté dernièrement de 8 à 10 caractères pour assurer l'unicité des objets SHA-1 et les anciens noms git describe sont par conséquent devenus invalides.
Maintenant, vous voulez publier une version.
Une des étapes consiste à créer une archive du dernier instantané de votre code pour les pauvres hères qui n'utilisent pas Git.
La commande dédiée à cette action est git archive :
$ git archive master --prefix='projet/' | gzip > `git describe master`.tar.gz
$ ls *.tar.gz
v1.6.2-rc1-20-g8c5b85c.tar.gz
Lorsqu'on ouvre l'archive, on obtient le dernier instantané du projet sous un répertoire projet.
On peut aussi créer une archive au format zip de manière similaire en passant l'option --format=zip à la commande git archive :
$ git archive master --prefix='projet/' --format=zip > `git describe master`.zip
Voilà deux belles archives tar.gz et zip de votre projet prêtes à être téléchargées sur un site web ou envoyées par e-mail.
Il est temps d'envoyer une annonce à la liste de diffusion des annonces relatives à votre projet.
Une manière simple d'obtenir rapidement une sorte de liste des modifications depuis votre dernière version ou e-mail est d'utiliser la commande git shortlog.
Elle résume toutes le validations dans l'intervalle qui vous lui spécifiez.
Par exemple, ce qui suit vous donne un résumé de toutes les validations depuis votre dernière version si celle-ci se nomme v1.0.1 :
$ git shortlog --no-merges master --not v1.0.1
Chris Wanstrath (8):
Add support for annotated tags to Grit::Tag
Add packed-refs annotated tag support.
Add Grit::Commit#to_patch
Update version and History.txt
Remove stray `puts`
Make ls_tree ignore nils
Tom Preston-Werner (4):
fix dates in history
dynamic version method
Version bump to 1.0.2
Regenerated gemspec for version 1.0.2
Vous obtenez ainsi un résumé clair de toutes les validations depuis v1.0.1, regroupées par auteur, prêt à être envoyé sur la liste de diffusion.
Vous devriez à présent vous sentir à l'aise pour contribuer à un projet avec Git, mais aussi pour maintenir votre propre projet et intégrer les contributions externes. Félicitations, vous êtes un développeur Git efficace ! Au prochain chapitre, vous découvrirez des outils plus puissants pour gérer des situations complexes, qui feront de vous un maître de Git.