
Braq document with 3 sections
Customizable data format for config files, AI prompts, and more
- Overview
- Data format specification
- Notable use cases
- Classes for interacting with a document
- Section class
- Base functions
- Braq schema for data validation
- Misc functions
- Miscellaneous
- Testing and contributing
- Installation
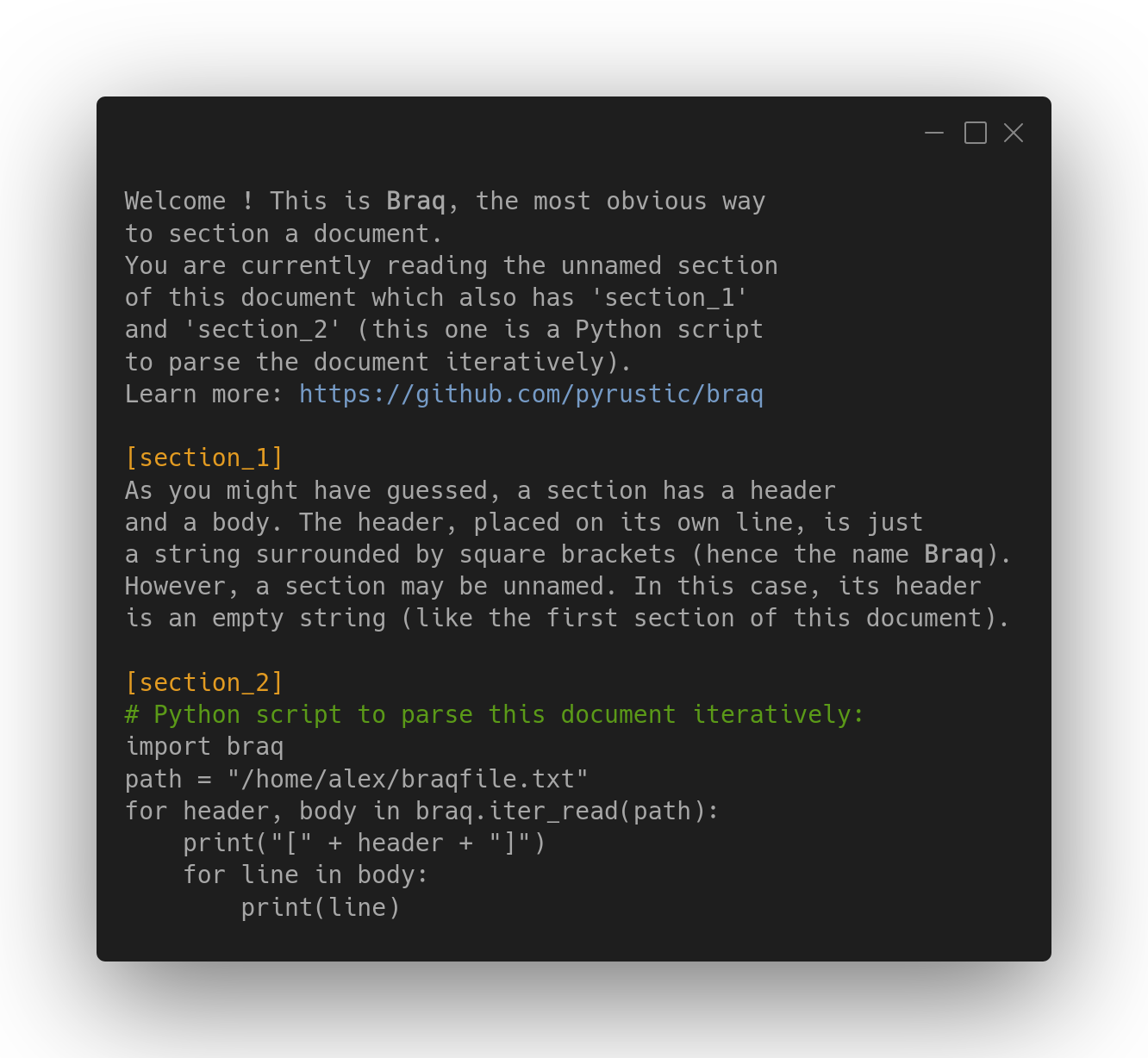
Braq (pronounced /ˈbɹæk/) is a human-readable customizable data format whose reference parser is an eponymous lightweight Python library available on PyPI.
A Braq document is made up of sections, each defined by a header surrounded by square brackets (hence the name Braq) and a body which is just lines of text.
Since a body is arbitrary text, it is possible to embed a complex dictionary data structure into a section by encoding it with the human-readable Paradict data format.
Its versatility and minimal format specification make Braq highly customizable and therefore allow it to be used in an eclectic set of use cases such as config files, AI prompts, and code documentation.
The Braq parser offers an intuitive programming interface to smoothly interact with a Braq document as well as a transparent integration with Paradict for embedding and loading complex dictionary data structures.
Braq provides functions for parsing documents line by line, creating document models, rendering documents, and performing file I/O operations, among other functionalities.
At a higher level, the Document class leverages the base functions to model documents and allow seamless interaction with them. This class also serves as the parent class for FileDoc that focuses specifically on documents with associated disk files.
Here are the specs and recommended practices for a valid and neat Braq document:
-
A Braq document, when not empty, can be divided into sections.
-
A section is made up of two parts: a header and a body.
-
The header is defined on its own line, surrounded by two single square brackets (opening and closing brackets respectively).
-
The body is what is between two consecutive headers or between a header and the end of the document.
-
A section can be defined multiple times in the same document. In this case, the parser will concatenate its bodies from top to bottom.
-
A section with an empty header is called an unnamed section.
-
It is recommended to define no more than a single occurrence of a section in a document.
-
When a document contains a single unnamed section, it is recommended to place this section at the top of the document.
-
When an unnamed document starts a document, it is recommended to omit its header.
-
A dictionary data structure encoded with the human-readable Paradict data format can be safely embedded into a section. This section should then be referenced as a dict section.
-
It is recommended to put 1 empty line as spacing between two consecutive sections.
Example:
This is the unnamed section
that starts this document.
[section 1]
Lorem ipsum dolor sit amet,
consectetur adipiscing elit.
[section 2]
# dictionary data structure encoded with Paradict
id = 42
user = "alex"
books = (dict)
sci-fi = (list)
"book 1"
"book 2"
thriller = (set)
"book 3"
[section 1]
it is not recommended to multiply the occurrences
of a section, however the parser will append this
occurrence of 'section 1' to the previous one.
This section outlines three notable use cases for Braq, namely config files, AI prompts, and code documentation.
Being able to embed a dictionary data structure in a section makes Braq de facto suitable for config files.
Example of a Braq config file:
# This is the unnamed section of 'my-config.braq' file.
# This section will serve as HELP text.
[user]
id = 42
name = 'alex'
[gui]
theme = 'dark'
window-size = '1024x420'
Using functions to consume and create config files:
from braq import load_config, dump_config
config = load_config("my-config.braq")
# get the 'user' dict section
user = config["user"]
# test
assert user == {"id": 42, "name": "alex"}
# embed a 'server' dict section in the config file then dump the config
config["server"] = {"ip-address": "127.0.0.1", "port": 80}
dump_config(config, "my-config.braq") # persistedNote that
load_configanddump_configshould be used only when the target filename is a config file that contains exclusively dict sections. For other files, use theFileDocclass
Using the FileDoc class to consume the config file:
from braq import FileDoc
confile = FileDoc("my-config.braq")
# build the 'user' dict section
user = confile.build("user")
# test
assert user == {"id": 42, "name": "alex"}
# retrieve the unnamed section
text = confile.get("") # notice the empty header str
# retrieve the 'user' dict section as a text
text = confile.get("user")
# embed a 'server' dict section in the config file
server_conf = {"ip-address": "127.0.0.1", "port": 80}
confile.embed("server", server_conf) # change persistedA schema can be passed to a
FileDocinstance to validate dict sections.
The capability to seamlessly interweave human-readable structured data with prose within a single document is a fundamental capability that a language designed to interact with AI must possess.
Additionally, the fact that Braq natively supports indentation removes the need for input sanitization, thereby eliminating an entire class of injection attacks.
Following are specs for building structured AI prompts with Braq:
- A prompt document must start with the root instructions defined inside the top unnamed section.
- The next section that the AI should actively care about, after the top unnamed section, should be explicitly referenced in the root instructions.
- User input must be programmatically embedded as a text value of a dictionary key inside a section that is not the top unnamed section.
That's it ! The specification is deliberately short to avoid unnecessary complexity and also to leave room for creativity.
You are an AI assistant, your name is Jarvis.
You will access the websites defined in the WEB section
to answer the question that will be submitted to you.
The question is stored in the 'input' key of the USER
dict section.
Be kind and consider the conversation history stored
in the 'data' key of the HISTORY dict section.
[USER]
timestamp = 2024-12-25T16:20:59Z
input = (raw)
Today, I want you to teach me prompt engineering.
Please be concise.
---
[WEB]
https://github.com
https://www.xanadu.net
https://www.wikipedia.org
https://news.ycombinator.com
[HISTORY]
0 = (dict)
timestamp = 2024-12-20T13:10:51Z
input = (raw)
What is the name of the planet
closest to the sun ?
---
output = (raw)
Mercury is the planet closest
to the sun !
---
1 = (dict)
timestamp = 2024-12-22T14:15:54Z
input = (raw)
What is the largest planet in
the solar system?
---
output = (raw)
Jupiter is the largest planet
in the solar system !
---
The flexibility of Braq gives the possibility to define custom data formats for specific use cases. Source code documentation is one of those use cases that need Braq with a custom format on top of it.
This is how Braq can be used to document a function:
def add(a, b):
"""
This function adds together the values of
the provided arguments.
[param]
- a: first integer
- b: second integer
[return]
Returns the sum of `a` and `b`
"""
return a + bMikeDoc is a docstring format for generating API references. The library uses Braq to parse docstrings.
The library exposes the Document and FileDoc classes for interacting with documents. In contrary to the Document class, FileDoc focuses specifically on documents with associated disk files such as config files.
The Document class creates an editable model of a Braq document and also offers to validate it with a schema.
Usage example:
from braq import Document
INIT_TEXT = """
This document contains
configuration data
[user]
id = 42
name = 'alex'
"""
SCHEMA = {"user": {"id": "int", "name": "str"}}
document = Document(INIT_TEXT, schema=SCHEMA)
# get the body of the unnamed section as a text
text = document.get("") # empty header string
# build the 'user' dict section
user = document.build("user")
# test
assert user == {"id": 42, "name": "alex"}
# set a section (here, we are editing the unnamed section)
document.set("", "line 1\nline 2")
assert document.get("") == "line 1\nline 2"
# embed a 'server' dict section
server_conf = {"ip-address": "127.0.0.1", "port": 80}
document.embed("server", server_conf)
# list headers
assert document.list_headers() == ("", "user", "server")
# validate specific dict sections
# (no args implies that the entire doc will be the target)
document.is_valid("user", "server") # returns a bool
# beware, the 'validate' method may raise an exception
# for good reasons !There is more to discover about the
Documentclass, such as theclear,remove, andrendermethods, exposed properties, and more.
Check out the API reference for
braq.Documenthere.
The FileDoc class is based on the Document class and focuses specifically on documents with associated disk files such as config files.
As with the
Documentclass, a schema can be passed to aFileDocinstance to validate dict sections.
from braq import FileDoc
confile = FileDoc("config-file.braq")
# build the 'user' section
user = confile.build("user")
# test
assert user == {"id": 42, "name": "alex"}
# retrieve the unnamed section as a text
text = confile.get("") # notice the empty header str
# retrieve the 'user' dict section as a text
text = confile.get("user")
# embed a 'server' dict section
server_conf = {"ip-address": "127.0.0.1", "port": 80}
confile.embed("server", server_conf) # change persistedThere is more to discover about the FileDoc class, such as the
load,save, andsave_tomethods, exposed properties, and more.
Check out the API reference for
braq.FileDochere.
The Section class is an abstraction representing a Braq section. It exposes the header and body properties and renders itself when its __str__ method is called implicitly.
import braq
# create a Section object
header, body = "my header", ("line a", "line b")
section = braq.Section(header, body)
# test the properties
assert section.header == "my header"
assert section.body == "line a\nline b"
# test the rendering
assert str(section) == """\
[my header]
line a
line b"""Base classes such as Document and FileDoc use several public functions under the hood that can be directly called by the programmer at the right time. These basic functions allow you to parse and render documents as well as read and write file documents.
The library exposes the parse function which takes as input the text stream to be parsed, then returns a dictionary whose keys and values are strings representing headers and bodies respectively.
Sections sharing the same header are concatenated ! The header of an unnamed section is an empty string.
import braq
text = """\
this is the unnamed section at
the top of this document...
[section 1]
this is section 1"""
d = braq.parse(text)
# check headers
assert tuple(d.keys()) == ("", "section 1")
# check the body of 'section 1'
assert d["section 1"] == "this is section 1"Check out the API reference for
braq.parsehere.
A document can be parsed line by line as following:
import braq
text = """\
this is the unnamed section
[section 1]
this is section 1"""
for header, body in braq.parse_iter(text):
if header:
print("[" + header + "]")
for line in body:
print(line)Output:
this is the unnamed section
[section 1]
this is section 1
Check out the API reference for
braq.parse_iterhere.
The library exposes the read function which takes as input the path to a file to parse, then returns a dictionary whose keys and values are strings representing headers and bodies respectively.
Sections sharing the same header are concatenated !
import braq
path = "/home/alex/braqfile.txt"
r = braq.read(path)
assert tuple(r.keys()) == ("", "section 1")Check out the API reference for
braq.readhere.
A large text file can be parsed line by line as following:
import braq
path = "/home/alex/braqfile.txt"
for header, body in braq.read_iter(path):
if header:
print("[" + header + "]")
for line in body:
print(line)Output:
this is the unnamed section
[section 1]
this is section 1
Check out the API reference for
braq.read_iterhere.
Rendering a document involves transforming Python objects representing sections into Braq text which is a string that can be displayed on the screen or stored in a file.
The library exposes the render function which accepts as input a sequence of sections (either header-body tuples or Section objects) and returns a Braq document.
import braq
# sections
section_1 = braq.Section("section 1", "line a\nline b")
section_2 = "section 2", "line c\nline d"
section_3 = "section 3", ("line e", "line f")
# rendering
r = braq.render(section_1, section_2, section_3)
print(r)Output:
[section 1]
line a
line b
[section 2]
line c
line d
[section 3]
line e
line f
The
renderfunction also accepts thespacingargument which defaults to 1 and represents the number of lines of spacing between two adjacent sections.
Check out the API reference for
braq.renderhere.
Following is a snippet for writting a Braq document to a file:
import braq
# sections
section_1 = braq.Section("", "welcome")
section_2 = braq.Section("section 2")
section_3 = "section 3", ("line a", "line b")
# path to file
path = "/home/alex/braqfile.txt"
# write to file
sections = (section_1, section_2, section_3)
r = braq.write(sections, path)The contents of the Braq file:
welcome
[section 2]
[section 3]
line a
line b
Check out the API reference for
braq.writehere.
Dict sections can be validated against a Braq schema. A Braq schema is a Python dictionary object that can be passed to a Document or a FileDoc. The keys of this dictionary are the headers of dict sections to validate and the values are Paradict schemas.
A Paradict schema is a dictionary containing specs for data validation.
A spec is either simply a string that represents an expected data type, or a Spec object that can contain a checking function for complex validation.
Supported spec strings are: dict, list, set, obj, bin, bin, bool, complex, date, datetime, float, grid, int, str, time
Example:
from paradict.validator import Spec
from braq import Document
# Braq text with 2 dict sections
TEXT = """
[user]
id = 42
name = 'alex'
[server]
ip-address = "127.0.0.1"
port = 80
"""
# Associated schema
SCHEMA = {"user": {"id": "int",
"name": "str"},
"server": {"ip-address": "str",
"port": Spec("int", lambda x: 0 < x < 65535)}}
doc = Document(TEXT, schema=SCHEMA)
assert doc.is_valid()
# beware, the validate function returns a bool
# but it can also raises an exception when something is wrong The check_header function accepts a line of text as input and then returns a boolean to indicate whether this line is a header or not.
import braq
line_1 = "[my header]"
line_2 = "[this isn't a header] at all"
assert braq.check_header(line_1) is True
assert braq.check_header(line_2) is FalseThe get_header function accepts a line of text as input and returns a string if the line is a header. Otherwise, None is returned.
import braq
line_1 = "[my header]"
line_2 = "[this isn't a header] at all"
assert braq.get_header(line_1) == "my header"
assert braq.get_header(line_2) is NoneCheck out the API reference for
braq.check_headerandbraq.get_headerhere.
Collection of miscellaneous notes.
The beautiful cover image is generated with Carbon.
Feel free to open an issue to report a bug, suggest some changes, show some useful code snippets, or discuss anything related to this project. You can also directly email me.
Following are instructions to setup your development environment
# create and activate a virtual environment
python -m venv venv
source venv/bin/activate
# clone the project then change into its directory
git clone https://github.com/pyrustic/braq.git
cd braq
# install the package locally (editable mode)
pip install -e .
# run tests
python -m unittest discover -f -s tests -t .
# deactivate the virtual environment
deactivateBraq is cross-platform. It is built on Ubuntu and should work on Python 3.5 or newer.
python -m venv venv
source venv/bin/activatepip install braqpip install braq --upgrade --upgrade-strategy eagerdeactivateHello world, I'm Alex, a tech enthusiast ! Feel free to get in touch with me !