© 2023, Anyscale Inc. All Rights Reserved

Welcome to the Multilingual Chat with Ray Serve!
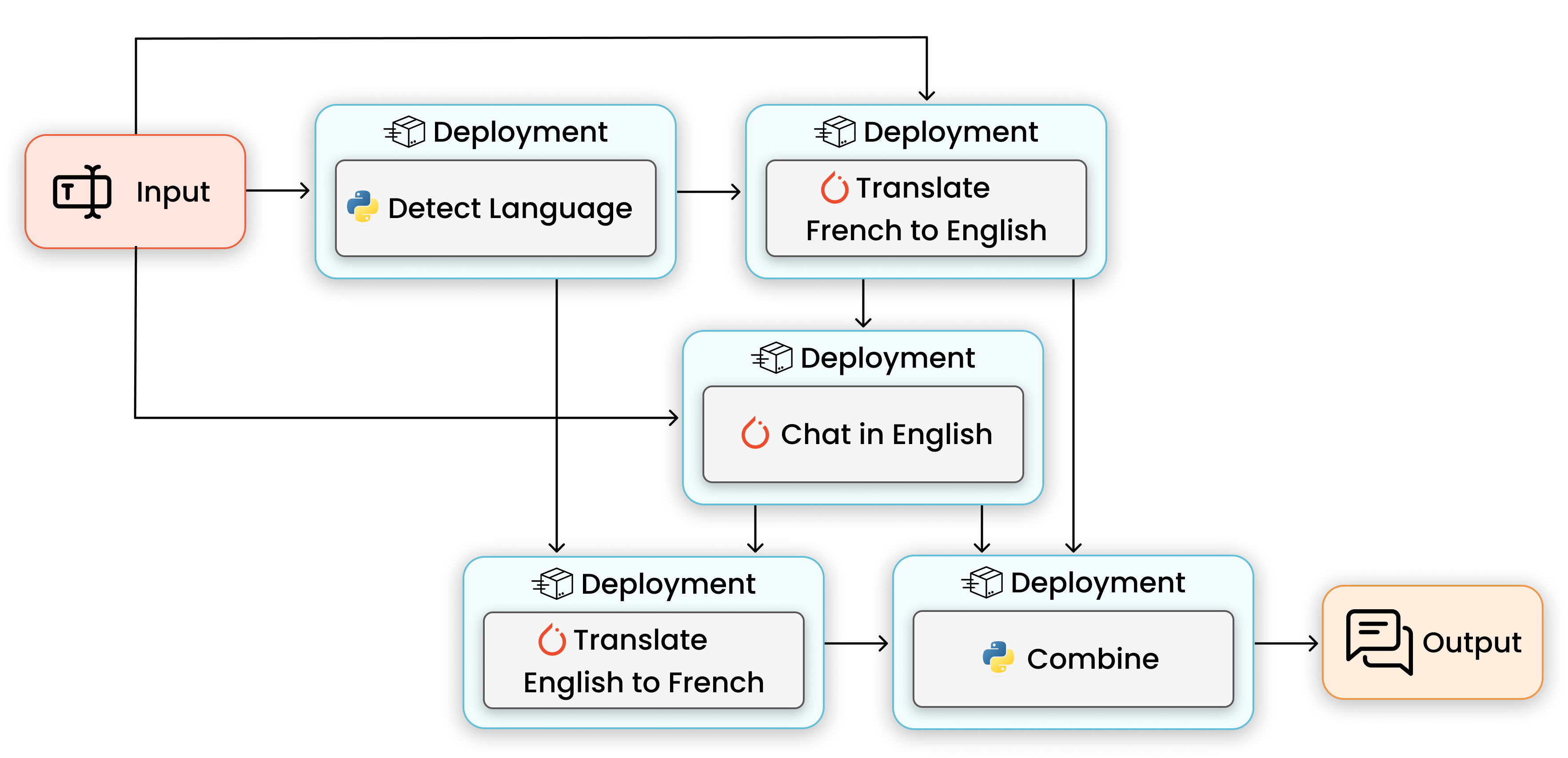
In this tutorial, we will explore how to author real-time inference pipelines in Python with Ray Serve and the deployment graph API. We will also discuss scaling and resources allocation problems and show how Ray enables you to simplify and control your deployments. This workshop is especially suited for ML practitioners and ML engineers who look for modern tools for scalable ML.
We will build multilingual chat. System will consist of deep learning models and business logic implemented with Ray Serve and the deployment graph API.
You can learn and get more involved with the Ray community of developers and researchers:
-
Official Ray site Browse the ecosystem and use this site as a hub to get the information that you need to get going and building with Ray.
-
Join the community on Slack Find friends to discuss your new learnings in our Slack space.
-
Use the discussion board Ask questions, follow topics, and view announcements on this community forum.
-
Join a meetup group Tune in on meet-ups to listen to compelling talks, get to know other users, and meet the team behind Ray.
-
Open an issue Ray is constantly evolving to improve developer experience. Submit feature requests, bug-reports, and get help via GitHub issues.
-
Become a Ray contributor We welcome community contributions to improve our documentation and Ray framework.
You can further explore Ray ecosystem and expand your distributed ML skills by checking supplementary resources.
| Module | Description |
|---|---|
| LLM fine-tuning and batch (offline) inference | Finetune Google's Flan-T5 text generation model of the Alpaca instructions and demonstrations dataset. |
| Scaling CV batch inference | Use SegFormer architecture to learn about scaling batch inference in computer vision with Ray. |
| Scaling CV model training | Use SegFormer architecture to learn about scaling model training in computer vision with Ray. |