![]()
See and Think: Embodied Agent in Virtual Environment
Zhonghan Zhao*, Wenhao Chai*, Xuan Wang*, Li Boyi, Shengyu Hao, Shidong Cao, Tian Ye, Jenq-Neng Hwang, Gaoang Wang✉️
arXiv 2023
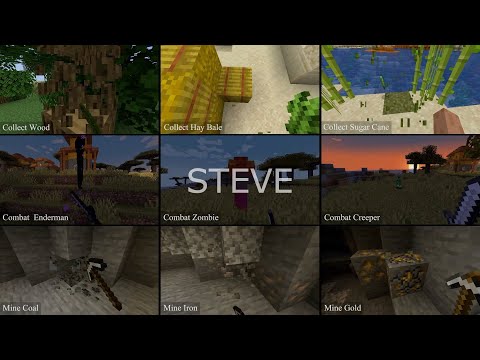
STEVE, named after the protagonist of the game Minecraft, is our proposed framework aims to build an embodied agent based on the vision model and LLMs within an open world.
- [2023.12.13] : We release our STEVE-7B model at huggingface.
- [2023.12.11] : We release our STEVE-13B model at huggingface.
- [2023.12.06] : We release our code at code-v0 branch.
- [2023.11.26] 📃 We release the paper.
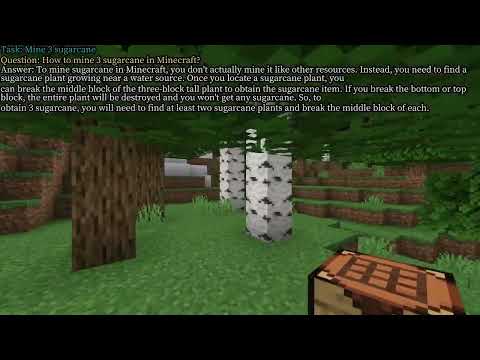
The Vision Perception part takes images or videos, encodes them into tokens, and combines them with the tokens of Agent State and Task as input. The STEVE-13B in the Language Instruction part is used for automatic reasoning and task decomposition, and it calls the Skill Database in the form of the Query to output code as action.



If you find STEVE useful for your your research and applications, please cite using this BibTeX:
@article{zhao2023see,
title={See and Think: Embodied Agent in Virtual Environment},
author={Zhao, Zhonghan and Chai, Wenhao and Wang, Xuan and Boyi, Li and Hao, Shengyu and Cao, Shidong and Ye, Tian and Hwang, Jenq-Neng and Wang, Gaoang},
journal={arXiv preprint arXiv:2311.15209},
year={2023}
}