Home
Forecast probabilities of a project's effort and duration using Monte Carlo simulations.
This tool can give accurate results regardless of your project management and development process. However, you will get better results when your project tasks are broken down to be within reasonable size differences. Differences of up to 500% in task sizes are perfectly fine, but please don't expect highly-accurate results if some tasks take 15 minutes while others take 45 days (unless they are evenly spread)
Public-facing URL: https://rodrigozr.github.io/ProjectForecaster/
You can see a sample project here (pre-filled with test data)
Monte Carlo Simulation is a computerized mathematical technique to tell:
- All of the possible events that could or will happen
- The probability of each possible outcome
The technique is used by professionals in such widely disparate fields as finance, project management, energy, manufacturing, engineering, research and development, insurance, oil & gas, transportation, and the environment. It was first used by scientists working on the hydrogen atom bomb; it was named for Monte Carlo, the Monaco resort town renowned for its casinos. Since its introduction in World War II, Monte Carlo simulation has been used to model a variety of physical and conceptual systems.
A Monte Carlo simulation builds models of possible results by substituting a range of values — a probability distribution — for any factor that has inherent uncertainty. It then calculates results over and over, each time using a different set of random values from the probability functions. In the end, the frequency of occurrences is evaluated to determine the probabilities.
The Monte Carlo simulation model for a project is based on the following uncertainties:
- How many tasks will be executed throughout the project?
- How many tasks will be completed every week, until the project is completed?
In order to build a probability distribution for those uncertainties, the following data is used:
- Size of the team
- Minimum and maximum number of individual contributors who can work in the project
- Number of tasks that this project is expected to have
- Risks of the project
- Historical weekly throughput
- Historical task lead times
- Historical project's split rate
To use this tool, you need to:
- Break your projects into tasks
- Collect data for at least 7 weeks
- Run the simulation
- Understand the results
The sections below explain each of those steps in more details:
If you are delivering projects, this is something that you probably already do today, right? You should be breaking down your projects into smaller tasks of some sort.
For using a Monte Carlo simulation, it doesn't matter what kind of tasks you are using, nor your project management methodology. You can break down in user-stories, technical tasks, or anything else that makes sense to you. The only restriction is that those tasks should not be "absurdly" different in sizes. As a general rule of thumb, differences in sizes of up to 500% are perfectly acceptable. However, you should avoid having super-simple tasks mixed in the same bucket with highly-complex ones. For example, having tasks that take a few minutes or a couple of hours, along with tasks that take several weeks, will make your forecasts unreliable.
This process is sometimes called "work break-down structure" (WBS), "taskfying", among others. How you name it doesn't really matter, as long as you are able to do it and get to a number of tasks for the whole project.
Sometimes, you may be in doubt about the total number of tasks because there are project risks that need further investigation. I.e.: "I'm not sure if we will need to upgrade the database or not". In this kind of scenario, you can add all those risks to the simulation in the Risks section. Each risk has the following data:
-
Likelihood: The estimated probability (in percentage) of that risk manifesting. It may be quite hard to predict
this probability, but as a general rule of thumb, you can use
25%for unlikely events,50%for "somewhat likely", and75%for "highly likely". - Low impact: The minimum number of tasks you will need to add to your project if the risk manifests to be true.
- High impact: The maximum number of tasks you will need to add to your project if the risk manifests to be true.
- Description: Description of the risk
- For each project task completed: Write down the start date and end date. You MUST NOT include here anything else not related to project tasks. I.e.: Ignore any bug-fix, general requests, tech debt, etc. This is very important because all this interference will be computed in the forecast model by impacting your actual productivity. (This data will be used to calculate the weekly throughput and task cycle times).
-
For each project completed: Write down the number of tasks that you had planned at the beginning of the
project, and the actual total number of tasks implemented by the time you complete the project. These two numbers
will differ very often for multiple reasons, such as: Finding out that a task was too big and splitting it in two,
finding additional unplanned mandatory scope, etc. This information is used to calculate the project's "split rate".
The split rate is calculated by a simple formula:
actual tasks quantitydivided byplanned tasks quantity. For example, as split rate of1.2means that the project ended up having20%more tasks than originally planned.
With the data above, and a simple excel file, you can easily calculate the following, which is used by the tool:
-
Weekly throughput: Total number of tasks completed per week. You can, for example, use excel's
WEEKNUM(completed date)formula to get the week number for each task, then create a pivot table to get the weekly throughput. -
Cycle times: This is how long each individual task took to complete in calendar days. This is calculated
as
end date - start date. -
Split rates: This is calculated for each completed project with a simple formula:
actual tasks quantitydivided byplanned tasks quantity. For example, as split rate of1.2means that the project ended up having20%more tasks than originally planned.
The more data you collect, the better, but old and stale data may end up hurting your forecast. The recommended is to have a minimum of 7 weeks and a maximum of 24 weeks of historical data (except for the project split rates - it is fine to have up to one year of split rates collected).
Once you have the number of tasks, and the historical data, you just need to input the data and run the simulation. Here is a brief explanation of each field in the simulation data:
- Project name: This is just an optional name for the project you are simulating. This is useful because Project Forecaster allows sharing a link of your simulation data, so when you open a link to a simulation you had saved, you will know for which project that was.
- Team size: Total number of individual contributors on this team (or service). This must represent the number of individual contributors that generated the weekly throughput samples you collected. You MUST NOT adjust this number to account for vacations, sick leaves, and other similar temporary leaves. However, if the team size changes permanently, this number should represent the number of contributors that produced the majority of the data points collected. Notice that big team changes (such as a major re-org, doubling the team size for a new project, etc), should be considered as a "new system", so data collected from the previous system will very likely not be valid for this "new system". In these cases, you may need to start from scratch by collecting at least seven weeks of data.
- Minimum contributors: Minimum number of individual contributors who will start working in the project. This is used to model the project's S-curve to forecast the project duration in calendar weeks. This field is optional: If you only want to forecast the project effort, this is not necessary, so you can leave it empty.
- Maximum contributors: Maximum number of individual contributors who can work in the project (maximum parallelism within the project). This is used to model the project's S-curve to forecast the project duration in calendar weeks. This field is optional: If you only want to forecast the project effort, this is not necessary, so you can leave it empty. Notice that if your team will work on multiple projects in parallel, this number will be lower than Team size.
- Number of tasks: Number of tasks planned for this project. Notice that tasks should be within a reasonable range of sizes (up to 500% difference in sizes is perfectly fine). It doesn't matter how you are breaking down your projects, as long as task sizes are within this range. This could be user stories or any other granular level that makes sense to you.
-
Number of simulations: Number of simulations to execute. The recommended values are:
Minimum 10K,Default: 100K,Max: 10MM. The more simulations you run, the more accurate the forecasts are, but the longer they will take. For large projects, with a large number of tasks, and many collected data-points, it may be unfeasible to run with higher values. If you put this value too high, your browser may appear to hang for a while during the simulations. -
"S-Curve" size: Size of the S-Curve (a.k.a "Z-Curve") at the beginning and end of the project. Empirical evidence
demonstrates that most projects have lower productivity in the first 20% and the last 20% of the project.
Minimum: 0%,Default: 20%,Max: 50%. If you don't want to simulate an S-curve, set this to0%. -
Confidence level: Level of confidence to report in the results. This is used in the "Forecast summary" as well as in the
charts to draw the percentile lines.
Minimum: 1%,Default: 85%,Max: 99%. - Start date: Optional planned start date for this project. Set this if you want to calculate a planned end date.
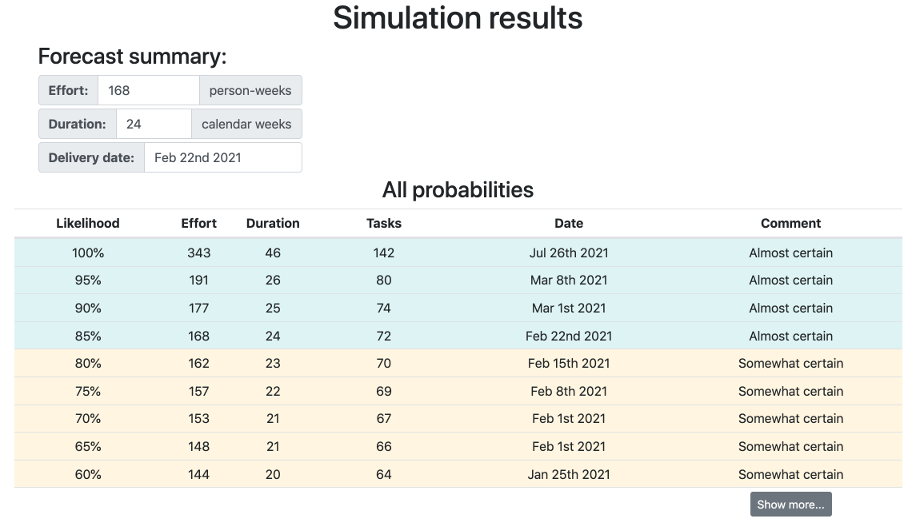
Project Forecaster will tell you the probability of "maximum effort and duration" for several confidence levels.
This means that, if you configure a confidence level of 85%, and the Forecast summary says something like Effort: 148 person-weeks and Duration: 45 calendar weeks, it means that this project will take "148 person-weeks or less" and it can be delivered in "45 calendar weeks or less", with 85% of confidence.
This means that you decide how much risk you are willing to take when committing to project deadlines. For critical projects, with a high cost of delay, you may decide to go up to 95% confidence, while less critical projects, with a low cost of delay, may decide to use something closer to 70% of confidence. Going lower than that may not make sense, as it would mean that you have a 50% chance or higher of not delivering the project on time.
Keep in mind that the two extremes (0% confidence and 100% confidence) will typically be way off when compared to all other probabilities because they represent unreal scenarios where "everything will go absolutely wrong" or "everything will go perfectly" during the whole project execution.
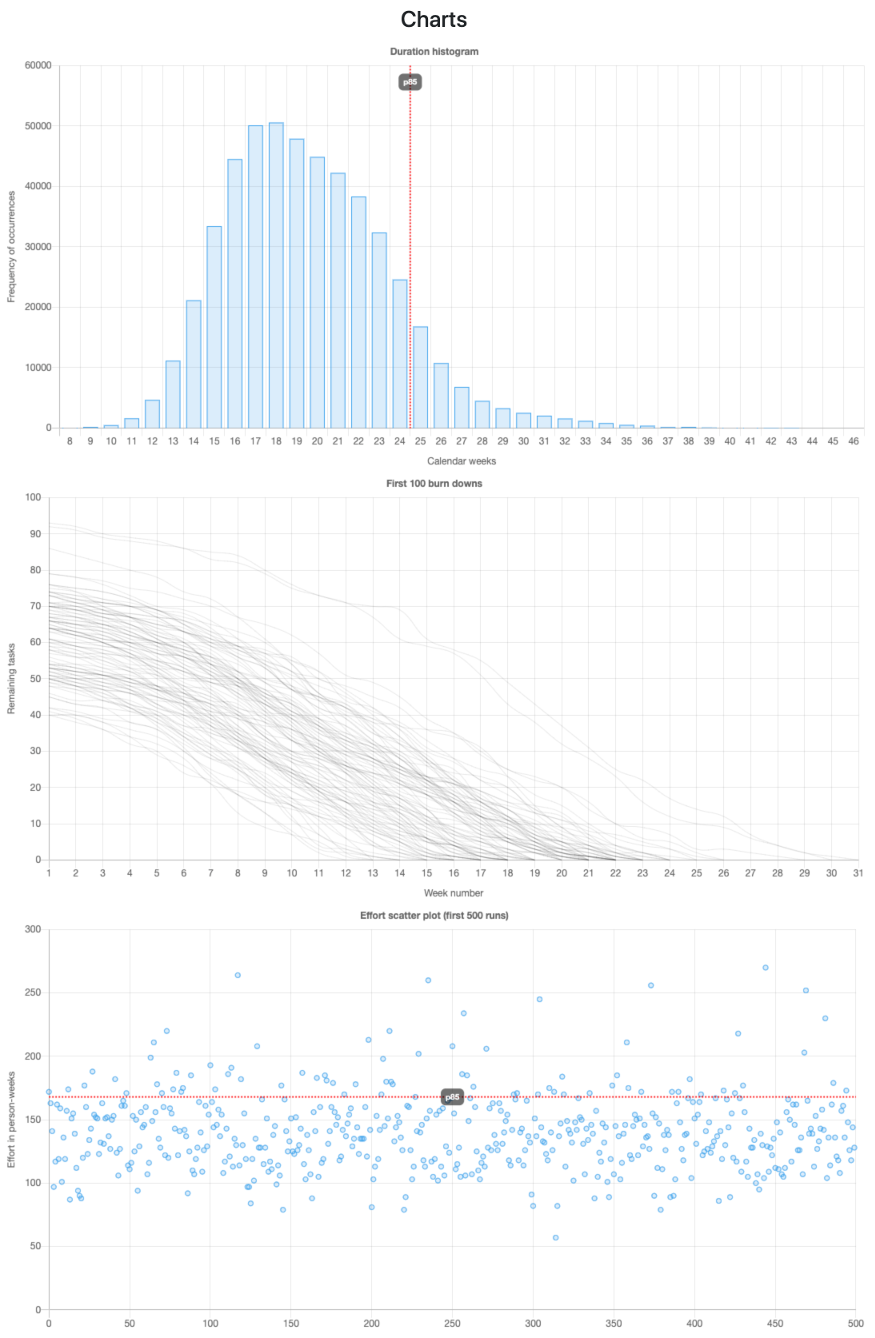
The charts can also give you a good idea of what is happening "under the hoods" during the simulations:
- Duration histogram: Plots how frequently each possible "duration in calendar weeks" occurred after completing all simulations.
- First 100 burn downs: Plots the burn-down chart for the first 100 simulations (plotting more than that would make the chart very hard to understand).
- Effort scatterplot: Plots the simulated effort for the first 500 simulations. Each individual dot in the chart is the result of a simulation, and they appear in the same order that they happened.
Your data is 100% safe because it never leaves your browser! Project Forecaster works completely offline after the webpage was loaded. When you share a link to your forecast, all the simulation data is encoded and stored in the URL itself, so no information is ever stored nor transmitted online (this also explains why the links are so long).
Absolutely! This tool is a "static website", and it doesn't even need any hosting. Just download the source-code, extract it, and open index.html in your browser - it is that simple!