Obsolete : published on the Consortium website
New look and new features for this 0.22 scikit-learn release. Just a bit earlier than Santa visiting, this past month some unusual Elves have worked really hard to keep the target of releasing scikit-learn twice a year.
Come take a look together at some of the many suprises this special package contains.
New features for plotting and interpretability
Models fitted by Machine Learning algorithms need to be interpreted and well understood if they have to be applied at a large scale and trusted by users.
Visualisation is an important step of data analysis and an essential one to the understanding of your dataset. It allows to have a first insight into the data and provides suggestions on which methods are suitable to a deeper investigation. The 0.22 scikit-learn version defines a simple API for visualisation. The key feature of this API is to allow for quick plotting and visual adjustments without recalculation. For each available plotting function a correspondent object is defined storing the necessary information to be graphically rendered.

Interpretability defines the level of comprehension we have of a general model and of its application to a dataset.
Dive deeper into interpretability of the fitted model makes Machine Learning more understandable.
This was also a recommendation from the Partners
of the scikit-learn Consortium.
The 0.22 version improves the inspection
module.
A new feature, the permutation feature importance, has been added.
It measures how the score of a specific model decreases when a feature is not available.
The permutation importance is calculated on the training set to show how much the model relies on each feature during training.
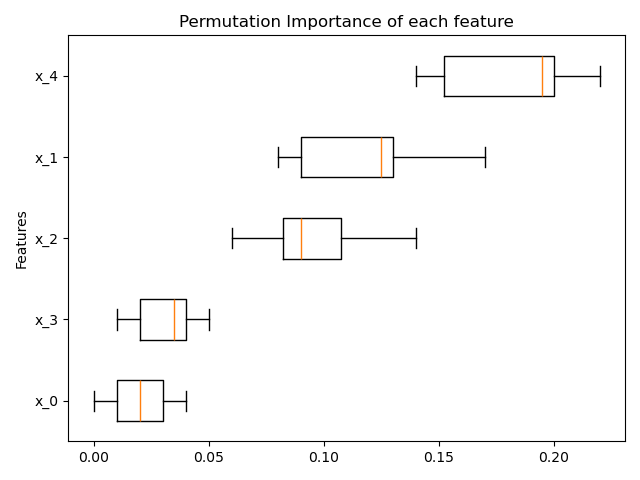
Also Partial Dependency analysis has been improved in particular increasing interoperability with Pandas objects and the new plotting capabilities.
Improvements in missing data management

When dealing with big amount of data there are just as big chances that some entries are incomplete. Multiple reasons, from instrument failures to bad format conversions to human errors, could be the causes of missing values in the dataset. Ideally, Machine Learning algorithm would know what to do with them. When this is not the case a number of so-called imputation algorithms could be used to make assumptions on the missing data.
For scikit-learn, version 0.22 brings the HistogramGradientBooster algorithm to
manage missing data without need of any imputing.
For those estimators that still need missing data to be imputed the impute module has now a new k-Nearest Neighbors imputer, for which a Euclidean distance has been defined in the
metric module taking missing values into account.
fetch_openml improvements and Pandas interoperability
Big amount of data needs to be efficiently and accurately manipulated: interoperability is the key for a safe data mining. No matter which software you are using, format and structure manipulations need to be automatised and user do not have to care about that. Pandas is a principal actor of the big data ecosystem: scikit-learn 0.22 improves input and output interoperability with pandas on a method by method basis. In particular fetch_openml can now return pandas dataframe and thus properly handle datasets with heterogeneous data.
Clear definition of the public API
Even if in Python there is no really private objects and methods, this 0.22 version aims to clean the public API space. Be aware that this could change some of your import. Private API are not meant to be documented and you should not rely on their stability.
stick to python deprecation recommendations
Managing logs is not an obvious task: if you are in a production or development environment, if you are managing a lot of
dependencies or just running a small script, you may want to monitor different behaviours, looking for different levels of
verbosity.
Python defines a standard behaviour for warnings, defining
also the level of the warning filter needed to avoid
them.
The scikit-learn approach has always been to make the user aware of object deprecations, as the code could be update as soon as
possible to avoid future failures.
But this was done in a non standard way, overriding user preferences in the __init__.py file.
Our Elves received some coal in the past for this.
They are happy to share that scikit-learn 0.22 is compliant with Python recommendation.
Deprecations are now identified with FutureWarnings, always thrown in the Python scheme.
The 0.22 release comes with a lot more of improvements and bug fixes. Check the Changelog to have them in a glance. As often, choices have to be made and compromises between the amazing feature you would have been happy to see in the code and the time availability of a community based project: so, please don't be too upset if your Santa's list is not completely covered.
The Elves are already working on the next step ... to 0.23 ... and beyond!