Home
Webrender is an experimental renderer for Servo that aims to draw web content like a modern game engine.
- Specialized renderer for web content.
- Not a general purpose vector graphics API.
- Complex items such as canvas can be rendered on CPU.
- Make the common case fast.
- Use GPU to do all rasterization where possible.
- Items not well suited to GPU rasterizing can be drawn on the CPU and cached in textures.
- Take advantage of multiple CPU cores.
- Many of the tasks in a game engine renderer are easily parallelized.
- Draw only what's on screen
- Aggressively cull items.
- Redraw each frame (when there is something to be updated - not a constant fps like games!).
- Cache results (such as vertex buffers, rasterized glyphs) where possible between frames.
- Take advantage of knowledge of entire scene up front to optimize drawing.
- Batching
- Group items into small number of draw calls.
- Necessary for good performance with OpenGL.
- High resolution displays, GPUs likely to scale better than CPUs here.
- GPUs excel at blits, blending.
- Hit common driver paths used in games, encounter fewer driver bugs?
- May be faster for cases that game engines already deal with (animations, transitions, 3d transforms).
- Simplifies parts of layout and rendering in traditional painting model.
- Layout no longer needs to worry about layerization, as this is an internal implementation detail!
- May allow simpler and faster WebGL implementation (this would be long term).
The renderer runs through a number of steps each time a layout completes. The backend thread receives messages (such as add_image, new_layout). When it has built a new frame it notifies the compositor by sending a message with the relevant information (texture cache updates, pre-compiled vertex buffers, and render batches).
When scrolling an existing layout, steps 1 and 2 are skipped. Since items from steps 6 and 7 are cached between frames, these are typically very quick to execute during scrolling.
There is currently no caching of render items, display lists and batches when a new layout is received - this is a (potentially large) optimization for the future.
- Flatten scene stacking context hierarchy into flat lists of items.
- Render batching implicitly works across iframes.
- Insert items into an AABB tree.
- Used to partitioning items spatially.
- Currently used for visibility culling, and binning items for thread pools.
- Could also be used for more elaborate batching schemes (by providing overlap information).
- Perform culling - traverse the AABB tree and mark visible nodes.
- [job threads] Iterate visible nodes, building lists of required images, glyphs and rasters (such as alpha masks for rounded corners).
- Allocate space in the texture cache for each new item.
- [job threads] Rasterize glyphs that are needed but not yet cached.
- [job threads] Compile visible nodes that aren't cached - build vertex and index buffers, border triangles, CPU clipping, texture coordinate generation etc.
- Collect visible item keys and sort in stacking context painting order.
- Currently sorts both opaque and alpha items together - a potential optimization would be to split opaque and alpha, to avoid sorting opaque items altogether.
- Batch generation - build list of batches, concatenate items into single vertex buffers.
- This also applies vertex compression to minimise upload time to the GPU.
- Split batches into opaque and alpha passes. The opaque batches rely on z-buffer for draw ordering, and can thus be submitted in any order regardless of stacking context position.
- Notify compositor of new frame.
These are profiles from a desktop Linux machine (8 cores), loading https://en.wikipedia.org/wiki/Rust at 1280x1024 resolution.
| Time (ms) | Function |
|---|---|
| 0.08 | flatten_stacking_context |
| 0.17 | build_aabb_tree |
| 0.01 | visibility_cull |
| 0.65 | update_resource_lists |
| 0.33 | update_texture_cache |
| 9.68 | raster_glyphs |
| 1.23 | compile_visible_nodes |
| 0.05 | collect_and_sort_visible_render_items |
| 0.97 | create_batches |
| 13.27 | TOTAL |
| Time (ms) | Function |
|---|---|
| 0.01 | visibility_cull |
| 0.07 | update_resource_lists |
| 0.06 | update_texture_cache |
| 0.05 | raster_glyphs |
| 0.04 | compile_visible_nodes |
| 0.04 | collect_and_sort_visible_render_items |
| 1.04 | create_batches |
| 1.37 | TOTAL |
The initial proof of concept supports enough features to validate the idea, and can render simple sites like Wikipedia, Reddit, HN.
In particular:
- Text rendering (via Freetype).
- Texture cache.
- Alpha masking (for rounded corners, border-radius, complex clips).
- Basic borders (solid, radius).
- Linear gradients.
- Images
- Basic text decorations
- Use multithreading on CPU where feasible.
- Naive batching only for now.
The graphs below show the total CPU "paint" time while loading the Rust wikipedia page. Each frame in the graph is a new paint (because of new images asynchronously loading and triggering layout). For the multi-threaded Servo case, the time recorded is the total time the paint thread is blocked waiting for paint jobs to complete (effectively this is the same as the longest running paint job).


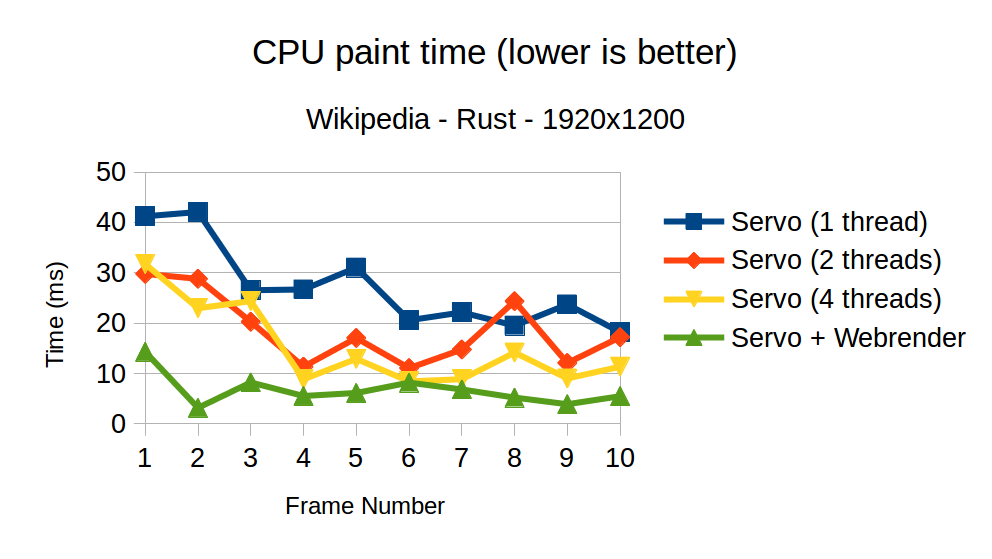
The graph below shows the actual frame rate while scrolling the Rust wikipedia page.

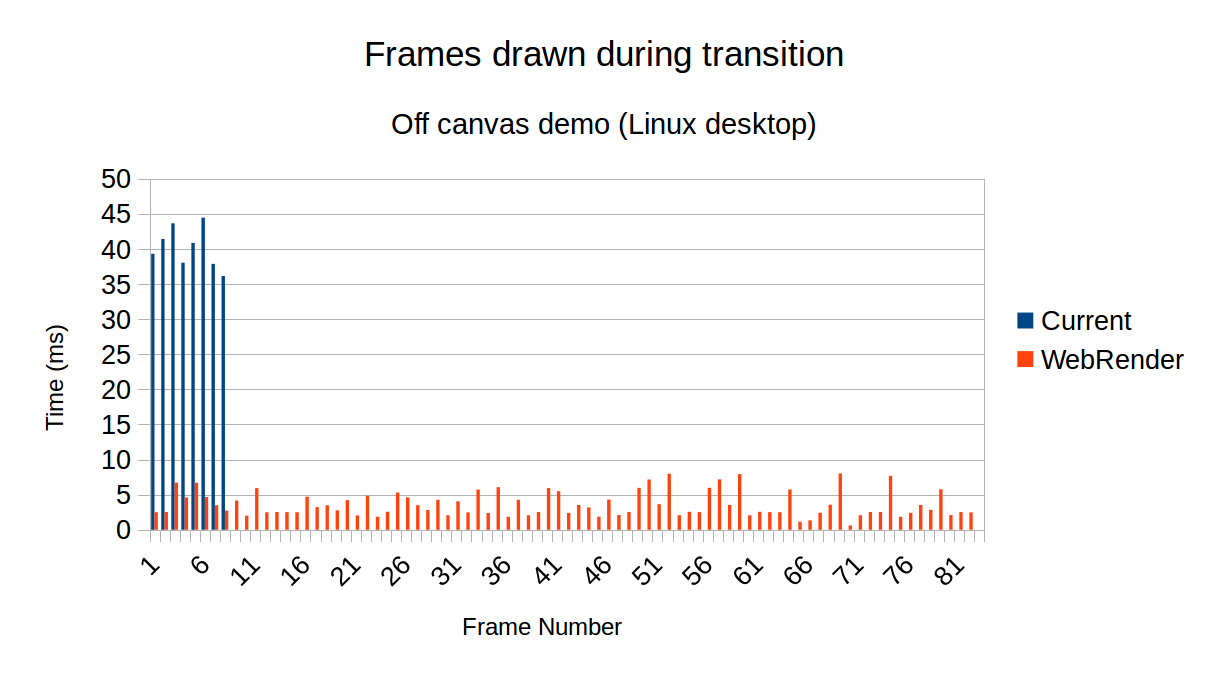
These graphs are from a simple off-canvas demonstration page. When the green button is pressed, the menu transition slides in from the left over 300ms.
In the desktop case, vsync is disabled for both tests. Each paint in existing renderer takes > 35ms, so only a small number of frames are rendered during the transition period. In the webrender case, each frame is rendered in well under 16.67ms, resulting in a very smooth looking transition.
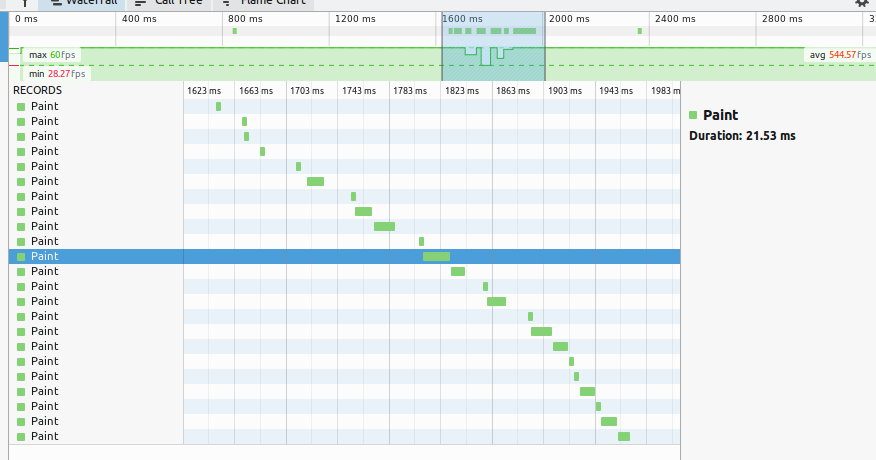
Although it's difficult to compare directly to the FF painting model, the image below shows the FF profiler during the transition when running on desktop.
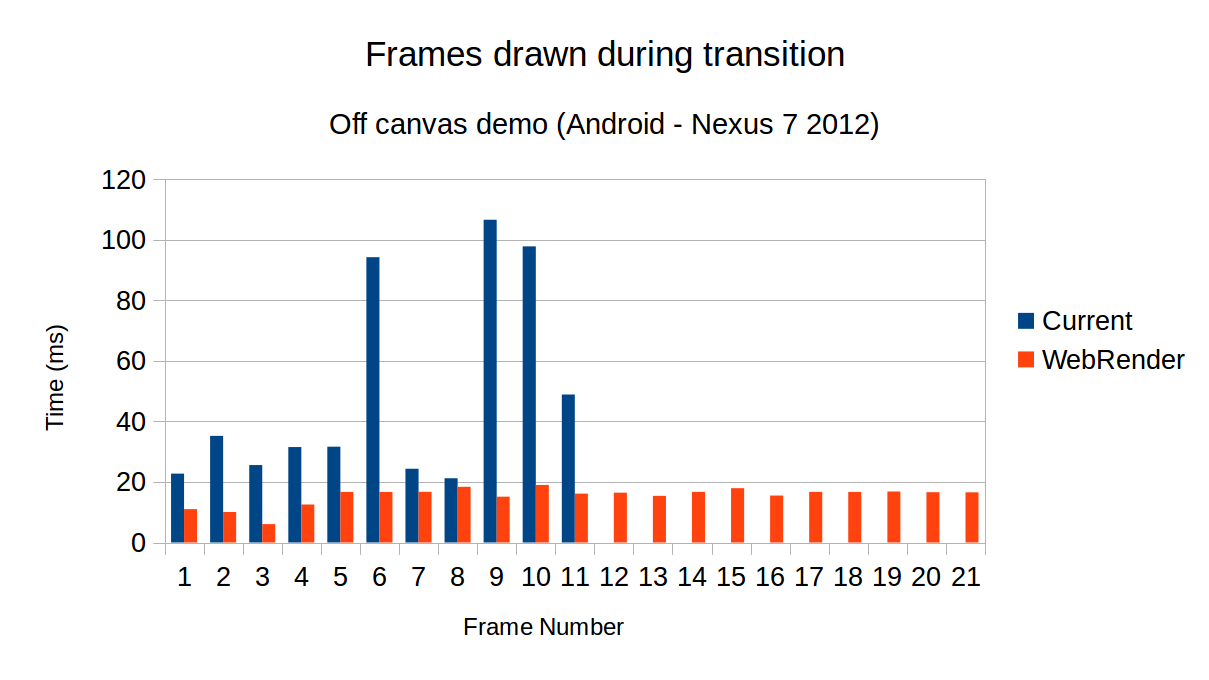
In the Android test case, a similar result is achieved. However, I was unable to disable vsync on the tablet. The transition on Android with webrender appeared very smooth.
- Support other web content (radial, conic gradients, box shadow etc).
- Support effects that require FBO (e.g. mix-blend-mode, blurs, shadows).
- Add deinit path to free images, fonts, make space in texture cache etc :)
- Better integration into Servo.
- Rasterize glyphs on GPU, to further improve initial page load?
- Better batching - make use of overlap information to reduce draw calls further.
- SIMD.
- Vulkan?
- This could possibly make some of the serial steps above able to be parallelized further.